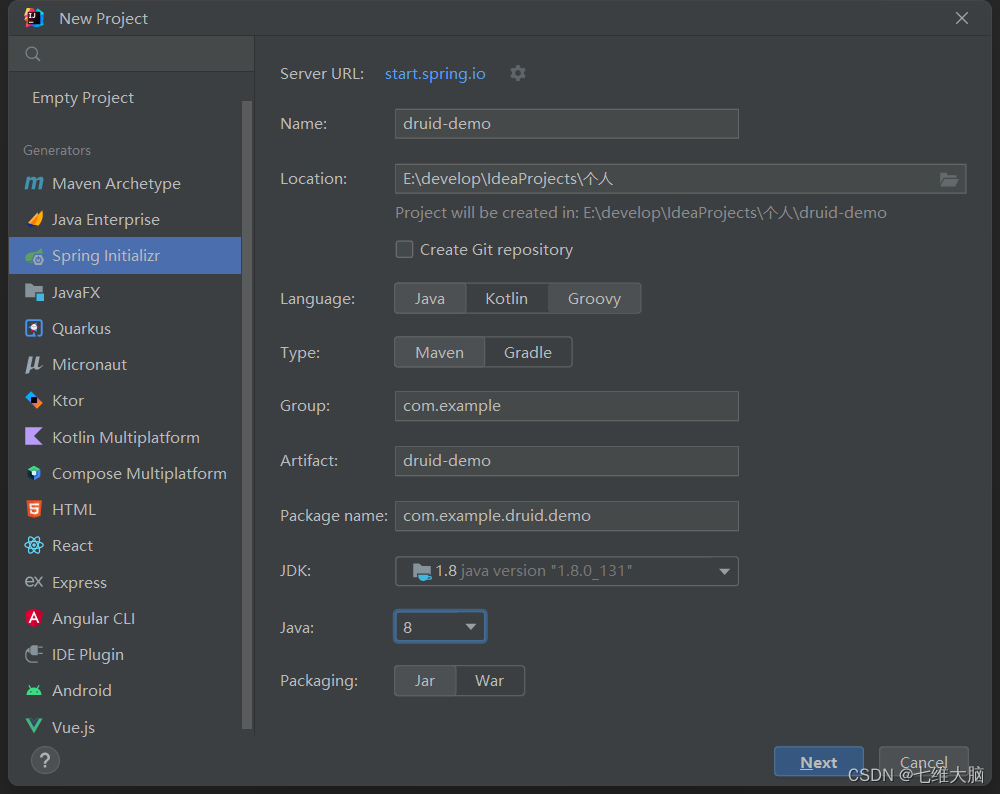
这里使用 IntelliJ IDEA 2022.1.2 演示
个人认为IDEA 用新不用旧,老有人说新版本bug多,其实呢,正在用的时候我是感知不到,相反他会在新版本修复老版本的bug,我觉得新版更好用更智能。如果你也深有其感,去拥抱新版本吧!
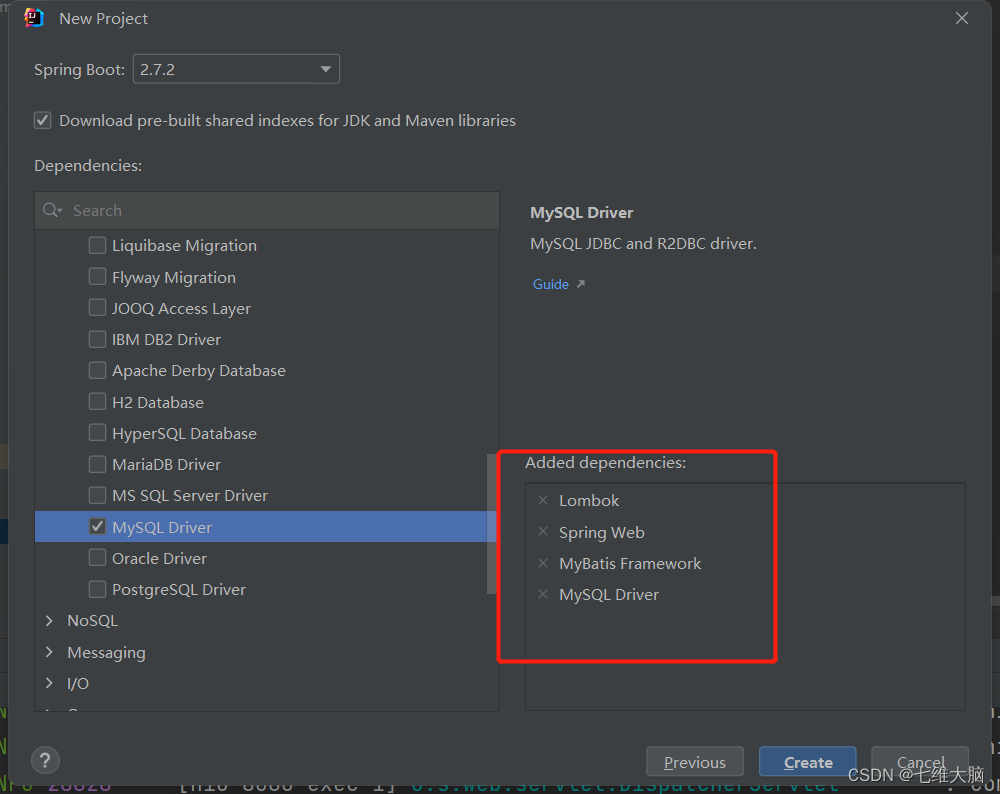
<!-- druid数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.11</version>
</dependency>
一般我习惯把数据库相关的配置单独写一个配置文件中,然后使用spring.profiles.active 配置,启用只能配置文件,比如 application-druid.yml。
# Spring配置
spring:
# 启用指定配置文件
#(文件名需满足application-{profile}.yml的格式)
profiles:
active: druid
spring:
datasource:
#1.JDBC
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/test_db?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=GMT%2B8
username: root
password: ok
druid:
#2.连接池配置
#初始化连接池的连接数量 大小,最小,最大
initial-size: 5
min-idle: 5
max-active: 20
#配置获取连接等待超时的时间
max-wait: 60000
#配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 30000
validation-query: SELECT 1 FROM DUAL
test-while-idle: true
test-on-borrow: true
test-on-return: false
# 是否缓存preparedStatement,也就是PSCache 官方建议MySQL下建议关闭 个人建议如果想用SQL防火墙 建议打开
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filter:
stat:
merge-sql: true
slow-sql-millis: 5000
#3.基础监控配置
web-stat-filter:
enabled: true
url-pattern: /*
#设置不统计哪些URL
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"
session-stat-enable: true
session-stat-max-count: 100
stat-view-servlet:
enabled: true
# 数据监控访问路径
url-pattern: /druid/*
reset-enable: true
#设置监控页面的登录名和密码
login-username: admin
login-password: admin
allow: 127.0.0.1
#deny: 192.168.1.100
地址即是druid.yml中配置的地址:http://localhost:8080/druid/login.html
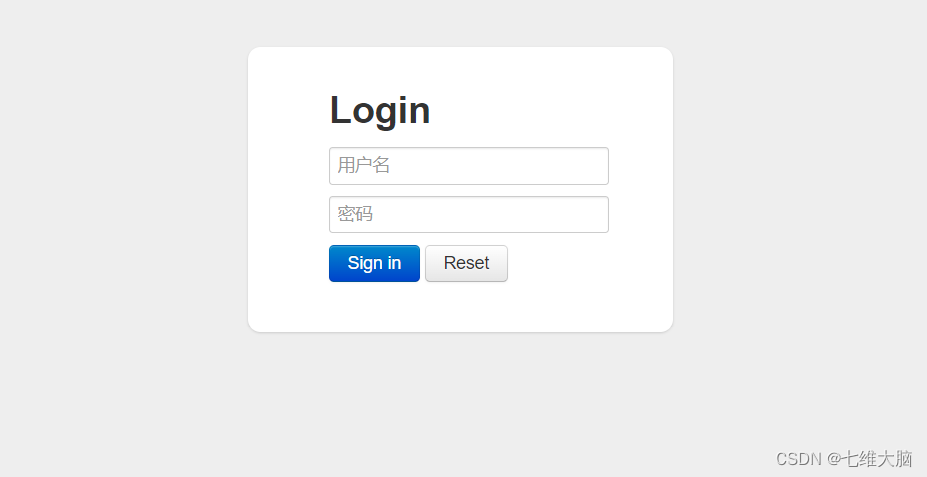
账号密码即是druid.yml中配置的账号密码:admin,admin
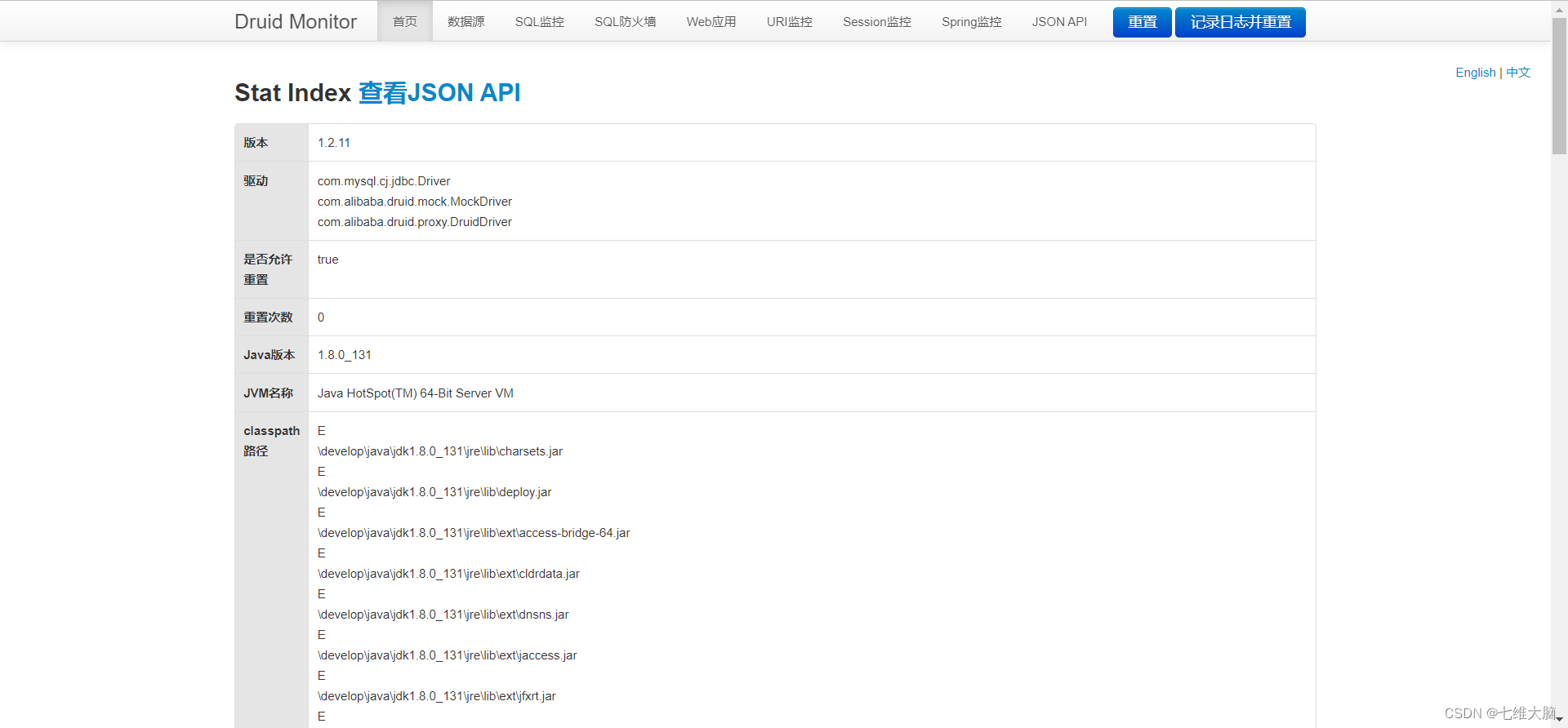
到此其实关于整合Druid就结束了,正常的去写业务代码即可。
接下来再演示下整合Mybatis吧。
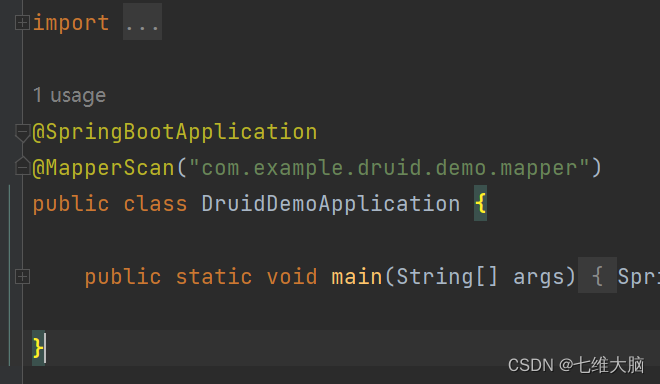
在启动类上添加@MapperScan注解,精确到mapper的位置。
如果不添加这个注解,则需要每个Mapper接口类都添加@Mapper注解比较麻烦。所以直接在启动类上配置批量扫描即可。
# MyBatis配置
mybatis:
# 搜索指定包别名
typeAliasesPackage: com.example.**.domain
# 配置mapper的扫描,找到所有的mapper.xml映射文件
mapperLocations: classpath*:mapper/**/*Mapper.xml
# 加载全局的配置文件(没有可注释掉或删除)
#configLocation: classpath:mybatis/mybatis-config.xml
package com.example.druid.demo.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.example.druid.demo.domain.UserTest;
import com.example.druid.demo.service.IUserTestService;
/**
* demoController
*
* @author 肥猫
* @date 2022-07-25
*/
@RestController
@RequestMapping("/user/demo")
public class UserTestController
{
@Autowired
private IUserTestService userTestService;
/**
* 获取用户详细信息demo (仅演示功能,返回类型随便写的,不要照抄!)
*/
@GetMapping(value = "/{id}")
public UserTest getInfo(@PathVariable("id") Long id)
{
return userTestService.selectUserTestById(id);
}
}
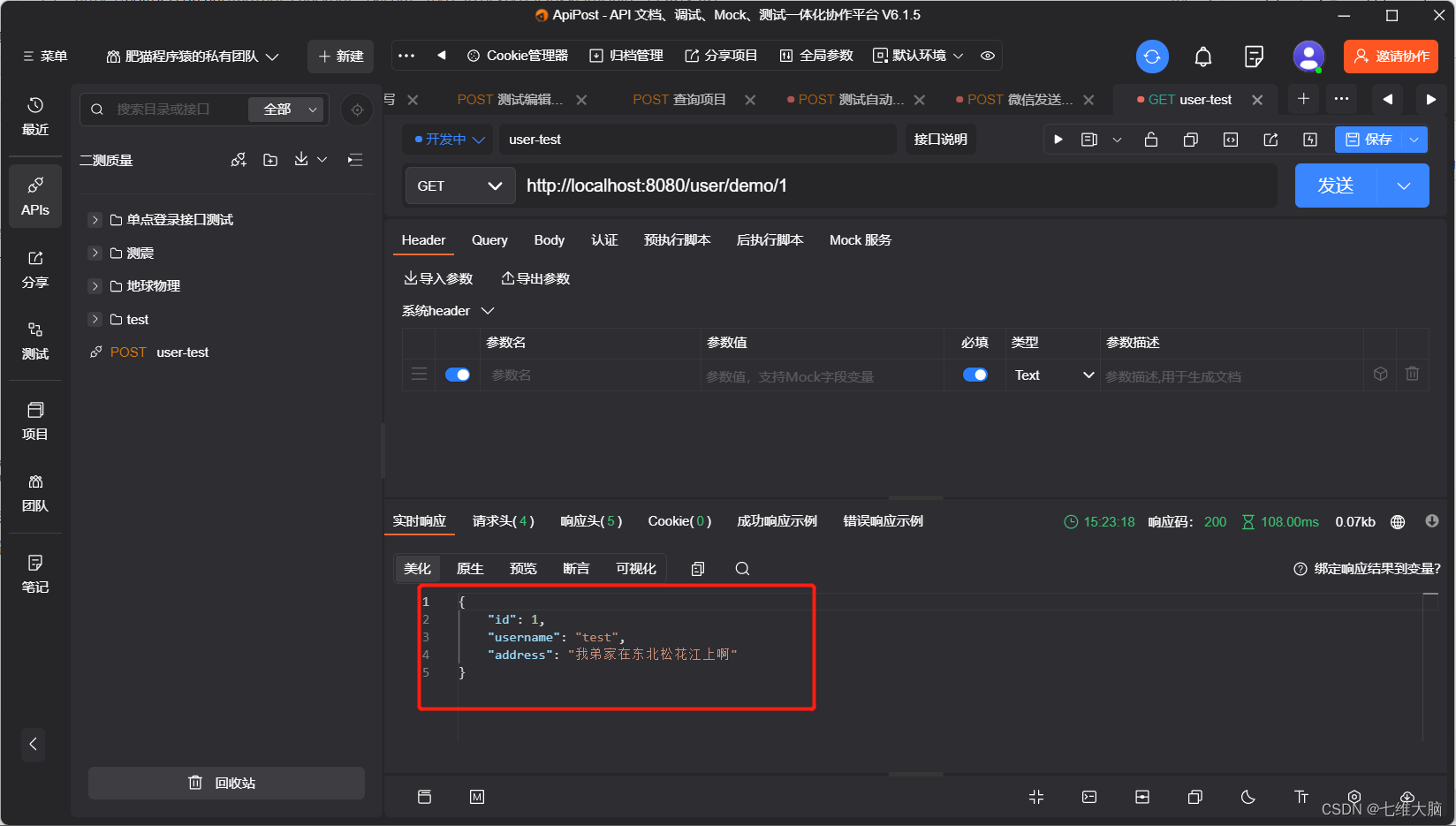
ApiPost测试结果
ApiPost国人研发的类似PostMan又比PostMan更智能的工具。很喜爱。
具体的业务代码就不拿出来了。都太简单了。主要的配置讲清楚就可以了。
算了有朋友需要,我上传到了网盘一份,需要下载: https://www.aliyundrive.com/s/ThxsHb76yEr
如果您希望在Spring中启用定时任务功能,则需要在主类上添加 @EnableScheduling 注解。这样Spring才会扫描 @Scheduled 注解并执行定时任务。在大多数情况下,只需要在主类上添加 @EnableScheduling 注解即可,不需要在Service层或其他类中再次添加。以下是一个示例,演示如何在SpringBoot中启用定时任务功能:@SpringBootApplication@EnableSchedulingpublicclassApplication{publicstaticvoidmain(String[]args){SpringApplication.ru
软件特点部署后能通过浏览器查看线上日志。支持Linux、Windows服务器。采用随机读取的方式,支持大文件的读取。支持实时打印新增的日志(类终端)。支持日志搜索。使用手册基本页面配置路径配置日志所在的目录,配置后按回车键生效,下拉框选择日志名称。选择日志后点击生效,即可加载日志。windows路径E:\java\project\log-view\logslinux路径/usr/local/XX历史模式历史模式下,不会读取新增的日志。针对历史文件可以分页读取,配置分页大小、跳转。历史模式下,支持根据关键词搜索。目前搜索引擎使用的是jdk自带类库,搜索速度相对较低,优点是比较简单。2G日志全文搜
1.依赖导入org.springframework.bootspring-boot-starter-weborg.springframework.bootspring-boot-starter-validation2.validation常用注解@Null被注释的元素必须为null@NotNull被注释的元素不能为null,可以为空字符串@AssertTrue被注释的元素必须为true@AssertFalse被注释的元素必须为false@Min(value)被注释的元素必须是一个数字,其值必须大于等于指定的最小值@Max(value)被注释的元素必须是一个数字,其值必须小于等于指定的最大值@D
我正在尝试找到一种更好的方法将IRB与我的常规ruby开发集成。目前我很少在我的代码中使用IRB。我只用它来验证语法或尝试一些小的东西。我知道我可以将我自己的代码加载到ruby中作为一个require'mycode'但这通常不符合我的编程风格。有时我要检查的变量超出范围或在循环内。有没有一种简单的方法可以启动我的脚本并在IRB内的某个点卡住?我想我正在寻找一种更简单的方法来调试我的ruby代码而不破坏我的F5(编译)键。也许有经验的ruby开发者可以和我分享一个更精简的开发方法。 最佳答案 安装ruby-debugg
我开始了一个小型网络项目并使用Drupal来构建它。到目前为止,还不错:您可以快速建立一个不错的面向CMS的网站,通过模块添加社交功能,并且您有一个广泛的API可以在一个架构良好的平台中进行自定义。现在问题来了:网站的增长超出了最初的计划,我发现自己正处于认真开始为它编写代码的境地。由于Drupal项目,我对PHP有了新的认识,但我想用Ruby来做。我会感觉更舒服,以后维护起来更容易,我可以在其他Ruby/Rails应用程序中重用它。随着时间的推移,我想我会用Ruby重写Drupal中的现有部分。基于此,问题是:是否有人将两者(成功或失败的故事)结合起来?这是一个相当大的决定,但我在G
Iparking停车收费管理系统-可商用介绍Iparking是一款基于springBoot的停车收费管理系统,支持封闭车场和路边车场,支持微信支付宝多种支付渠道,支持多种硬件,涵盖了停车场管理系统的所有基础功能。技术栈Springboot,MybatisPlus,Beetl,Mysql,Redis,RabbitMQ,UniApp功能云端功能序号模块功能描述1系统管理菜单管理配置系统菜单2系统管理组织管理管理组织机构3系统管理角色管理配置系统角色,包含数据权限和功能权限配置4系统管理用户管理管理后台用户5系统管理租户管理多租户管理6系统管理公众号配置租户公众号配置7系统管理操作日志审计日志8系统
一、Elasticsearch简介实际业务场景中,多端的查询功能都有很大的优化空间。常见的处理方式有:建索引、建物化视图简化查询逻辑、DB层之上建立缓存、分页…然而随着业务数据量的不断增多,总有那么一张表或一个业务,是无法通过常规的处理方式来缩短查询时间的。在查询功能优化上,作为开发人员应该站在公司的角度,本着优化客户体验的目的去寻找解决方案。本人有幸做过Tomcat整合solr,今天一起研究一下当前比较火热的Elasticsearch搜索引擎。Elasticsearch是一个非常强大的搜索引擎。它目前被广泛地使用于各个IT公司。Elasticsearch是由Elastic公司创建。它的代码位
场景在SpringBoot项目中需要对接三方系统,对接协议是TCP,需实现一个TCP客户端接收服务端发送的数据并按照16进制进行解析数据,然后对数据进行过滤,将指定类型的数据通过mybatis存储进mysql数据库中。并且当tcp服务端断连时,tcp客户端能定时检测并发起重连。全流程效果 注:博客:霸道流氓气质的博客_CSDN博客-C#,架构之路,SpringBoot领域博主实现1、SpringBoot+Netty实现TCP客户端本篇参考如下博客,在如下博客基础上进行修改Springboot+Netty搭建基于TCP协议的客户端(二):https://www.cnblogs.com/haolb
一、SpringBoot是什么SpringBoot是依赖于Spring的,比起Spring,除了拥有Spring的全部功能以外,SpringBoot无需繁琐的Xml配置,这取决于它自身强大的自动装配功能;并且自身已嵌入Tomcat、Jetty等web容器,集成了SpringMvc,使得SpringBoot可以直接运行,不需要额外的容器,提供了一些大型项目中常见的非功能性特性,如嵌入式服务器、安全、指标,健康检测、外部配置等,其实Spring大家都知道,Boot是启动的意思。所以,SpringBoot其实就是一个启动Spring项目的一个工具而已,总而言之,SpringBoot是一个服务于框架的
一、引入依赖:dependency>groupId>org.springframework.bootgroupId>artifactId>spring-boot-starter-websocketartifactId>2.7.1-->dependency>二、准备工具类:/***@authorWeiDaPang*/@ConfigurationpublicclassScheduledConfiguration{@BeanpublicTaskSchedulertaskScheduler(){ThreadPoolTaskSchedulertaskScheduler=newThreadPoolTask