
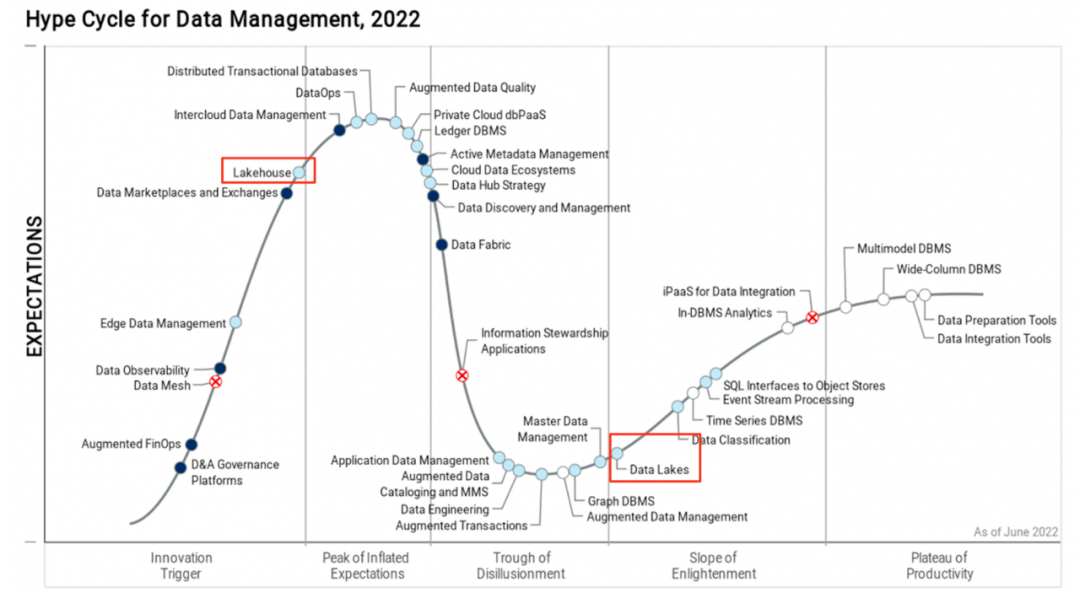
 还有一份报告值得关注,在 2021 (2022 的报告还未发布)最新发布的数据库魔力象限中,主打 lakehouse 产品的 databricks 和 snowflake 携手进入领导力第一象限,而去年这份报告中,只有 snowflake 处于挑战者的位置:
还有一份报告值得关注,在 2021 (2022 的报告还未发布)最新发布的数据库魔力象限中,主打 lakehouse 产品的 databricks 和 snowflake 携手进入领导力第一象限,而去年这份报告中,只有 snowflake 处于挑战者的位置: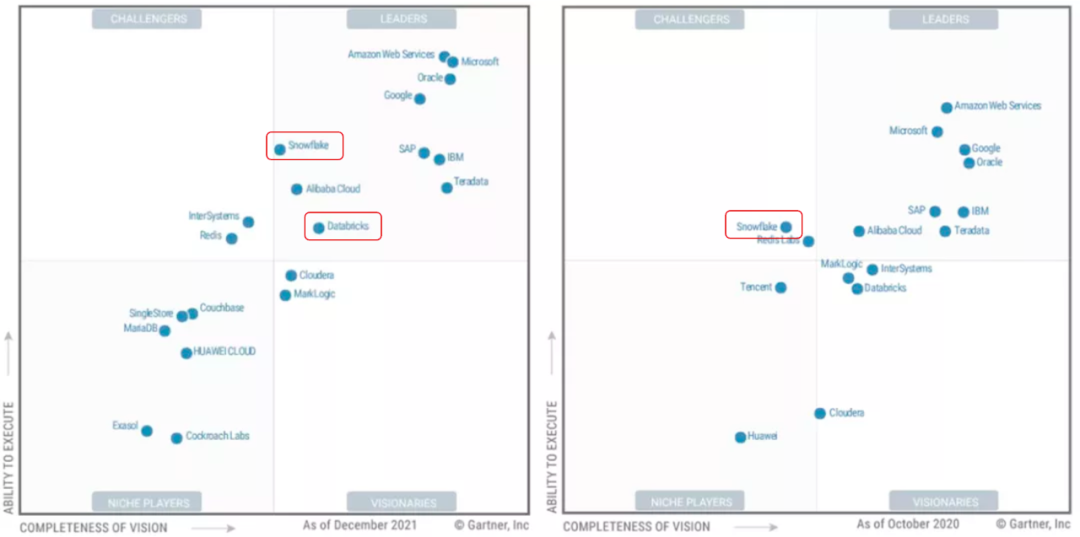 Lakehouse 不光在技术圈受捧,在资本圈也是鼎鼎有名,巴老爷子加持的 snowflake 千亿神话自不必说,databricks 经过多轮融资之后,也达到了 380 亿美金的估值。就在前不久,delta2.0 完全开源了(过去只开源了一部分)。
Lakehouse 不光在技术圈受捧,在资本圈也是鼎鼎有名,巴老爷子加持的 snowflake 千亿神话自不必说,databricks 经过多轮融资之后,也达到了 380 亿美金的估值。就在前不久,delta2.0 完全开源了(过去只开源了一部分)。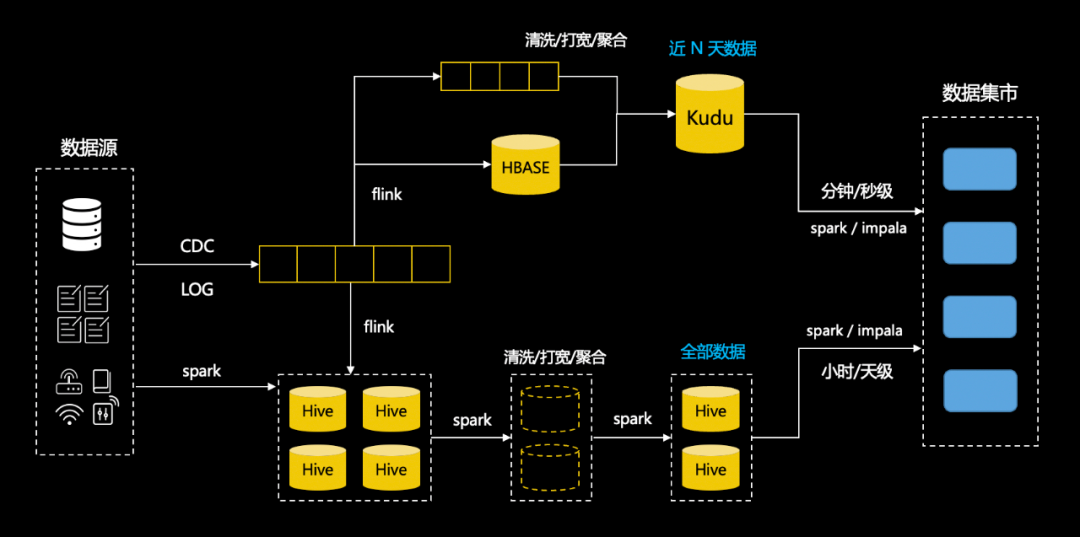 场景中用 hive 做批表,kafka 做流表,实时场景下需要用户构建数据库同步到 hbase 的实时任务,需要用户实现 join hbase 维表的流计算任务,把数据写到支持实时更新的 kudu 中,最后由业务根据实时和离线的需要选择查询 kudu 表还是 hive 表,在此之前,用户需要分别在数据模型中建表,使用 kudu 的工具建表,并且自己处理两个系统的差异。在这个架构中,用户遭受了割裂的体验,并且需要在上层做很多工作。在这套 lambda 架构中,用户使用 hive 和离线开发工具构建离线数仓,使用 kudu,hbase 和实时开发平台构建实时任务,相同的业务逻辑构建了两套数据模型,维护两套数仓和两套任务链路,造成人效和资源的浪费,语义的二义性也会给维护带来更大的成本,对数据分析师,算法工程师,数据科学家,去熟悉两套规范和工具,理解更多的底层概念也是一项很大的挑战。比如对网易云音乐而言,数据分析师和算法工程师很多,怎样尽可能提效和降本是一个很有意义的课题,而对一些规模有限的业务团队,人力紧张,也可能没有多余的预算来搭建两套系统,既快且省可能是第一位的诉求。理解了流批一体的必要性,那么为什么要基于数据湖做流批一体?第一数据湖是个兜底的存储中心,具有极强的弹性伸缩能力,符合“省”的要求,第二过去我们围绕数据湖已经搭建了非常丰富的工具,而且现在依然在向 dataops 的方向持续演进,基于这套方法论也沉淀了非常多的规范和实践,如果基于数据湖做流批一体,数据中台上的很多能力可以复用,快速上手,符合业务对“快”的需求。反之如果我们使用其他数仓做流批一体,比如 doris,相当于在数据湖之外又构建了一个数据孤岛,在依然需要数据湖的情况下,业务需要自己处理 doris 和数据湖的传输和一致性,没有从根本上解决问题。
场景中用 hive 做批表,kafka 做流表,实时场景下需要用户构建数据库同步到 hbase 的实时任务,需要用户实现 join hbase 维表的流计算任务,把数据写到支持实时更新的 kudu 中,最后由业务根据实时和离线的需要选择查询 kudu 表还是 hive 表,在此之前,用户需要分别在数据模型中建表,使用 kudu 的工具建表,并且自己处理两个系统的差异。在这个架构中,用户遭受了割裂的体验,并且需要在上层做很多工作。在这套 lambda 架构中,用户使用 hive 和离线开发工具构建离线数仓,使用 kudu,hbase 和实时开发平台构建实时任务,相同的业务逻辑构建了两套数据模型,维护两套数仓和两套任务链路,造成人效和资源的浪费,语义的二义性也会给维护带来更大的成本,对数据分析师,算法工程师,数据科学家,去熟悉两套规范和工具,理解更多的底层概念也是一项很大的挑战。比如对网易云音乐而言,数据分析师和算法工程师很多,怎样尽可能提效和降本是一个很有意义的课题,而对一些规模有限的业务团队,人力紧张,也可能没有多余的预算来搭建两套系统,既快且省可能是第一位的诉求。理解了流批一体的必要性,那么为什么要基于数据湖做流批一体?第一数据湖是个兜底的存储中心,具有极强的弹性伸缩能力,符合“省”的要求,第二过去我们围绕数据湖已经搭建了非常丰富的工具,而且现在依然在向 dataops 的方向持续演进,基于这套方法论也沉淀了非常多的规范和实践,如果基于数据湖做流批一体,数据中台上的很多能力可以复用,快速上手,符合业务对“快”的需求。反之如果我们使用其他数仓做流批一体,比如 doris,相当于在数据湖之外又构建了一个数据孤岛,在依然需要数据湖的情况下,业务需要自己处理 doris 和数据湖的传输和一致性,没有从根本上解决问题。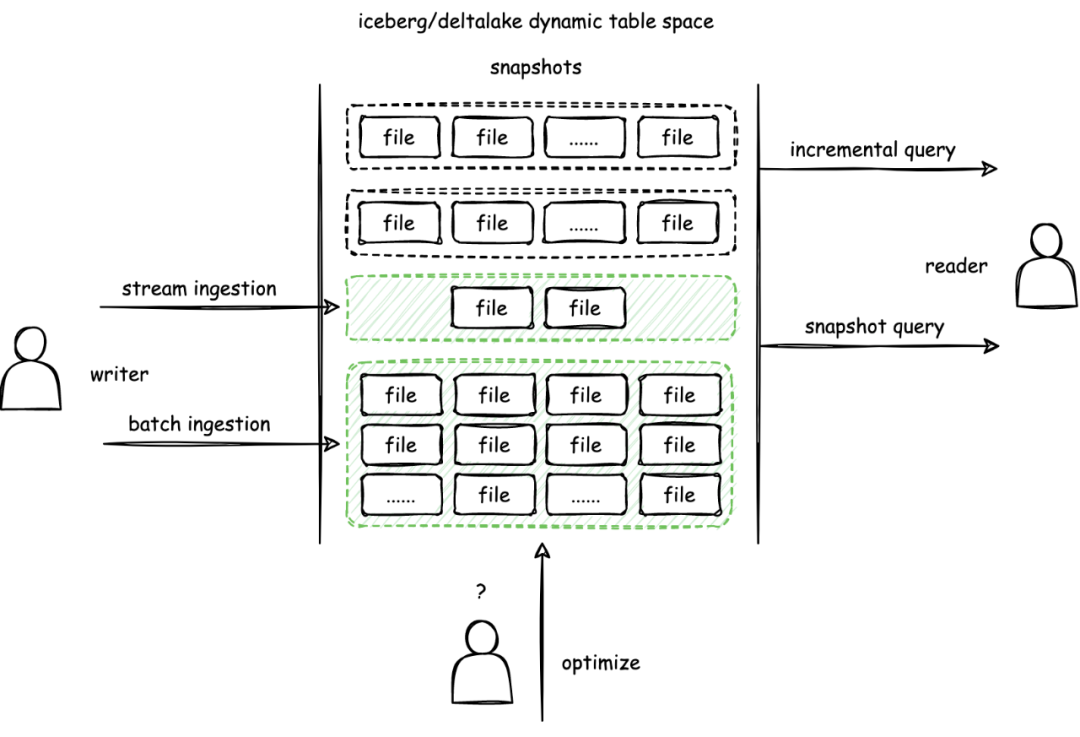
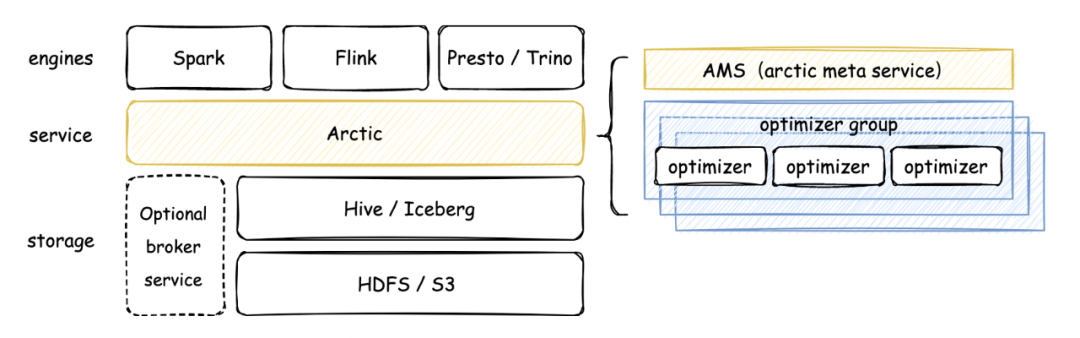 可以看到,Arctic 的核心组件包含 AMS 和 Optimizer,在 arctic 中,AMS 被定义为新一代 HMS,AMS 管理 Arctic 所有 schema,向计算引擎提供元数据服务和事务 API,以及负责触发后台结构优化任务。Arctic 作为流式湖仓服务,会在后台持续进行文件结构优化操作,并致力于这些优化任务的可视化和可测量,优化操作包括但不限于小文件合并,数据分区,数据在 Tablestore 之间的合并转化。Optimizer container 是 optimizing 任务调度的容器,目前生产环境主要是在 yarn 上调度,支持扩展 optimizer container 实现调度到 k8s 或其平台。Optimizer group 用于资源隔离,optimizing container 下可以设置一个或多个 optimizer group,也可以通过 optimizer group 实现优先级的功能,在 yarn 上 optimizer container 对应队列。篇幅关系不再对 arctic 的架构与概念进一步展开,感兴趣的同学可以移步我们的文档,后续我也会在其他的文章里聊聊 arctic 在架构设计中的考量,与其他产品的差异。
可以看到,Arctic 的核心组件包含 AMS 和 Optimizer,在 arctic 中,AMS 被定义为新一代 HMS,AMS 管理 Arctic 所有 schema,向计算引擎提供元数据服务和事务 API,以及负责触发后台结构优化任务。Arctic 作为流式湖仓服务,会在后台持续进行文件结构优化操作,并致力于这些优化任务的可视化和可测量,优化操作包括但不限于小文件合并,数据分区,数据在 Tablestore 之间的合并转化。Optimizer container 是 optimizing 任务调度的容器,目前生产环境主要是在 yarn 上调度,支持扩展 optimizer container 实现调度到 k8s 或其平台。Optimizer group 用于资源隔离,optimizing container 下可以设置一个或多个 optimizer group,也可以通过 optimizer group 实现优先级的功能,在 yarn 上 optimizer container 对应队列。篇幅关系不再对 arctic 的架构与概念进一步展开,感兴趣的同学可以移步我们的文档,后续我也会在其他的文章里聊聊 arctic 在架构设计中的考量,与其他产品的差异。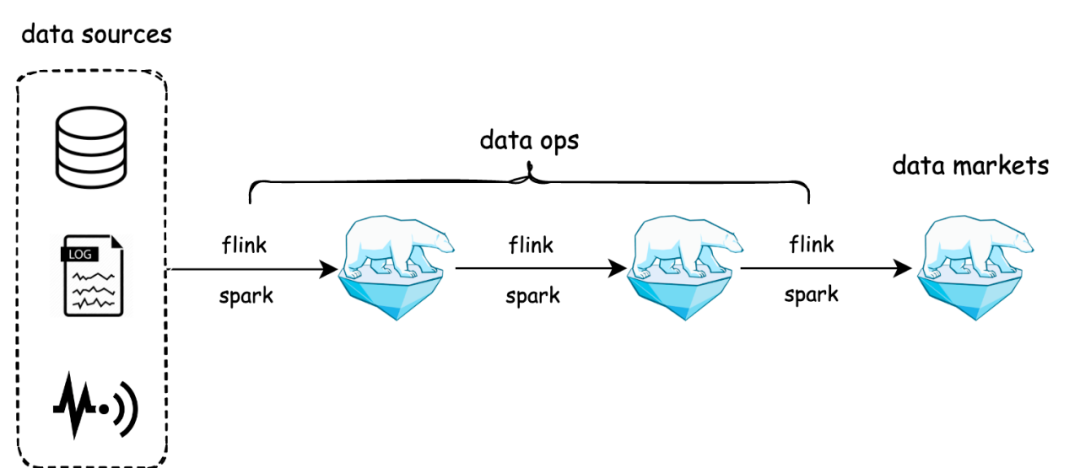 与原先流批割裂的 lambda 架构相比,arctic 用存储统一了数据生产的链路,arctic 表既可以作为离线表给 spark 用,也可以作为流表给 flink 用,还可以用 impala/trino 的 OLAP 引擎查询 arctic 表,构建数据集市。值得一提的是,arctic 的流表能够做到毫秒到秒级,arctic 将用户需要的消息队列,作为 broker service 封装到 arctic 的管理体系里,用户只需要在创建表的时候指定是否需要引入队列,在后续的使用中即可透明无感地用到消息队列实时分发的能力,arctic 在对接 flink 的 connector 中,封装了消息队列与数据湖的双写和一致性保障。在 AP 性能上,arctic 通过 optimizer 机制实现表的结构自优化,在我们的 benchmark 测试中,流式写入 iceberg 表 1 个小时以后,因为小文件问题,以及一些不完善,性能下降会非常厉害,1.5 小时候数据已经跑不出来了,arctic 的平均延迟维持在 20s 左右,而 hudi 30s 左右(平均延迟越小,性能越好),详细的 benchmark 报告可以移步:https://arctic.netease.com/ch/benchmark/
与原先流批割裂的 lambda 架构相比,arctic 用存储统一了数据生产的链路,arctic 表既可以作为离线表给 spark 用,也可以作为流表给 flink 用,还可以用 impala/trino 的 OLAP 引擎查询 arctic 表,构建数据集市。值得一提的是,arctic 的流表能够做到毫秒到秒级,arctic 将用户需要的消息队列,作为 broker service 封装到 arctic 的管理体系里,用户只需要在创建表的时候指定是否需要引入队列,在后续的使用中即可透明无感地用到消息队列实时分发的能力,arctic 在对接 flink 的 connector 中,封装了消息队列与数据湖的双写和一致性保障。在 AP 性能上,arctic 通过 optimizer 机制实现表的结构自优化,在我们的 benchmark 测试中,流式写入 iceberg 表 1 个小时以后,因为小文件问题,以及一些不完善,性能下降会非常厉害,1.5 小时候数据已经跑不出来了,arctic 的平均延迟维持在 20s 左右,而 hudi 30s 左右(平均延迟越小,性能越好),详细的 benchmark 报告可以移步:https://arctic.netease.com/ch/benchmark/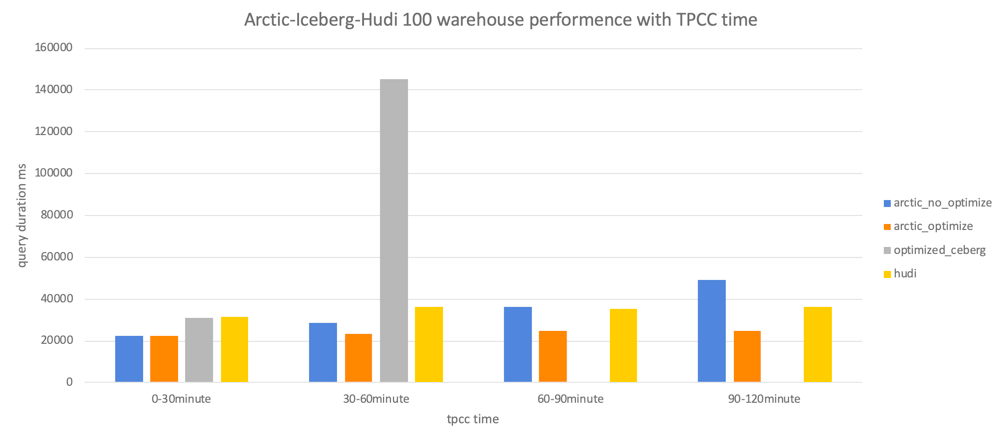 Arctic 流批一体的能力可以拓展数据中台,或 dataops 的边界,更直观点说,用户可以直接用各种有数的中台工具来实现流批一体,比如今年我们在帮有道做的替换 doris,和传媒一起做的替换 clickhouse,业务在使用之前的系统时,缺乏高效率的工具,还要为这些独立部署的资源买单,切到 arctic 之后,由于数据湖高度弹性的能力,和低成本的特性,可以给用户省钱提效。Arctic 不光可以用在大数据场景,今年调研发现,在线业务也有一些需要存储大体量的历史数据,或者 AP 和 TP 混用的场景,比如风控场景需要存储非常多日志清洗后的数据,而这些数据全部存储在 ES 里成本会失控,我们和云音乐团队一起做了一个数据湖与 ES 混合使用的方案,数据湖来兜底,会存储非常久的数据,并且是实时入湖,在我们测量下,用数据湖来实现冷热分离,占用的空间小 XX 倍,成本上则带来几十倍的提升。
Arctic 流批一体的能力可以拓展数据中台,或 dataops 的边界,更直观点说,用户可以直接用各种有数的中台工具来实现流批一体,比如今年我们在帮有道做的替换 doris,和传媒一起做的替换 clickhouse,业务在使用之前的系统时,缺乏高效率的工具,还要为这些独立部署的资源买单,切到 arctic 之后,由于数据湖高度弹性的能力,和低成本的特性,可以给用户省钱提效。Arctic 不光可以用在大数据场景,今年调研发现,在线业务也有一些需要存储大体量的历史数据,或者 AP 和 TP 混用的场景,比如风控场景需要存储非常多日志清洗后的数据,而这些数据全部存储在 ES 里成本会失控,我们和云音乐团队一起做了一个数据湖与 ES 混合使用的方案,数据湖来兜底,会存储非常久的数据,并且是实时入湖,在我们测量下,用数据湖来实现冷热分离,占用的空间小 XX 倍,成本上则带来几十倍的提升。无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
伴随农业机械化和智能化的发展,越来越多的人开始使用农机自动驾驶系统助力耕作,千耘农机导航的“星地一体”能力可有效解决信号受限的问题,实现作业提效。究竟什么是“星地一体”,又是如何解决智能化农机作业的痛点的?下面为大家揭秘。农机效率通常受限于通信网络目前虽然我国通讯网络的人口覆盖率达到99%,但地面移动通讯网络覆盖率仍小于国土面积的40%,而很多农田所在区域恰是山区、戈壁滩等偏远地区。两省交界地也会出现通信信号不稳定的状况;而国内大部分农机自动驾驶系统非常依赖通信网络,当通信网络弱的时候会出现系统掉线的现象,必须得携带小基站才能正常使用,极为繁琐。Q:什么是千耘农机导航“星地一体”能力?A:是星
目录1古彝文与古典保护2古文识别的挑战2.1西文与汉文OCR2.2古彝文识别难点3合合信息:古彝文保护新思路3.1图像矫正3.2图像增强3.3语义理解3.4工程技巧4总结1古彝文与古典保护彝文指的是云南、贵州、四川等地的彝族人使用的文字,区别于现代意义上的彝文,古彝文指的是在民间流通使用的原生态彝文,多达87046字。古彝文的起源距今至少数千年,是世界上最古老的文字之一。对古彝文字集研究有助于理解尚未被翻译成汉文、用字尚未规范化的古籍,更深层、透彻地作用于传统文化保护。古彝文字义对照图(网络资料+邵文苑供图)古籍是不可再生的宝贵资源,应当得到妥善保护。中国的古籍在历史上迭经水火兵燹等自然灾害、
文章目录背景一、最初的疑惑二、简单聊聊原理三、组织内实践案例四、实践带来的反思五、最后聊几句问题背景这个概念由来已久,但是在国内兴起,是最近几年;低代码即Low-Code;指提供可视化开发环境,可以用来创建和管理软件应用;简单的说就是可以通过各种组件的拖拽,实现页面的创建,交互流程和逻辑,以及数据层面的管理,更加高效的实现需求;早先在数据公司时;见识过低代码的应用,也参与过部分研发,比如元数据平台,BI分析等;不过,当时还是以数据管理的工具来定义项目,并非是低代码;从「2020年底」开始;实际上,那个时间节点,低代码平台的应用已经形成趋势了;现在的公司,将低代码平台的使用规划到业务体系中;后来
一、乱花迷人眼我就是被迷的那双眼。有时候需求来了,用熟悉的套路进行开发,确实很节省时间也能保证功能的稳定,但是这些开发的惯性无形中阻碍了我对技术的探索。我一直想改造详情页,解放重复功能开发的劳动力,但是详情页一眼望都是内容平铺,好像并没有什么可做的代码设计。后来我拨开繁花,发现详情页的组件化不必想的过于复杂,后台系统风格统一即可。因为大部分的详情页面是内容的展示,偶尔会出现少量的操作功能。将风格统一的部分进行组件化处理,操作功能使用回调函数放回当前页面,避免组件里做过多的业务逻辑。看,这不就成了。项目基于React框架开发的,所以代码写法是JSX语法,组件开发使用的hooks函数式组件,UI框
Python3.6.9Flink1.15.2消费KafakaTopicPyFlink基础应用之kafka通过PyFlink作业处理Kafka数据1环境准备1.1启动kafka(1)启动zookeeperzkServer.shstart(2)启动kafkacd/usr/local/kafka/nohup./bin/kafka-server-start.sh./config/server.properties>>/tmp/kafkaoutput.log2>&1&或者./bin/kafka-server-start.sh-daemon./config/server0.properties(3)查看进
英文标题:ANovelSignalDesignandAnalysisforNavcom中文标题:一种导通一体化信号设计分析作者:JiJing,ChenWei,LiuYuting,DuLuyao,LuHongyang一、背景简介 北斗三号全球系统已于2020年完成全球部署和联网服务(图1),而北斗三号之后,国家综合定位、导航、授时体系(PNT)的工作也被提上日程,即2030年将构建成一个以北斗系统为核心,弹性、泛在的国家综合PNT体系(图2)建成天地一体、覆盖无缝、安全可信、高效便捷的国家综合PNT体系,显著提升国家时空信息服务能力,满足国民经济和国家安全需求,为全球用户提供更为优质的服务
记得点击文章末尾的“ 阅读原文 ”查看哟~下面先一起看下本期周刊 摘要 吧~奇舞推荐■■■ ChatGPT的狂飙之路最近随着ChatGPT爆火出圈,网络上各种关于ChatGPT的争论声也不断;有些人把它当成一个更高级的聊天机器人,有人兴奋地看到了创业的风口,而另一些人对它取代人类的工作露出了不少担忧;那么它到底是推动社会不断前进的工具,还是妄图颠覆人类社会的T-1000?本文我们来深入的探讨一下ChatGPT的那些事。 带你看看前端生态圈的技术趋势今年的state-of-css调查共回收了14310份问卷结果,state-of-js调查共回收了39472份问卷结果,希望各位能在这些数据和分析中
LVS文章目录LVS一、负载均衡集群介绍1、集群是什么?2、负载均衡集群技术3、负载均衡集群技术实现方式和产品4、负载均衡实现效果图5、负载均衡分类6、四层负载均衡与七层负载均衡的区别二、LVS介绍三、LVS工作模式1、LVS负载均衡的四种工作模式2、四种工作模式的原理、优缺点3、四种工作模式的区别四、LVS管理工具——ipvsadm五、LVS负载均衡集群实战应用1、环境:2、搭建web服务器3、LVS负载均衡配置4、验证六、LVS的调度算法1、静态算法2、动态算法七、LVS健康监测脚本一、负载均衡集群介绍1、集群是什么?集群技术是一种较新的技术,可以在付出较低成本的情况下获得在性能、可靠性、
汽车供应链管理系统开发可以降低供应链成本和库存,并提高运营效率。如何打造高效B2B供应链电商平台?汽车供应链系统制作平台数商云表示,B2B供应链采购管理系统方案服务优势何在,汽车供应链管理系统解决方案既提高供应商的可视度、实现企业间沟通并提供高级系统集成,又为企业带来高投资回报率。现阶段国内汽车保有量、销量远低于全球发达国家市场水平,可见我国汽车以及汽配市场发展有较大的增长空间。因为国内大多数汽车交易、维修等汽车后市场服务具有高度的专业性、个性化、信息不对称特征,汽车企业仅凭线下模式难以实现大规模发展。B2B供应链电商系统平台解决方案,如何实现全网资源整合?汽车电商供应链采购系统服务商【数商云