目录
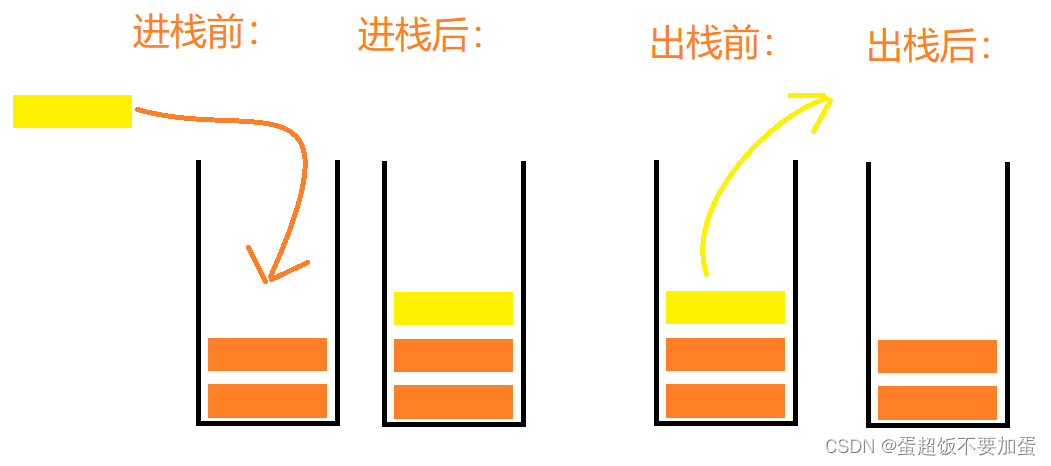
栈的实现:栈的实现有数组和链表两种方式,相对而言数组的结构实现更优一些,因为数组在尾部插入数据更加方便和高效
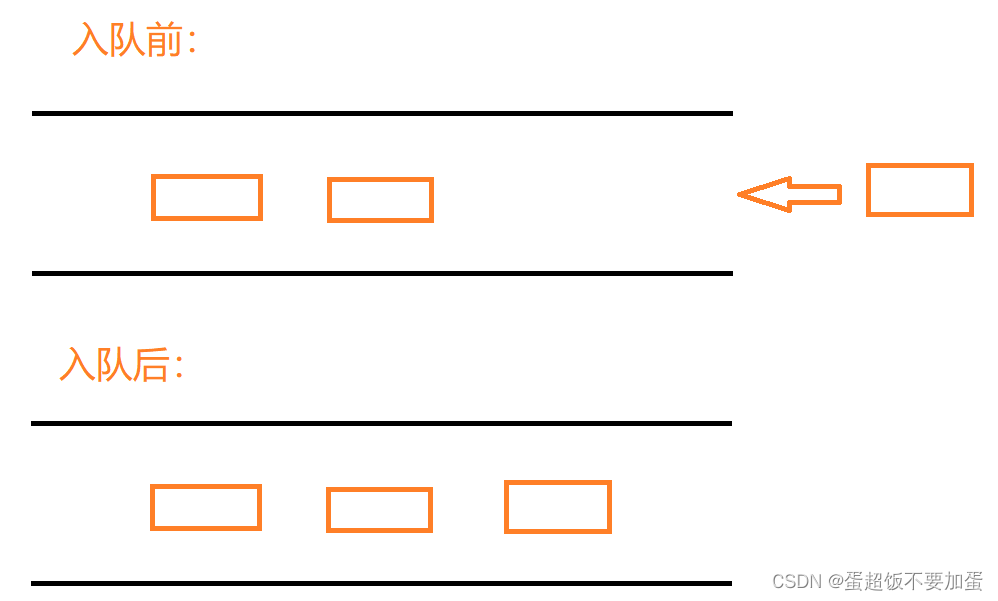
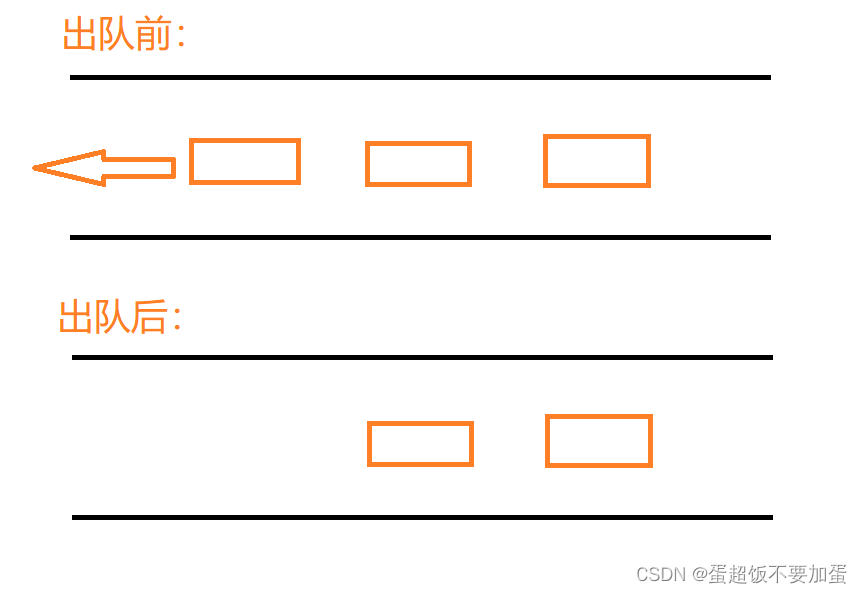
队列的实现:队列的实现有数组和链表两种方式,使用链表的结构更优一些,因为其头出数据更加方便和高效,而数组头出数据效率较低
栈采用数组实现更优,栈的基本操作有初始化、入栈、出栈、返回栈顶元素、获取栈元素个数、判空、销毁等操作
数组实现:
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;//栈顶元素的下一个位置
int capacity;//栈的最大容量
}Stack;栈的初始化需要给栈开辟一定的空间,top指针为栈顶元素的下一个元素,一开始栈没有元素,故将top置为0,然后给capacity一个值,这里我们设定为4,后续空间不够时再动态扩容
void StackInit(Stack* ps)
{
assert(ps);
ps->a = (STDataType *)malloc(sizeof(STDataType)*4);//申请空间
if (ps->a ==NULL)//申请失败则报错
{
perror("error:ps->a");
return;
}
ps->top = 0;//栈顶指向当前元素的下一个位置
ps->capacity = 4;//初始容量为4
}栈的入栈步骤:首先判断栈是否已满,若栈满则需要扩容,这里我们将最大容量翻倍,即增容为原来容量的2倍,扩容后再将值赋给top位置,top加1,若栈未满则直接将值赋给top位置,top加1
void StackPush(Stack* ps, STDataType data )
{
assert(ps);
if (ps->top >= ps->capacity)//栈顶下标大于最大容量则扩容
{
ps->capacity = ps->capacity * 2;//容量翻倍
ps->a = (STDataType*)realloc(ps->a, ps->capacity*sizeof(STDataType));
}
ps->a[ps->top++] = data;//元素入栈,栈顶指针+1
}栈的出栈步骤为:首先判断栈是否为空,为空则不能出栈,直接报错,若栈不为空则将top减1即可
void StackPop(Stack* ps)
{
assert(ps);
assert(ps->top != 0);//栈为空则直接报错
ps->top--;//出栈,即将栈顶指针减1
}获取栈顶元素首先需要判断栈是否为空,若栈为空则直接报错,若栈不为空,因为top为栈顶元素的下一个位置,故栈顶元素下标为top-1,返回top-1下标的值即可
STDataType StackTop(Stack* ps)
{
assert(ps);
assert(ps->top != 0);//栈为空则直接报错
return ps->a[ps->top - 1];//返回栈顶元素
}由于top为栈顶元素的下一个位置,故其值就为栈元素的个数,将其返回即可
int StackSize(Stack* ps)
{
assert(ps);
return ps->top;//返回栈顶指针
}栈的判空只需判断top是否为0,如果为0则说明栈没有元素即栈空,返回真,若不为0说明栈有元素即栈不为空,返回假
int StackEmpty(Stack* ps)
{
assert(ps);
if (ps->top == 0)//栈顶指针为0则说明栈空
return 1;
return 0;
}栈的销毁只需将在堆上申请的数组空间给释放,然后指向该空间的指针置空,栈的top和最大容量置为0
void StackDestroy(Stack* ps)
{
assert(ps);
free(ps->a);//释放指针指向的空间
ps->a = NULL;
ps->top = ps->capacity = 0;
}
队列由单链表实现结构更优,由于队列有队头和队尾两个指针,故我们用一个结构体将两个指针封装起来,队列的基本操作有初始化、入队、出队、获取队头元素、获取队尾元素、获取队列元素个数、判空、销毁等操作
单链表实现:
typedef int QDataType;
typedef struct QListNode
{
struct QListNode* next;
QDataType data;
}QNode;
// 队列的结构
typedef struct Queue
{
QNode* front;
QNode* rear;
}Queue;队列的初始化只需将两个指针都置为空即可
void QueueInit(Queue* q)
{
assert(q);
//队头和队尾指针置为空
q->front = NULL;
q->rear = NULL;
}队列的入队步骤:首先新建一个节点,再判断是否是第一次入队,即如果队列为空,则让队头和队尾指针都指向该节点,如果队列不为空,则类似于链表的尾插,将队尾指针rear指向的节点的next指向新节点,再将队尾指针rear指向新节点,即实现入队
void QueuePush(Queue* q, QDataType data)
{
assert(q);
QNode* newnode = (QNode*)malloc(sizeof(QNode));//创建一个新的节点
newnode->data = data;
if (q->rear ==NULL)//如果队列为空队列,则让队头和队尾都指向该新节点
{
q->rear = q->front = newnode;
}
else
{ //不为空则将新节点进行尾插操作
q->rear->next = newnode;
q->rear = newnode;
}
}队列的出队步骤:首先判断队列是否为空,为空则直接报错,再判断队列是否只有一个元素,只有一个元素则将该元素删除,队头和队尾指针置为空,如果队列不只有一个元素,则类似于单链表的头删,定义一个临时指针指向队头元素,然后让队头指针往后走一步,再删除临时指针指向的元素即可
void QueuePop(Queue* q)
{
assert(q);
assert(q->rear != NULL);//队列为空则报错
if (q->rear == q->front)//如果队列只有一个元素,则将该元素出列,队头队尾指针置为空
{
free(q->front);
q->rear = q->front = NULL;
}
else
{ //如果队列不只有一个元素,则进行出列操作,即头删操作
QNode* cur = q->front;
q->front = q->front->next;
free(cur);
}
}获取队头元素首先判断队头指针是否为空,为空则返回空,否则则直接返回队头指针指向的元素
QDataType QueueFront(Queue* q)
{
assert(q);
if (q->front == NULL)
return NULL;
return q->front->data;//返回队头指针指向的元素值
}获取队尾元素首先判断队尾指针是否为空,为空则返回空,不为空则直接返回队尾指针指向的元素
QDataType QueueBack(Queue* q)
{
assert(q);
if (q->rear == NULL)
return NULL;
return q->rear->data;//返回队尾指针指向的元素值
}获取元素个数首先判断队列是否为空,为空则返回0,不为空则定义一个遍历指针,从队头遍历到队尾,遍历该队列统计元素个数即可
int QueueSize(Queue* q)
{
assert(q);
if (q->rear == NULL)//队列为空则返回空
return 0;
QNode* cur = q->front;//定义遍历指针
int num = 1;//统计元素个数
while (cur != q->rear)//遍历统计元素个数
{
num++;
cur = cur->next;
}
return num;
}队列的判空只需判断队头指针等于队尾指针且都为空即可,若是则队列为空,否则不为空
int QueueEmpty(Queue* q)
{
assert(q);
if((q->front == q->rear) && (q->front == NULL))//队头队尾指针相等且都为空则队列为空
return 1;
return 0;
}队列的销毁首先判断队列是否为空,为空则直接返回,不为空则定义遍历指针,从队头遍历到队尾依次删除节点即可,最后将队头和队尾指针置空即可
void QueueDestroy(Queue* q)
{
assert(q);
if (QueueEmpty(q))//队列为空则直接返回
return;
if (q->front == q->rear)//队列只有一个元素,删除这个元素,将两个指针置空
{
free(q->front);
q->front = q->rear = NULL;
}
else
{
QNode* cur = q->front;//定义临时指针
while (cur != q->rear)//遍历删除元素
{
q->front = q->front->next;
free(cur);
cur = q->front;
}
free(q->rear);//删除队尾
q->front = q->rear = NULL;//两个指针置空
}
}好啦,栈和队列就先学习到这,如果对您有所帮助,欢迎一键三连~
种一棵树最好的时间是十年前,其次是现在
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
a=[3,4,7,8,3]b=[5,3,6,8,3]假设数组长度相同,是否有办法使用each或其他一些惯用方法从两个数组的每个元素中获取结果?不使用计数器?例如获取每个元素的乘积:[15,12,42,64,9](0..a.count-1).eachdo|i|太丑了...ruby1.9.3 最佳答案 使用Array.zip怎么样?:>>a=[3,4,7,8,3]=>[3,4,7,8,3]>>b=[5,3,6,8,3]=>[5,3,6,8,3]>>c=[]=>[]>>a.zip(b)do|i,j|c[[3,5],[4,3],[7,6],
我有一个非常简单的Controller来管理我的Rails应用程序中的静态页面:classPagesController我怎样才能让View模板返回它自己的名字,这样我就可以做这样的事情:#pricing.html.erb#-->"Pricing"感谢您的帮助。 最佳答案 4.3RoutingParametersTheparamshashwillalwayscontainthe:controllerand:actionkeys,butyoushouldusethemethodscontroller_nameandaction_nam
我正在尝试复制此GETcurl请求:curl-D--XGET-H"Authorization:BasicdGVzdEB0YXByZXNlYXJjaC5jb206NGMzMTg2Mjg4YWUyM2ZkOTY2MWNiNWRmY2NlMTkzMGU="-H"Content-Type:application/json"http://staging.example.com/api/v1/campaigns在Ruby中,通过电子邮件+apikey生成身份验证:auth="Basic"+Base64::encode64("test@example.com:4c3186288ae23fd9661c