| 组件安装包 | 软件名称与版本 | 功能 |
|---|---|---|
| Java程序编译运行组件 | JDK 1.8.0_211 | 程序编译运行组件 |
| elasticsearch | 7.1.1 | 日志存储 |
| ik | 7.1.1 | ik分词器 |
| kibana | 7.1.1 | 日志数据图形化展示 |
| logstash | 7.1.1 | 日志处理 |
| filebeat | 7.1.1 | 日志采集 |
注:elasticsearch、logstash、kibana、filebeat、ik安装的版本号必须全部一致。
.
mkdir -p /data/nusp/es/{data,logs}
useradd esUser
chown -R esUser:esGroup /data/nusp/es
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
vm.overcommit_memory = 1
vm.max_map_count=655360
sysctl -p
cd /data/nusp/es
tar -zxvf elasticsearch-7.1.1-linux-x86_64.tar.gz
vim /data/nusp/es/elasticsearch-7.1.1/config/elasticsearch.yml
cluster.name: elkbdp-cluster #集群名称
node.name: elk #节点名称
cluster.initial_master_nodes: ["elk"] #主节点信息
path.data: /data/nusp/es/data #数据存放路径
path.logs: /data/nusp/es/logs #日志存放路径
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0 #所有ip可以访问,
discovery.seed_hosts: ["192.168.11.11","192.168.11.12","192.168.11.13"] #输出至elasticsearch服务器
discovery.zen.minimum_master_nodes: 2 #最多有几个可参与主节点选举
http.cors.enabled: true
http.max_initial_line_length: "1024k"
http.max_header_size: "1024k"
cd /data/nusp/es/elasticsearch-7.1.1/config/
vim jvm.options
-Xms4g
-Xmx4g
ik分词器安装
将准备好的ik分词器安装包解压后将文件复制到 es的安装目录/plugins/ik下面即可,没有目录则自行创建目录,目录文件夹下不能有其他东西。
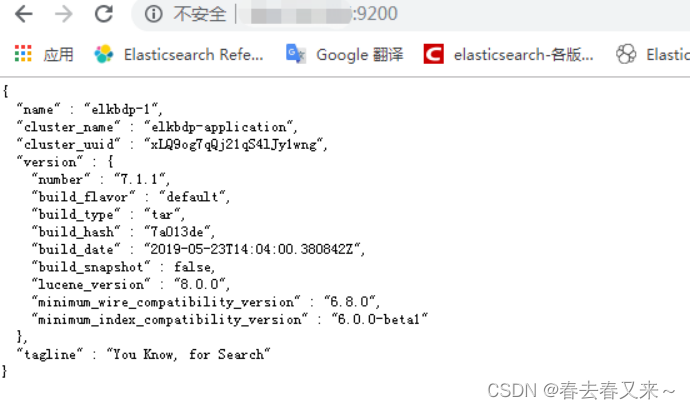
启动es服务,进入es的安装目录/bin下执行(后台启动,无任何错误表示启动完成,此时通过访问http://ip:9200即可)。
./elasticsearch -d
.
以下步骤在一台master上执行即可
cd /data/nusp/es/elasticsearch-7.1.1/bin
./elasticsearch-certutil ca # 两次回车
./elasticsearch-certutil cert --ca elastic-stack-ca.p12 # 三次回车
mkdir /data/nusp/es/elasticsearch-7.1.1/config/certs
mv elastic-*.p12 config/certs/
chown -R elsearch:elsearch config/certs/
vim /data/nusp/es/elasticsearch-7.1.1/config/elasticsearch.yml
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate # 证书认证级别
xpack.security.transport.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: certs/elastic-certificates.p12
kill -9 10086
./elasticsearch -d
bin/elasticsearch-setup-passwords interactive
cd /data/nusp/es
tar -zxvf kibana-7.1.1-linux-x86_64.tar.gz
vim /data/nusp/es/kibana-7.1.1-linux-x86_64/config/kibana.yml
server.port: 5601 #修改绑定ip,使外部可以通过http访问
server.host: "0.0.0.0" ##监听端口,可以不修改
elasticsearch.hosts: ["192.168.11.11","192.168.11.12","192.168.11.13"]
elasticsearch.username: "kibana"
elasticsearch.password: "10086"
./bin/kibana &
通过浏览器访问http://192.168.11.11:5601验证。
登录后顺带验证刚才安装的分词器
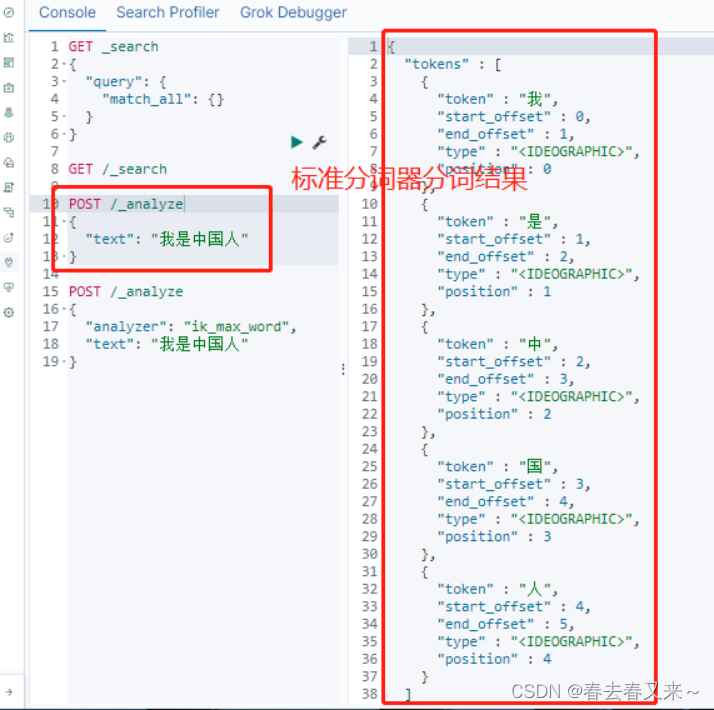
POST /_analyze
{
"text": "我是中国人"
}
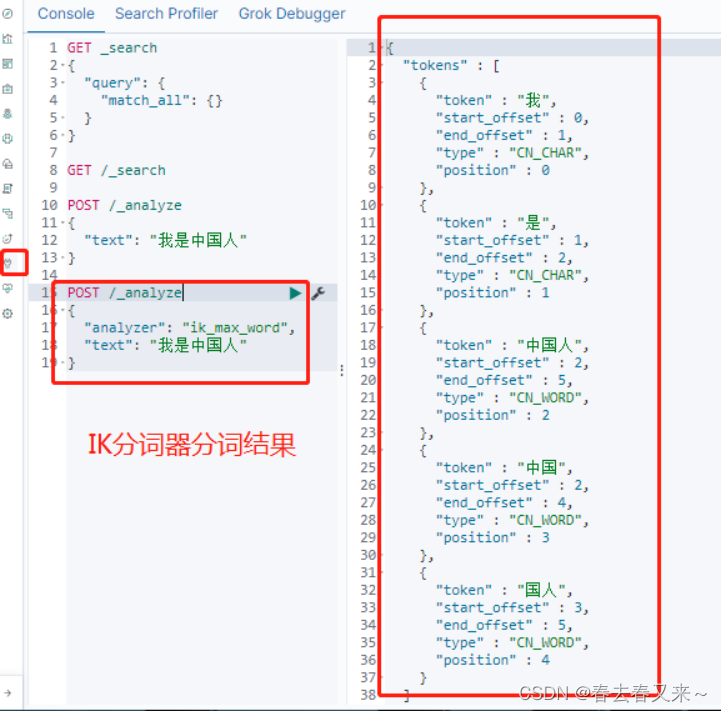
Ik分词器验证脚本
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
.
.
cd /data/nusp/es
tar -xzvf logstash-7.1.1.tar.gz
chown -R esUser:esUser logstash-7.1.1
cd /data/nusp/es/logstash-7.1.1/pipeline
mv /data/nusp/es/logstash-7.1.1/config/logstash-sample.conf .
vim logstash-sample.conf
input {
beats {
port => 5044
}
}
filter {
}
output {
elasticsearch {
hosts => ["192.168.11.11","192.168.11.12","192.168.11.13"]
index => "logstash-dev-%{+YYYY.MM.dd}"
user => "elastic"
password => "10086"
}
stdout { codec => rubydebug }
}
su - esUser
cd /data/nusp/es/logstash-7.1.1/
./bin/logstash -f ./pipeline/logstash-gn.conf > /dev/null &
cd /data/nusp/es/logstash-7.1.1/logs
tail -f logstash-plain.log
.
Filebeat部署在需要采集日志的节点上(如k8s中的master和node节点),由于当前收集的是root用户下的日志,因此filebeat在root用户下安装,否则需要用户具备对/var/log/messages文件以及/var/log/podlog目录的读取权限。
mkdir /data/nusp/es
tar xzvf filebeat-7.1.1-linux-x86_64.tar.gz
mv filebeat-7.1.1-linux-x86_64 filebeat-7.1.1-host
tar xzvf filebeat-7.1.1-linux-x86_64.tar.gz
mv filebeat-7.1.1-linux-x86_64 filebeat-7.1.1-pod
修改filebeat配置文件,将配置文件filebeat-nusplog.yml拷贝到/data/nusp/es/filebeat-7.1.1-pod目录下。将filebeat-hostlog.yml文件拷贝到/data/nusp/es/filebeat-7.1.1-host目录下,注意修改文件中logstash的地址和端口信息,与logstash保持一致,修改如下。
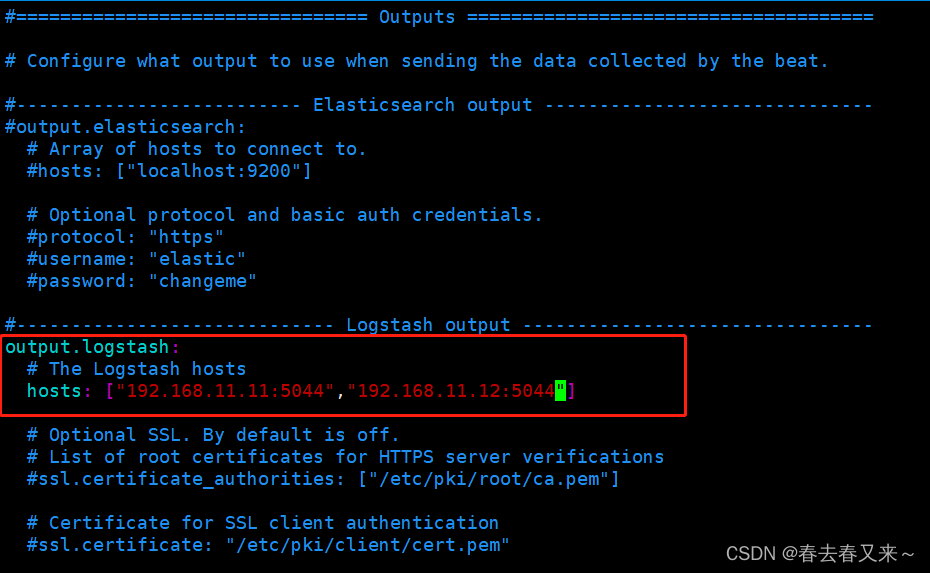
启动filebeat服务并添加权限
这里启动了两个filebeat是因为有两个logstash,如果是一个logstash,启动一个filebeat就可以呢
cd /data/nusp/es/filebeat-7.1.1-host/
chmod 644 filebeat-hostlog.yml
./filebeat -e -c filebeat-hostlog.yml -d publish &
cd /data/nusp/es/filebeat-7.1.1-pod/
chmod 644 filebeat-nusplog.yml
./filebeat -e -c filebeat-nusplog.yml -d publish &
整个流程即为 filebeat采集/var/log/messages和/var/log/podlog目录下的日志数据传输给logstash,logstash接收到数据后经过解析将数据发送给ES集群。
后续如果新增filebeat,则需要在filebeat配置文件中配置logstash地址,logstash配置文件中配置es集群的地址。
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
Ocra无法处理需要“tk”的应用程序require'tk'puts'nope'用奥克拉http://github.com/larsch/ocra不起作用(如链接中的一个问题所述)问题:https://github.com/larsch/ocra/issues/29(Ocra是1.9的"new"rubyscript2exe,本质上它用于将rb脚本部署为可执行文件)唯一的问题似乎是缺少tcl的DLL文件我不认为这是一个问题据我所知,问题是缺少tk的DLL文件如果它们是已知的,则可以在执行ocra时将它们包括在内有没有办法知道tk工作所需的DLL依赖项? 最佳答
我有一个类unzipper.rb,它使用Rubyzip解压文件。在我的本地环境中,我可以成功解压缩文件,而无需使用require'zip'明确包含依赖项但是在Heroku上,我得到一个NameError(uninitializedconstantUnzipper::Zip)我只能通过使用明确的require来解决问题:为什么这在Heroku环境中是必需的,但在本地主机上却不是?我的印象是Rails自动需要所有gem。app/services/unzipper.rbrequire'zip'#OnlyrequiredforHeroku.Workslocallywithout!class
出于某种原因,heroku尝试要求dm-sqlite-adapter,即使它应该在这里使用Postgres。请注意,这发生在我打开任何URL时-而不是在gitpush本身期间。我构建了一个默认的Facebook应用程序。gem文件:source:gemcuttergem"foreman"gem"sinatra"gem"mogli"gem"json"gem"httparty"gem"thin"gem"data_mapper"gem"heroku"group:productiondogem"pg"gem"dm-postgres-adapter"endgroup:development,:t
我已经开始学习Ruby,我已经阅读了一些教程,甚至还买了一本书(“ProgrammingRuby1.9-ThePragmaticProgrammers'Guide”),我遇到了一些以前从未见过的新东西使用我知道的任何其他语言(我是一名PHP网络开发人员)。block和过程。我想我明白它们是什么,但我不明白的是为什么它们如此伟大,以及我应该在何时何地使用它们。我到处都看到他们说block和过程是Ruby中的一个很棒的特性,但我不理解它们。这里有人能给像我这样的Ruby新手一些解释吗? 最佳答案 block有很多好处。电梯演讲:bloc
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva