引用论文:Zhao, Sicheng, et al. “Emotion Recognition from Multiple Modalities: Fundamentals and Methodologies.” arXiv preprint arXiv:2108.10152 (2021).
PDF链接:Emotion Recognition from Multiple Modalities: Fundamentals and Methodologies.
新鲜出炉的赵思成和杨巨峰大佬的论文哦(情感识别领域的专家),全面的梳理了多模态情感识别(Multi-modal Emotion Recognition, MER)的多个关键方面,是一篇日期新鲜(2021.08),内容详实,高质量的综述,非常适合入门的同学入手和老司机们回顾总结。翻译和整理了一上午,有用请帮我点个赞再走吧,谢谢Thanks♪(・ω・)ノ~
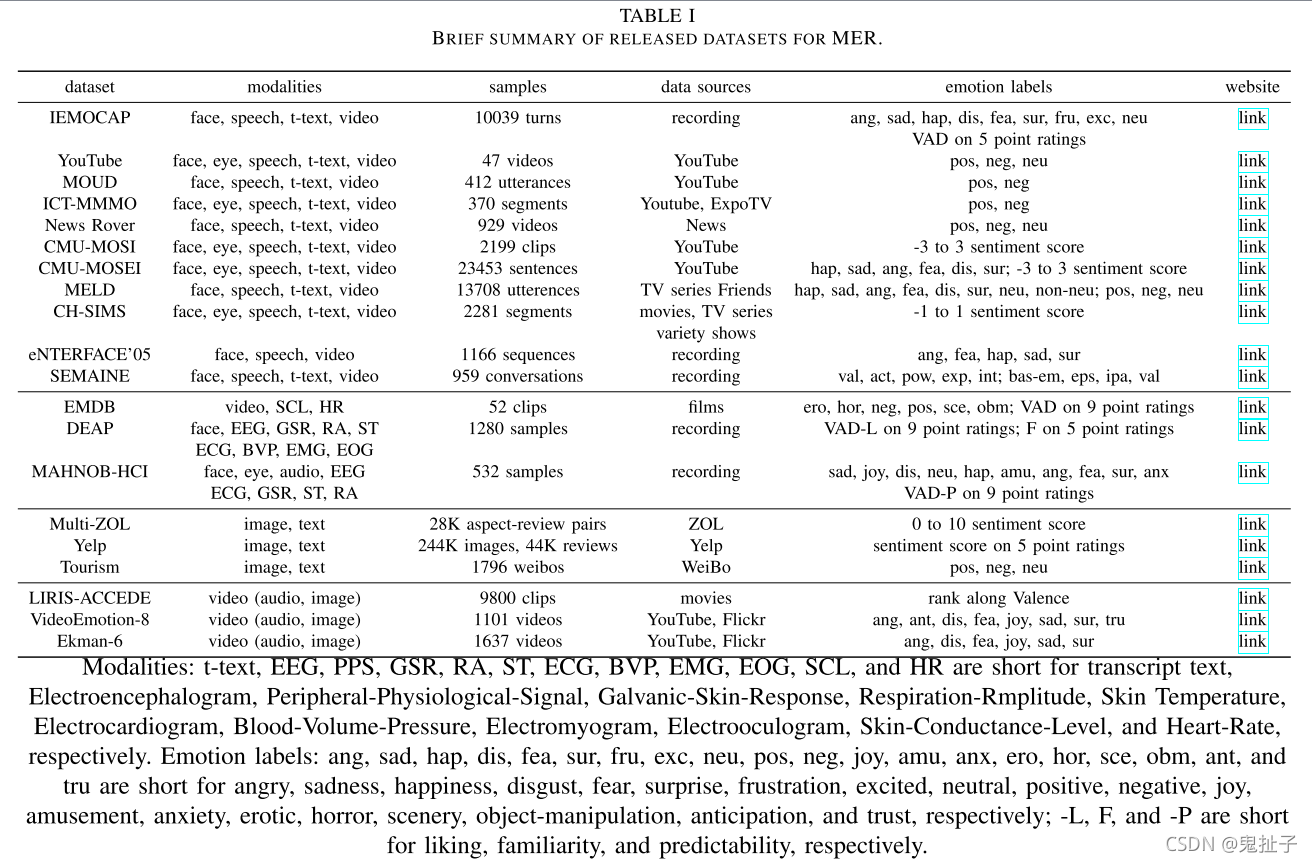
下表为多模态数据集,可以看到最后一列给出了下载地址,需要数据集的朋友们可以点上面链接地址进入文章下载,如果除了数据集还想了解多模态情感识别(MER)的其他章节内容(模型,难点,挑战,任务,方法,应用),请继续往下阅读哦~

目前,学术界对情绪分类并没有统一的定义,一般的情绪分类主要有两大基本观点:离散模式(categorical emotion states (CES))和连续模式( dimensional emotion space (DES))。离散模式认为情绪具有完全不同的结构,连续模式认为不同情绪之间有着过渡阶段。
binary sentiment :positive and negative, sometimes including neutral;
Ekman’s six basic emotions: positive happiness, surprise and negative anger, disgust, fear, sadness;
Mikels’s eight emotions: positive amusement, awe, contentment, excitement, and negative anger, disgust, fear, sadness;
Plutchik’s emotion wheel :eight basic emotion categories by three intensities;
Parrott’s tree hierarchical grouping :primary, secondary and tertiary categories.
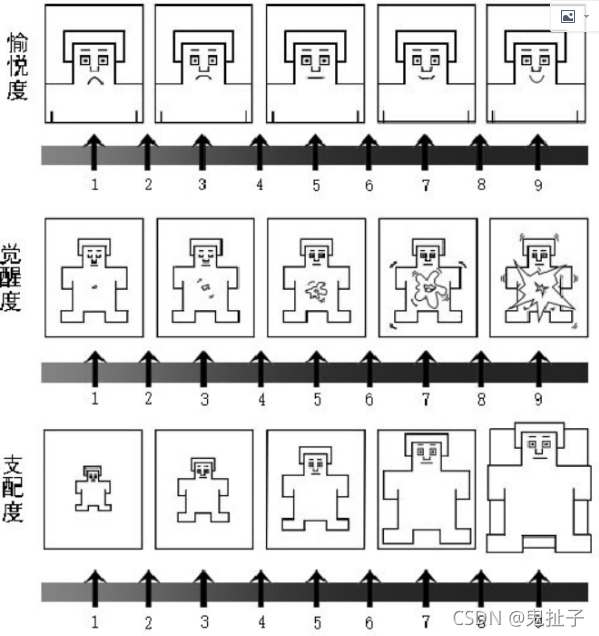
valence-arousal-dominance (VAD):where valence, measure all emotions as different coordinate points in the continuous Cartesian space, but the absolute continuous values are beyond users’ understanding.
在MER(多模态情感识别)领域,多种模式(multi-modal)被用于识别和预测人类情绪。根据情感是来自人体的身体变化还是来自外部数字媒体,MER中的情感模态可以大致分为两类:
显性情感线索:包括面部表情、眼球运动、语言、动作、步态和脑电图,所有这些都可以直接观察、记录或从个人身上收集。
隐性情感刺激:后者表示常用的数字媒体类型,如文本、音频、图像和视频。我们使用这些数据类型来存储信息和知识,以及在数字设备之间传输信息和知识。通过这种方式,情感可能会含蓄地参与和唤起。虽然单一模式作为情感表达的可靠渠道的有效性无法保证,但联合考虑多种模式将显著提高[12]的可靠性和稳健性。
对于多模态情感信号,我们可以进行不同的MER任务,包括分类、回归、检测和检索。
在情感分类任务中,我们假设样本只能属于一个或固定数量的情感类别,其目标是发现数据空间[16]中的类边界或类分布。目前的工作主要集中在多模态特征和分类器的手工设计或以端到端方式使用深度神经网络。
MER定义为单标签学习(SLL)问题,为每个样本分配一个显性情绪标签。然而,情感可能是来自不同区域或序列的所有成分的混合物,而不是一个单一的代表性情感。与此同时,不同的人可能有对同一刺激产生不同的情绪反应,这是由性格等多种因素引起的。因此,多标签学习(MLL)被用来研究一个实例与多个情绪标签关联的问题。
最近,为了解决MLL不能很好地适应实际应用的问题,不同标签重要性的总体分布很重要,标签分布学习(LDL)被提出,覆盖一定数量的标签,代表每个情绪标签描述实例[20]的程度。
情感回归的目的是学习一种映射函数可以有效地将一个实例与笛卡尔空间中的连续情感值联系起来。最常用的MER回归算法旨在将平均维数值分配给源数据。为了解决情绪固有的主观性,研究者提出了预测在维价唤起空间中表现的情绪的连续概率分布的方法。具体地说,可以用高斯混合模型(GMM)来表示情感标签,然后将情感分布预测形式化为参数学习问题[21]。
由于原始数据不能保证承载情绪,或者只有部分数据能够引起情绪反应,所以情绪检测的目的是找出源数据中哪一种情绪在哪里。例如,Yelp上的餐厅评论可能是“这家餐厅就在我工作的街对面,非常方便,步行对我来说是一个巨大的加分!” 在食物方面,那里和我去过的几乎所有地方都一样,所以没什么可说的。我不得不说,客户服务是命中注定或错过。”同时,总体评分是3星(满分5星)。这篇评论包含了不同的情绪和态度:第一句是积极的,第二句是中立的,最后一句是消极的。因此,系统检测哪个句子对应哪个情绪是至关重要的。另一个例子是图像[22]中的情感区域检测。
如何基于人的感知来搜索情感内容是另一个有意义的任务。现有框架首先检测查询和候选数据源中的局部兴趣块或序列。然后,通过确定两个patch或序列之间的距离是否小于给定的固定阈值来发现所有匹配的对。查询与每个候选项之间的相似度得分被计算为匹配组件的数量,然后对该查询的可候选项进行相应的排名。尽管情感检索系统有助于从海量存储库[10]中获取具有所需情感的在线内容,但抽象和主观特征使任务具有挑战性和难以评估。
情感鸿沟是MER的主要挑战之一,它衡量的是提取的特征和感知到的高级情绪之间的不一致性。在客观多媒体分析中,情感鸿沟比语义鸿沟更具挑战性。即使语义上的鸿沟被弥合了,情感上的鸿沟仍然可能存在。例如,一朵盛开的玫瑰和一朵凋谢的玫瑰都含有玫瑰,但却能唤起不同的情感。对于同一个句子,不同的语调可能对应着完全不同的情绪。提取具有区别性的高级特征,特别是与情绪相关的特征,有助于弥合情感鸿沟。主要难点在于如何评价所提取的特征是否与情绪相关。
有的人可能会因为巨大的雷声而感到恐惧,有的人可能会因为捕捉到这样罕见的场景而感到兴奋;即使相同的情绪(如兴奋),也会有不同的反应,如面部表情、步态、动作和语言。对于主观性的挑战,一个直接的解决方案是学习每个受试者的个性化的MER模型。从刺激的角度,我们也可以预测一定数量被试参与时的情绪分布。除了刺激内容和直接的生理和心理变化外,上述个人因素、情境因素和心理因素的联合建模也有助于MER任务的完成。
由于在数据采集中存在许多不可避免的因素,如传感器设备故障,特定形式的信息可能会被破坏,从而导致数据丢失或不完整。数据不完整是现实世界MER任务中常见的现象。例如,对于明确的情感线索,脑电图耳机可能会记录受污染的信号,甚至无法记录任何信号;在晚上,摄像机无法捕捉到清晰的面部表情。对于内隐情感刺激,一个用户可能只发布包含图像(没有文本)的tweet;对于一些视频,音频通道变化不大。在这种情况下,最简单的特征融合方法,即早期融合,是行不通的,因为在没有捕获信号的情况下,我们无法提取任何特征。设计能够处理数据不完整性的有效融合方法是一种广泛采用的策略。
同一样本的不同模态可能会相互冲突,从而表达不同的情绪。例如,面部表情和言语可以很容易地被抑制或掩盖,以避免被发现,但脑电图信号是由中枢神经系统控制的,可以反映人类无意识的身体变化。当人们在社交媒体上发布推文时,图像与文本在语义上不相关的现象非常普遍。在这种情况下,一种有效的MER方法有望自动评估哪些模式更可靠,例如通过为每个模式分配权重。
在一些MER应用中,不同的模式对唤起的情绪的贡献可能是不平等的。例如,网络新闻在我们的日常生活中扮演着重要的角色,除了了解读者的偏好,预测他们的情绪反应在各种应用中都有很大的价值,比如个性化广告。然而,一篇网络新闻通常包含不平衡的文字和图片,即文章可能很长,有很多详细的信息,而新闻中只有一两个插图。可能更有问题的是,新闻编辑可能会为一篇带有明显情绪的文章选择一幅中性的图像。
现有的MER方法,特别是基于深度学习的MER方法需要大量的标记数据进行训练。然而,在实际应用中,在生成ground-truth给情绪贴标签不仅花费昂贵和时间,而且高度不一致,这导致数据量大,但很少或甚至没有情绪标签。随着情感需求的日益多样化和细粒度化,我们可能有足够的训练数据来处理某些情感类别,而不是其他类别。手动注释的另一种解决方案是利用社交推文的标签或关键字作为情感标签,但这样的标签是不完整的和嘈杂的。因此,为无监督/弱监督学习和少/零次学习设计有效的算法可以提供潜在的解决方案。
同时,我们可能在一个领域有足够的标记情感数据,如合成面部表情和语音。问题是如何有效地将经过训练的MER模型在有标记的源域转移到另一个未标记的目标域。当使用直接传输[23]时,畴移的存在导致显著的性能下降。多模态域自适应和域泛化有助于缓解这种域间隙。还应该考虑实际的设置,例如多源域。
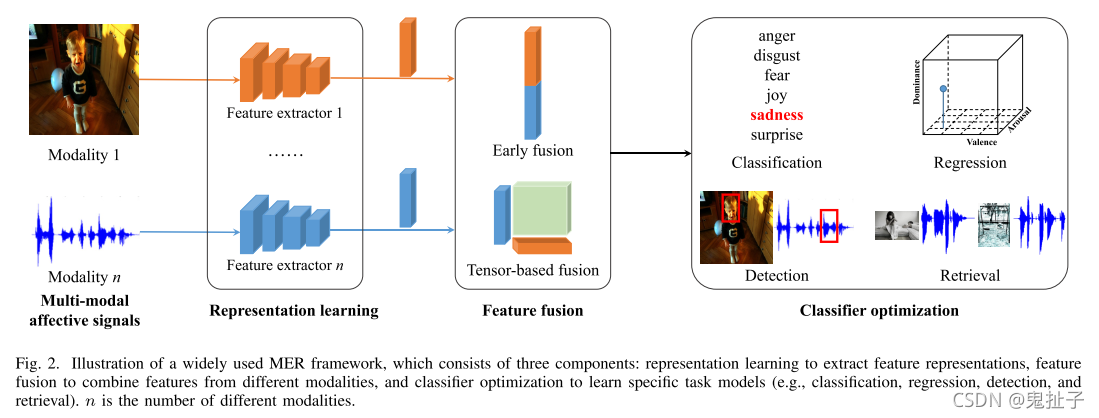
一般而言,在目标域具有足够标记训练数据的MER框架中,有三个组成部分:表示学习、特征融合和分类器优化,如上图2所示。在本节中,我们将介绍这些部分。进一步,我们将描述在目标域没有标记训练数据和在另一个相关源域有足够标记数据时的域自适应。
基于模型的融合在构建学习模型的过程中进行了明确的融合,因此受到了更多的关注[7,9]。近年来,基于神经网络的深度模型、基于注意力的深度模型和基于张量的深度模型被广泛应用。
域自适应的目的是从标记的源域学习一个可迁移的MER模型,该模型可以很好地应用于未标记的目标域[23]。最近致力于深度无监督域自适应[23],它采用了两流架构。一个流用于在标记的源域上训练MER模型,而另一个流用于对齐源域和目标域。基于对齐策略,现有的单模态域自适应方法可分为基于差异、对抗判别、对抗生成和基于自我监督的方法[23]。(更多请阅读原文,没翻译完)
从多种外显线索和内隐刺激中识别情绪具有广泛的现实应用意义。一般来说,情感是我们存在的质量和意义的最重要的方面,它使生活有价值。数字数据的情感影响在于它可以改善现有技术的用户体验,进而加强人与计算机之间的知识转移[18]。
许多人倾向于在社交网络上发布文字、图片和视频来表达他们的日常生活感受。受此启发,我们可以挖掘人们对现实世界中发生的话题和事件的看法和情感。例如,Facebook或Instagram上的用户生成内容可以用来获取来自不同国家和地区的人们在面对COVID-19[29]等流行病时的态度。研究人员还试图检测社交网络中的情绪,并将结果应用于预测政治选举。注意,当个体的个性化情绪被发现时,我们可以进一步将这些情绪分组,这可能有助于预测社会趋势。
多模态情感识别的另一个重要应用是商业智能,特别是营销和消费者行为分析[30]。如今,大多数服装电子零售商都使用人体模型来展示产品。模型的面部呈现对消费者接近行为有显著影响。具体来说,对于情绪接受度高的参与者,微笑的面部表情更容易导致最高接近行为。此外,研究人员在刺激-机体-反应框架的基础上,考察了网上商店专业化如何影响消费者的愉悦和唤起。情绪识别也可以应用于呼叫中心,其目的是检测呼叫者和接线员的情绪状态。该系统通过语调和节奏识别相关的情绪,以及从相应的讲话中翻译出来的文本。在此基础上,我们可以收到关于服务质量的反馈。
同时,情感识别在医疗和心理健康领域具有重要作用。随着社交媒体的普及,一些人更喜欢在互联网上分享他们的情绪而不是与他人。如果用户被观察到频繁且持续地分享负面信息(如悲伤),就有必要跟踪其心理状态,防止心理疾病甚至自杀的发生。情绪状态还可以用来监测和预测各种人的疲劳状态,如司机、飞行员、装配线上的工人和教室里的学生。这种方法既能防止危险情况的发生,又有利于工作/学习效率的评估。此外,情绪状态可以被整合到各种安全应用中,例如监控公共空间(如公交/火车/地铁站,足球场)的系统,以防范潜在的攻击行为。最近,在儿童自闭症谱系障碍(ASD)的诊断和治疗过程中引入了一种有效的辅助系统,以辅助收集患儿的病理信息。为了帮助专业临床医生更好、更快地对ASD患者进行诊断和治疗,该系统将面部表情和眼睛注视注意力作为自闭症早期筛查的显著指标。
采用多模态情感识别提高个人娱乐体验。例如,最近的一项脑电波-音乐界面的研究将脑电图特征映射到音乐结构(音符、强度和音高)。同样,人们也在努力理解不同模式之间以情感为中心的相关性,这对各种应用至关重要。情感图像-音乐匹配提供了一个很好的机会,将音乐序列附加到给定的图像,在那里它们可能唤起相同的情感。这有助于从移动设备上的个人相册照片中生成能感知情感的音乐播放列表。
现有的方法在视觉-音频、面部-文本-语音和文本-视觉任务等各种MER设置上取得了很好的性能。然而,所有概括的挑战都没有得到充分处理。例如,如何提取与情绪关系更密切的鉴别特征,如何平衡普通情绪反应和个性化情绪反应,以及如何强调更重要的表现形式等,仍是开放的。为提高MER方法的性能,使其适应现实世界的特殊要求,本文提出了一些潜在的发展方向。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我有一个存储主机名的Ruby数组server_names。如果我打印出来,它看起来像这样:["hostname.abc.com","hostname2.abc.com","hostname3.abc.com"]相当标准。我想要做的是获取这些服务器的IP(可能将它们存储在另一个变量中)。看起来IPSocket类可以做到这一点,但我不确定如何使用IPSocket类遍历它。如果它只是尝试像这样打印出IP:server_names.eachdo|name|IPSocket::getaddress(name)pnameend它提示我没有提供服务器名称。这是语法问题还是我没有正确使用类?输出:ge
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit