目的:测试1000个用户抢购优惠券时秒杀功能的并发性能~
①数据库中创建1000+用户
这里推荐使用开源工具:https://www.sqlfather.com/ ,导入以下配置即可一键生成模拟数据
{"dbName":"hmdp","tableName":"tb_user","tableComment":"用户表","mockNum":100,"fieldList":[{"fieldName":"id","fieldType":"bigint(20)","defaultValue":null,"notNull":true,"comment":"主键id","primaryKey":true,"autoIncrement":true,"mockType":"递增","mockParams":2,"onUpdate":null},{"fieldName":"phone","fieldType":"varchar(33)","defaultValue":null,"notNull":false,"comment":null,"primaryKey":false,"autoIncrement":false,"mockType":"随机","mockParams":"手机号","onUpdate":null},{"fieldName":"password","fieldType":"varchar(384)","defaultValue":null,"notNull":false,"comment":null,"primaryKey":false,"autoIncrement":false,"mockType":"随机","mockParams":"字符串","onUpdate":null},{"fieldName":"nick_name","fieldType":"varchar(96)","defaultValue":null,"notNull":false,"comment":null,"primaryKey":false,"autoIncrement":false,"mockType":"规则","mockParams":"user_\\w{10}$","onUpdate":null},{"fieldName":"icon","fieldType":"varchar(765)","defaultValue":null,"notNull":false,"comment":null,"primaryKey":false,"autoIncrement":false,"mockType":"固定","mockParams":"/imgs/blogs/blog1.jpg","onUpdate":null},{"fieldName":"create_time","fieldType":"timestamp","defaultValue":null,"notNull":false,"comment":null,"primaryKey":false,"autoIncrement":false,"mockType":"固定","mockParams":"2023-01-01 00:00:00","onUpdate":null},{"fieldName":"update_time","fieldType":"timestamp","defaultValue":null,"notNull":false,"comment":null,"primaryKey":false,"autoIncrement":false,"mockType":"固定","mockParams":"2023-01-01 00:00:01","onUpdate":null}]}
②将1000个用户处于登录状态(本质就是为1000个用户生成token,并保存到Redis中)
/**
* 在Redis中保存1000个用户信息并将其token写入文件中,方便测试多人秒杀业务
*/
@Test
void testMultiLogin() throws IOException {
List <User> userList = userService.lambdaQuery().last("limit 1000").list();
for (User user : userList) {
String token = UUID.randomUUID().toString(true);
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
Map <String,Object> userMap = BeanUtil.beanToMap(userDTO,new HashMap <>(),
CopyOptions.create().ignoreNullValue()
.setFieldValueEditor((fieldName,fieldValue) -> fieldValue.toString()));
String tokenKey = RedisConstants.LOGIN_USER_KEY + token;
stringRedisTemplate.opsForHash().putAll(tokenKey, userMap);
stringRedisTemplate.expire(tokenKey, 60,TimeUnit.MINUTES);
}
Set <String> keys = stringRedisTemplate.keys(RedisConstants.LOGIN_USER_KEY + "*");
@Cleanup FileWriter fileWriter = new FileWriter(System.getProperty("user.dir") + "\\tokens.txt");
@Cleanup BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
assert keys != null;
for (String key : keys) {
String token = key.substring(RedisConstants.LOGIN_USER_KEY.length());
String text = token + "\n";
bufferedWriter.write(text);
}
}
③在Jmeter中进行压力测试:1000个线程请求接口,观察结果
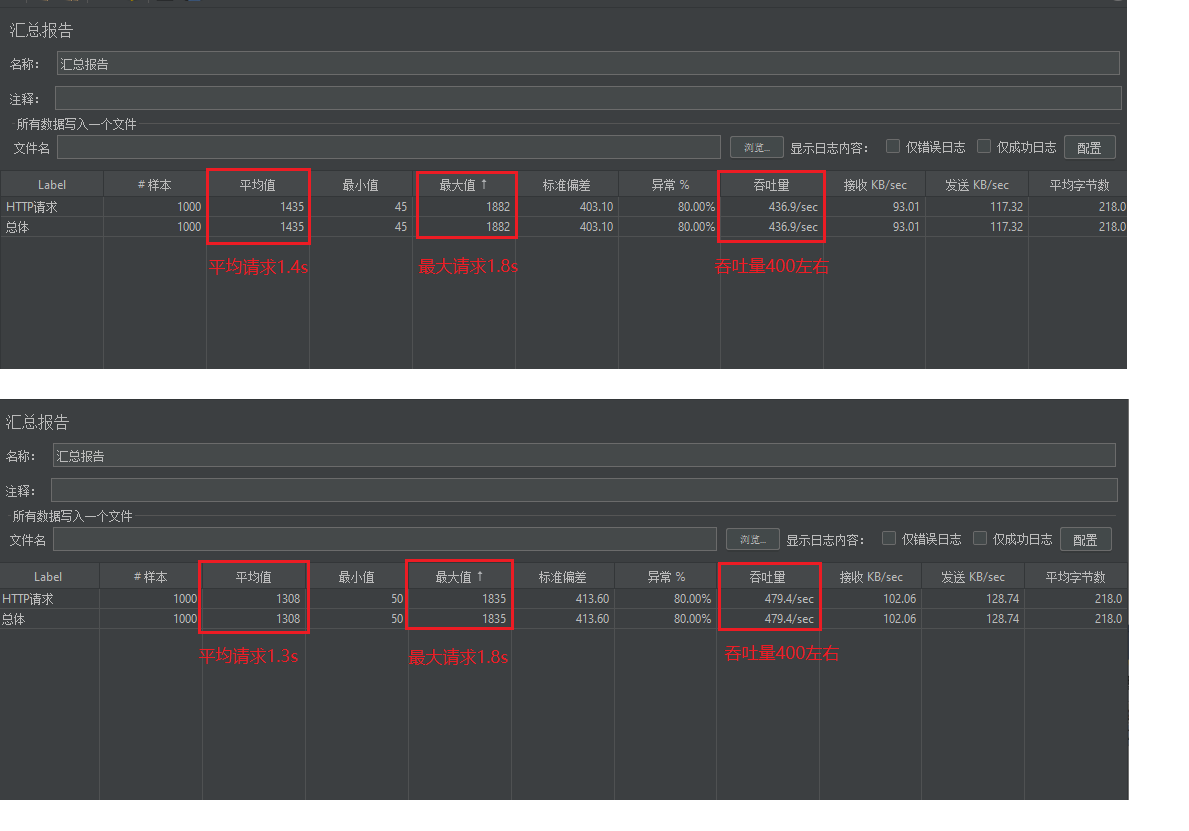
这接口被Leader发现,估计要被骂死~
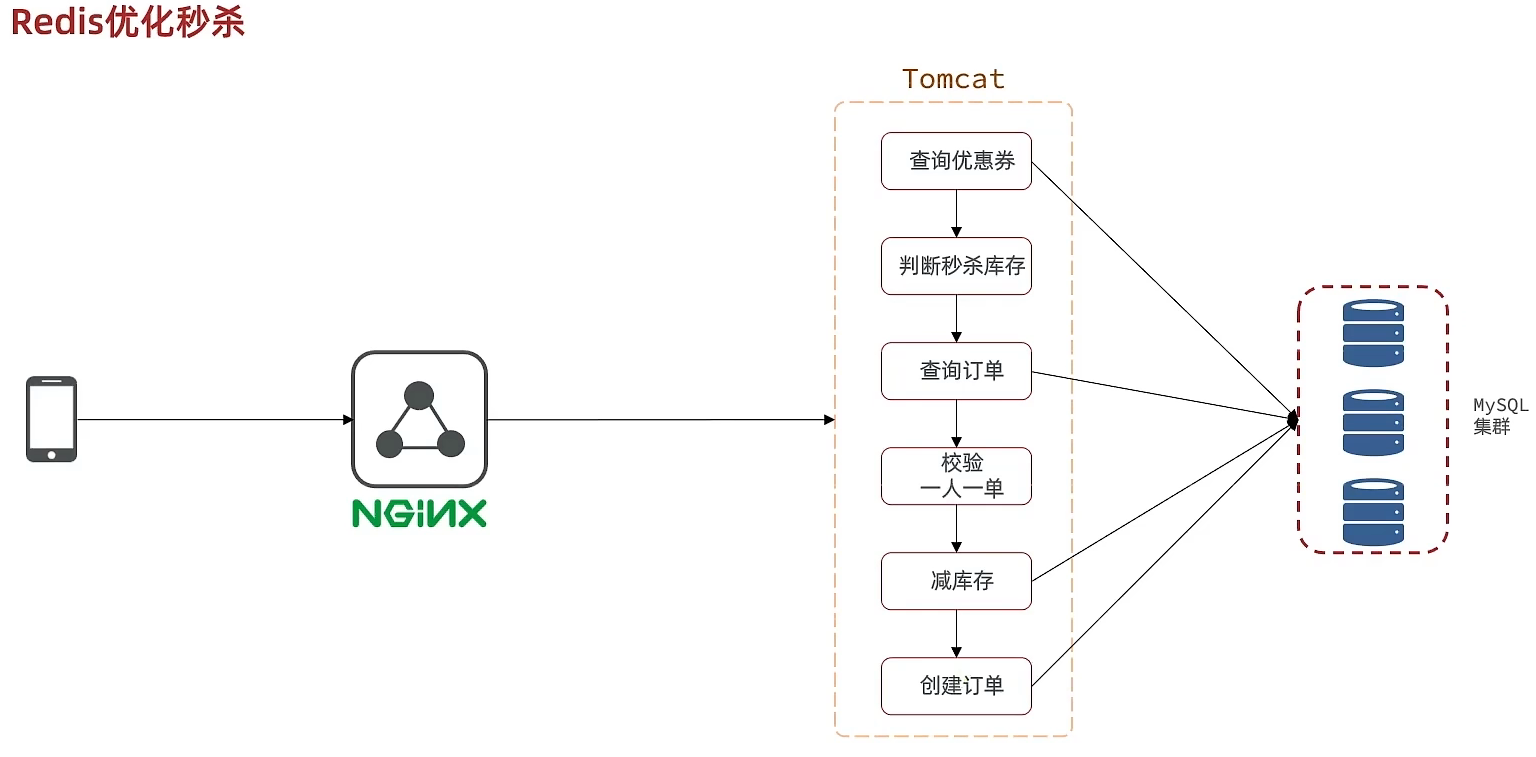
我们来回顾一下下单流程
当用户发起请求,此时会请求nginx,nginx会访问到tomcat,而tomcat中的程序,会进行串行操作,分成如下几个步骤
1、查询优惠卷
2、判断秒杀库存是否足够
3、查询订单
4、校验是否是一人一单
5、扣减库存
6、创建订单
在这六步操作中,又有很多操作是要去操作数据库的,而且还是一个线程串行执行, 这样就会导致我们的程序执行的很慢,所以我们需要异步程序执行,那么如何加速呢?
在这里笔者想给大家分享一下课程内没有的思路,看看有没有小伙伴这么想,比如,我们可以不可以使用异步编排来做,或者说我开启N多线程,N多个线程,一个线程执行查询优惠卷,一个执行判断扣减库存,一个去创建订单等等,然后再统一做返回,这种做法和课程中有哪种好呢?答案是课程中的好,因为如果你采用我刚说的方式,如果访问的人很多,那么线程池中的线程可能一下子就被消耗完了,而且你使用上述方案,最大的特点在于,你觉得时效性会非常重要,但是你想想是吗?并不是,比如我只要确定他能做这件事,然后我后边慢慢做就可以了,我并不需要他一口气做完这件事,所以我们应当采用的是课程中,类似消息队列的方式来完成我们的需求,而不是使用线程池或者是异步编排的方式来完成这个需求
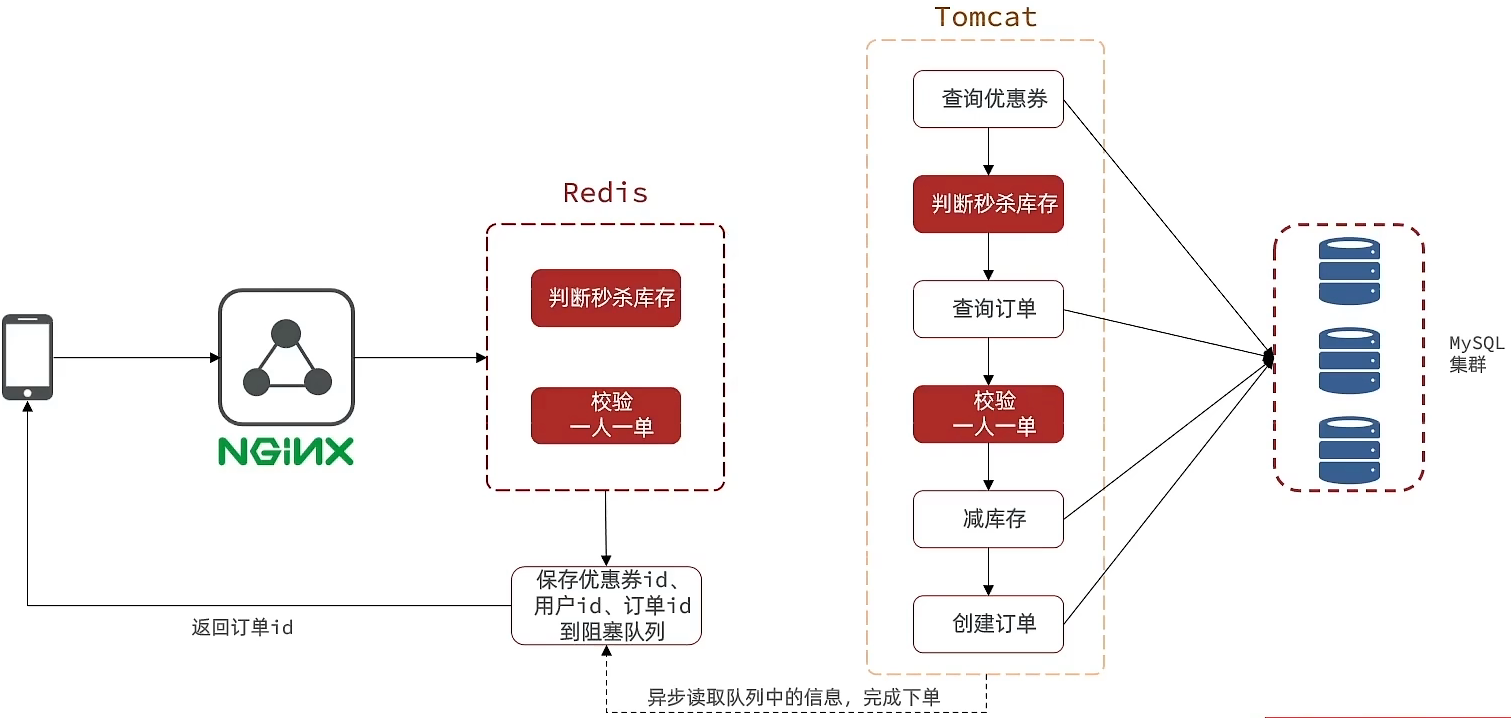
**优化方案:**我们将耗时比较短的逻辑判断放入到redis中,比如是否库存足够,比如是否一人一单,这样的操作,只要这种逻辑可以完成,就意味着我们是一定可以下单完成的,我们只需要进行快速的逻辑判断,根本就不用等下单逻辑走完,我们直接给用户返回成功, 再在后台开一个线程,后台线程慢慢的去执行queue里边的消息,这样程序不就超级快了吗?而且也不用担心线程池消耗殆尽的问题,因为这里我们的程序中并没有手动使用任何线程池。当然这里边有两个难点
第一个难点是我们怎么在redis中去快速校验一人一单,还有库存判断
第二个难点是由于我们校验和tomct下单是两个线程,那么我们如何知道到底哪个单他最后是否成功,或者是下单完成,为了完成这件事我们在redis操作完之后,我们会将一些信息返回给前端,同时也会把这些信息丢到异步queue中去,后续操作中,可以通过这个id来查询我们tomcat中的下单逻辑是否完成了。【饭店的运营流程】
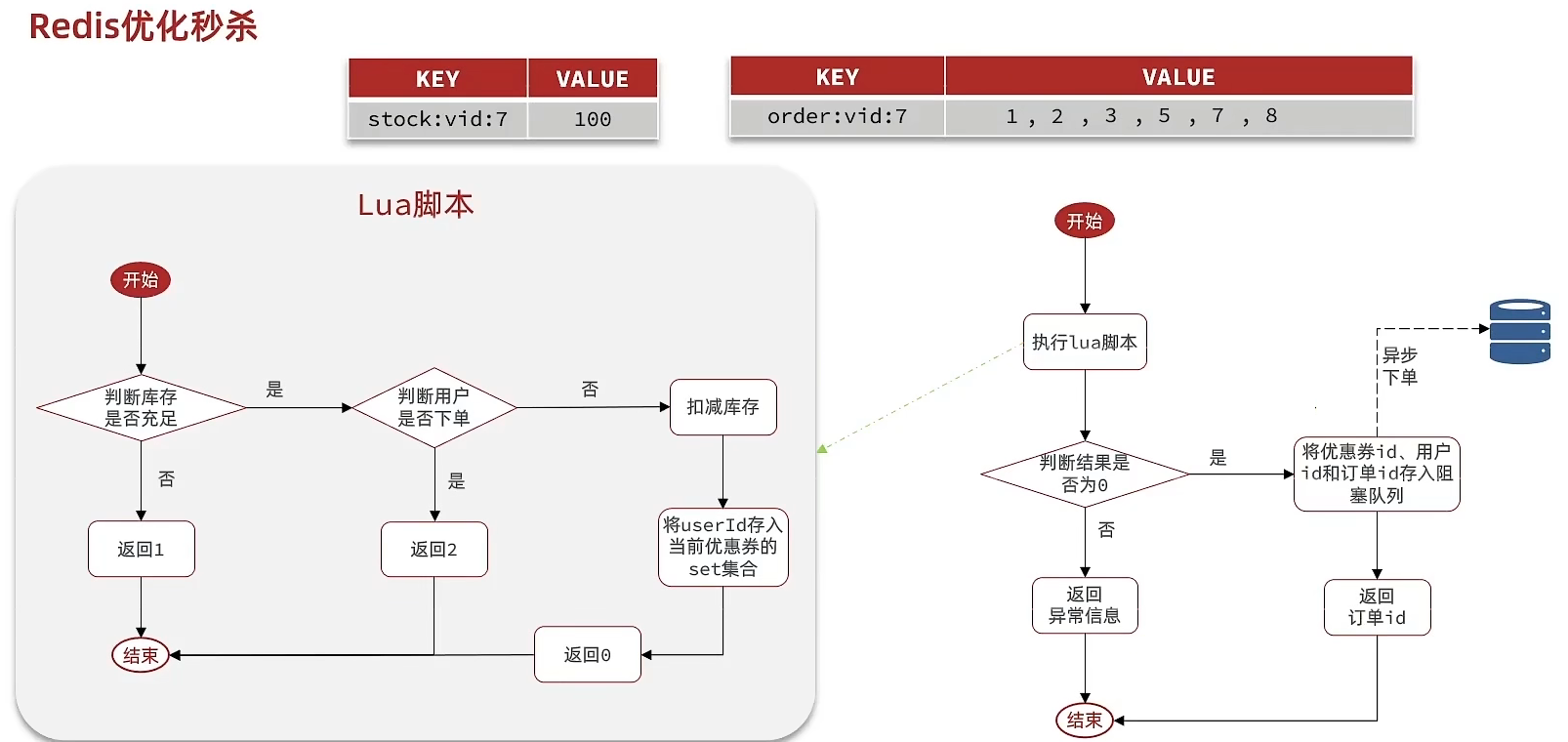
我们现在来看看整体思路:当用户下单之后,判断库存是否充足只需要到redis中去根据key找对应的value是否大于0即可,如果不充足,则直接结束,如果充足,继续在redis中判断用户是否可以下单,如果set集合中没有这条数据,说明他可以下单,如果set集合中没有这条记录,则将userId和优惠卷存入到redis中,并且返回0,整个过程需要保证是原子性的,我们可以使用lua来操作
当以上判断逻辑走完之后,我们可以判断当前redis中返回的结果是否是0 ,如果是0,则表示可以下单,则将之前说的信息存入到到queue中去,然后返回,然后再来个线程异步的下单,前端可以通过返回的订单id来判断是否下单成功。
需求:
新增秒杀优惠券的同时,将优惠券信息保存到Redis中
基于Lua脚本,判断秒杀库存、一人一单,决定用户是否抢购成功
如果抢购成功,将优惠券id和用户id封装后存入阻塞队列
开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能

VoucherServiceImpl
@Override
@Transactional
public void addSeckillVoucher(Voucher voucher) {
// 保存优惠券
save(voucher);
// 保存秒杀信息
SeckillVoucher seckillVoucher = new SeckillVoucher();
seckillVoucher.setVoucherId(voucher.getId());
seckillVoucher.setStock(voucher.getStock());
seckillVoucher.setBeginTime(voucher.getBeginTime());
seckillVoucher.setEndTime(voucher.getEndTime());
seckillVoucherService.save(seckillVoucher);
// 保存秒杀库存到Redis中
stringRedisTemplate.opsForValue().set(SECKILL_STOCK_KEY + voucher.getId(), voucher.getStock().toString());
}
完整lua表达式
-- 1.参数列表
-- 1.1 优惠券Id
local voucherId = ARGV[1]
-- 1.2 用户id
local userId = ARGV[2]
-- 2.数据key
-- 2.1 库存key
local stockKey = 'seckill:stock:' .. voucherId
-- 2.2 订单key
local orderKey = 'seckill:order:' .. voucherId
-- 3.脚本业务
-- 3.1 判断库存是否充足 get stockKey
if (tonumber(redis.call('get', stockKey)) <= 0) then
-- 3.1.2 库存不足,返回1
return 1
end
-- 3.2 判断用户是否已经下过单
if (redis.call('sismember', orderKey, userId) == 1) then
-- 3.2.2 存在,说明重复下单,返回2
return 2
end
-- 3.3 扣库存 incrby stockKey -1
redis.call('incrby', stockKey, -1)
-- 3.4 下单(保存用户) sadd orderKey userId
redis.call('sadd', orderKey, userId)
-- 3.5 用户有下单资格,返回0
return 0
当以上lua表达式执行完毕后,剩下的就是根据步骤3,4来执行我们接下来的任务了
VoucherOrderServiceImpl
/**
* 使用Lua脚本+消息队列实现秒杀下单
*
* @param voucherId
* @return
*/
@Override
public Result seckillVoucher(Long voucherId) {
// 获取用户id
Long userId = UserHolder.getUser().getId();
// 1.执行Lua脚本
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(),
voucherId.toString(),
userId.toString()
);
// 2.判断结果是否为0
if (result != 0) {
// 2.1 不为0,代表没有购买资格
return Result.fail(result == 1 ? "库存不足" : "不能重复下单");
}
//TODO 保存阻塞队列
// 3.返回订单id
return Result.ok(orderId);
}
**压力测试:**因为目前前两步骤做完,后面的加入阻塞队列执行时间就很短了~
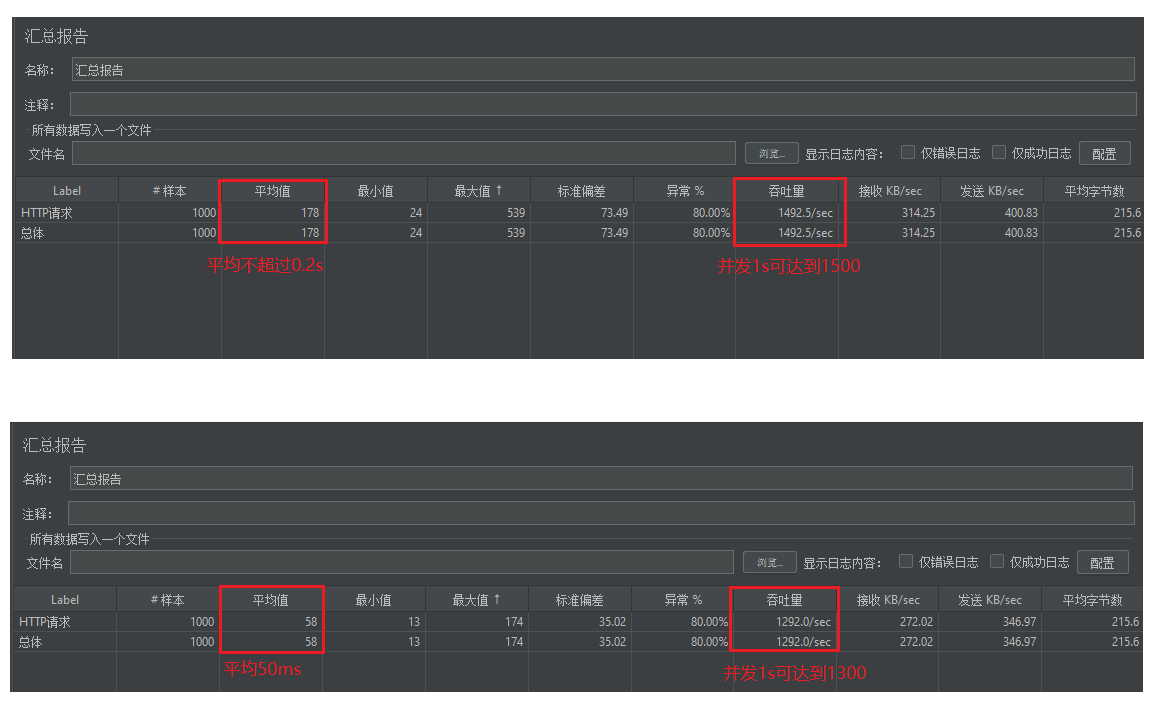
可以看到并发性能大大提升,请求响应值在0.1s左右,吞吐量可达到1500/sec~ 速度飞起
VoucherOrderServiceImpl
修改下单动作,现在我们去下单时,是通过lua表达式去原子执行判断逻辑,如果判断我出来不为0 ,则要么是库存不足,要么是重复下单,返回错误信息,如果是0,则把下单的逻辑保存到队列中去,然后异步执行
/**
* 将代理对象声明成全局
*/
private IVoucherOrderService proxy;
/**
* 存放任务的阻塞队列
* 特点:当一个线程尝试从队列中获取元素,没有元素,线程就会被阻塞,直到队列中有元素,线程才会被唤醒,并去获取元素
*/
private BlockingQueue <VoucherOrder> orderTasks = new ArrayBlockingQueue <>(1024 * 1024);
/**
* 思考一个问题:为什么要使用线程池呢,而不是直接创建一个线程?
* 其实直接创建一个线程也行,但是创建一个线程开销很大的,用阻塞队列+线程池的形式实现了线程的的复用
*/
private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();
/**
* 由于用户秒杀的时间可能是随时的,所以需要我们项目已启动 线程池就应该从消息队列获取任务,然后工作...
*
* @PostConstruct类初始花后立刻执行
*/
@PostConstruct
private void init() {
SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler());
}
private class VoucherOrderHandler implements Runnable {
@Override
public void run() {
while (true) {
try {
// 1.获取队列中的订单信息
// take():获取和删除该队列的头部,如果没有则阻塞等待,直到有元素可用。所以使用该方法,如果有元素,线程就工作,没有线程就阻塞(卡)在这里,不用担心CPU会空转~
VoucherOrder voucherOrder = orderTasks.take();
// 2.创建订单
handleVoucherOrder(voucherOrder);
} catch (Exception e) {
log.error("处理订单异常:", e);
}
}
}
}
/**
* 创建订单
*
* @param voucherOrder
*/
private void handleVoucherOrder(VoucherOrder voucherOrder) {
/**
* 其实这里可以不加锁了:(方式一)
* ①:前面的Lua脚本已经进判断过库存和一人一单了,并且也可以保证执行的原子性(一次只有一个线程执行)。
* ②:此时线程池中只有一个线程,是单线程哦~
* ③:之后从消息队列取任务执行并不需要保证其原子性,因为就不存在并发安全问题了
* 加锁算是一种兜底~
*/
// 方式一:加分布式锁再创建订单
// // 1.获取用户
// // 注意:这里userId不能从UserHolder中去取,因为当前并不是主线程,而是子线程,无法拿到父线程ThreadLocal中的数据
// Long userId = voucherOrder.getUserId();
// // 2.获取分布式锁
// RLock lock = redissonClient.getLock("lock:order:" + userId);
// boolean isLock = lock.tryLock();
// // 3.判断是否获取锁成功
// if (!isLock) {
// // 获取锁失败,返回错误和重试
// log.error("不允许重复下单~");
// }
// try {
// // 获取代理对象(只有通过代理对象调用方法,事务才会生效)
// // 注意:这里直接通过以下方式获取肯定是不行的。因为方法底层也是基于ThreadLocal获取的,子线程是无法获取父线程ThreadLocal中的对象的
// // 解决办法:在seckillVoucher中提前获取,然后通过消息队列传入或者声明成全局变量,从而就可以使用了
// // IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();
// proxy.createVoucherOrder(voucherOrder.getVoucherId());
// } finally {
// lock.unlock();
// }
// 方式二:直接创建订单
proxy.createVoucherOrder(voucherOrder);
}
// RedisScript需要加载seckill.lua文件,为了避免每次释放锁时都加载,我们可以提前加载好。否则每次读取文件就会产生IO,效率很低
static {
SECKILL_SCRIPT = new DefaultRedisScript <>();
SECKILL_SCRIPT.setLocation(new ClassPathResource("seckill.lua"));
SECKILL_SCRIPT.setResultType(Long.class);
}
/**
* 使用Lua脚本+消息队列实现秒杀下单
*
* @param voucherId
* @return
*/
@Override
public Result seckillVoucher(Long voucherId) {
// 获取用户id
Long userId = UserHolder.getUser().getId();
// 1.执行Lua脚本
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(),
voucherId.toString(),
userId.toString()
);
// 2.判断结果是否为0
if (result != 0) {
// 2.1 不为0,代表没有购买资格
return Result.fail(result == 1 ? "库存不足" : "不能重复下单");
}
// 2.2 为0,有购买资格,把下单信息保存到消息队列
// 2.3 创建订单
VoucherOrder voucherOrder = new VoucherOrder();
// 2.4 订单id
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
// 2.5 用户id
voucherOrder.setUserId(userId);
// 2.6代金券id
voucherOrder.setVoucherId(voucherId);
// 2.7放入阻塞队列【理论上只要放入消息队列就有购买资格】
orderTasks.add(voucherOrder);
// 3.获取代理对象
proxy = (IVoucherOrderService) AopContext.currentProxy();
// 4. 返回订单id
return Result.ok(orderId);
}
@Override
public void createVoucherOrder(VoucherOrder voucherOrder) {
//注意:因为我们在Lua中已经校验过库存和一人一单了,这里就不需要校验拉~
// 1.扣减库存
boolean success = seckillVoucherService.update().setSql("stock = stock - 1").
eq("voucher_id", voucherOrder.getVoucherId())
.gt("stock", 0)
.update();
//这里其实不判断也是OK的,因为Lua脚本中校验过了,所以一定是充足的
if (!success) {
log.error("库存不足!");
}
// 2.保存订单
this.save(voucherOrder);
}
并发测试:
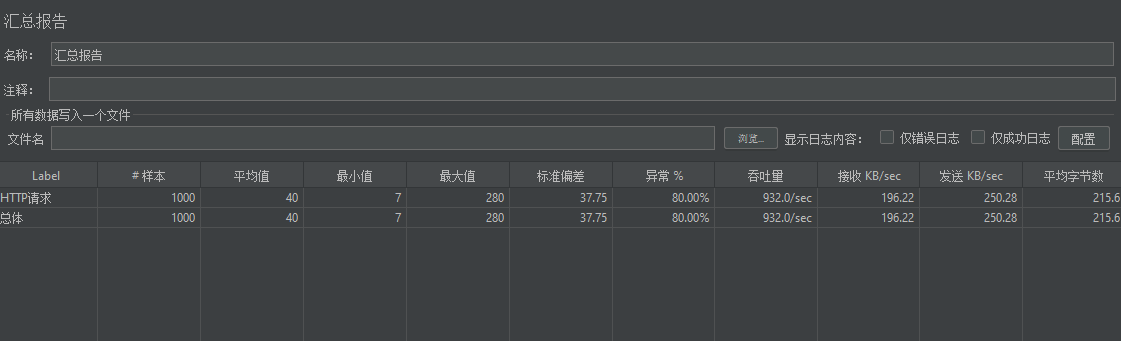
可以看出平均每个请求40ms,并发达到1000/sec,速度非常快。
小总结:
秒杀业务的优化思路是什么?
内存限制问题:因为我们使用的是JDK的阻塞队列,它使用的是内存。不加以限制的时候,在高并发的情况下,无数订单进入队列,可能导致内存溢出。所以我们在创建队列的时候设置了上限。另外如果此时队列已经存满了,又有新的任务忘里面塞,就放不进去了。数据安全问题:目前是基于内存来保存这些订单信息的,
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
我希望Ruby的解析器会进行这种微不足道的优化,但似乎并没有(谈到YARV实现,Ruby1.9.x、2.0.0):require'benchmark'deffib1a,b=0,1whileb由于这两种方法除了在第二种方法中使用预定义常量而不是常量表达式外是相同的,因此Ruby解释器似乎在每个循环中一次又一次地计算幂常数。是否有一些Material说明为什么Ruby根本不进行这种基本优化或只在某些特定情况下进行? 最佳答案 很抱歉给出了另一个答案,但我不想删除或编辑我之前的答案,因为它下面有有趣的讨论。正如JörgWMittag所说,
我正在尝试从数据库中读取大量单元格(超过100.000个)并将它们写入VPSUbuntu服务器上的csv文件。碰巧服务器没有足够的内存。我正在考虑一次读取5000行并将它们写入文件,然后再读取5000行,等等。我应该如何重构我当前的代码以使内存不会被完全消耗?这是我的代码:defwrite_rows(emails)File.open(file_path,"w+")do|f|f该函数由sidekiqworker调用:write_rows(user.emails)感谢您的帮助! 最佳答案 这里的问题是,当您调用emails.each时,
文章目录前言约束硬约束的轨迹优化Corridor-BasedTrajectoryOptimizationBezierCurveOptimizationOtherOptions软约束的轨迹优化Distance-BasedTrajectoryOptimization优化方法前言可以看看我的这几篇Blog1,Blog2,Blog3。上次基于MinimumSnap的轨迹生成,有许多优点,比如:轨迹让机器人可以在某个时间点抵达某个航点。任何一个时刻,都能数学上求出期望的机器人的位置、速度、加速度、导数。MinimumSnap可以把问题转换为凸优化问题。缺点:MnimumSnap可以控制轨迹一定经过中间的
我对为我的RubyonRails3.1.3应用优化我的Unicorn设置的方法很感兴趣。我目前正在高CPU超大实例上生成14个工作进程,因为我的应用程序在负载测试期间似乎受CPU限制。在模拟负载测试中,每秒大约20个请求重放请求,我的实例上的所有8个内核都达到峰值,盒子负载飙升至7-8个。每个unicorn实例使用大约56-60%的CPU。我很好奇可以通过哪些方式对其进行优化?我希望能够每秒将更多请求汇集到这种大小的实例上。内存和所有其他I/O一样完全正常。在我的测试过程中,CPU越来越低。 最佳答案 如果您受CPU限制,您希望使用
美团外卖搜索工程团队在Elasticsearch的优化实践中,基于Location-BasedService(LBS)业务场景对Elasticsearch的查询性能进行优化。该优化基于Run-LengthEncoding(RLE)设计了一款高效的倒排索引结构,使检索耗时(TP99)降低了84%。本文从问题分析、技术选型、优化方案等方面进行阐述,并给出最终灰度验证的结论。1.前言最近十年,Elasticsearch已经成为了最受欢迎的开源检索引擎,其作为离线数仓、近线检索、B端检索的经典基建,已沉淀了大量的实践案例及优化总结。然而在高并发、高可用、大数据量的C端场景,目前可参考的资料并不多。因此
最近在工作中,看到一些新手测试同学,对接口测试存在很多疑问,甚至包括一些从事软件测试3,5年的同学,在聊到接口时,也是一知半解;今天借着这个机会,对接口测试做个实战教学,顺便总结一下经验,分享给大家。计划拆分成4个模块跟大家做一个分享,(接口测试、接口基础知识、接口自动化、接口进阶)感兴趣的小伙伴记得关注,希望对你的日常工作和求职面试,带来一些帮助。注:文章较长有5000多字,希望小伙伴们认真看完,当然有些内容对小白同学不是太友好,如果你需要详细了解其中的一些概念或者名词,请在文章之后留言,后续我将针对大家的疑问,整理输出一些大家感兴趣的文章。随着开发模式的迭代更新,前后端分离已不是新的概念,
目录FIFO一.自定义同步FIFO1.1代码设计1.2Testbech1.3行为仿真***学习位宽计算函数$clog2()***$clog2()系统函数使用,可以不关注***分布式资源或者BLOCKBRAM二.异步FIFO2.1在FIFO判满的时候有两种方式:2.2异步FIFO为什么要使用格雷码2.2.1介绍格雷码2.2.2格雷码在异步FIFO中的应用2.2.2格雷码判满2.4二进制与格雷码之间的转换2.4.1二进制码转换为格雷码的方法2.4.2格雷码转换为二进制码的方法2.3实现框图2.5实现及仿真代码2.6仿真图验证2.7结论FIFO 这篇更多的是记录FIFO学习,参考了众多优秀的文章,
RTS在阿里云视频直播的基础上进行底层技术优化,通过集成阿里云播放器SDK,支持在千万级并发场景下节点间毫秒级延时直播的能力,弥补了传统直播存在3~6秒延时的问题,确保了超低延时、低卡顿、秒开流畅的直播观看体验。本文介绍了基于RTS超低延迟直播优化强互动场景体验的最佳实践方案,并以阿里云播放器Aliplayer为例,详细介绍RTS超低延迟拉流接入、自动降级、排障信息获取等逻辑的实现,助力企业打造互动直播行业的产品竞争力。适用场景该方案适用于对超低延迟直播有诉求的客户,尤其是业务中存在强互动场景直播的场景。强互动场景直播主要是指对主播和观众存在互动,或观众存在更高实时性观看、画面互动需求的情况,
我目前正在研究Ruby2.1.1的改进,但遇到了一些奇怪的事情。我正在尝试改进String类并定义一个名为FOO的常量。沙箱.rbmoduleFoobarrefineStringdoFOO="BAR"deffoobar"foobar"endendendusingFoobarputs"".class::FOO#=>uninitializedconstantString::FOO(NameError)puts"".foobar#=>"foobar"这给了我未初始化的常量String::FOO(NameError)。但是我可以调用"".foobar这让我相信我在正确的范围内。奇怪的是,如果我