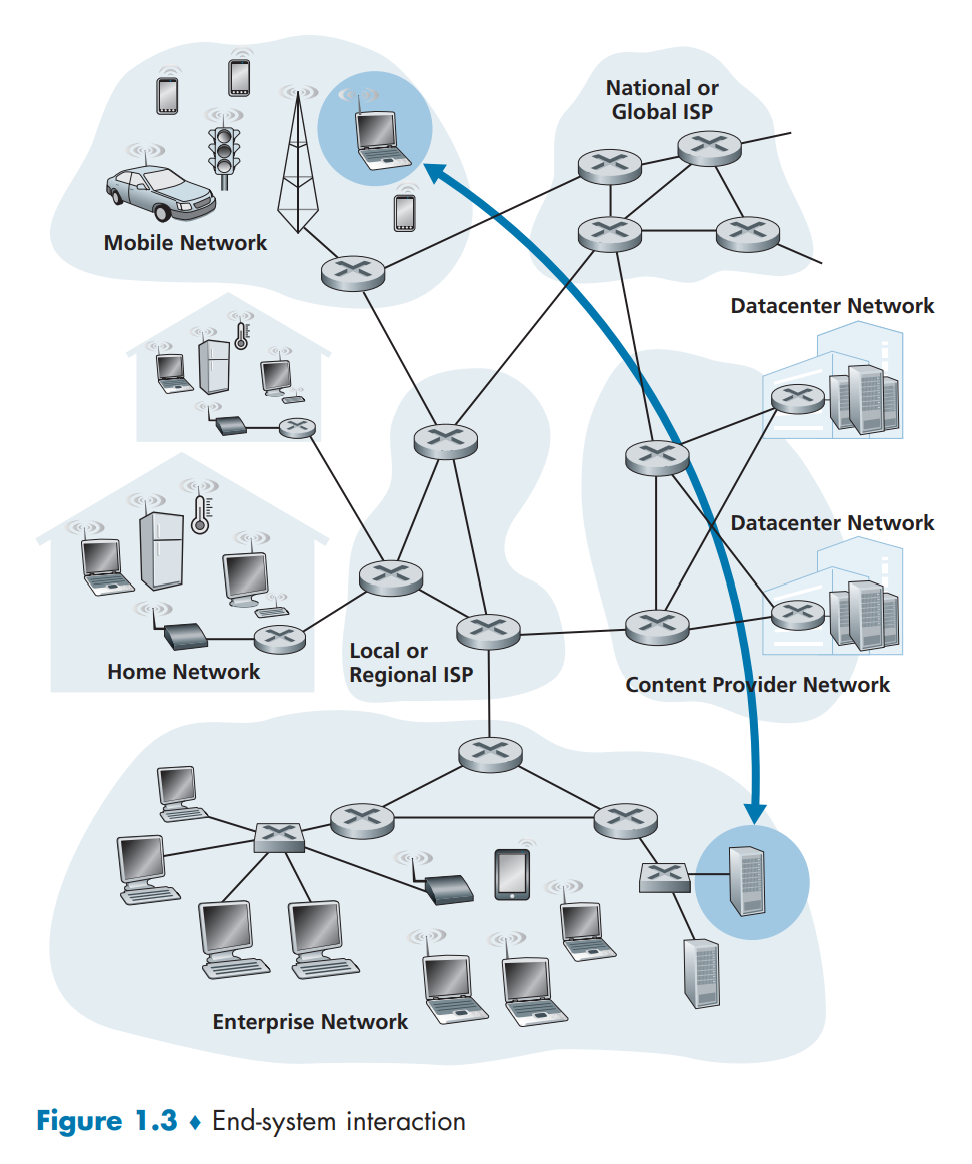
因特网边缘
端系统通过通信链路(communication link)和分组交换机(packet switch)连接到一起。信息在通信链路中以分组的形式传输;当今因特网中最重要的两类分组交换机是路由器(router)和链路层交换机(link-layer switch)。
端系统通过因特网服务提供商(Internet Service Provider,ISP)接入因特网。ISP彼此互联,独立管理。
端系统、分组交换机和其他因特网部件都要运行一些列协议(protocol),协议控制着因特网中信息的发送和接收。因特网的主要协议统称为TCP/IP,其中TCP(Transmission Control Protocol,传输控制协议),IP(Internet Protocol,网际协议)。
另一个视角:
与因特网相连的端系统提供了一个套接字接口(socket interface),该接口规定了运行在一个端系统上的程序请求因特网基础设施向另一个端系统上的特定目的地程序交付数据的方式。因特网套接字接口是一套发送程序必须遵循的规则集合。
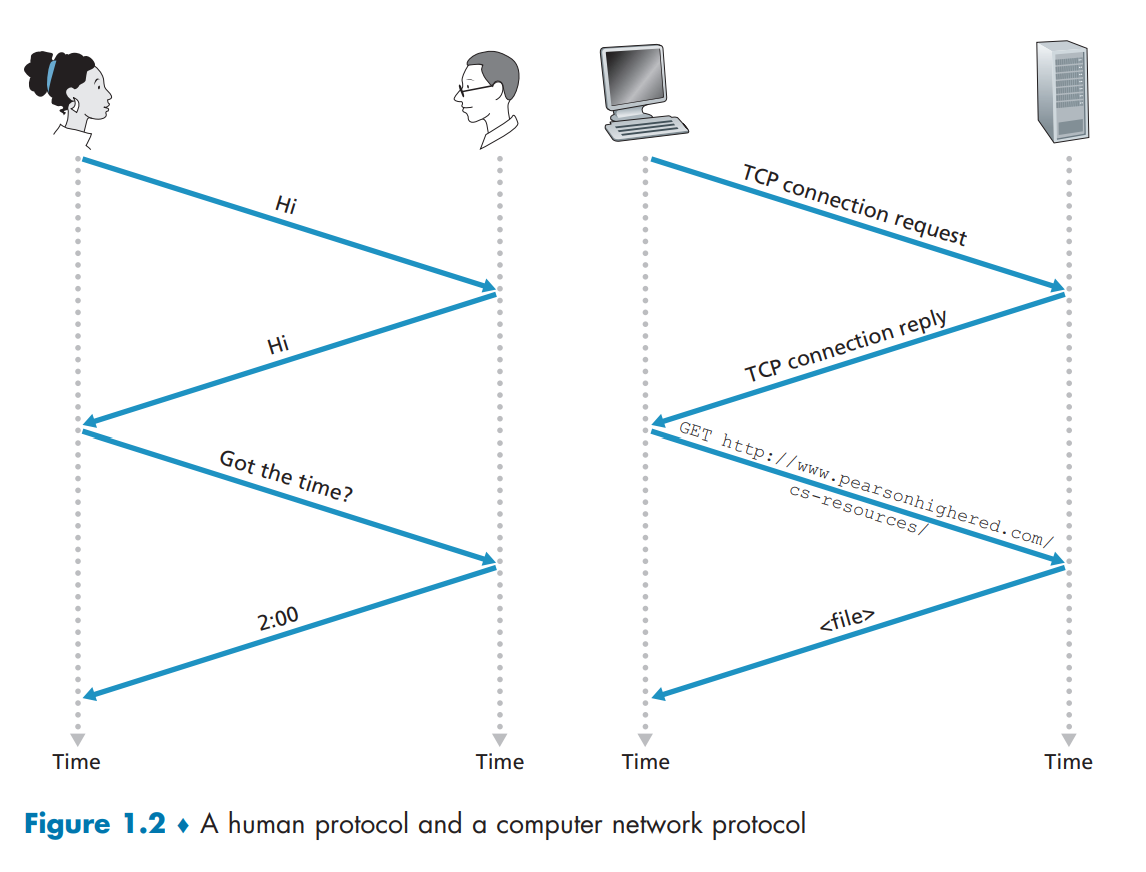
Internet 中涉及两个或多个通信远程实体的所有活动都受协议控制。 例如,两台物理连接的计算机中的硬件实现协议控制两个网络接口卡之间“线路”上的位流; 终端系统中的拥塞控制协议控制发送方和接收方之间的数据包传输速率; 路由器中的协议确定数据包从源到目的地的路径。
协议定义了在两个或多个通信实体之间交换报文的格式和顺序,以及报文发送和\或接收报文或其他事件所采取的动作。
接入网
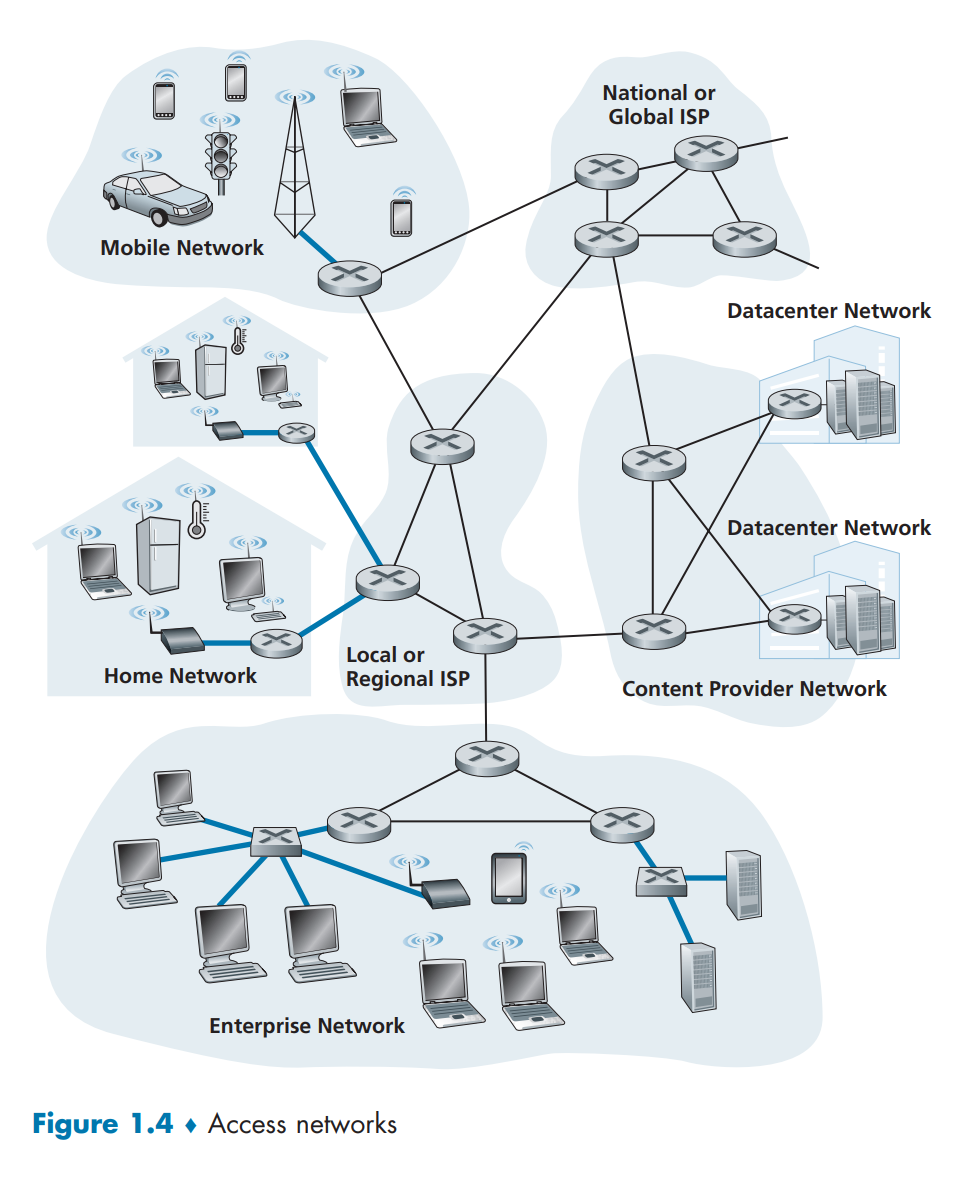
网络边缘是各类应用程序和端系统,而将网络边缘设备物理连接到其边缘路由器(edge router)的网络称为接入网。边缘路由器是任何端系统到任何其他远程端系统的路径上的第一台路由器。
接入网又分为:
物理媒介:分为两种类型,引导型媒体(guided media)和非引导型媒体(unguided media)。
双绞铜线、同轴电缆、光纤、陆地无线电信道、卫星无线电信道
网络核心
网络核心是由互联因特网端系统的分组交换机和链路构成的网状网络。
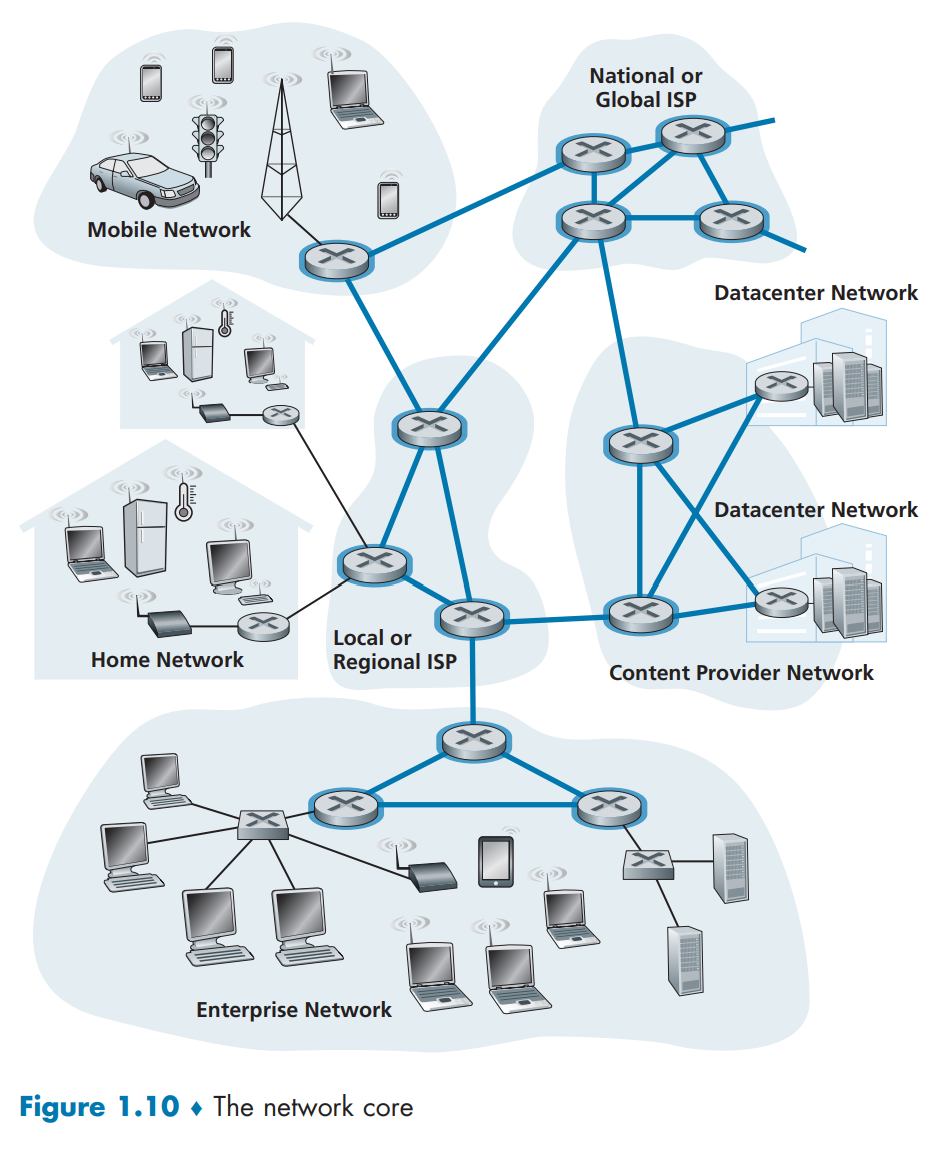
通过网络链路和交换机移动数据有两种基本方法:分组交换和电路交换。
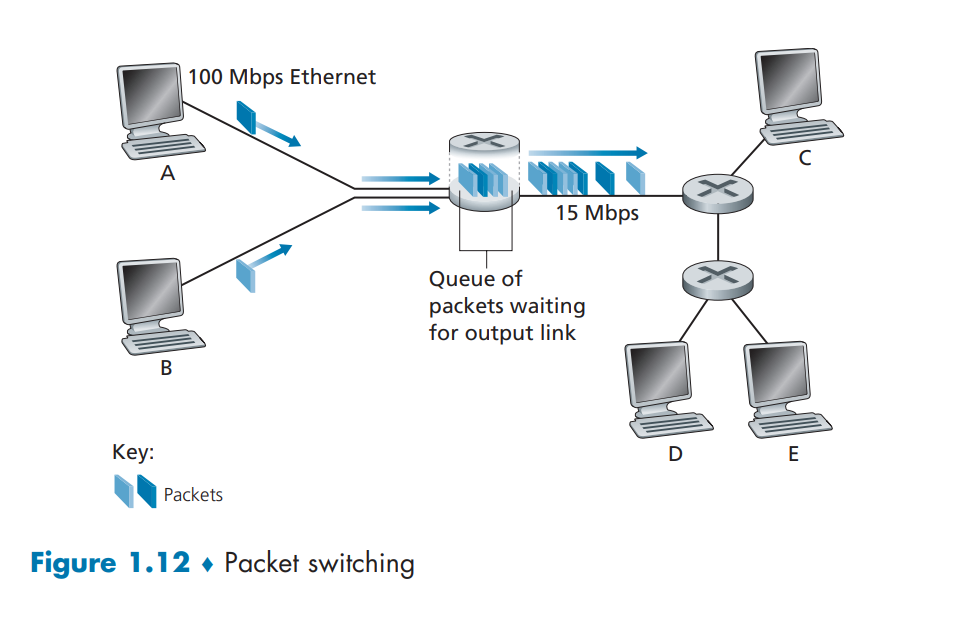
1.分组交换(packet switching)
端系统彼此交换报文(message),为了从源端系统向目的端系统发送一个报文,源端系统将长报文划分为较小的数据块,称为分组(packet),在源和目的之间,每个分组都通过通信链路和分组交换机传送。交换机主要有两种类型:路由器和链路层交换机。
存储转发传输(Store-and-Forward Transmission),多数分组交换机在链路的输入端采用存储转发传输机制。是指在交换机能够向链路的输出端转发该分组的第一个比特之前,必须接收到整个分组。
排队时延和分组丢失(Queuing Delays and Packet Loss),每台交换机有多条链路与之相连,对于每条相连的链路,该分组交换机具有一个输出缓存(output buffer,也叫输出队列,output queue),用于存储路由器准备发往那条链路的分组。如果输出缓存已满,将出现分组丢失(packet loss,丢包)。
转发表和路由选择协议(Forwarding Tables and Routing Protocols),路由器如何决定将分组转发到哪一条链路?每台路由器具有一个转发表,用于将目的地址(或目的地址一部分)映射成为输出链路。因特网具有一些特殊的路由选择协议,用于自动设置转发表。
2.电路交换(circuit switching)
在电路交换网络中,为终端系统之间的通信提供沿路径所需的资源(缓冲区、链路传输速率)在终端系统之间的通信会话期间保留。 在分组交换网络中,这些资源是不保留的; 会话的消息按需使用资源,因此可能必须等待(即排队)才能访问通信链路。
电路交换网中的复用,通过频分复用(frequency-division multiplexing)和时分复用( time-division multiplexing)实现。

频分可理解为并行,每条链路使用不同的频谱同时传输;时分理解为并发,将时域分割为帧,每帧具有特定的时隙(time slot),不同的链路传输使用不同的时隙。
分组交换和电路交换比较:
分组交换的性能可以优于电路交换。电路交换预先分配传输链路的使用,而不考虑需求,分配但不需要的链路时间未使用。另一方面,分组交换按需分配链路使用。链路传输容量将仅在具有需要通过链路传输的数据包的用户之间以逐个数据包的方式共享。尽管分组交换和电路交换在当今的电信网络中都很普遍,但趋势肯定是朝着分组交换的方向发展。甚至今天的许多电路交换电话网络也在缓慢地向分组交换迁移。特别是,电话网络经常使用分组交换来处理电话呼叫中昂贵的海外部分。
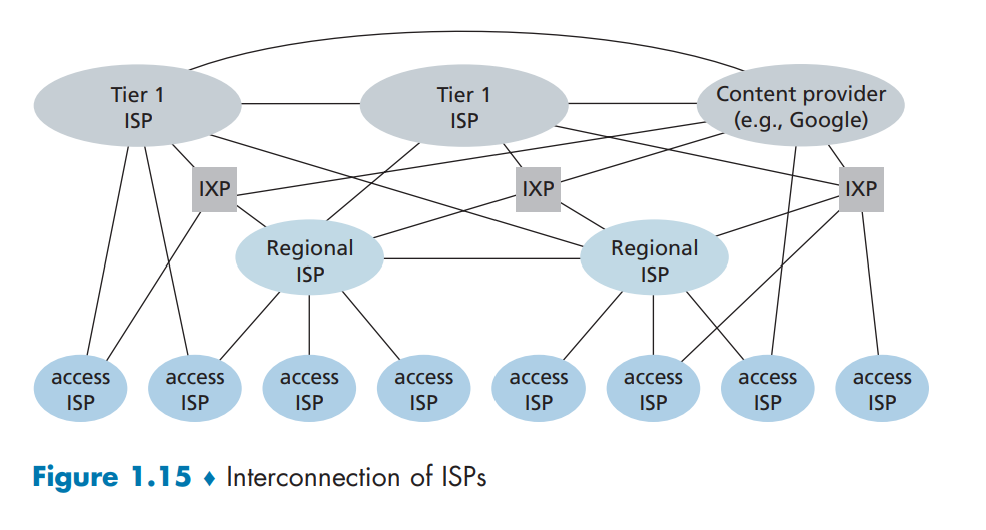
网络的网络
IXP(Internet Exchange Point,因特网交换点)是一个汇合点,多个ISP能够在这里一起对等(peer),即位于相同等级结构层次的邻近一对ISP直接将它们的网络连接到一起。
这个生态系统为网络结构4,由接入ISP、区域ISP、第一层ISP、PoP、多宿(multi-home)、对等和IXP组成。
在网络结构4的顶部增加内容提供商网络(content provider network)便构建成网络结构5,描述了现今的因特网。
分组交换网中的时延、丢包和吞吐量(每秒能传送的数据量)
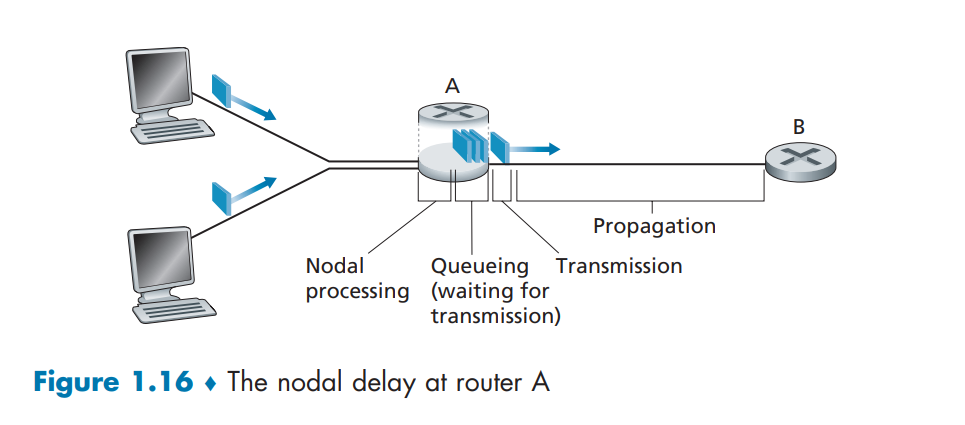
时延:节点处理时延(nodal processing delay)、排队时延(queuing delay)、传输时延(transmission delay)和传播时延(propagation delay),这些时延累加起来是节点总时延(total nodal delay)。
需注意传输时延和传播时延的区别:传输时延是路由器推出分组所需的时间,是分组长度和链路传输速率的函数,与两台路由器之间的距离无关;传播时延是一个比特从一台路由器传播到另一台路由器所需的时间,是两台路由器之间的距离函数,与分组长度和链路传输速率无关。
排队时延是节点时延最复杂有趣的成分。举例:R是链路传输速率(从队列中推出比特的速率,bps,比特每秒),a表示分组到达队列的平均速率(分组/秒),分组由L比特组成,则比特到达队列的平均速率是:La bps,比率:La/R称为(traffic intensity)。
La/R > 1则会出现丢包。
吞吐量受限于连接链路中的瓶颈链路(bottleneck link),即传输路径中吞吐量最小的链路。
协议层次和服务模型
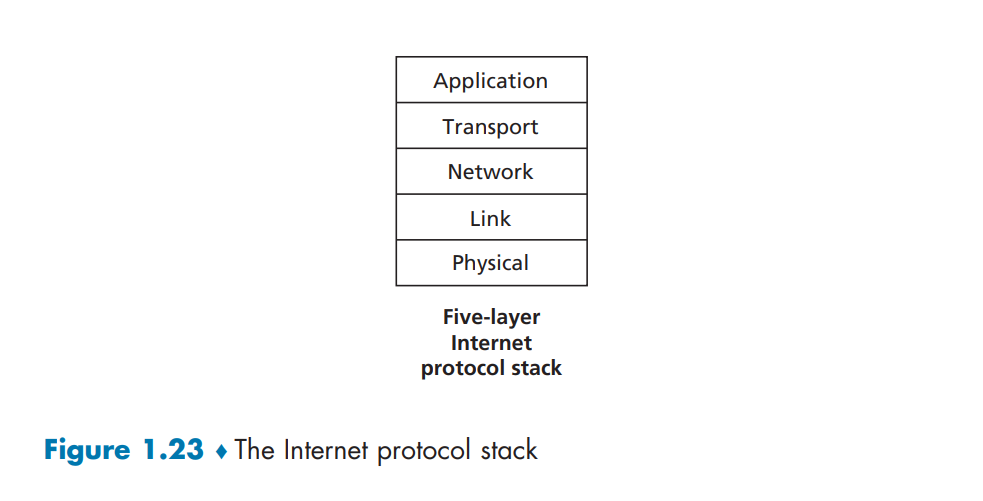
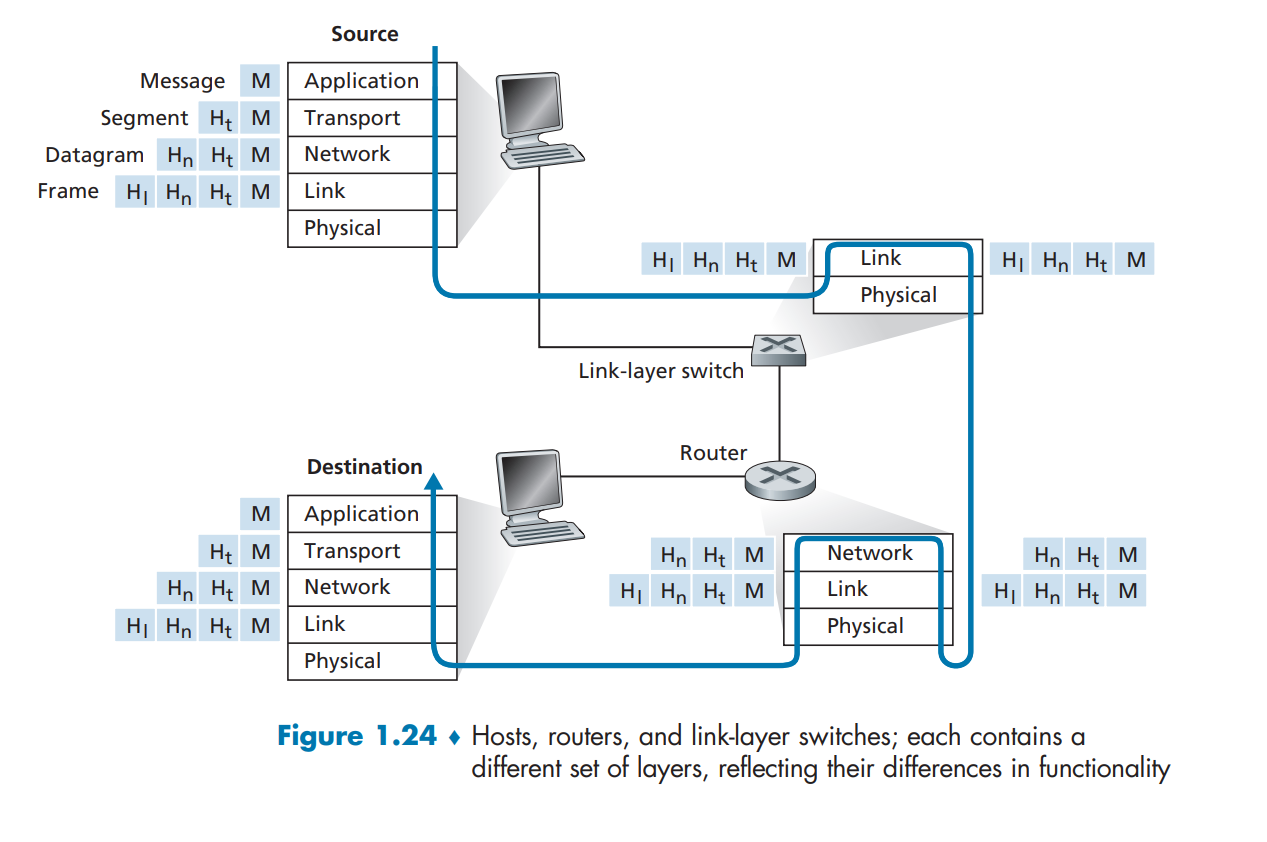
协议分层,一个协议层可以用软件、硬件或两者结合来实现。应用层和传输层协议一般是软件实现,网络层协议是软件和硬件实现的混合体。所有这些综合起来各层所有协议称为协议栈(protocol stack)。因特网的协议栈由5层组成:物理层、链路层、网络层、传输层、应用层。
OSI模型:开放系统互连模型,应用层、表示层、会话层、传输层、网络层、链路层、物理层。
封装:
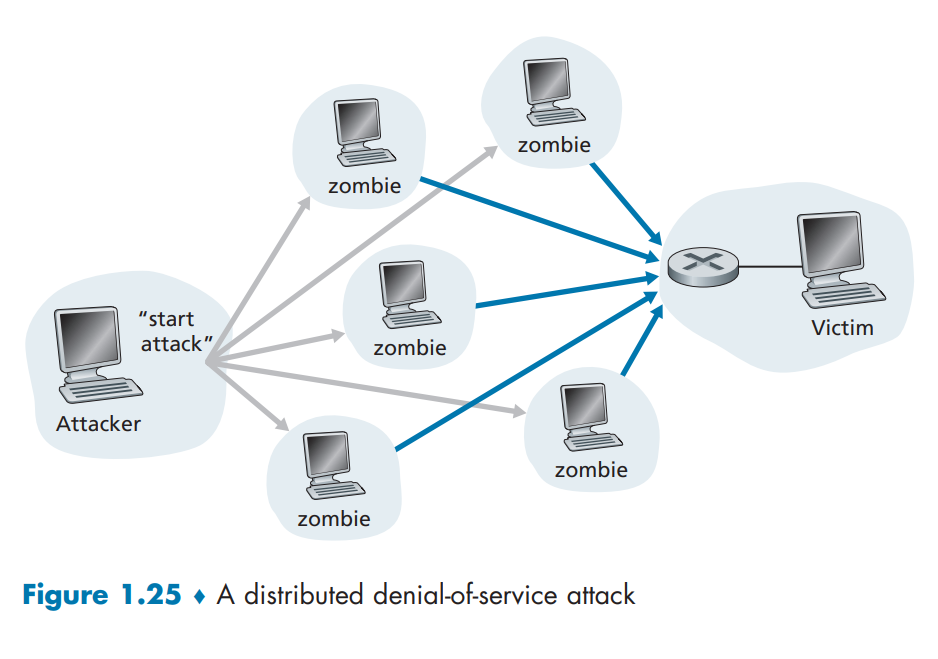
网络攻击:
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案
我在这方面尝试了很多URL,在我遇到这个特定的之前,它们似乎都很好:require'rubygems'require'nokogiri'require'open-uri'doc=Nokogiri::HTML(open("http://www.moxyst.com/fashion/men-clothing/underwear.html"))putsdoc这是结果:/Users/macbookair/.rvm/rubies/ruby-2.0.0-p481/lib/ruby/2.0.0/open-uri.rb:353:in`open_http':404NotFound(OpenURI::HT
Ruby中如何“一般地”计算以下格式(有根、无根)的JSON对象的数量?一般来说,我的意思是元素可能不同(例如“标题”被称为其他东西)。没有根:{[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]}根包裹:{"posts":[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]} 最佳答案 首先,withoutroot代码不是有效的json格式。它将没有包