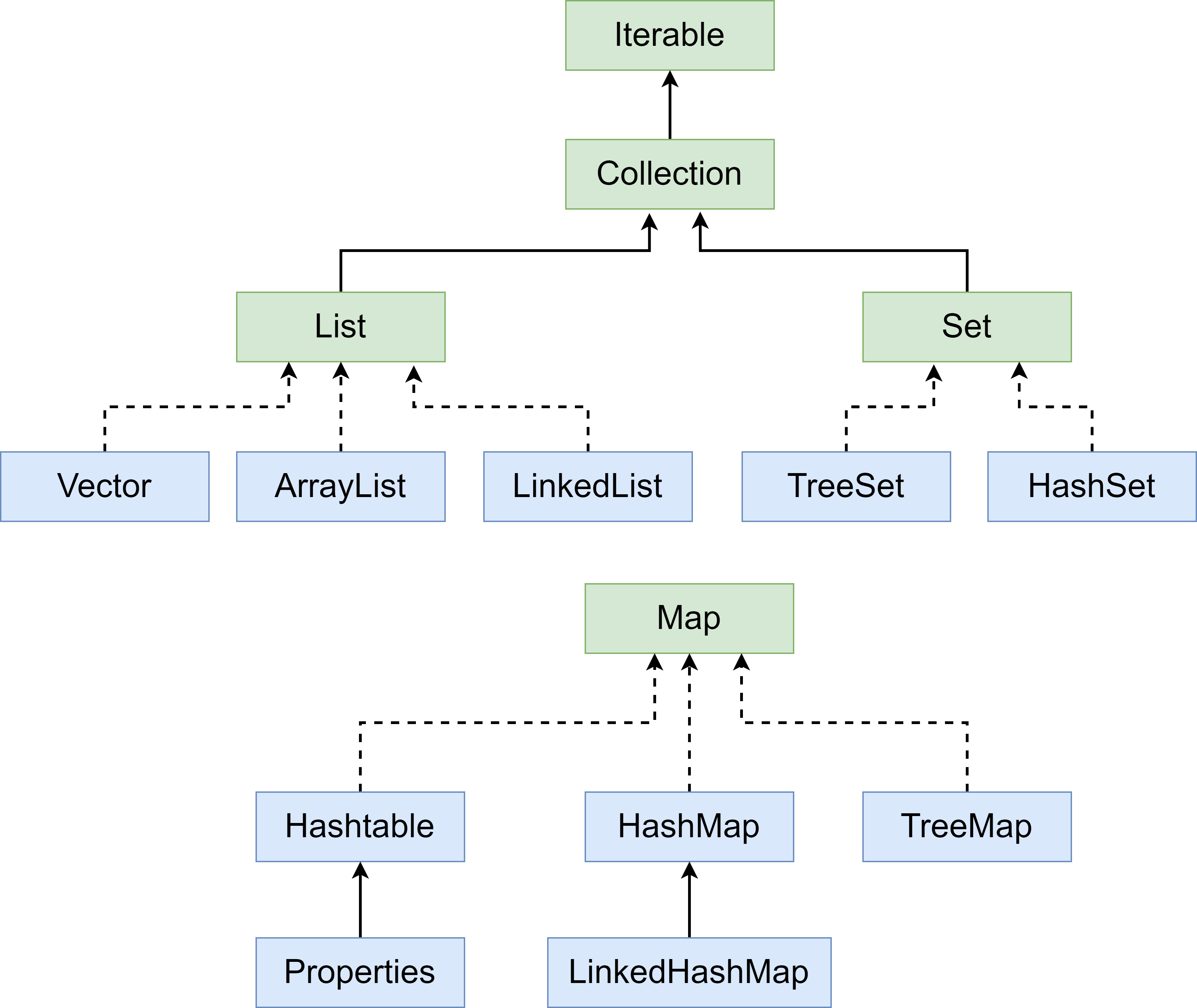
前面我们保存数据使用的是数组,数组有不足的地方,我们来分析一下:
例子
package li.collections;
import java.util.*;
public class CollectionsTest {
public static void main(String[] args) {
//Collection
//Map
ArrayList arrayList = new ArrayList();
arrayList.add("jack");//单列
arrayList.add("tony");
HashMap hashMap = new HashMap();
hashMap.put("No1","北京");//双列
hashMap.put("No2","上海");
}
}
public interface Collecion<E> extends Iterable<E>
例子1:Collection接口不能直接被实例化,因此以实现了接口的子类ArrayList来演示
package li.collections;
import java.util.*;
public class CollectionMethod {
public static void main(String[] args) {
List list = new ArrayList();
//1. add()添加单个元素
list.add("jack");
list.add(10);//list.add(new Integer(10)); 自动装箱
list.add(true);
System.out.println("list="+list);//list=[jack, 10, true] 注意里面的元素都是对象,非基本数据类型
//2. remove()删除指定元素
//list.remove(0);//指定删除的索引
//System.out.println("list="+list);//list=[10, true]
list.remove(true);//指定删除某个对象
System.out.println("list="+list);//list=[jack, 10]
//3. contains()查找元素是否存在
System.out.println(list.contains("jack"));//true
//4. size()获取元素个数
System.out.println(list.size());//2
//5. isEmpty()判断是否为空
System.out.println(list.isEmpty());//false
//6. clear()清空
list.clear();
System.out.println(list);//[] 空的集合
//7. addAll()添加多个元素
ArrayList list2 =new ArrayList();
list2.add("红楼梦");
list2.add("三国演义");
list.addAll(list2);
System.out.println("list="+list);//list=[红楼梦, 三国演义]
//8. containsAll()查找多个元素是否都存在
System.out.println(list.containsAll(list2));//true
//9. removeAll()删除多个元素
list.add("聊斋志异");
list.removeAll(list2);
System.out.println("list="+list);//list=[聊斋志异]
}
}
迭代:即Collection集合元素的通用获取方式。在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续再判断,如果还有就再取出出来。一直把集合中的所有元素全部取出。这种取出方式专业术语称为迭代。
基本介绍:

PS:在调用iterator.next()方法之前一定必须要调用iterator.hasNext()方法来进行检测,若不调用且下一条记录无效则会抛出 NoSuchElementException 异常。
例子:
package li.collections;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class CollectionIterator {
@SuppressWarnings({"all"})
public static void main(String[] args) {
Collection col = new ArrayList();
col.add(new Book("三国演义","罗贯中",10.1));
col.add(new Book("小李飞刀","古龙",5.1));
col.add(new Book("红楼梦","曹雪芹",34.6));
System.out.println("col"+col);//col[Book{name='三国演义', author='罗贯中', price=10.1}, Book{name='小李飞刀', author='古龙', price=5.1}, Book{name='红楼梦', author='曹雪芹', price=34.6}]
//现在想要遍历这个col集合
//1.先得到col集合对应的迭代器
Iterator iterator = col.iterator();
//2.使用while循环遍历
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
//3.当退出while循环之后,这使得iterator迭代器指向最后的元素,
// 这时如果再执行iterator.next()就会出现NoSuchElementException异常
//4.如果想要再次遍历集合,则需要重置迭代器
//重置迭代器,这之后就可以再次遍历,实质上是重新创建了一个迭代器对象
iterator = col.iterator();
}
}
class Book{
private String name;
private String author;
private double price;
public Book(String name, String author, double price) {
this.name = name;
this.author = author;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", author='" + author + '\'' +
", price=" + price +
'}';
}
}

快捷键:itit

快捷键:Ctrl+j 显示所有快捷键

Collection接口遍历对象的方式1--迭代器遍历 2--for循环增强
增强for循环,可以代替iterator迭代器,特点:增强for循环就是简化版的iterator,本质一样。只能用于遍历集合或者数组。
基本语法:
for(元素类型 元素名:集合名或数组名){
访问元素
}
例子:
package li.collections;
import java.util.ArrayList;
import java.util.Collection;
public class CollectionFor {
@SuppressWarnings({"all"})
public static void main(String[] args) {
Collection col = new ArrayList();
col.add(new Book("三国演义","罗贯中",10.1));
col.add(new Book("小李飞刀","古龙",5.1));
col.add(new Book("红楼梦","曹雪芹",34.6));
//增强for,用于集合
//增强for底层仍然是迭代器
//因此增强for可以理解成简化版的迭代器
for (Object book:col) {//元素类型 元素名:集合名或数组名
System.out.println("book="+book);
}
//使用增强for,不但可以适用于集合,还可以用于数组
int[] nums ={1,3,8,10};
for (int i:nums){
System.out.println("i="+i);
}
}
}

快捷键:集合名.for
List接口是Collection接口的子接口

boolean add(int index, E element) 将指定的元素插入此列表中的指定位置(可选操作)
boolean addAll(int index, Collection<? extends E> c) 将指定集合中的所有元素插入到此列表中的指定位置(可选操作)
Obect get(int index) 返回此列表中指定位置的元素
int indexOf(Object o) 返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1
int lastIndexOf(Object o) 返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1
Object remove(int index) 删除该列表中指定位置的元素,并返回此元素(可选操作)
Object set(int index, E element) 用指定的元素(可选操作)替换此列表中指定位置的元素
List subList(int fromIndex, int toIndex) 返回从 fromIndex(不含)到 toIndex(不含)位置的子集合:[fromIndex,toIndex)
例子:
package li.collections.list;
import java.util.ArrayList;
import java.util.List;
public class ListMethod {
@SuppressWarnings({"all"})
public static void main(String[] args) {
List list = new ArrayList();
list.add("张三丰");
list.add("贾宝玉");
//boolean add(int index, E element)
//将指定的元素插入此列表中的指定位置(可选操作)
list.add(1,"杨过");//在index=1的位置插入一个对象
System.out.println(list);//[张三丰, 杨过, 贾宝玉]
//boolean addAll(int index, Collection<? extends E> c)
//将指定集合中的所有元素插入到此列表中的指定位置(可选操作)
List list2 = new ArrayList();
list2.add("jack");
list2.add("tom");
list.addAll(1,list2);//在索引1位置插入list2集合的元素
System.out.println(list);//[张三丰, jack, tom, 杨过, 贾宝玉]
//Obect get(int index)
// 返回此列表中指定位置的元素。
//int indexOf(Object o)
//返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1
System.out.println(list.indexOf("tom"));//2
//int lastIndexOf(Object o)
//返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1
list.add("杨过");
System.out.println(list);//[张三丰, jack, tom, 杨过, 贾宝玉, 杨过]
System.out.println(list.lastIndexOf("杨过"));//5
//Object remove(int index)
//删除该列表中指定位置的元素,并返回此元素(可选操作)
list.remove(3);
System.out.println(list);//[张三丰, jack, tom, 贾宝玉, 杨过]
//Object set(int index, E element)
//用指定的元素(可选操作)替换此列表中指定位置的元素
list.set(1,"马丽");
System.out.println(list);//[张三丰, 马丽, tom, 贾宝玉, 杨过]
//List subList(int fromIndex, int toIndex)
//返回从 fromIndex(不含)到 toIndex(不含)位置的子集合:[fromIndex,toIndex)
List returnList = list.subList(0,2);
System.out.println(returnList);//[张三丰, 马丽]
}
}
List的三种遍历方式:
例子:
package li.collections.list;
import java.util.*;
public class ListFor {
@SuppressWarnings({"all"})
public static void main(String[] args) {
//List接口的实现子类 Vector LinkedList同理
//List list = new ArrayList();
//List list = new Vector();
List list = new LinkedList();
list.add("jack");
list.add("tom");
list.add("鱼香肉丝");
list.add("北京烤鸭");
//1.使用迭代器
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.print(obj);
}
//2.增强for循环
for (Object obj:list) {
System.out.print(obj);
}
//使用普通for循环
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i));
}
}
}
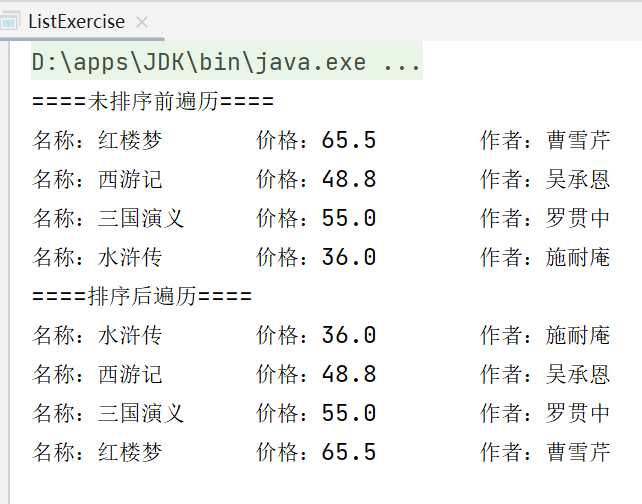
使用List的实现类添加三本图书,并遍历,打印效果如下:
名称:XX 价格:xx 作者:xx
名称:XX 价格:xx 作者:xx
名称:XX 价格:xx 作者:xx
要求:
按价格排序,从低到高(使用冒泡排序)
要求使用ArrayList、LinkedList、Vector三种集合实现
使用冒泡实现集合的排序
package li.collections.list;
import java.util.ArrayList;
import java.util.List;
@SuppressWarnings("all")
public class ListExercise {
public static void main(String[] args) {
//使用ArrayList,LinkedList、Vector同理
List list = new ArrayList();
list.add(new Book("红楼梦", 65.5, "曹雪芹"));
list.add(new Book("西游记", 48.8, "吴承恩"));
list.add(new Book("三国演义", 55, "罗贯中"));
list.add(new Book("水浒传", 36, "施耐庵"));
System.out.println("====未排序前遍历====");
for (Object o : list) {
System.out.println(o);
}
sort(list);
System.out.println("====排序后遍历====");
for (Object o : list) {
System.out.println(o);
}
}
//对集合进行排序
public static void sort(List list) {
int listSize = list.size();//获取集合的长度
Book book1;
Book book2;
for (int i = 0; i < listSize - 1; i++) {//轮数
for (int j = 0; j < listSize - 1 - i; j++) {//每轮的索引
book1 = (Book) list.get(j);
book2 = (Book) list.get(j + 1);
if (book1.getPrice() > book2.getPrice()) {
list.set(j, book2);
list.set(j + 1, book1);
}
}
}
}
}
class Book {
private String name;
private double price;
private String author;
public Book() {
}
public Book(String name, double price, String author) {
this.name = name;
this.price = price;
this.author = author;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
@Override
public String toString() {//按格式重写toString方法
return "名称:" + name + "\t\t" + "价格:" + price + "\t\t" + "作者:" + author;
}
}
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
我看到这个错误:translationmissing:da.datetime.distance_in_words.about_x_hours我的语言环境文件:http://pastie.org/2944890我的看法:我已将其添加到我的application.rb中:config.i18n.load_path+=Dir[Rails.root.join('my','locales','*.{rb,yml}').to_s]config.i18n.default_locale=:da如果我删除I18配置,帮助程序会处理英语。更新:我在config/enviorments/devolpment
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
如果我使用ruby版本2.5.1和Rails版本2.3.18会怎样?我有基于rails2.3.18和ruby1.9.2p320构建的rails应用程序,我只想升级ruby的版本,而不是rails,这可能吗?我必须面对哪些挑战? 最佳答案 GitHub维护apublicfork它有针对旧Rails版本的分支,有各种变化,它们一直在运行。有一段时间,他们在较新的Ruby版本上运行较旧的Rails版本,而不是最初支持的版本,因此您可能会发现一些关于需要向后移植的有用提示。不过,他们现在已经有几年没有使用2.3了,所以充其量只能让更
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
大家好!我对我的:username字段进行了一个小的验证,它应该是4到30个字符。我写了一个验证::length=>{:within=>4..30,:message=>I18n.t('activerecord.errors.range')-我想显示一个错误各种错误的消息(不像,太长或太短),但这里有一个问题-我可以将最小值和最大值都传递给翻译,以便有类似的东西:用户名应该在4到30个字符之间。目前我有:range:"shouldbebetween%{count}and%{count}characters",这显然不起作用(只是为了检查)。是否可以从范围中获取这些值?谢谢大家的指教!
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候