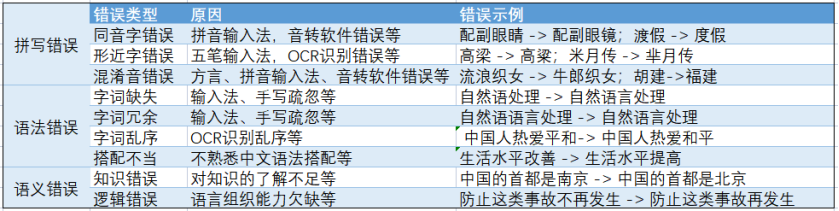
 整体处理难度上:拼写错误 < 语法错误 < 语义错误。
整体处理难度上:拼写错误 < 语法错误 < 语义错误。 图1检错模块检错模块的主要目标是错误识别,识别并定位出文本中的错误字/词位置,若存在则将错误向后传递。候选召回候选召回阶段针对检错模块识别到的错误点,结合历史错误信息,以及近音、近形等特征形成纠错候选集合。纠错模块纠错模块主要解决候选集合的排序问题,由于纠错的正确结果具有唯一性,该模块的任务是将正确的结果排在第一位。
图1检错模块检错模块的主要目标是错误识别,识别并定位出文本中的错误字/词位置,若存在则将错误向后传递。候选召回候选召回阶段针对检错模块识别到的错误点,结合历史错误信息,以及近音、近形等特征形成纠错候选集合。纠错模块纠错模块主要解决候选集合的排序问题,由于纠错的正确结果具有唯一性,该模块的任务是将正确的结果排在第一位。 图2 h代表隐藏层,c代表编码器和解码器之间的状态向量
图2 h代表隐藏层,c代表编码器和解码器之间的状态向量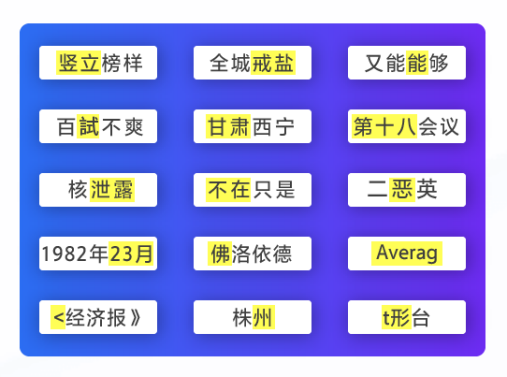 图3 文本纠错检错阶段的标注
图3 文本纠错检错阶段的标注我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
当谈到运行时自省(introspection)和动态代码生成时,我认为ruby没有任何竞争对手,可能除了一些lisp方言。前几天,我正在做一些代码练习来探索ruby的动态功能,我开始想知道如何向现有对象添加方法。以下是我能想到的3种方法:obj=Object.new#addamethoddirectlydefobj.new_method...end#addamethodindirectlywiththesingletonclassclass这只是冰山一角,因为我还没有探索instance_eval、module_eval和define_method的各种组合。是否有在线/离线资
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
我有这个代码:context"Visitingtheusers#indexpage."dobefore(:each){visitusers_path}subject{page}pending('iii'){shouldhave_no_css('table#users')}pending{shouldhavecontent('Youhavereachedthispageduetoapermissionic错误')}它会导致几个待处理,例如ManagingUsersGivenapractitionerloggedin.Visitingtheusers#indexpage.#Noreason
我一直在玩一个脚本,它在Chrome中获取选定的文本并在Google中查找它,提供四个最佳选择,然后粘贴相关链接。它以不同的格式粘贴,具体取决于当前在Chrome中打开的页面-DokuWiki打开的DokuWiki格式,普通网站的HTML,我想要我的WordPress所见即所得编辑器的富文本。我尝试使用pbpaste-Preferrtf来查看没有其他样式的富文本链接在粘贴板上的样子,但它仍然输出纯文本。在文本编辑中保存文件并进行试验后,我想出了以下内容text=%q|{\rtf1{\field{\*\fldinst{HYPERLINK"URL"}}{\fldrsltTEXT}}}|te
我使用“newapp_name”创建了一个新的Rails应用程序,我正在尝试编辑.gitignore文件,但在我的应用程序文件夹中找不到它。我在哪里可以找到它?我安装了Git。 最佳答案 .gitignore位于项目的root中,而不是app子目录中。首先打开终端并进入您的目录。您需要使用ls-a来显示stash文件。然后使用打开.gitignore 关于ruby-on-rails-尝试打开.gitignore以在文本编辑器中对其进行编辑,但在OSXMountainLion上找不到文件位
我想获取任意的ASCII文本字符串,例如“Helloworld”,并将其压缩为字符数较少(尽可能少)的版本,但要采用可以解压缩的方式。压缩版本应仅由ascii字符组成。有没有一种方法可以做到这一点,尤其是在Ruby中? 最佳答案 如果知道只会使用ASCII字符,那就是每个字节的低7位。通过位操作,您可以将每8个字节混合成7个字节(节省12.5%)。如果您可以将其放入更小的范围(仅限64个有效字符),则可以删除另一个字节。但是,因为您希望压缩形式也只包含ASCII字符,所以会丢失一个字节-除非您的输入可以限制为64个字符(例如,有损压
多年来,我在各种网站上遇到过各种问题,用户在字符串和文本字段的开头/结尾放置空格。有时这些会导致格式/布局问题,有时会导致搜索问题(即搜索顺序看起来不对,但实际上并非如此),有时它们实际上会使应用程序崩溃。我认为这会很有用,而不是像我过去所做的那样放入一堆before_save回调,向ActiveRecord添加一些功能以在保存之前自动调用任何字符串/文本字段上的.strip,除非我告诉它不是,例如do_not_strip:field_x,:field_y或类定义顶部的类似内容。在我去弄清楚如何做到这一点之前,有没有人看到更好的解决方案?明确一点,我已经知道我可以做到这一点:befor
我正在尝试使用nokogirigem提取页面上的所有url及其链接文本,并将链接文本和url存储在散列中。FooBar我想回去{"Foo"=>"#foo","Bar"=>"#bar"} 最佳答案 这是一个单行:Hash[doc.xpath('//a[@href]').map{|link|[link.text.strip,link["href"]]}]#=>{"Foo"=>"#foo","Bar"=>"#bar"}拆分一点可以说更具可读性:h={}doc.xpath('//a[@href]').eachdo|link|h[link.t