😊😊😊欢迎来到本博客😊😊😊
本次博客内容将继续讲解关于OpenCV的相关知识
🎉作者简介:⭐️⭐️⭐️目前计算机研究生在读。主要研究方向是人工智能和群智能算法方向。目前熟悉深度学习(keras、pytorch、yolo),python网页爬虫、机器学习、计算机视觉(OpenCV)、群智能算法。然后正在学习深度学习的相关内容。以后可能会涉及到网络安全相关领域,毕竟这是每一个学习计算机的梦想嘛!
📝目前更新:🌟🌟🌟目前已经更新了关于网络爬虫的相关知识、机器学习的相关知识、目前正在更新计算机视觉-OpenCV的相关内容。
💛💛💛本文摘要💛💛💛
本文我们将继续讲解计算机视觉领域项目-基于特征点匹配的图像拼接。
文章目录
之前我们介绍过基于OpenCv的特征匹配操作,我们通过特征匹配可以精确的找到目标。本节我们继续探索基于特征匹配还可以做哪些事情。我们都在拍一个集体的过程中使用过苹果手机的全图效果进行拍照留念。那么苹果手机这个效果它是基于什么技术来做的呢?没错其实就是特征匹配。他是实时拍取多个照片,然后使用特征匹配操作继续两个图像之间特征点的匹配,然后生成转换矩阵,最后转换成效果图,我们本次博客就是要介绍一下这个操作如何使用OpenCv进行实现。
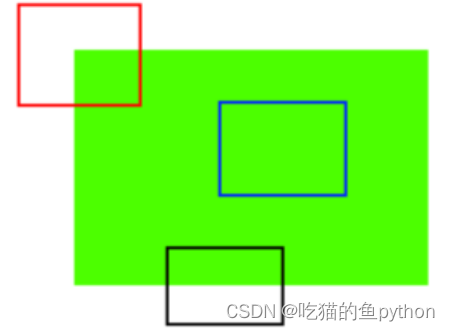
原理图,这里第一个图表示的就是平面灰度值没有明显变化,第二个图就是要给边界灰度值水平方向变化明显垂直方向灰度值变化并不明显,第三个图表示的就是一个角点,无论水平还是垂直方向都很明显。主要看灰度级的变化结果:
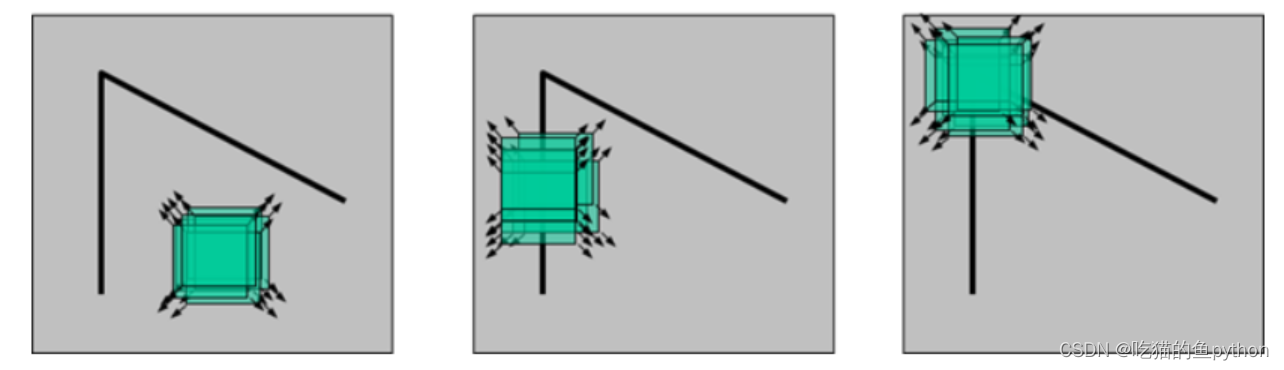
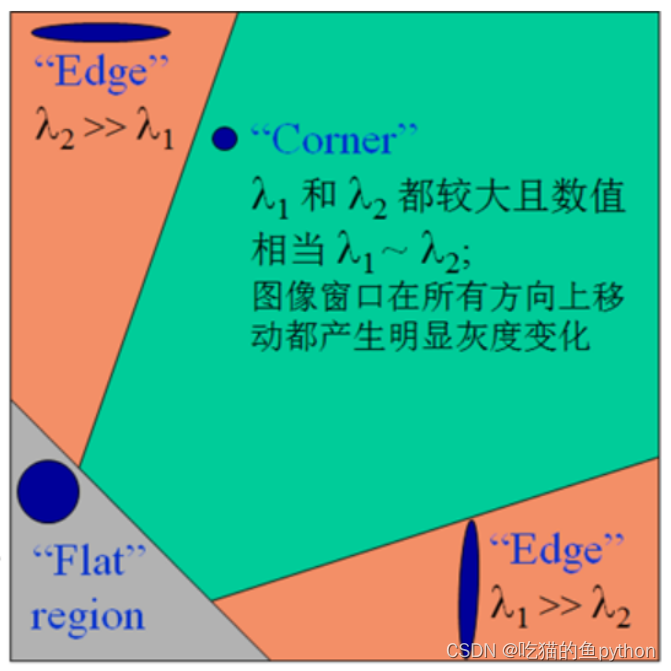
边界:一个特征值大,一个特征值小,自相关函数在某一个方向上大,在其他方向上小。
平面:两个特征都小,且近似相等。
角点:两个特征都大,且近似相等,自相关函数在所有方向都大。
在OpenCV当中我们使用,cv2.cornerHarris()来进行角点检测。
其中参数都有:

import cv2
import numpy as np
img = cv2.imread('white-black.webp')
print ('img.shape:',img.shape)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 2, 3, 0.04)
print ('dst.shape:',dst.shape)
img[dst>0.01*dst.max()]=[0,0,255]
cv2.imshow('dst',img)
cv2.waitKey(0)
cv2.destroyAllWindows()


这里有一些点检测的不是特别好,然后我们用黑白棋盘来看一下。

这个效果堪称完美!!!
SIFT是指尺度空间:是指在一定的范围内,无论物体是大是小,人眼都可以进行一个识别,然后计算机要去识别却很难,所以要让计算机能够对物体进行一个在不同尺度下都存在一个统一的认知,就要考虑图像在不同的尺度在都存在的特点,尺度空间的获取一般使用高斯模糊来实现-高斯滤波。
我们再说说SIFT有什么优点:
1、具有较好的稳定性和不变性,能够适应旋转、尺度缩放、亮度的变化,能在一定程度上不受视角变化、仿射变换、噪声的干扰。
2、区分性好,能够在海量特征数据库中进行快速准确的区分信息进行匹配
3、多量性,就算只有单个物体,也能产生大量特征向量
4、高速性,能够快速的进行特征向量匹配
5、可扩展性,能够与其它形式的特征向量进行联合
我们都知道如果图片经过高斯滤波操作之后呢,他会变模糊,那么为什么要这么做呢?因为当我们从很近的看一个人的时候,他是清晰的,那么从很远看的时候他就是模糊的。所以我们为了模拟这个过程,就用高斯滤波来进行相同了一个模拟。
不同σ的高斯函数决定了对图像的平滑程度,越大的σ值对应的图像越模糊。
因此我们要介绍一个金字塔,高斯差分金字塔。
我们需要做一个多分辨率的金字塔,对于金字塔的每一层都要做高斯滤波。
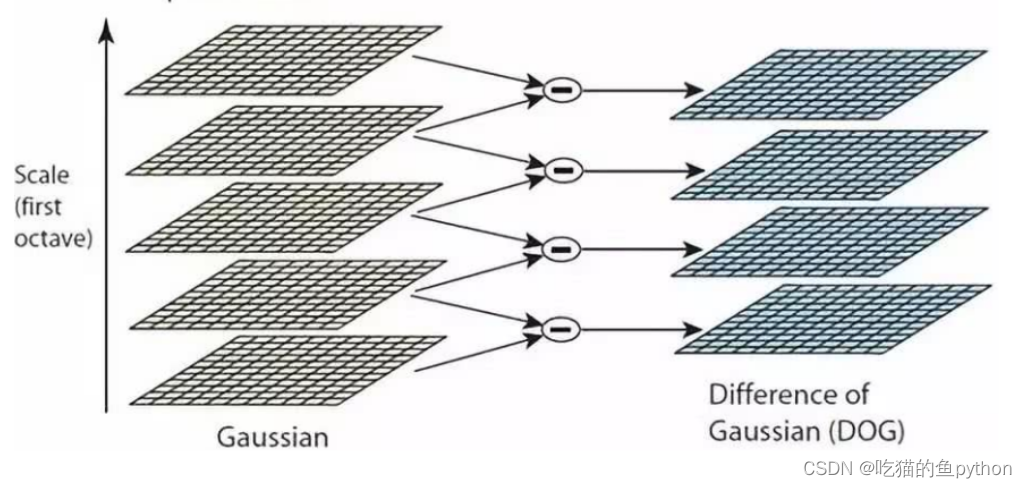
根据意思就是5个输入的高斯图像,相邻的进行像素值相减,得到4张差分后的结果。那么我们想要找什么呢?找SIFT,就是特征点,那么什么样的点被认为是特征点呢?通常关键点数值较大、差分结果较大的、极值里面较大的。是不是有点像之前讲的图像金字塔。
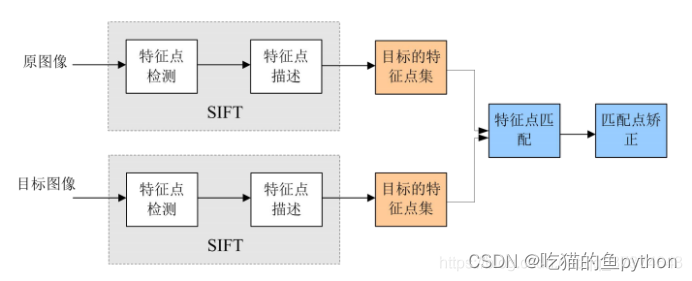
前面我们简单的将特征匹配介绍了一下,然后我们开始讲一下我们本次博客的内容。
主函数:
from Stitcher import Stitcher
import cv2
# 读取拼接图片
imageA = cv2.imread("left_02.jpg")
imageB = cv2.imread("right_02.jpg")
# 把图片拼接成全景图
stitcher = Stitcher()
(result, vis) = stitcher.stitch([imageA, imageB], showMatches=True)
# 显示所有图片
cv2.imshow("Image A", imageA)
cv2.imshow("Image B", imageB)
cv2.imshow("Keypoint Matches", vis)
cv2.imshow("Result", result)
cv2.waitKey(0)
cv2.destroyAllWindows()
在主函数这里我们把两张图像导入进来,注意这里的图像宽度必须一致,因为后续要进行拼接。长度可以保持不一致。然后我们进入拼接全景图的操作当中。
Stitcher()函数部分:
import numpy as np
import cv2
class Stitcher:
#拼接函数
def stitch(self, images, ratio=0.75, reprojThresh=4.0,showMatches=False):
#获取输入图片
(imageB, imageA) = images
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
M = self.matchKeypoints(kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh)
# 如果返回结果为空,没有匹配成功的特征点,退出算法
if M is None:
return None
# 否则,提取匹配结果
# H是3x3视角变换矩阵
(matches, H, status) = M
# 将图片A进行视角变换,result是变换后图片
result = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
#self.cv_show('result', result)
# 将图片B传入result图片最左端
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
#self.cv_show('result', result)
# 检测是否需要显示图片匹配
if showMatches:
# 生成匹配图片
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches, status)
# 返回结果
return (result, vis)
# 返回匹配结果
return result
首先我们将程序写成一个类,然后在类中使用self.detectAndDescribe()函数检测A、B图片的SIFT关键特征点,并计算特征描述子。
def detectAndDescribe(self, image):
# 将彩色图片转换成灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
descriptor = cv2.SIFT_create()
(kps, features) = descriptor.detectAndCompute(image, None)
kps = np.float32([kp.pt for kp in kps])
return (kps, features)
首先我们将图像转换成了灰度图,然后我们建立了使用SIFT检测特征点的检测器。然后对两张图片进行特征点检测,然后将结果转化成numpy数组并且返回。
然后在使用self.matchKeypoints()对特征点进行匹配。
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh):
# 建立暴力匹配器
matcher = cv2.BFMatcher()
# 使用KNN检测来自A、B图的SIFT特征匹配对,K=2
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
for m in rawMatches:
# 当最近距离跟次近距离的比值小于ratio值时,保留此匹配对
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
# 存储两个点在featuresA, featuresB中的索引值
matches.append((m[0].trainIdx, m[0].queryIdx))
# 当筛选后的匹配对大于4时,计算视角变换矩阵
if len(matches) > 4:
# 获取匹配对的点坐标
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# 计算视角变换矩阵
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)
# 返回结果
return (matches, H, status)
# 如果匹配对小于4时,返回None
return None
通过上述代码我们可以计算出来两张图象的视角变换矩阵,然后返回结果。最后进行可视化操作。
def drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):
# 初始化可视化图片,将A、B图左右连接到一起
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
# 联合遍历,画出匹配对
for ((trainIdx, queryIdx), s) in zip(matches, status):
# 当点对匹配成功时,画到可视化图上
if s == 1:
# 画出匹配对
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 255, 0), 1)
# 返回可视化结果
return vis
我们来看一下效果图:
左一图:

右一图:

最终效果图:

在用一个经典案例:



🔎支持:🎁🎁🎁如果觉得博主的文章还不错或者您用得到的话,可以免费的关注一下博主,如果三连收藏支持就更好啦!这就是给予我最大的支持!
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
如何匹配未被反斜杠转义的平衡定界符对(其本身未被反斜杠转义)(无需考虑嵌套)?例如对于反引号,我试过了,但是转义的反引号没有像转义那样工作。regex=/(?!$1:"how\\"#expected"how\\`are"上面的正则表达式不考虑由反斜杠转义并位于反引号前面的反斜杠,但我愿意考虑。StackOverflow如何做到这一点?这样做的目的并不复杂。我有文档文本,其中包括内联代码的反引号,就像StackOverflow一样,我想在HTML文件中显示它,内联代码用一些spanMaterial装饰。不会有嵌套,但转义反引号或转义反斜杠可能出现在任何地方。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我有一个驼峰式字符串,例如:JustAString。我想按照以下规则形成长度为4的字符串:抓取所有大写字母;如果超过4个大写字母,只保留前4个;如果少于4个大写字母,则将最后大写字母后的字母大写并添加字母,直到长度变为4。以下是可能发生的3种情况:ThisIsMyString将产生TIMS(大写字母);ThisIsOneVeryLongString将产生TIOV(前4个大写字母);MyString将生成MSTR(大写字母+tr大写)。我设法用这个片段解决了前两种情况:str.scan(/[A-Z]/).first(4).join但是,我不太确定如何最好地修改上面的代码片段以处理最后一种
我真的为这个而疯狂。我一直在搜索答案并尝试我找到的所有内容,包括相关问题和stackoverflow上的答案,但仍然无法正常工作。我正在使用嵌套资源,但无法使表单正常工作。我总是遇到错误,例如没有路线匹配[PUT]"/galleries/1/photos"表格在这里:/galleries/1/photos/1/edit路线.rbresources:galleriesdoresources:photosendresources:galleriesresources:photos照片Controller.rbdefnew@gallery=Gallery.find(params[:galle
我有带有Logo图像的公司模型has_attached_file:logo我用他们的Logo创建了许多公司。现在,我需要添加新样式has_attached_file:logo,:styles=>{:small=>"30x15>",:medium=>"155x85>"}我是否应该重新上传所有旧数据以重新生成新样式?我不这么认为……或者有什么rake任务可以重新生成样式吗? 最佳答案 参见Thumbnail-Generation.如果rake任务不适合你,你应该能够在控制台中使用一个片段来调用重新处理!关于相关公司
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
我已经在mountainlion上成功安装了rbenv和rubybuild。运行rbenvinstall1.9.3-p392结束于:校验和不匹配:ruby-1.9.3-p392.tar.gz(文件已损坏)预期f689a7b61379f83cbbed3c7077d83859,得到1cfc2ff433dbe80f8ff1a9dba2fd5636它正在下载的文件看起来没问题,如果我使用curl手动下载文件,我会得到同样不正确的校验和。有没有人遇到过这个?他们是如何解决的? 最佳答案 tl:博士;使用浏览器从http://ftp.rub
@raw_array[i]=~/[\W]/非常简单的正则表达式。当我用一些非拉丁字母(具体来说是俄语)尝试时,条件是错误的。我能用它做什么? 最佳答案 @raw_array[i]=~/[\p{L}]/使用西里尔字符进行测试。引用:http://www.regular-expressions.info/unicode.html#prop 关于ruby-正则表达式将非英文字母匹配为非单词字符,我们在StackOverflow上找到一个类似的问题: https://
