摘要:本文详细介绍基于支持向量机的图像分类系统,给出MATLAB的算法介绍及界面设计过程。在界面中可点击选择图片或带图片的文件夹,系统自动对所涉及图片进行识别分类,可选择自己训练的模型进行分类;另外系统设计了模型训练功能,可在界面上选择训练数据集的文件夹和少量选择设置,系统便可以自动进行模型训练,适合不同的自定义数据集;算法部分的特征提取过程采用方向梯度直方图(HOG)特征,分类过程采用性能优异的核支持向量机(SVM)算法。系统界面清新美观,文中包含完整的代码文件及数据集,开箱即用,适合新手朋友学习参考。
完整资源下载链接:https://mbd.pub/o/bread/mbd-YpiTl5ht
代码介绍及演示视频链接:https://www.bilibili.com/video/BV1V44y1M7mC/(正在更新中,欢迎关注博主B站视频)
当前机器学习的算法已经获得应用,对于经典的支持向量机(SVM)算法,其有着实现简单、解释性较强、性能优越的特点。如今支持向量机的研究力度并没有减退,选择何种算法应该取决于具体的机器学习任务,对于多类别的图像分类任务,支持向量机或许是一个不错的选择。本文介绍的代码可以实现较高的分类测试准确率,所以想借此为大家提供一个学习的Demo共同交流。
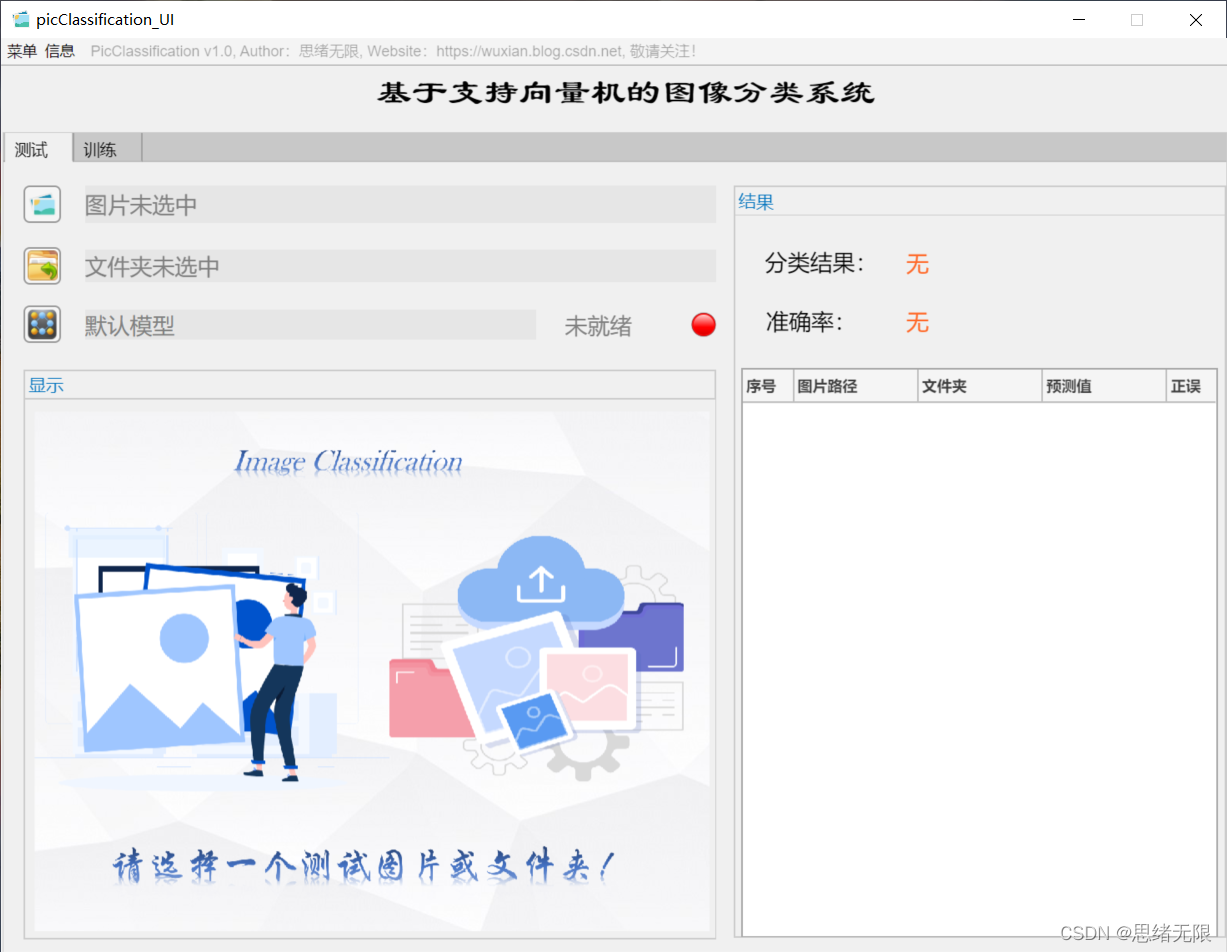
思路是先基于核支持向量机(SVM)算法开发一个能够根据图片内容进行分类的脚本,所用到的数据集可以是当前公开的分类图片数据集,也可以是自行从网络上爬取的。除了算法实现,为了便于展示和训练,我们利用MATLAB的APP设计工具开发一个GUI系统界面,能够满足我们选择模型、图片、文件夹路径的需求,初始界面如上图所示。另外由于自行设定的数据集可能经常调整,所以相应的代码也需要调整,所以这里把数据集的调整考虑进去,设计了可选择训练数据集、设置训练参数的功能,其界面如下图所示。
本文给出了MATLAB实现的完整代码供大家参考,有基础的读者可按照文中的介绍复现出完整程序;对于想获取全部数据集及程序文件的朋友,可以点击提供的下载链接获取可直接运行的代码,原创不易,还请多多支持了。如本文对您有所帮助,敬请点赞、收藏、关注!
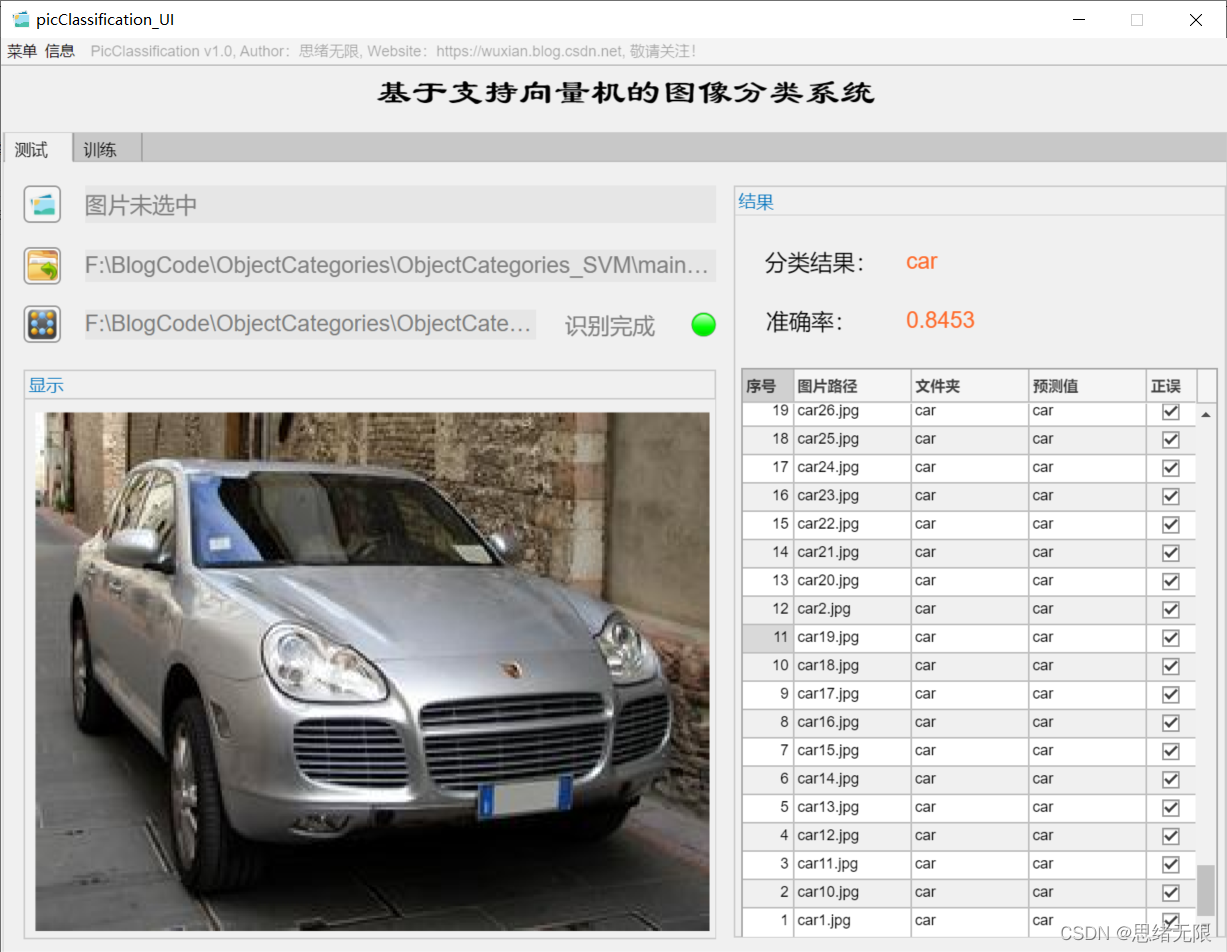
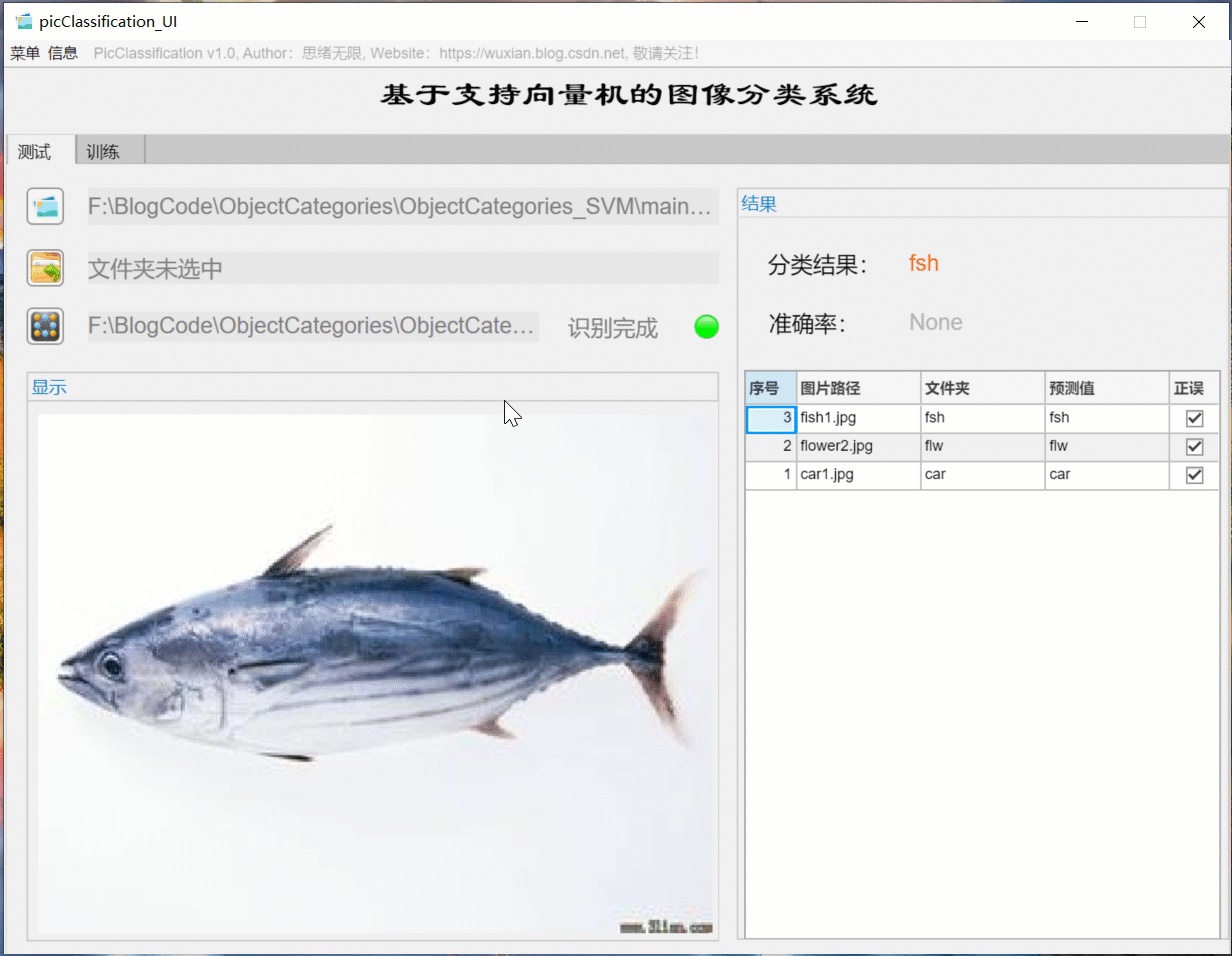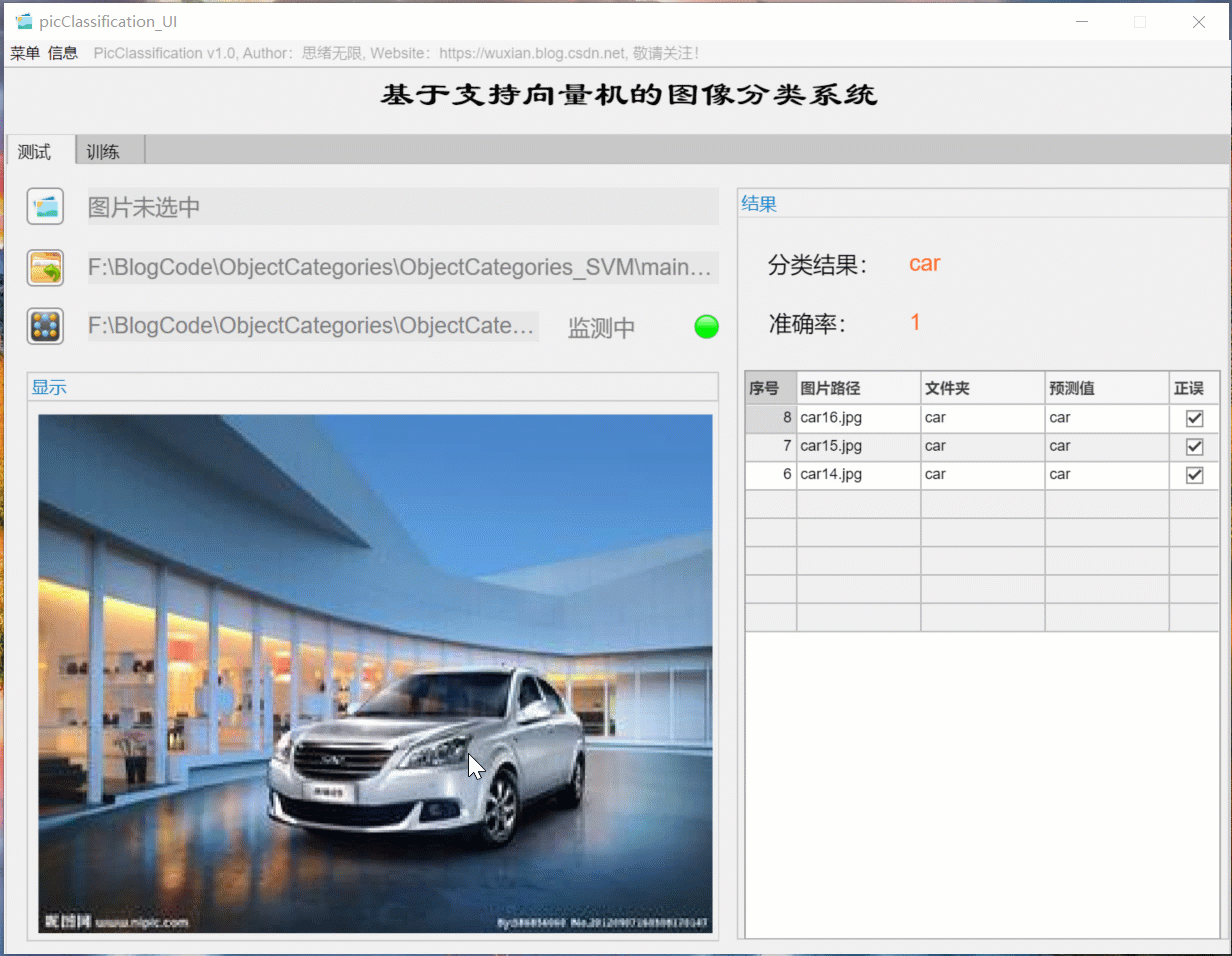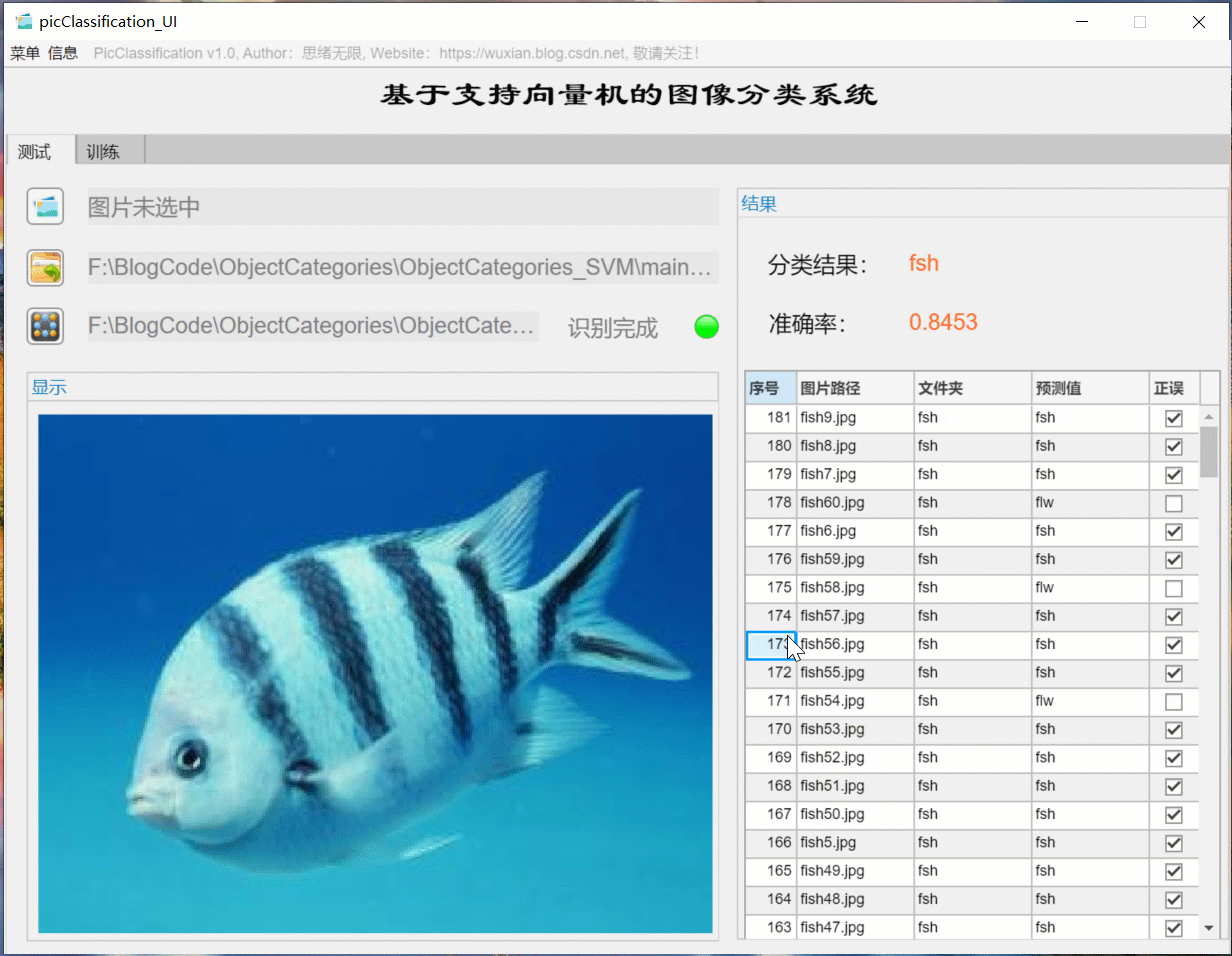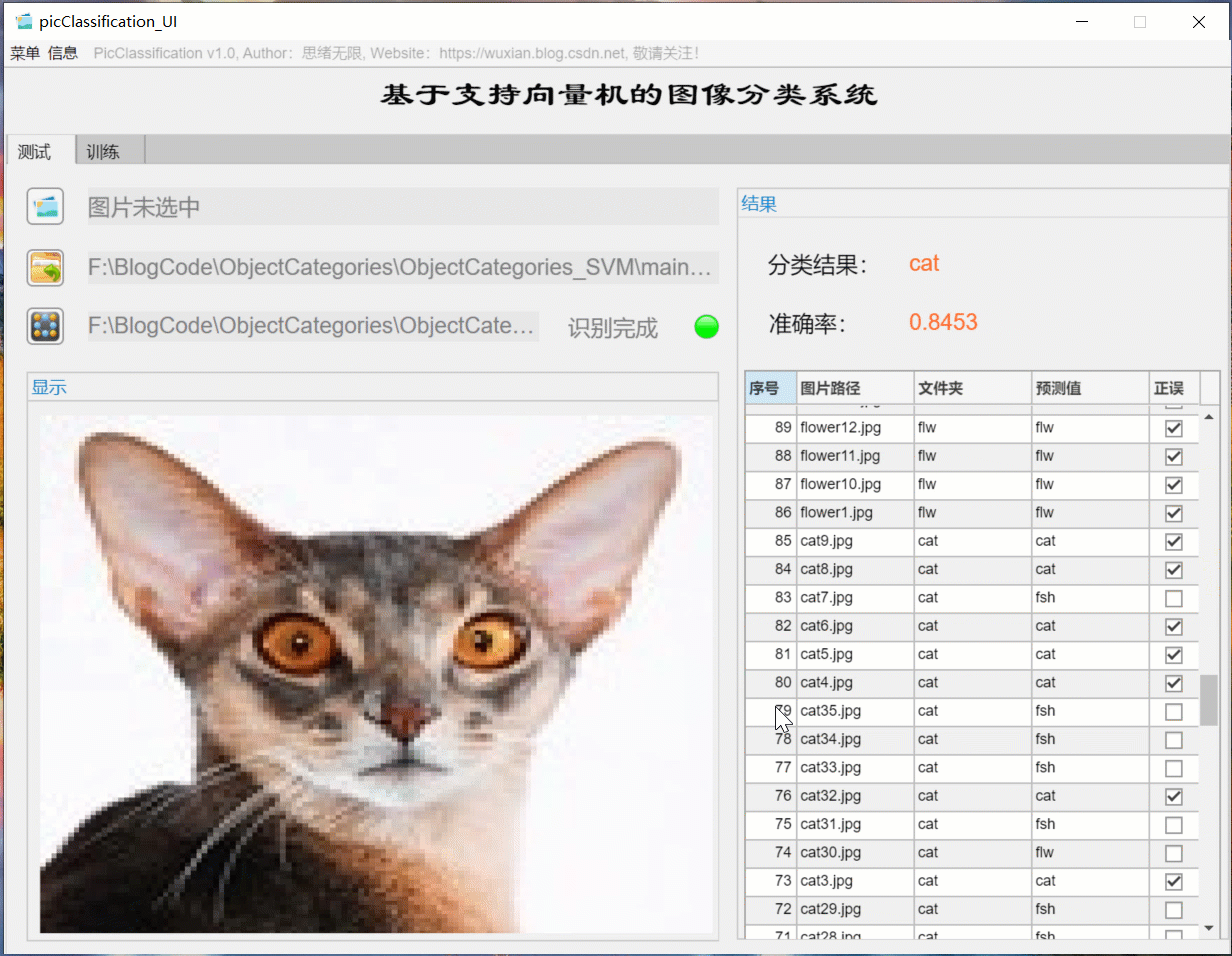
(一)选择模型+选择图片+历史记录
首先还是用动图先展示一下效果。进入软件界面后,点击模型选择按钮即可弹出文件选择窗口,可选择自行训练的模型文件;然后同样点击图片选择按钮,可以选择一张需要测试的图片,点击确认后,模型则自动识别图片内容,并给出预测的结果;结果会被记录在右侧的表格中,可供再次查看确认。本功能的界面展示如下图所示:
(二)批量图片识别+分类结果展示
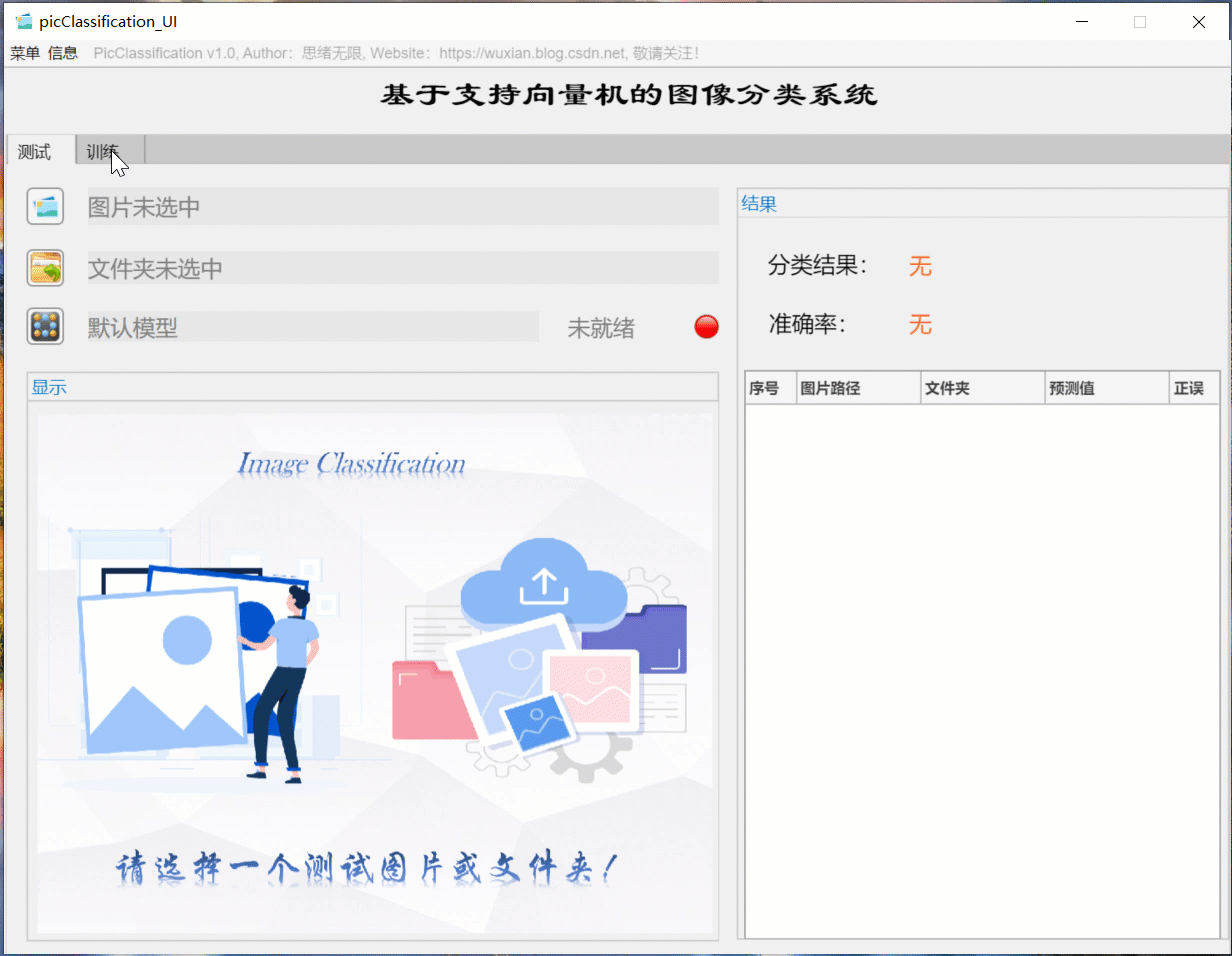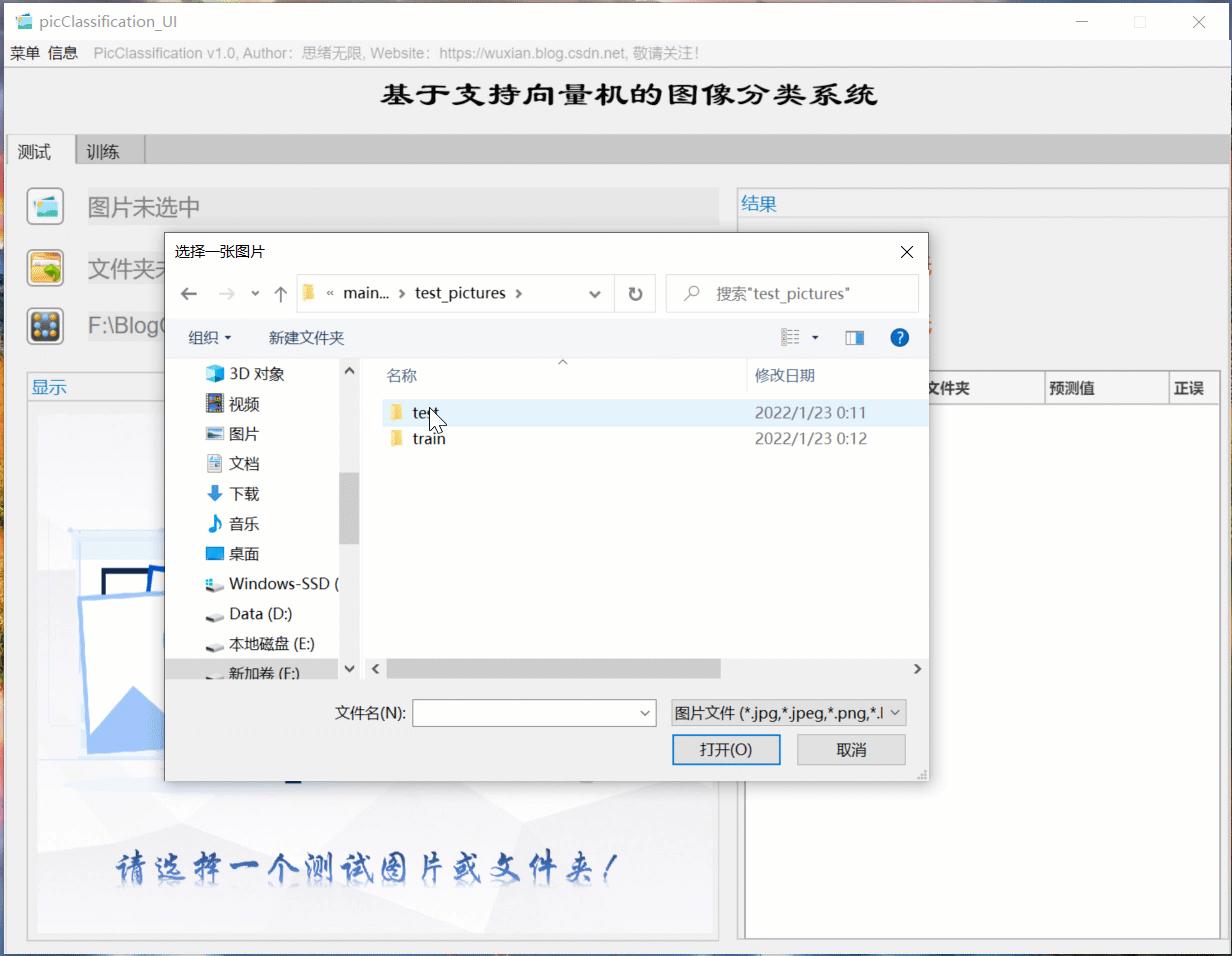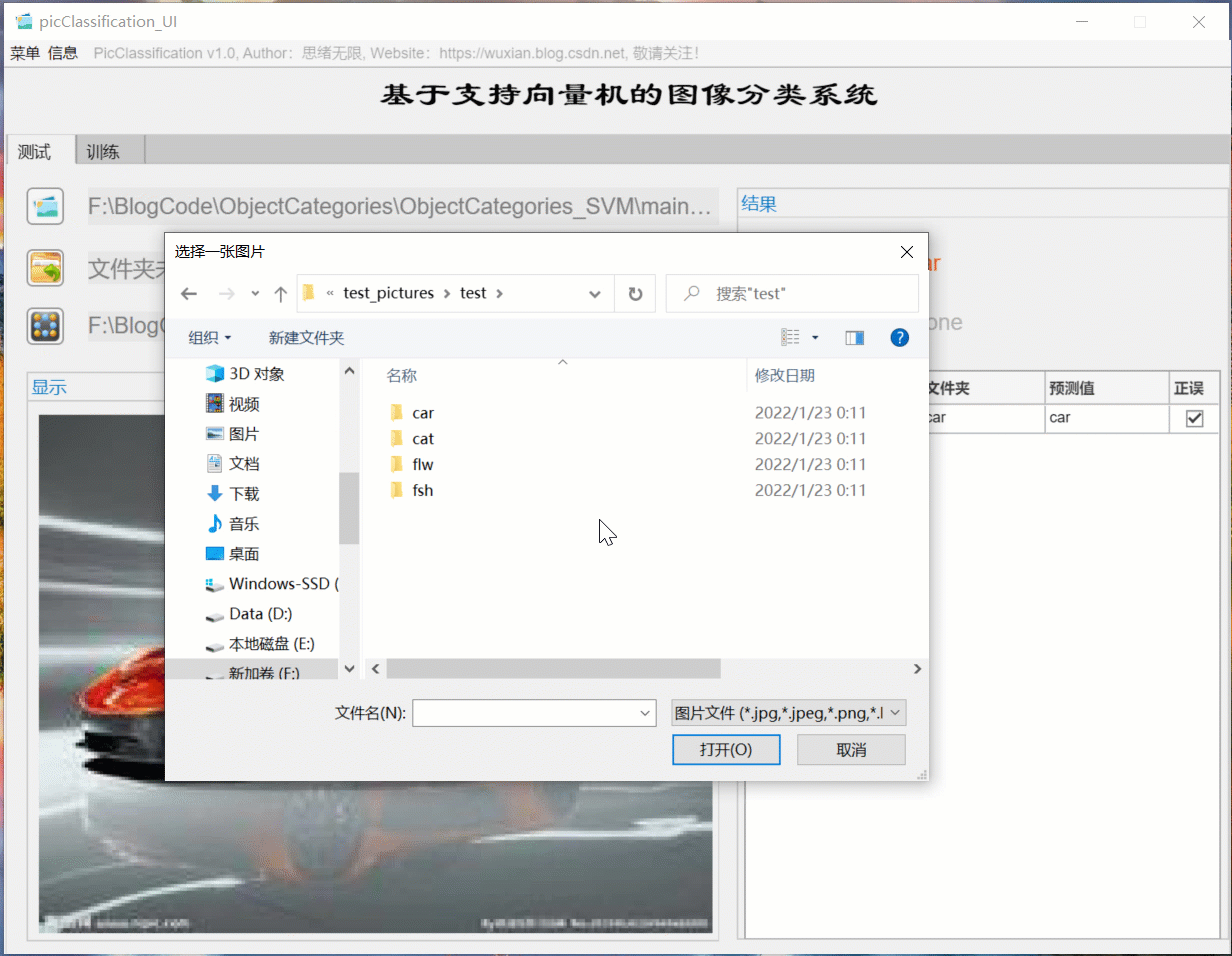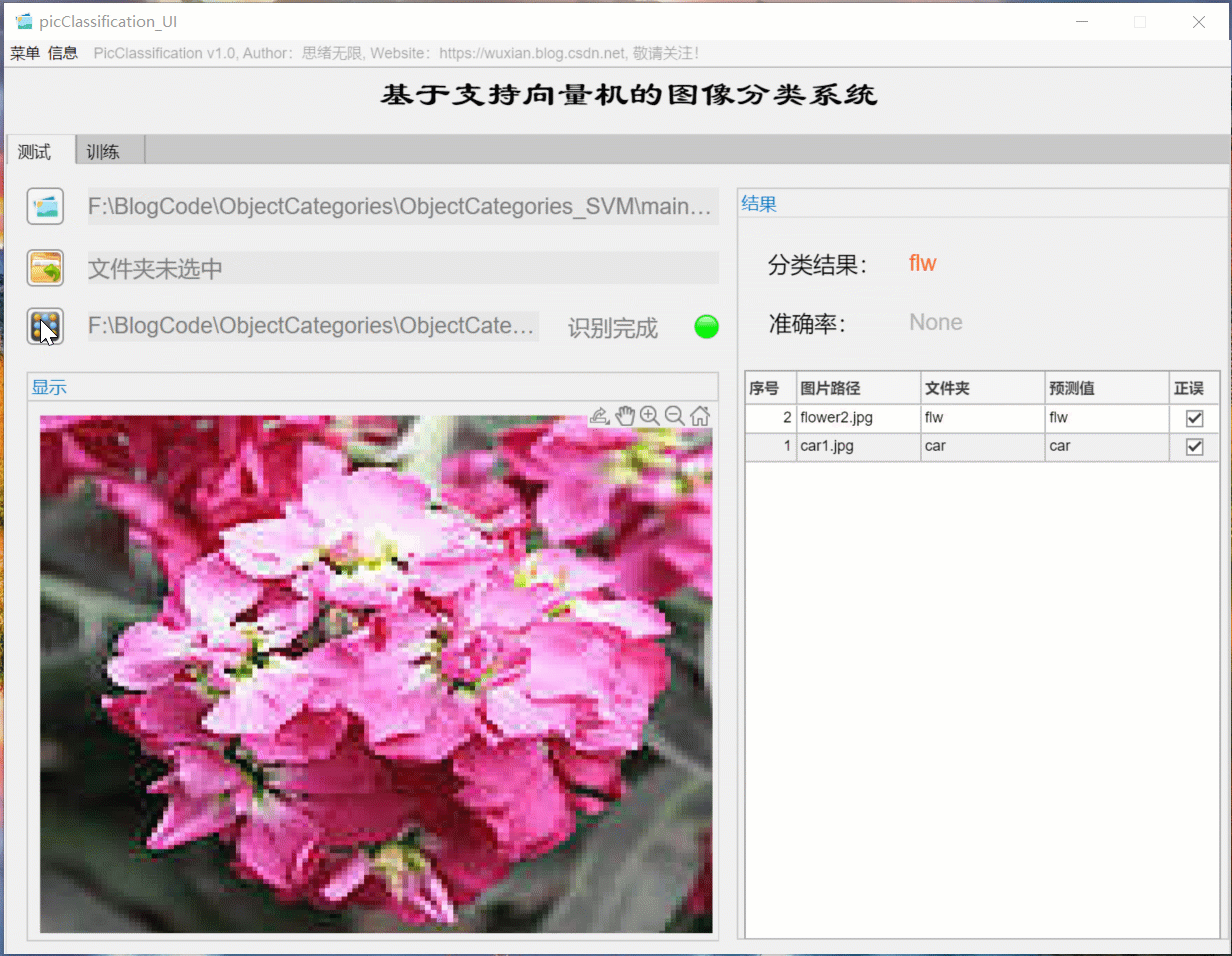
对于需要批量识别的情况,可选择界面中的文件夹按钮,选择一个待测试的图片文件夹,系统自动识别文件夹下的文件并进行分类识别。在此过程中识别结果展示在右侧,包括分类结果、准确率、图片的历史记录。用户可点击右侧的结果记录表格中的对应序号,回看图片以及对应的识别结果,该部分演示如下图所示:
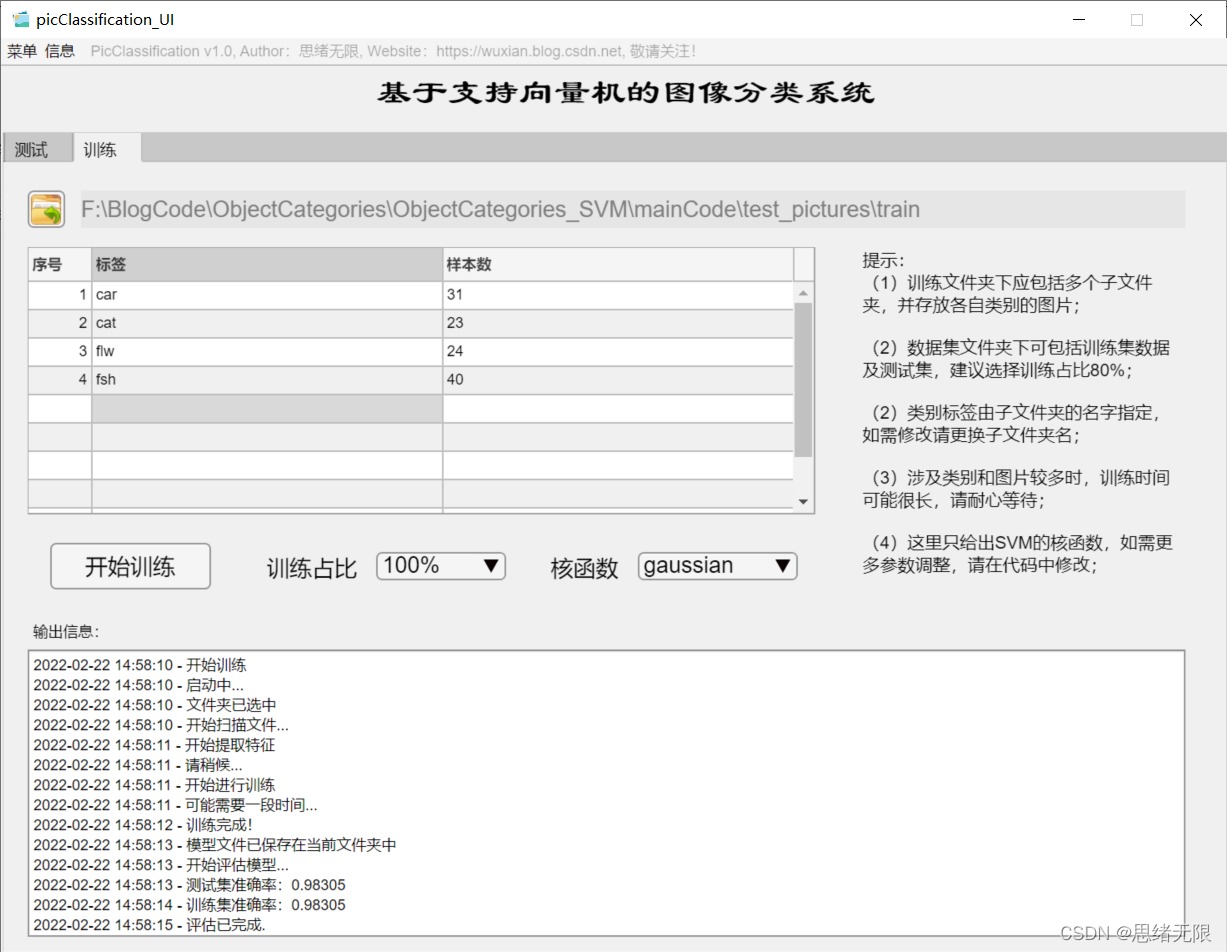
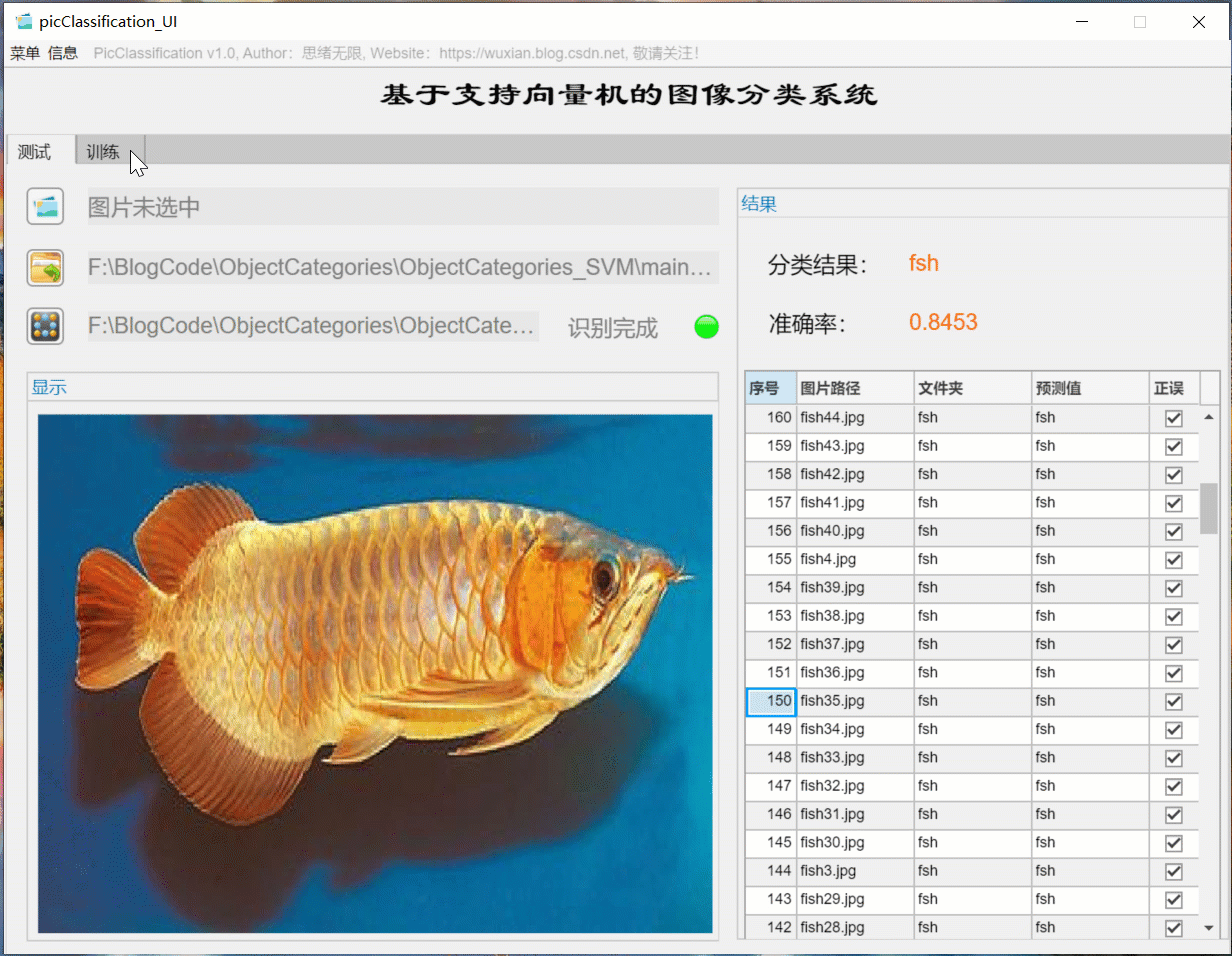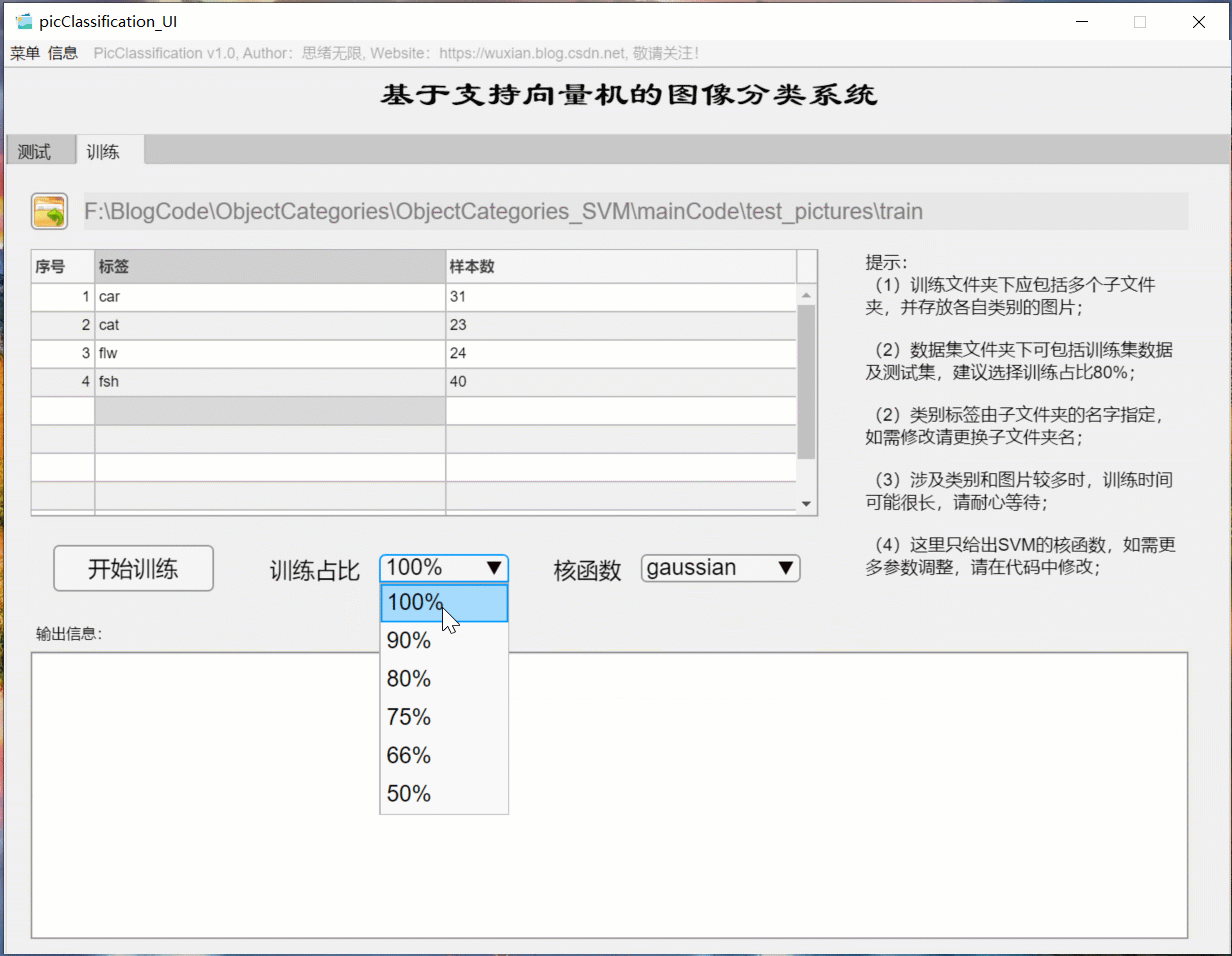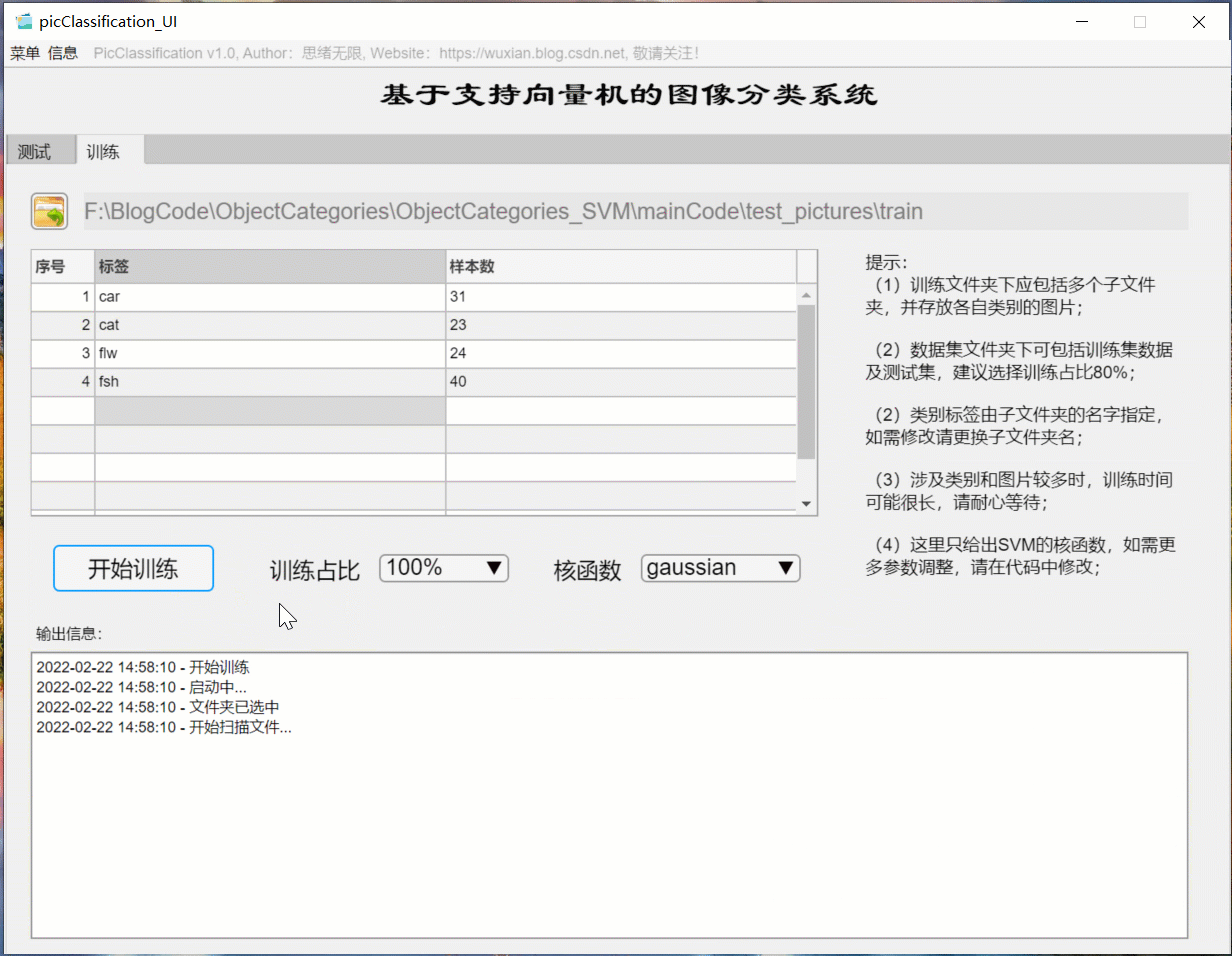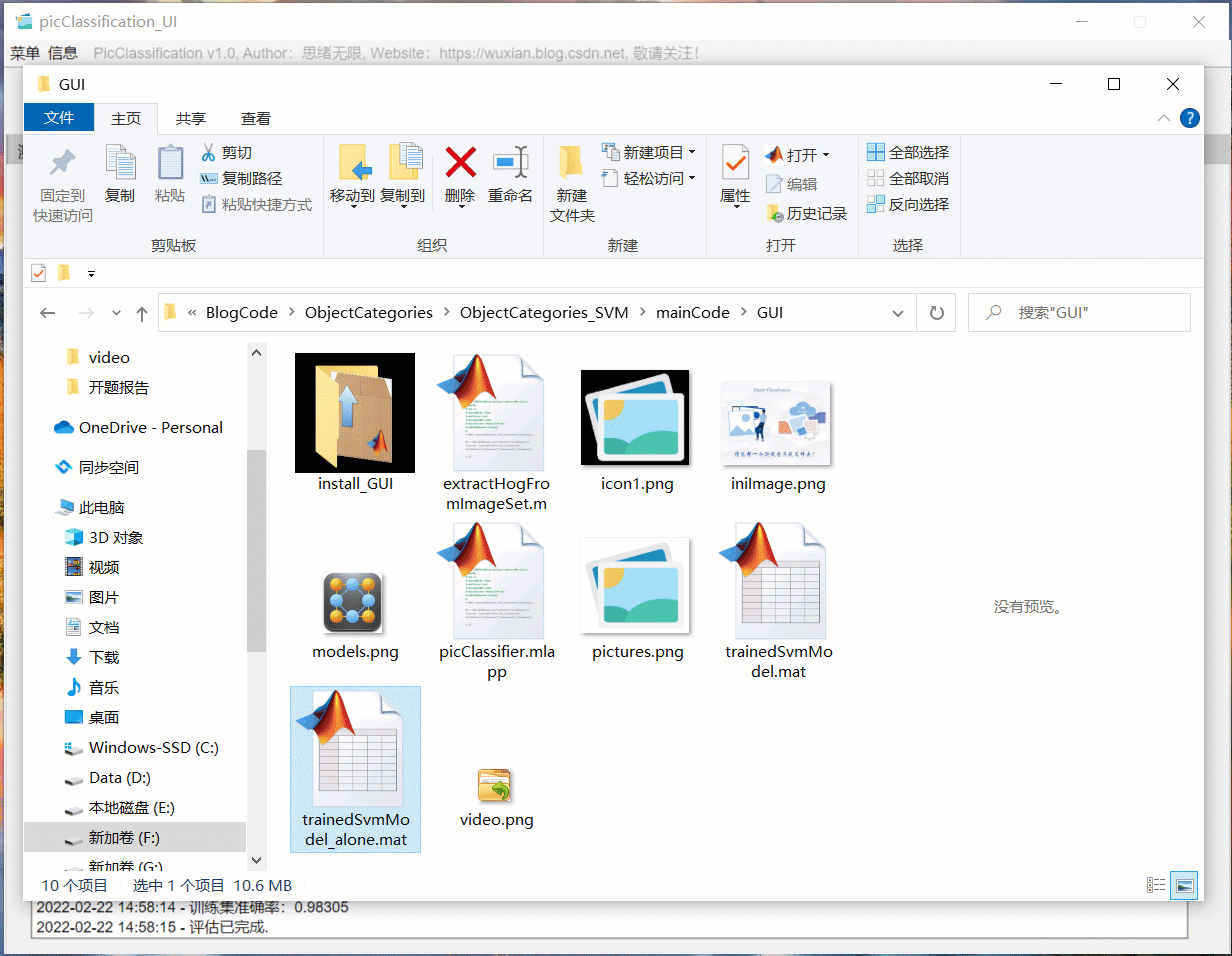
(三)自定义模型训练+参数设置+自动训练
如果想更换数据集并重新训练模型,这时只需要点击“训练”选项卡,可切换至训练界面。如下图所示,可选择一个自定义的图片文件夹,该文件夹下包含多个以类别命名的子文件夹,系统自动将文件夹的名字作为每一类的标签,并将读取的结果显示在界面中。可以选择训练占比和核函数的训练设置,点击“开始训练”即可自动进行训练,训练的过程信息显示在界面上,最终可以得到训练测试集准确率,以及各类别的混淆矩阵结果,模型自动保存在当前文件夹下供后续选择。
提到分类任务的数据集很容易想到ImageNet,它无疑是个巨大的训练图库,对于我们自行训练和测试其实是非常费力的事情(除非你拥有高端设备),所以我并不推荐在学习阶段就使用。至于早前不少论文中广泛使用的CIFAR10 / CIFAR100以及MNIST数据集,它们的尺寸过小,且本身任务比较简单,目前已不在普遍使用(水论文除外)。所以这里我们选择的数据集是更贴近真实情况的Caltech 101数据集,也是当前非常流行的数据集。
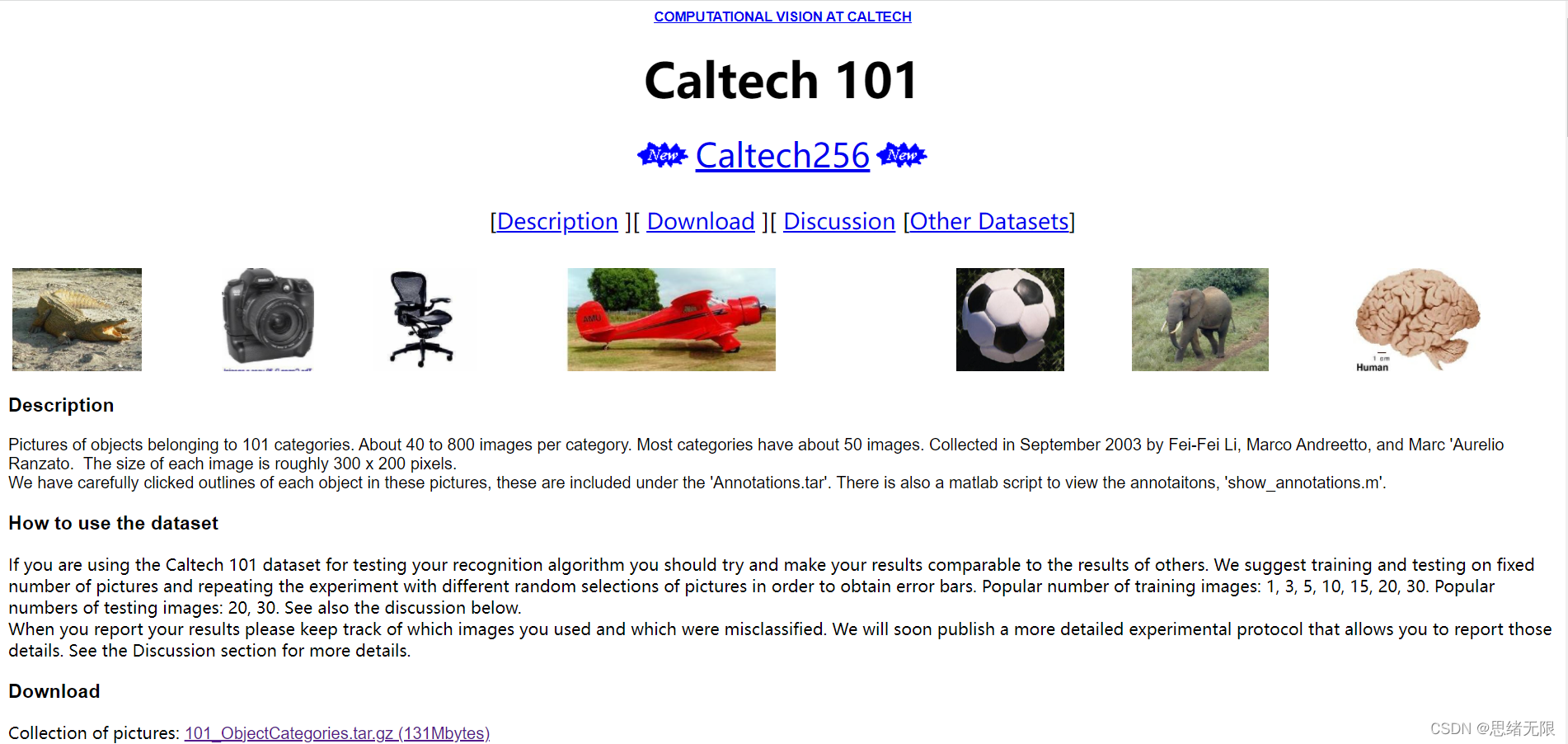
Caltech-101 Dataset是由 101 个类别的对象图片组成的数据集,它主要用于目标识别和图像分类,官网地址为https://www.vision.caltech.edu/Image_Datasets/Caltech101/。该数据集不同类别有 40 至 800 张图片,每张图片的大小在 300 * 200 像素,且数据集的发布者均已标注对应的目标以供使用。该数据集由加州理工学院的李菲菲、马克安德烈托和 Marc’Aurelio Ranzato 于 2003 年 9 月收集,相关论文有《Learning generative visual models from few training examples: an incremental Bayesian approach tested on 101 object categories》、《One-Shot learning of object categories》等。

下载完成后的数据集文件如上图所示,解压后即可看到其中包含101个子文件夹,每个文件夹对应一个类别的图片,文件夹的名字表示对应的标签。由于该数据集文件数目较大,这里选取其中的10类如下图所示,将这几个文件夹复制到新建的文件夹进行实验,最终确定所用的数据集。
数据集准备完毕,现在可以通过文件夹读取图片了。在MATLAB中可使用imageDatastore函数方便地批量读取图片集,它通过递归扫描文件夹目录,将每个文件夹名称自动作为图像的标签,该部分代码如下:
clear
clc
rng default % 保证结果运行一致
mpath = matlab.desktop.editor.getActiveFilename; % 程序所在目录
[pathstr,~]=fileparts(mpath);
cd(pathstr); % 自动切换至程序所在目录
imgDir = fullfile("../10_ObjectCategories/");
% imageDatastore递归扫描目录,将每个文件夹名称自动作为图像的标签
dataSet = imageDatastore(imgDir, 'IncludeSubfolders', true, 'LabelSource', 'foldernames');
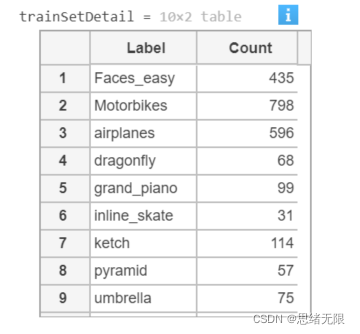
至此读取到的数据集被存放在dataSet变量中,可以简单查看训练和测试集每类标签的样本个数,显示代码如下:
trainSetDetail = countEachLabel(dataSet) % 训练数据
执行以上代码运行结果如下:
这里展示一下读取到的图片,代码如下所示:
figure
imshow(dataSet.Files{520});
执行该代码可以看到如下的运行结果:

这里我们划分训练和测试数据集,使用留一法将80%的数据用于训练,剩余的数据用于模型测试,将训练和测试文件保存在trainSet.Files及testSet.Files变量中,对应的标签则存在Label中,该部分代码如下:
indices = crossvalind('Kfold',dataSet.Labels,5); % 进行交叉验证划分
t=1;
test=(indices == t);
train=~test;
% 训练数据集
trainSet.Files = dataSet.Files(train);
trainSet.Labels = dataSet.Labels(train);
% 测试数据集
testSet.Files = dataSet.Files(test);
testSet.Labels = dataSet.Labels(test);
至此完成数据集的读取和划分工作,接下来进行特征提取步骤。
真正用于训练分类器的数据并不是原始图片数据,而是先经过特征提取后得到的特征向量,这里使用的特征类型是HOG,也就是方向梯度直方图。所以这里重要的一点是正确提取出HOG特征,extractHOGFeatures是MATLAB自带的HOG特征提取函数,该函数不仅可以有效提取特征,还可以返回特征的可视化结果以方便展示。该部分代码如下:
cellSize = [4 4];
img = readimage(dataSet, 23);
img = rgb2gray(img); % 灰度化图片
img = imbinarize(img);
img = imresize(img, [100 100]);
[hog_4x4, vis4x4] = extractHOGFeatures(img,'CellSize',[4 4]);
hogFeatureSize = length(hog_4x4);
% 提取HOG特征
tStart = tic;
[trainFeatures, trainLabels] = extractHogFromImageSet(trainSet, hogFeatureSize, cellSize); % 训练集特征提取
[testFeatures, testLabels] = extractHogFromImageSet(testSet, hogFeatureSize, cellSize); % 测试集特征提取
tEnd = toc(tStart);
fprintf('提取特征所用时间:%.2f秒\n', tEnd);
以上代码首先进行图片灰度化、二值化、尺寸调整等预处理操作,然后调用extractHogFromImageSet函数提取训练和测试集的HOG特征。由于图片数量众多,提取特征过程尚需一定时间,这里对训练集、测试集提取过程进行计时,因计算机算力不同,执行时间可能会不一致,最终打印特征提取所用的时间。
提取特征所用的时间:18.73秒
下面我们使用以上提取的HOG特征构建支持向量机模型,利用提取的训练集特征进行训练。首先利用templateSVM函数构建支持向量机模板参数,选择gaussian核函数,执行标准化处理数据,显示训练过程;利用fitcecoc函数执行训练过程,其代码如下。
% 训练支持向量机
t = templateSVM('SaveSupportVectors',true, 'Standardize', true, 'KernelFunction','gaussian', ...
'KernelScale', 'auto','Verbose', 0); % 利用polynomial核函数, 标准化处理数据,显示训练过程(verbose取0时取消显示)
tStart = tic; % 计时开始
classifier = fitcecoc(trainFeatures, trainLabels, 'Learner', t); % 训练SVM模型
tEnd = toc(tStart);
fprintf('训练模型所用时间:%.2f秒\n', tEnd);
等待训练完成,我们可以使用训练好的分类器进行预测,这里先利用测试集评估模型并计算分类评价指标,对测试集进行预测的代码如下:
tStart = tic;
% 对测试数据集进行预测
predictedLabels = predict(classifier, testFeatures);
tEnd = toc(tStart);
fprintf('模型对测试集进行预测所用时间:%.2f秒\n', tEnd);
运行结果如下:
模型对测试集进行预测所用时间:5.75秒
得到了预测结果,可以使用混淆矩阵评估结果,以下代码首先计算混淆矩阵结果,然后将结果打印出来:
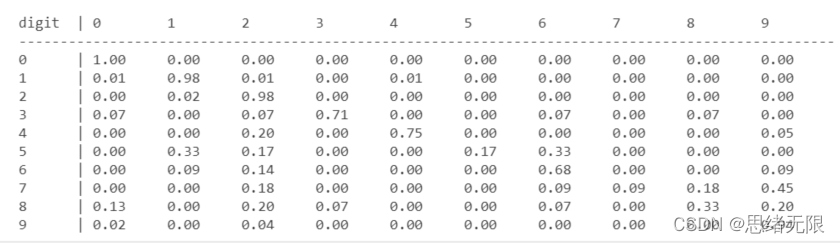
分类准确率可以通过以下代码进行计算:
accuracy = sum(predictedLabels == testLabels) / numel(testLabels);
fprintf('模型在测试集上的准确率:%.0f%%\n', accuracy*100);
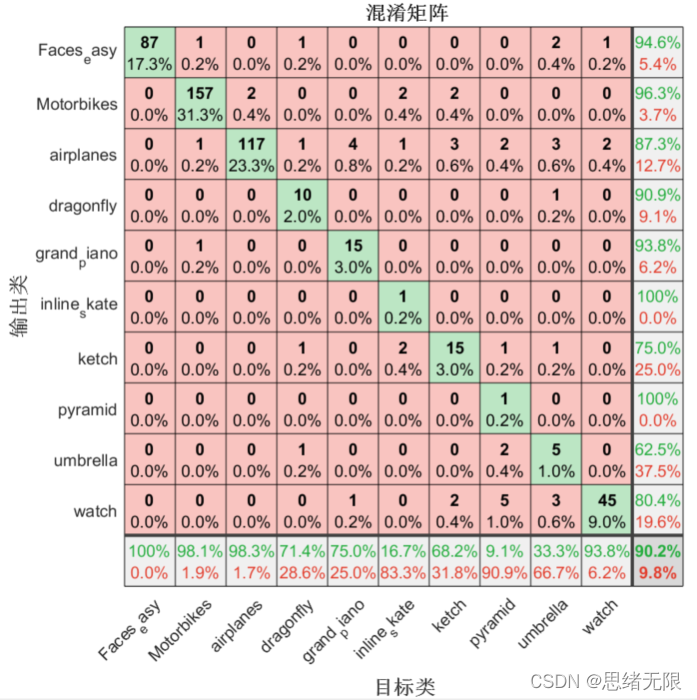
以上代码显示了混淆矩阵的结果,但可能还不够直观,下面绘制混淆矩阵图帮助更好了解模型性能:
% 绘制混淆矩阵图
plotconfusion(testLabels, predictedLabels);
运行代码后显示混淆矩阵图如下图所示,每行对角线上的网格(绿色网格)处显示了某类样本预测正确的数目及其占比。右下角网格表示分类的准确率,可以看出该分类器具有90.2%的总体分类准确率。
为了便于后续测试,这里保存模型文件,其代码如下:
save('trainedSvmModel.mat','classifier');
这里我们选取几张图片进行测试,以便对模型的效果有个更直观的感受,这部分代码如下所示:
clear
clc
rng default % 保证结果运行一致
img_test_1 = imread("../10_ObjectCategories/airplanes/image_0137.jpg");
img_test_2 = imread("../10_ObjectCategories/dragonfly/image_0001.jpg");
img_test_3 = imread("../10_ObjectCategories/inline_skate/image_0003.jpg");
img_test_4 = imread("../10_ObjectCategories/ketch/image_0005.jpg");
img_test_5 = imread("../10_ObjectCategories/Motorbikes/image_0006.jpg");
img_test_6 = imread("../10_ObjectCategories/umbrella/image_0010.jpg");
读取图片后,首先利用imshow函数将几张图片显示出来,采用subplot函数划分图片坐标轴区域,以便将6张图片展示出来:
figure;
subplot(2, 3, 1); imshow(img_test_1);
subplot(2, 3, 2); imshow(img_test_2);
subplot(2, 3, 3); imshow(img_test_3);
subplot(2, 3, 4); imshow(img_test_4);
subplot(2, 3, 5); imshow(img_test_5);
subplot(2, 3, 6); imshow(img_test_6);
执行以上代码,运行结果如下图所示:

与上一章类似,首先提取HOG特征,这里将提取到的特征进行可视化展示,并将其与原始图片进行对比,其代码如下:
img = rgb2gray(img_test_1);
img = imbinarize(img);
% img = imresize(img, [100 100]);
[hog_1, vis_1] = extractHOGFeatures(img,'CellSize',[4 4]);
figure
subplot(2,1,1);
imshow(img_test_1)
title("原始图像")
subplot(2, 1, 2)
plot(vis_1);
title("特征图像")
运行以上代码,特征提取的图像运行结果如下图所示:

接下来我们载入前面训练好的模型,对读取到的图片进行预测并显示结果。值得注意的是,每张图片在预测前的预处理工作,这里通过代码将灰度化、二值化、HOG特征的结果可视化在同一个绘图窗口中,其代码如下:
load("trainedSvmModel.mat", "classifier");
img_gray = rgb2gray(img_test_4);
img_bin = imbinarize(img_gray);
img = imresize(img_bin, [100 100]);
[hog_4, vis_4] = extractHOGFeatures(img,'CellSize',[4 4]);
% 对测试数据集进行预测
fea_4 = extractHOGFeatures(img,'CellSize',[4 4]);
predictedLabels = predict(classifier, fea_4);
fprintf("预测结果:%s",predictedLabels);
figure
subplot(2,2,1)
imshow(img_test_4);
title(["预测结果:", char(predictedLabels)])
subplot(2,2,2)
imshow(img_gray);
subplot(2,2,3)
imshow(img_bin);
subplot(2,2,4)
plot(vis_4)
运行以上代码,显示结果如下:

若您想获得博文中涉及的实现完整全部程序文件(包括数据集,m, UI文件等,如下图),这里已打包上传至博主的面包多平台和CSDN下载资源。本资源已上传至面包多网站和CSDN下载资源频道,可以点击以下链接获取,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
在文件夹下的资源显示如下:
注意:本资源已经过调试通过,下载后可通过MATLAB R2021b运行;训练主程序为main_trainClassifier.mlx,测试程序可运行main_testClassifier.mlx,要使用GUI界面请运行picClassifier.mlapp文件;其它程序文件大部分为函数而非可直接运行的脚本,使用时请勿直接点击运行!➷➷➷
完整资源下载链接1:博主在面包多网站上的完整资源下载页
完整资源下载链接2:https://mbd.pub/o/bread/mbd-YpiTl5ht
注:以上两个链接为面包多平台下载链接,CSDN下载资源频道下载链接稍后上传。
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。
我有带有Logo图像的公司模型has_attached_file:logo我用他们的Logo创建了许多公司。现在,我需要添加新样式has_attached_file:logo,:styles=>{:small=>"30x15>",:medium=>"155x85>"}我是否应该重新上传所有旧数据以重新生成新样式?我不这么认为……或者有什么rake任务可以重新生成样式吗? 最佳答案 参见Thumbnail-Generation.如果rake任务不适合你,你应该能够在控制台中使用一个片段来调用重新处理!关于相关公司
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我正在尝试使用Ruby2.0.0和Rails4.0.0提供的API从imgur中提取图像。我已尝试按照Ruby2.0.0文档中列出的各种方式构建http请求,但均无济于事。代码如下:require'net/http'require'net/https'defimgurheaders={"Authorization"=>"Client-ID"+my_client_id}path="/3/gallery/image/#{img_id}.json"uri=URI("https://api.imgur.com"+path)request,data=Net::HTTP::Get.new(path
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
因为我现在正在做一些时间测量,我想知道是否可以在不使用Benchmark类或命令行实用程序time的情况下测量用户时间或系统时间。使用Time类只显示挂钟时间,而不显示系统和用户时间,但是我正在寻找具有相同灵active的解决方案,例如time=TimeUtility.now#somecodeuser,system,real=TimeUtility.now-time原因是我有点不喜欢Benchmark,因为它不能只返回数字(编辑:我错了-它可以。请参阅下面的答案。)。当然,我可以解析输出,但感觉不对。*NIX系统的time实用程序也应该可以解决我的问题,但我想知道是否已经在Ruby中实
有这样的事吗?我想在Ruby程序中使用它。 最佳答案 试试这个http://csl.sublevel3.org/jp2a/此外,Imagemagick可能还有一些东西 关于ruby-是否有将图像文件转换为ASCII艺术的命令行程序或库?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/6510445/