目录

😎博客昵称:陈大大陈
😊座右铭:所谓觉悟,就是在漆黑的荒野上开辟出一条理当前进的光明大道。
😋博主简介:一名热爱C/C++和算法等技术,喜欢运动,爱胡思乱想却胸怀大志的小博主!
😚博主&唠嗑:早午晚哈喽Ciao!😄各位CSDN的朋友!😄我是博客新人陈大大陈,希望我的文章能为你带来帮助!欢迎大家在评论区畅所欲言!也希望大家多多为我提出您宝贵的建议!😘如果觉得我写的不错的话还请点个赞和关注哦~😘😘😘
c语言的内存区域可以划分为5个区——内核空间,栈,内存映射段,堆,数据段和代码段。
请看我作的图。 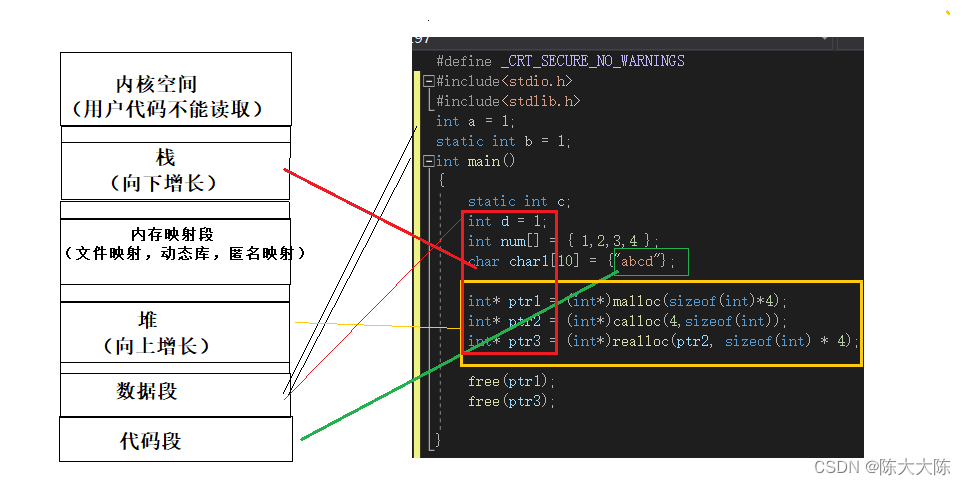
在学习计算机语言时,我们在语言层面一般把内存划分为下面几个区域——栈区,堆区和静态区。
栈区对应上面的栈,堆区对应上面的堆,而静态区所对应的是静态段。
内存中有一段区域是不允许用户来使用的,这块区域就是内核空间,内核空间是留给操作系统来使用的,用户代码是不能读写的。
我们写的代码编译之后会留下汇编指令,这些指令需要存储起来才能正常运行,储存这些指令的地方就是代码段了。
ptr1指向一段空间,这块空间是由malloc来申请的,malloc申请的空间在堆区储存,ptr1是维护那段空间的,它所储存的地址所指向的空间存储在堆区,但是ptr1本身是局部变量,存储在栈区。calloc和realloc同理。
下面两个都是柔型数组:
struct S
{
int n;
char c;
int arr[];
};
struct S
{
int n;
char c;
int arr[0];
};需要注意的是,第二种有的编译器会报错。
1.结构中的柔性数组成员前面必须至少一个其他成员
也就是说,下面这样的写法是绝对不行的:
struct S
{
int arr[];
};2.sizeof返回的带有柔型数组的结构体的大小不包括柔型数组。
#include<stdio.h>
struct S
{
int n;
char c;
int arr[];
};
int main()
{
printf("%d", sizeof(S));
return 0;
}
我们已经了解了最大对齐数,n和c一共是5字节,但是结构体大小必须是最大对齐数的整数倍,int的对齐数是4,char的对齐数是1,所以浪费三个字节,结构体大小为8,柔型数组的大小并没有被计算在里面。
3.包含柔型数组成员的结构用malloc进行内存的分配,并且分配的内存应该大于结构的大小,用来适应柔型数组的预期大小。
#include<stdio.h>
#include<stdlib.h>
#include<errno.h>
#include<string.h>
struct S
{
int n;
char c;
int arr[0];
};
int main()
{
struct S* ps = (struct S*)malloc(sizeof(struct S) + sizeof(int) * 10);
if (ps == NULL)
{
printf("%s\n", strerror(errno));
return 1;
}
ps->n = 100;
ps->c = 'w';
int i = 0;
for (i = 0; i < 10; i++)
{
ps->arr[i] = i;
printf("%d ", ps->arr[i]);
}
struct S* ptr = (struct S*)realloc(ps, sizeof(struct S) + 20 * sizeof(int));
if (ptr == NULL)
{
printf("%s\n", strerror(errno));
return 1;
}
else
{
ps = ptr;
}
free(ps);
ps = NULL;
return 0;
}柔性数组的柔性就体现在这里,如果我们将结构体中的数组大小定义成一个常量,那么它在一次程序的运行中是不可修改的,但是如果我们用柔性数组来定义的话,就可以动态地用realloc来修改。
需要注意的是,realloc的后一个参数不是要扩容的大小,而是算上本来就有的空间之后的新大小,这一点比较容易搞混。
我们也可以这样模拟实现
#include<stdio.h>
#include<stdlib.h>
#include<errno.h>
#include<string.h>
struct S
{
int n;
char c;
int *arr;
};
int main()
{
struct S* ps = (struct S*)malloc(sizeof(struct S));
if (ps == NULL)
{
perror("malloc");
return 1;
}
int* ptr = (int *)malloc(10*sizeof(int));
if (ptr == NULL)
{
perror("malloc2:");
return 1;
}
else
{
ps->arr = ptr;
}
ps->n = 100;
ps->c = 'w';
int i = 0;
for (i = 0; i < 10; i++)
{
ps->arr[i] = i;
}
for (i = 0; i < 10; i++)
{
printf("%d ", ps->arr[i]);
}
ptr = (int*)realloc(ps->arr, sizeof(int) * 20);
if (ptr == NULL)
{
perror("realloc");
return 1;
}
else
{
ps->arr = ptr;
}
free(ps->arr);
ps -> arr = NULL;
free(ps);
ps = NULL;
return 0;
}这种写法可以模拟实现上面柔型数组的功能,我们称它为结构中指针方案。
那么结构中指针和柔型数组这两个方案到底哪一个比较好呢?
如果我们用柔型数组的话,程序里面总共malloc一次,free一次。
如果用结构中指针的话,则是malloc两次,free两次。
这两个方案可以完成同样的功能,但是柔型数组的实现方式有两个好处:
第一个好处是:内存的使用率会高一些
malloc次数少,内存之间的内存碎片就会少一些,内存的使用率就会相应高一些。malloc次数多,维护难度增大,容易出错。
第二个好处是:访问速度会提高
柔型数组是一片连续的空间,访问速度理所应当地会快一些,而结构中指针空间之间可能不连续,我们在访问内存的时候,可能不是直接去内存里面拿,而是先去寄存器里找,寄存器没有再找内存要,如果空间连续,后面空间的内容可能会加载到寄存器里面,那么访问速度就会加快,而如果空间不连续,先去寄存器找却没找到,这么一来效率就会降低。
这篇博客旨在总结我自己阶段性的学习,要是能帮助到大家,那可真是三生有幸!😀如果觉得我写的不错的话还请点个赞和关注哦~我会持续输出编程的知识的!🌞🌞🌞
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
有没有办法在Ruby中动态创建数组?例如,假设我想遍历用户输入的书籍数组:books=gets.chomp用户输入:"TheGreatGatsby,CrimeandPunishment,Dracula,Fahrenheit451,PrideandPrejudice,SenseandSensibility,Slaughterhouse-Five,TheAdventuresofHuckleberryFinn"我把它变成一个数组:books_array=books.split(",")现在,对于用户输入的每一本书,我想用Ruby创建一个数组。伪代码来做到这一点:x=0books_array.
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
我想在IRB中浏览文件系统并让提示更改以反射(reflect)当前工作目录,但我不知道如何在每个命令后进行提示更新。最终,我想在日常工作中更多地使用IRB,让bash溜走。我在我的.irbrc中试过这个:require'fileutils'includeFileUtilsIRB.conf[:PROMPT][:CUSTOM]={:PROMPT_N=>"\e[1m:\e[m",:PROMPT_I=>"\e[1m#{pwd}>\e[m",:PROMPT_S=>"FOO",:PROMPT_C=>"\e[1m#{pwd}>\e[m",:RETURN=>""}IRB.conf[:PROMPT_MO
首先,我使用的是rails3.1.3和来自master的carrierwavegithub仓库的分支。我使用after_init钩子(Hook)来确定基于属性的字段页面模型实例并为这些字段定义属性访问器将值存储在序列化哈希中(希望它清楚我是什么谈论)。这是我正在做的事情的精简版:classPage省略mount_uploader命令让我可以访问我想要的属性。但是当我安装uploader时出现错误消息说“nil类的未定义新方法”我在源代码中读到有方法read_uploader和扩展模块中的write_uploader。我如何必须覆盖这些来制作mount_uploader命令使用我的“虚拟
这会导致Ruby出现内存问题吗?我知道如果大小超过10KB,Open-URI会写入TempFile。但是HTTParty会在写入TempFile之前尝试将整个PDF保存到内存吗?src=Tempfile.new("file.pdf")src.binmodesrc.writeHTTParty.get("large_file.pdf").parsed_response 最佳答案 您可以使用Net::HTTP。参见thedocumentation(特别是标题为“流媒体响应机构”的部分)。这是文档中的示例:uri=URI('http://e
我正在尝试动态构建一个多维数组。我想要的基本上是这样的(为简单起见写出来):b=0test=[[]]test[b]这给了我错误:NoMethodError:undefinedmethod`test=[[],[],[]]而且它工作正常,但在我的实际使用中,我不会事先知道需要多少个数组。有一个更好的方法吗?谢谢 最佳答案 不需要像您正在使用的索引变量。只需将每个数组附加到您的test数组:irb>test=[]=>[]irb>test[["a","b","c"]]irb>test[["a","b","c"],["d","e","f"]]
如何只加载map边界内的标记gmaps4rails?当然,在平移和/或缩放后加载新的。与此直接相关的是,如何获取map的当前边界和缩放级别? 最佳答案 我是这样做的,我只在用户完成平移或缩放后替换标记,如果您需要不同的行为,请使用不同的事件监听器:在你看来(index.html.erb):{"zoom"=>15,"auto_adjust"=>false,"detect_location"=>true,"center_on_user"=>true}},false,true)%>在View的底部添加:functiongmaps4rail
如何在对象上调用方法名称的嵌套哈希?例如,给定以下哈希:hash={:a=>{:b=>{:c=>:d}}}我想创建一个方法,给定上面的散列,执行以下操作:object.send(:a).send(:b).send(:c).send(:d)我的想法是我需要从一个未知的关联中获取一个特定的属性(这个方法不知道,但程序员知道)。我希望能够指定一个方法链来以嵌套哈希的形式检索该属性。例如:hash={:manufacturer=>{:addresses=>{:first=>:postal_code}}}car.execute_method_hash(hash)=>90210
