 2020年初,小红书首页 UI 的复杂度显著提升,在优化布局 xml 和使用一些 stub 方式的同时,我们也在寻找一些成本更低、性能更好的方式。X2C 是当时业界熟知的一种优化方式,其原理是编译期将 xml 翻译成代码,可以有效避免反射以及读取资源文件的损耗。由于小红书 APP 中存在着很多自定义 View 的场景,X2C 同时也会带来较高的维护成本。经过对 LayoutInflater 耗时的深入分析,我们找到了可以兼容各种 View 场景的 APT 方案。这一方案既避免了反射所带来的损耗,也不会增加额外的维护成本,成为了一个开箱即用的工具。
2020年初,小红书首页 UI 的复杂度显著提升,在优化布局 xml 和使用一些 stub 方式的同时,我们也在寻找一些成本更低、性能更好的方式。X2C 是当时业界熟知的一种优化方式,其原理是编译期将 xml 翻译成代码,可以有效避免反射以及读取资源文件的损耗。由于小红书 APP 中存在着很多自定义 View 的场景,X2C 同时也会带来较高的维护成本。经过对 LayoutInflater 耗时的深入分析,我们找到了可以兼容各种 View 场景的 APT 方案。这一方案既避免了反射所带来的损耗,也不会增加额外的维护成本,成为了一个开箱即用的工具。 ViewCompiler 在 Android Q(Android 10)的时候被引入,目前来说也还是一个实验性质的工具,因此我们平时并没有办法使用它。下图为Android S(Android 12)中的源码,大家可以看到这项功能未被开启。
ViewCompiler 在 Android Q(Android 10)的时候被引入,目前来说也还是一个实验性质的工具,因此我们平时并没有办法使用它。下图为Android S(Android 12)中的源码,大家可以看到这项功能未被开启。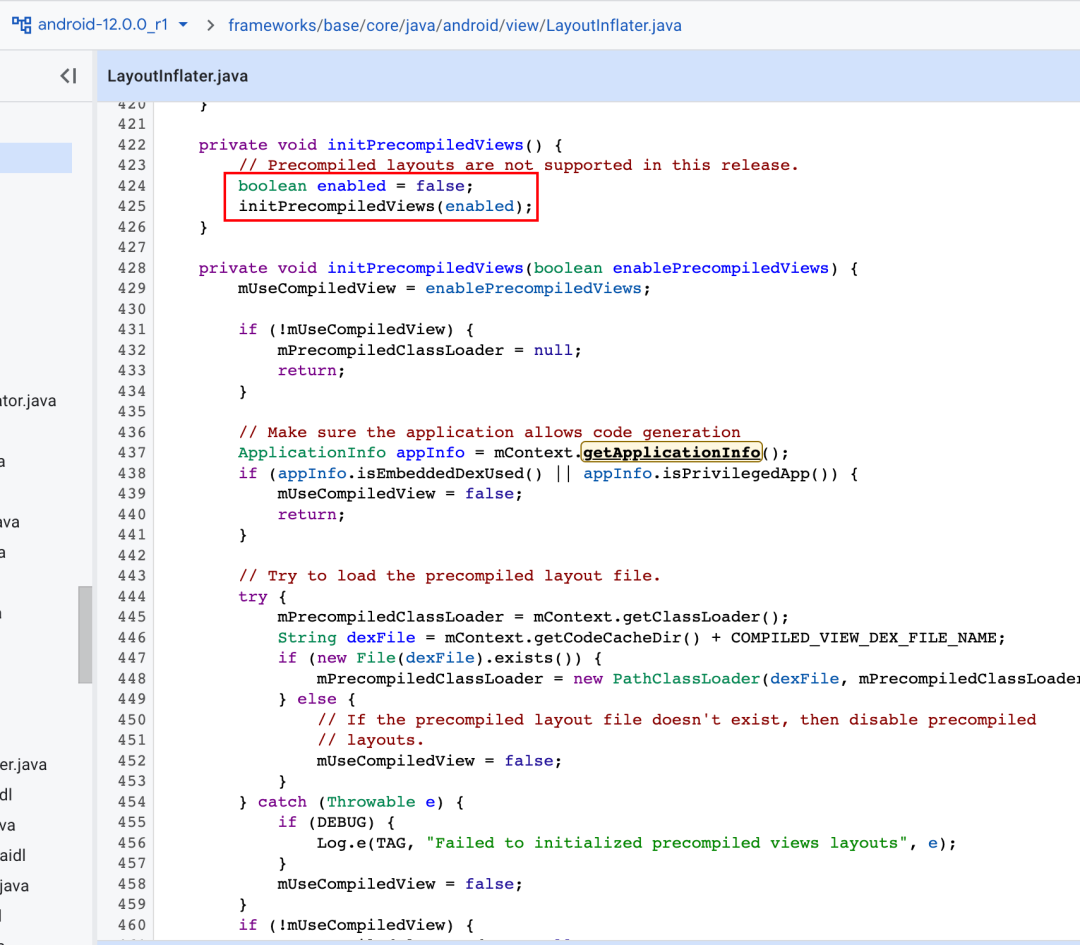 其原理也很简单,先生成一个模板代码片段,然后再生成遍历 xml 的逻辑代码。
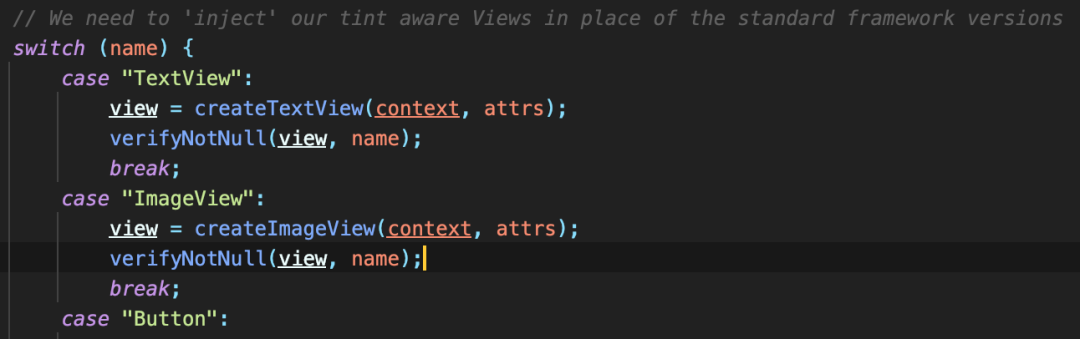
其原理也很简单,先生成一个模板代码片段,然后再生成遍历 xml 的逻辑代码。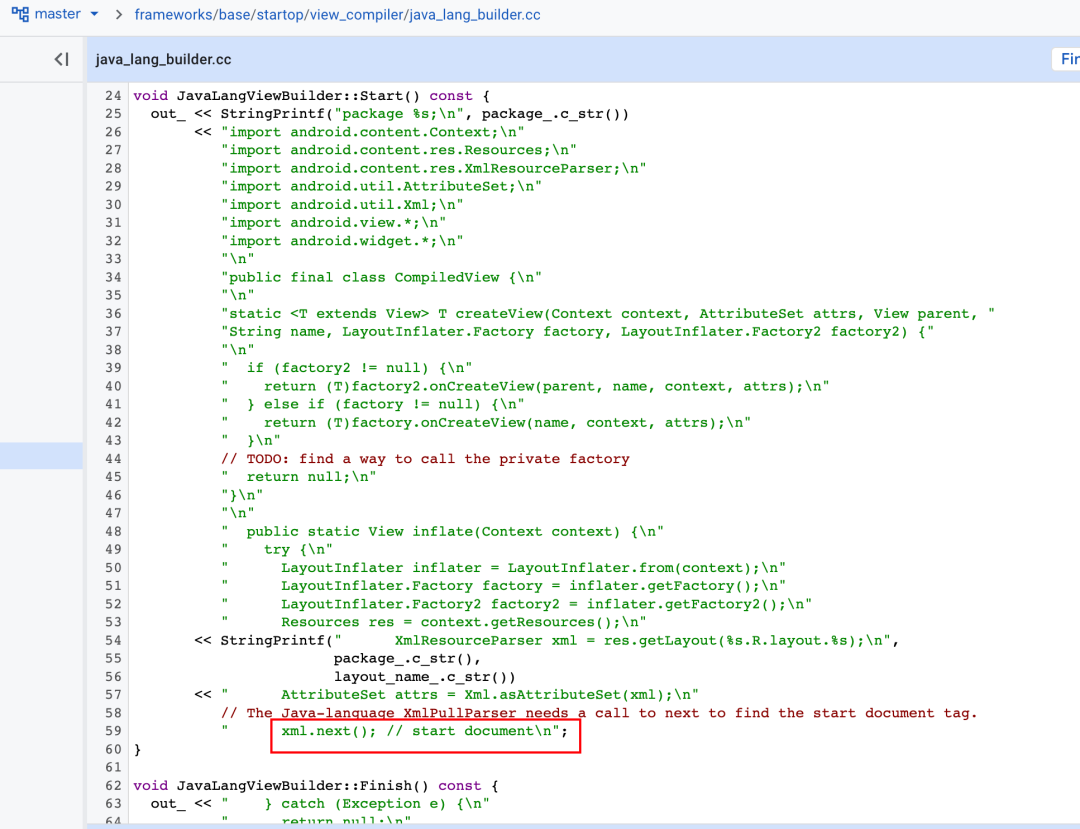 这样做的主要好处是可以节省掉反射带来的时间消耗,官方在 AppCompatViewInflater 中已经处理了原生 View 的创建,通过直接匹配名称 new 对象,避免了使用反射造成的性能开销。
这样做的主要好处是可以节省掉反射带来的时间消耗,官方在 AppCompatViewInflater 中已经处理了原生 View 的创建,通过直接匹配名称 new 对象,避免了使用反射造成的性能开销。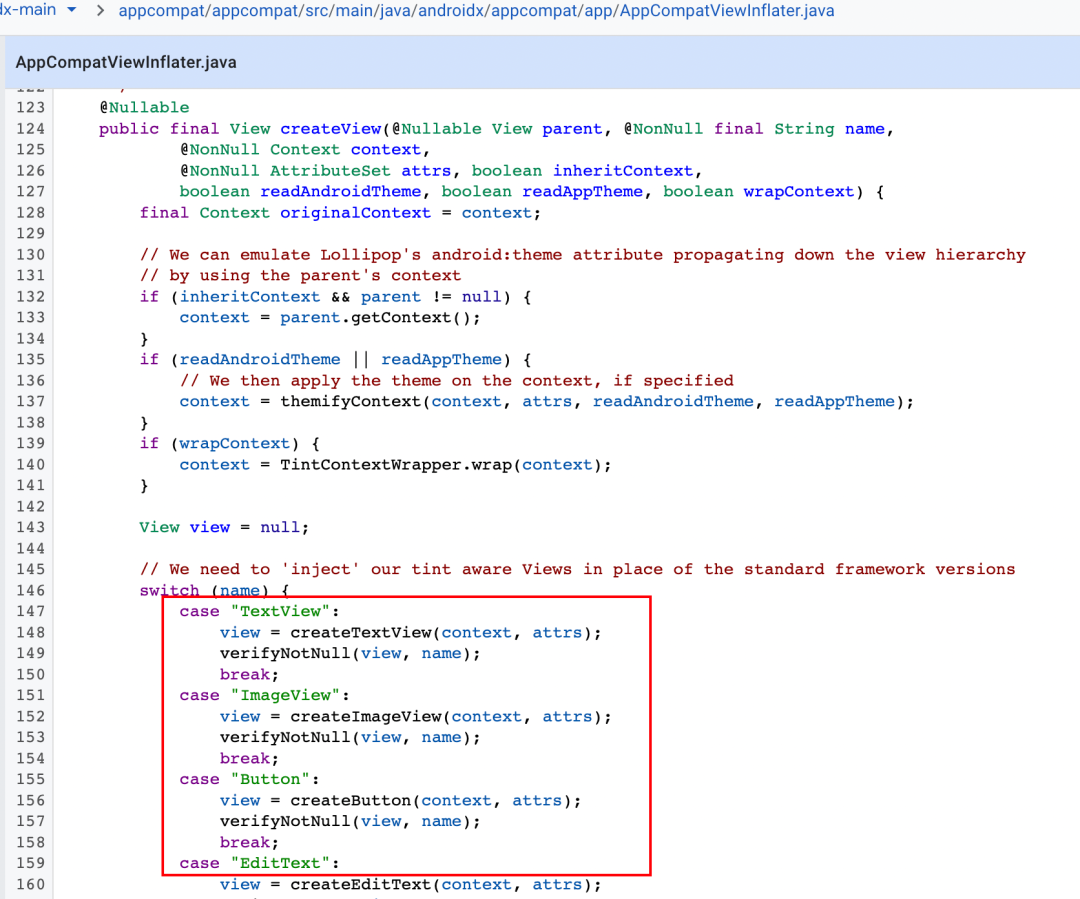
 在日常使用中,反射性能开销主要集中在自定义
View 这部分,我们的 App 本身就是一个自定义 View 非常多的场景,所以天然适合这种 VIewCompiler
的这种方式。同时,因为在遍历 xml 的时候,每一个 attrs 都会遍历到,所以它在维护性上也有着巨大的优势,我们不需要对自定义的 attrs
做任何处理。基于对
X2C 和 ViewCompiler 的源码和生成代码的阅读,我们决定做一个可以生成 Kotlin 代码,同时也解决 ViewCompiler
不支持的 include 和 merge 两个标签。我们用到的工具比较常规,有 kapt 和 kotlinpoet,整体的思路是通过
Resources.getLayout 取到 XmlResourceParser,然后通过 parser 的不断 next 来遍历每一个 xml
中的 tag,生成的代码示意如下:
在日常使用中,反射性能开销主要集中在自定义
View 这部分,我们的 App 本身就是一个自定义 View 非常多的场景,所以天然适合这种 VIewCompiler
的这种方式。同时,因为在遍历 xml 的时候,每一个 attrs 都会遍历到,所以它在维护性上也有着巨大的优势,我们不需要对自定义的 attrs
做任何处理。基于对
X2C 和 ViewCompiler 的源码和生成代码的阅读,我们决定做一个可以生成 Kotlin 代码,同时也解决 ViewCompiler
不支持的 include 和 merge 两个标签。我们用到的工具比较常规,有 kapt 和 kotlinpoet,整体的思路是通过
Resources.getLayout 取到 XmlResourceParser,然后通过 parser 的不断 next 来遍历每一个 xml
中的 tag,生成的代码示意如下: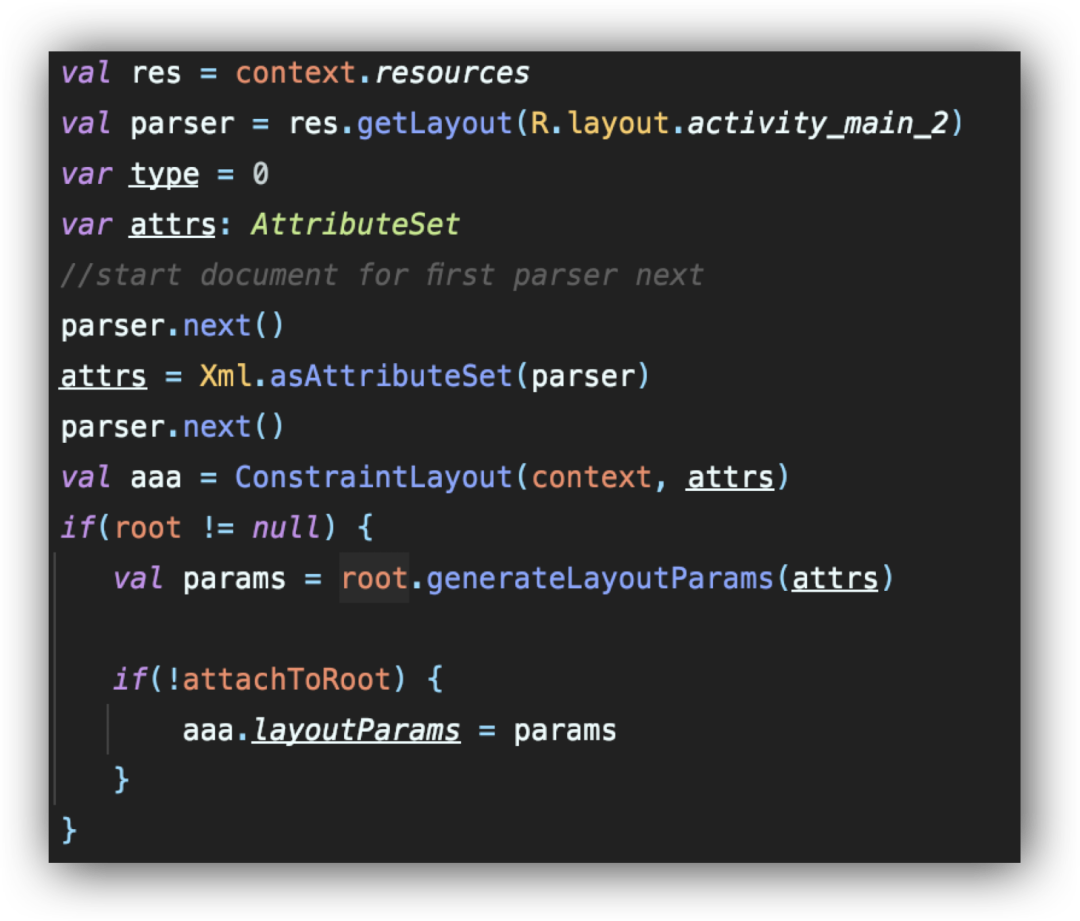 在遇到 merge 和 include 时,我们需要特殊处理递归调用的逻辑,以便可以将父子布局连在一起。用这种新的方式替换掉首页中一些布局的实现后,我们发现,线上首页部分 p90 的布局时间减少了 200ms+,时长、CES、留存等指标均得到了显著提升。
在遇到 merge 和 include 时,我们需要特殊处理递归调用的逻辑,以便可以将父子布局连在一起。用这种新的方式替换掉首页中一些布局的实现后,我们发现,线上首页部分 p90 的布局时间减少了 200ms+,时长、CES、留存等指标均得到了显著提升。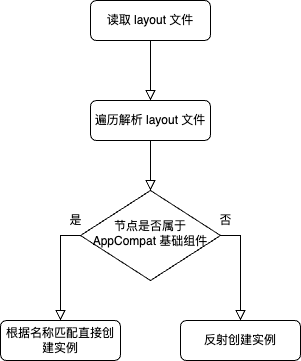
 就一个具体的布局而言,能够通过 Layout2Code 的使用得以提升的性能只有除了基础组件之外的其他组件,尤其是当布局使用了大量自定义组件时,效果尤为明显。这也给了我们另一个提醒。如在 xml 中写 TextView / TextViewCompat,在 AppCmpatViewInflater 的作用下最终创建的实例都是 TextViewCompat。但在不使用 Layout2Code 或类 X2C 方案时,它们的效率是不同的,前者命中上图的直接创建逻辑,而后者则会通过反射创建。
就一个具体的布局而言,能够通过 Layout2Code 的使用得以提升的性能只有除了基础组件之外的其他组件,尤其是当布局使用了大量自定义组件时,效果尤为明显。这也给了我们另一个提醒。如在 xml 中写 TextView / TextViewCompat,在 AppCmpatViewInflater 的作用下最终创建的实例都是 TextViewCompat。但在不使用 Layout2Code 或类 X2C 方案时,它们的效率是不同的,前者命中上图的直接创建逻辑,而后者则会通过反射创建。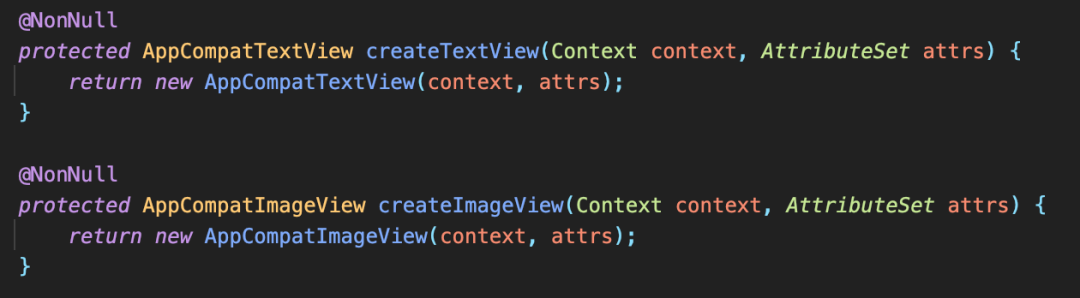 X2C的不足X2C
除了做了以上优化,还将 layout 文件的读取和解析也一并移到了编译阶段,以此来降低 IO 开销。但编译期解析 xml
最大的困难在于我们需要逐条翻译 View 的属性,原因是编译期间并没有 SDK 的依赖,因此无法生成 AtrributeSet 对象直接供以
View 的构造器消费。这样一来,需要人工维护翻译规则,将一条条 xml 属性转换成设置 View 属性的代码,这带来了几个问题:1. 生成的代码量指数级增加2. 需要极高的维护成本来支持自定义 View 的属性3. 某些 xml 属性并没有相对应的方法或不是一一对应的。总而言之,在此基础上要维持健壮完备的功能是非常困难的。而我们所探索的 Layout2Code 的新方案与之相比,兼容性和维护成本都有着巨大优势,唯一需要权衡考虑的就是运行时读取 layout 文件的优化空间有多少,是否值得这样的投入。layout 文件的特殊性提到
xml 文件,条件反射般地就会想到是 IO 操作,性能差,这没错,但 layout 文件却比较特殊。在 Andorid
应用打包过程中,AAPT 会对资源进行打包,会将除了 asset 文件夹下的 xml
文件通过字符串池复用、二进制转换等方式进行压缩,最终生成压缩后的资源文件和资源文件索引 resources.arsc 还有 R 文件。而在使用
AssetManager 对资源文件进行加载时,我们也会使用 mmap 来降低 IO 成本。
X2C的不足X2C
除了做了以上优化,还将 layout 文件的读取和解析也一并移到了编译阶段,以此来降低 IO 开销。但编译期解析 xml
最大的困难在于我们需要逐条翻译 View 的属性,原因是编译期间并没有 SDK 的依赖,因此无法生成 AtrributeSet 对象直接供以
View 的构造器消费。这样一来,需要人工维护翻译规则,将一条条 xml 属性转换成设置 View 属性的代码,这带来了几个问题:1. 生成的代码量指数级增加2. 需要极高的维护成本来支持自定义 View 的属性3. 某些 xml 属性并没有相对应的方法或不是一一对应的。总而言之,在此基础上要维持健壮完备的功能是非常困难的。而我们所探索的 Layout2Code 的新方案与之相比,兼容性和维护成本都有着巨大优势,唯一需要权衡考虑的就是运行时读取 layout 文件的优化空间有多少,是否值得这样的投入。layout 文件的特殊性提到
xml 文件,条件反射般地就会想到是 IO 操作,性能差,这没错,但 layout 文件却比较特殊。在 Andorid
应用打包过程中,AAPT 会对资源进行打包,会将除了 asset 文件夹下的 xml
文件通过字符串池复用、二进制转换等方式进行压缩,最终生成压缩后的资源文件和资源文件索引 resources.arsc 还有 R 文件。而在使用
AssetManager 对资源文件进行加载时,我们也会使用 mmap 来降低 IO 成本。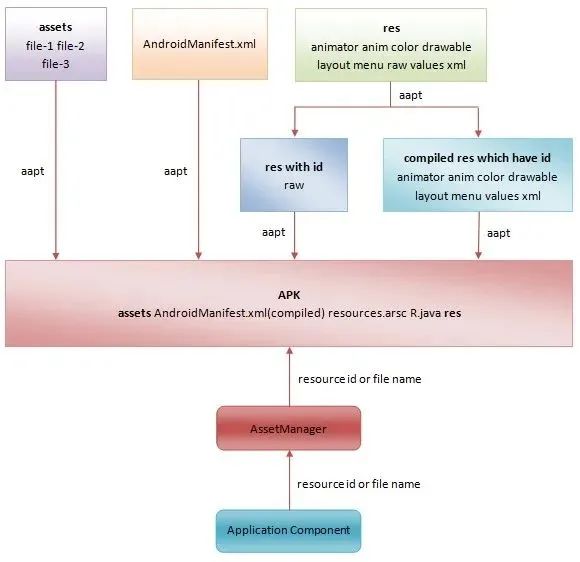 通过分析以上种种手段的利弊,我们在实际应用场景中测试后发现读取 layout 文件的耗时通常不超过 1ms。因此,考虑到将 layout 文件的读取和解析移到编译阶段所带来的维护成本,权衡之下我们最终选择了直接放弃这一部分的优化。
通过分析以上种种手段的利弊,我们在实际应用场景中测试后发现读取 layout 文件的耗时通常不超过 1ms。因此,考虑到将 layout 文件的读取和解析移到编译阶段所带来的维护成本,权衡之下我们最终选择了直接放弃这一部分的优化。在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
为了在我的mac上为一个rails项目安装mysql,我遵循了安装Homebrew软件和删除mac端口的在线建议。这是问题开始的地方。rails项目不会构建,我得到这个:[rake--prereqs]rakeaborted!dlopen(/Users/Parker/.rvm/gems/ruby-1.9.3-p448/gems/nokogiri-1.6.0/lib/nokogiri/nokogiri.bundle,9):Librarynotloaded:/opt/local/lib/libiconv.2.dylibReferencedfrom:/Users/Parker/.rvm/gem
我需要在rail3中使用标准注册/登录/忘记密码功能进行身份验证。是否有大多数人为此使用的插件或其他东西? 最佳答案 我不确定最常用的方法是什么-但可以肯定的是,Plataformatec的“Devise”是一个非常流行的方法:http://github.com/plataformatec/devise我已经尝试了一些authgem,对我来说,它是最简单的设置和修改以满足我的需要。它内置了密码恢复、帐户确认(如果需要)和其他一些非常方便的功能。 关于ruby-on-rails-在Rail
我在ruby表单中有一个提交按钮f.submitbtn_text,class:"btnbtn-onemgt12mgb12",id:"btn_id"我想在不使用任何javascript的情况下通过ruby禁用此按钮 最佳答案 添加disabled:true选项。f.submitbtn_text,class:"btnbtn-onemgt12mgb12",id:"btn_id",disabled:true 关于ruby-on-rails-如何在Rails中添加禁用的提交按钮,我们在St
关闭。这个问题是off-topic.它目前不接受答案。想改进这个问题吗?Updatethequestion所以它是on-topic用于堆栈溢出。关闭11年前。Improvethisquestion我不经常使用ruby-通常它加起来相当于每两个月或更长时间编写一次脚本。我的大部分编程都是使用C++进行的,这与ruby有很大不同。由于我与ruby之间的差距如此之大,我总是忘记语言的基本方面(比如解析文本文件和其他简单的东西)。我想每天练习一些基本的东西,我想知道是否有一些我可以订阅的网站,并且会向我发送当天的Ruby问题或类似的东西。有人知道这样的站点/Internet服务吗?
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
LL库和HAL库简介LL:Low-Layer,底层库HAL:HardwareAbstractionLayer,硬件抽象层库LL库和hal库对比,很精简,这实际上是一个精简的库。LL库的配置选择如下:在STM32CUBEMX中,点击菜单的“ProjectManager”–>“AdvancedSettings”,在下面的界面中选择“AdvancedSettings”,然后在每个模块后面选择使用的库总结:1、如果使用的MCU是小容量的,那么STM32CubeLL将是最佳选择;2、如果结合可移植性和优化,使用STM32CubeHAL并使用特定的优化实现替换一些调用,可保持最大的可移植性。另外HAL和L