随机森林
library(rio)
library(ggplot2)
library(magrittr)
library(randomForest)
library(tidyverse)
library(skimr)
library(DataExplorer)
library(caret)
library(varSelRF)
library(pdp)
library(iml)
data("boston")
as.data.frame(boston)
skim(boston)#数据鸟瞰
plot_missing(boston)#数据缺失
#na.roughfix() #填补缺失
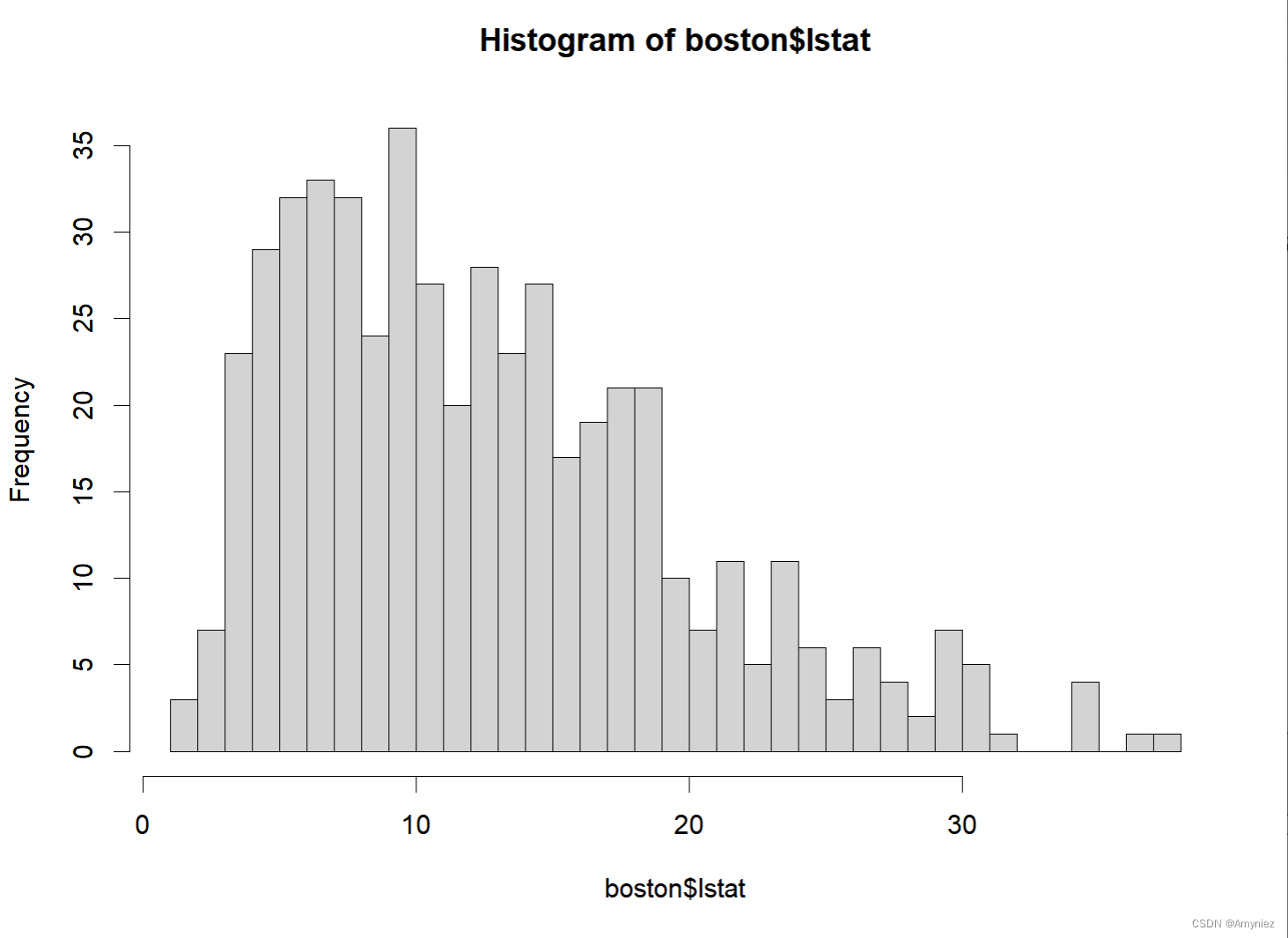
hist(boston$lstat,breaks = 50)
数据展示:
######################################
# 1.数据集划分
set.seed(123)
trains <- createDataPartition(y = boston$lstat,p=0.70,list = F)
traindata <- boston[trains,]
testdata <- boston[-trains,]
#因变量自变量构建公式
colnames(boston)
form_reg <- as.formula(paste0("lstat ~",
paste(colnames(traindata)[1:15],collapse = "+")))
form_reg

构建的公式:

#### 2.1模型mtry的最优选取,mry=12 % Var explained最佳
#默认情况下数据集变量个数的二次方根(分类模型)或1/3(预测模型)
set.seed(123)
n <- ncol(boston)-5
errRate <- c(1) #设置模型误判率向量初始值
for (i in 1:n) {
rf_train <- randomForest(form_reg, data = traindata,
ntree = 1000,#决策树的棵树
p =0.8,
mtry = i,#每个节点可供选择的变量数目
importance = T #输出变量的重要性
)
errRate[i] <- mean(rf_train$mse)
print(rf_train)
}
m= which.min(errRate)
print(m)
结果:
Call:
randomForest(formula = form_reg, data = traindata, ntree = 1000, p = 0.8, mtry = i, importance = T)
Type of random forest: regression
Number of trees: 1000
No. of variables tried at each split: 1
Mean of squared residuals: 13.35016
% Var explained: 72.5
Call:
randomForest(formula = form_reg, data = traindata, ntree = 1000, p = 0.8, mtry = i, importance = T)
Type of random forest: regression
Number of trees: 1000
No. of variables tried at each split: 2
Mean of squared residuals: 11.0119
% Var explained: 77.31
Call:
randomForest(formula = form_reg, data = traindata, ntree = 1000, p = 0.8, mtry = i, importance = T)
Type of random forest: regression
Number of trees: 1000
No. of variables tried at each split: 3
Mean of squared residuals: 10.51724
% Var explained: 78.33
Call:
randomForest(formula = form_reg, data = traindata, ntree = 1000, p = 0.8, mtry = i, importance = T)
Type of random forest: regression
Number of trees: 1000
No. of variables tried at each split: 4
Mean of squared residuals: 10.41254
% Var explained: 78.55
Call:
randomForest(formula = form_reg, data = traindata, ntree = 1000, p = 0.8, mtry = i, importance = T)
Type of random forest: regression
Number of trees: 1000
No. of variables tried at each split: 5
Mean of squared residuals: 10.335
% Var explained: 78.71
Call:
randomForest(formula = form_reg, data = traindata, ntree = 1000, p = 0.8, mtry = i, importance = T)
Type of random forest: regression
Number of trees: 1000
No. of variables tried at each split: 6
Mean of squared residuals: 10.22917
% Var explained: 78.93
Call:
randomForest(formula = form_reg, data = traindata, ntree = 1000, p = 0.8, mtry = i, importance = T)
Type of random forest: regression
Number of trees: 1000
No. of variables tried at each split: 7
Mean of squared residuals: 10.25744
% Var explained: 78.87
Call:
randomForest(formula = form_reg, data = traindata, ntree = 1000, p = 0.8, mtry = i, importance = T)
Type of random forest: regression
Number of trees: 1000
No. of variables tried at each split: 8
Mean of squared residuals: 10.11666
% Var explained: 79.16
Call:
randomForest(formula = form_reg, data = traindata, ntree = 1000, p = 0.8, mtry = i, importance = T)
Type of random forest: regression
Number of trees: 1000
No. of variables tried at each split: 9
Mean of squared residuals: 10.09725
% Var explained: 79.2
Call:
randomForest(formula = form_reg, data = traindata, ntree = 1000, p = 0.8, mtry = i, importance = T)
Type of random forest: regression
Number of trees: 1000
No. of variables tried at each split: 10
Mean of squared residuals: 10.09231
% Var explained: 79.21
Call:
randomForest(formula = form_reg, data = traindata, ntree = 1000, p = 0.8, mtry = i, importance = T)
Type of random forest: regression
Number of trees: 1000
No. of variables tried at each split: 11
Mean of squared residuals: 10.12222
% Var explained: 79.15

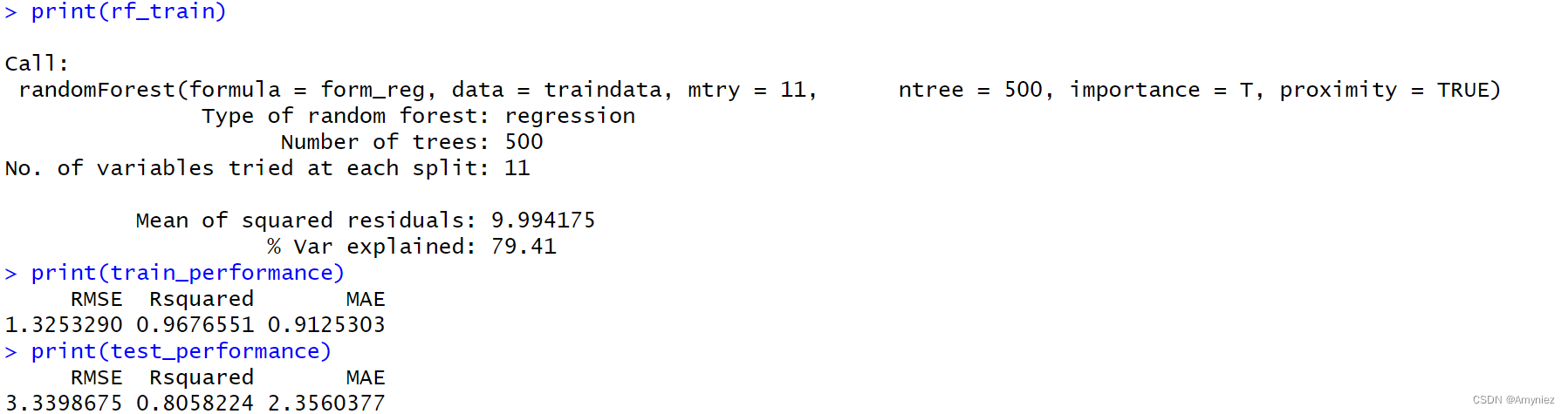
结果显示mtry为11误差最小,精度最高
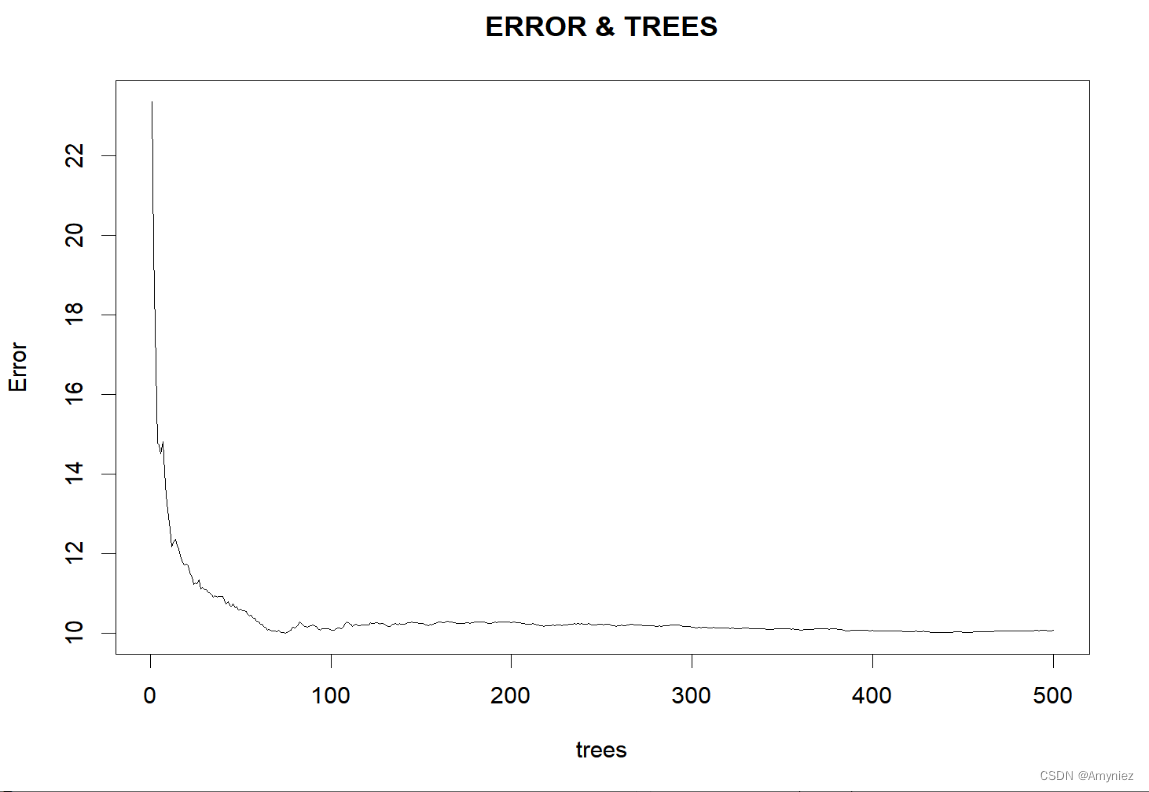
#### 寻找合适的ntree
set.seed(123)
rf_train<-randomForest(form_reg,data=traindata,
mtry=11,ntree=500,importance = T,proximity=TRUE)
plot(rf_train,main = "ERROR & TREES") #绘制模型误差与决策树数量关系图
运行结果:
#### 变量重要性
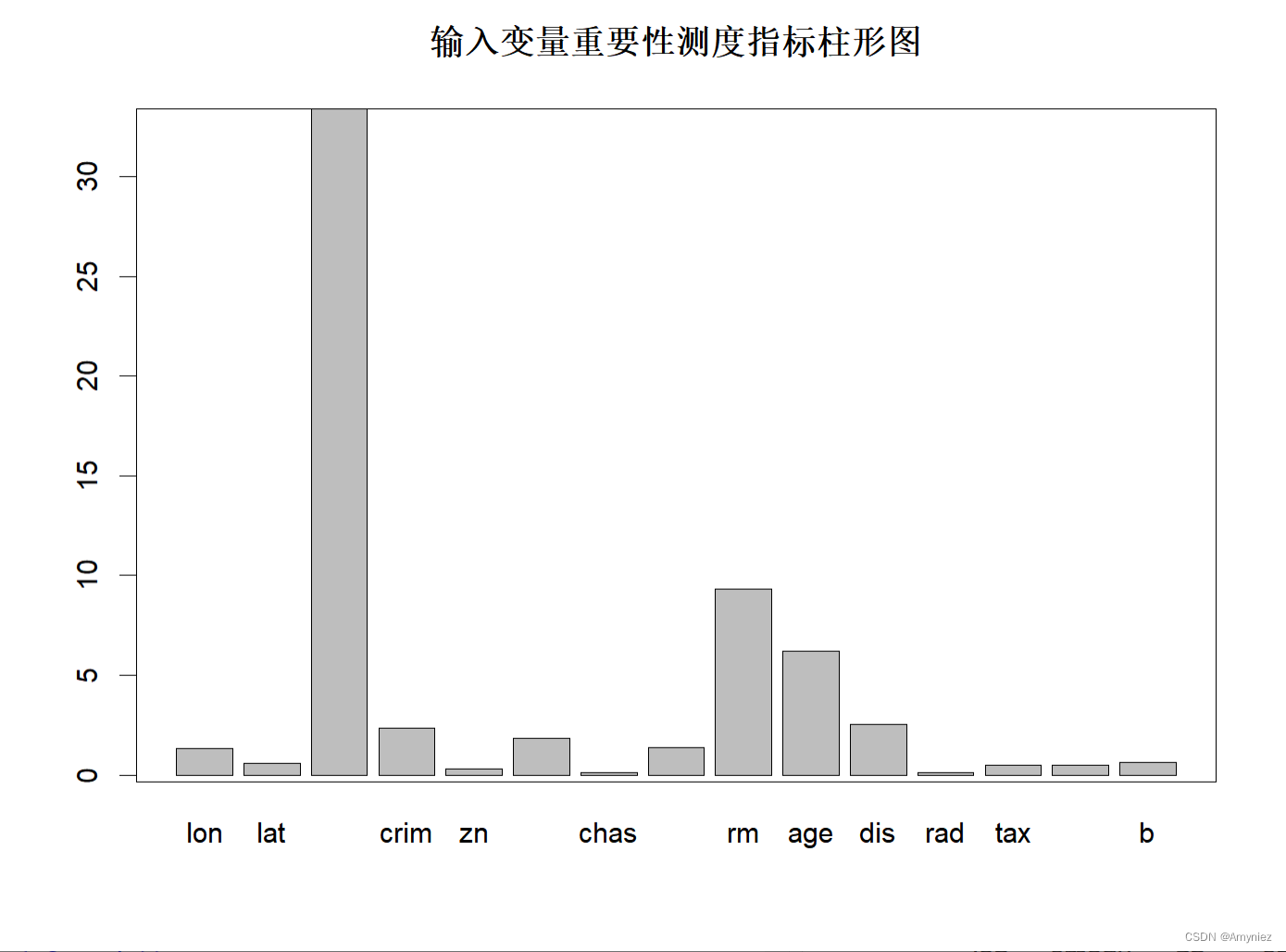
importance<-importance(rf_train)
##### 绘图法1
barplot(rf_train$importance[,1],main="输入变量重要性测度指标柱形图")
box()
重要性展示:
##### 绘图法2
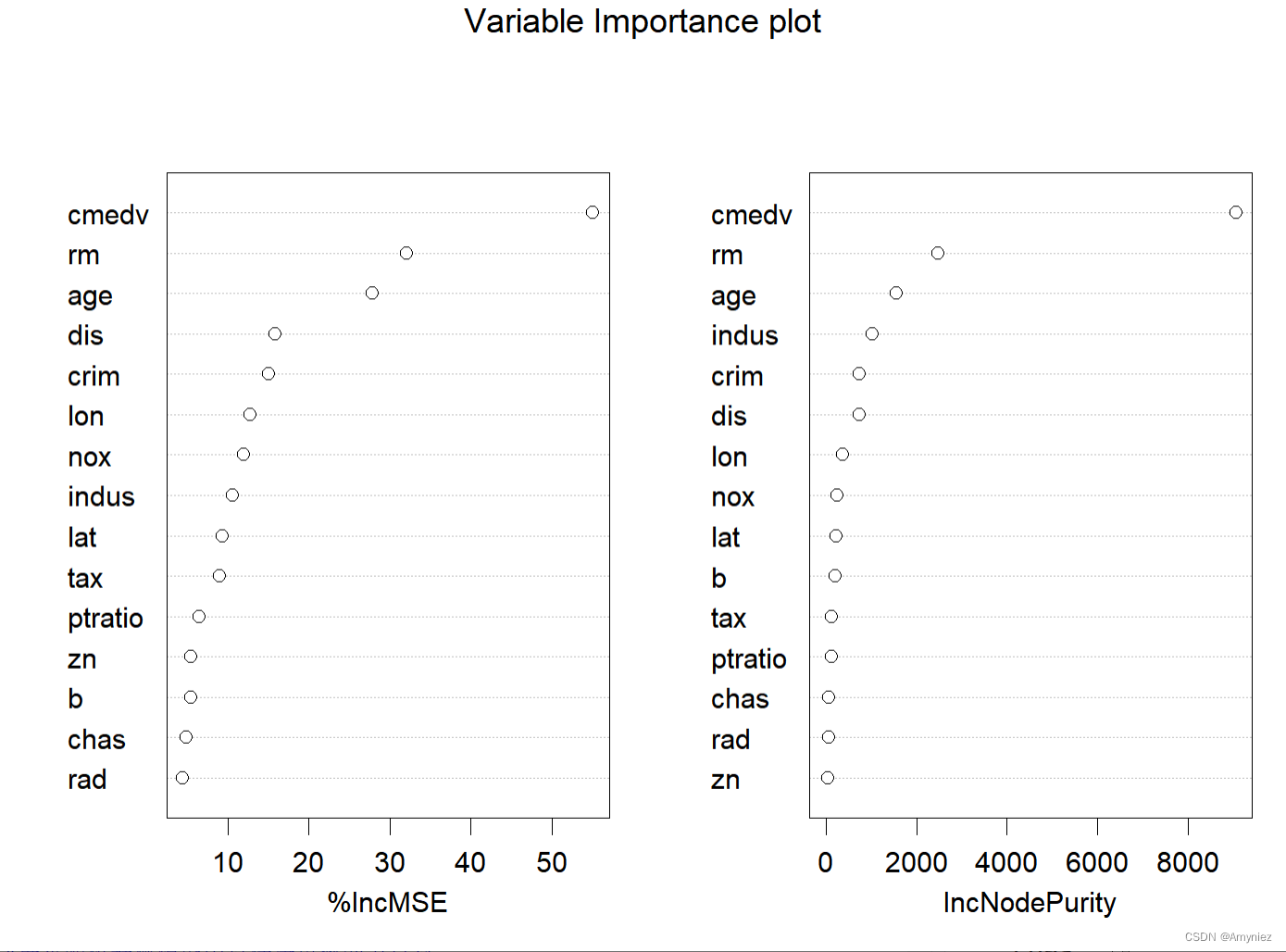
varImpPlot(rf_train,main = "Variable Importance plot")
varImpPlot(rf_train,main = "Variable Importance plot",type = 1)
varImpPlot(rf_train,sort=TRUE,
n.var=nrow(rf_train$importance),
main = "Variable Importance plot",type = 2) # 基尼系数
hist(treesize(rf_train)) #展示随机森林模型中每棵决策树的节点数
max(treesize(rf_train));
min(treesize(rf_train))
“%IncMSE” 即increase in mean squared error,通过对每一个预测变量随机赋值,如果该预测变量更为重要,那么其值被随机替换后模型预测的误差会增大。“IncNodePurity”即increase in node purity,通过残差平方和来度量,代表了每个变量对分类树每个节点上观测值的异质性的影响,从而比较变量的重要性。两个指示值均是判断预测变量重要性的指标,均是值越大表示该变量的重要性越大,但分别基于两者的重要性排名存在一定的差异。
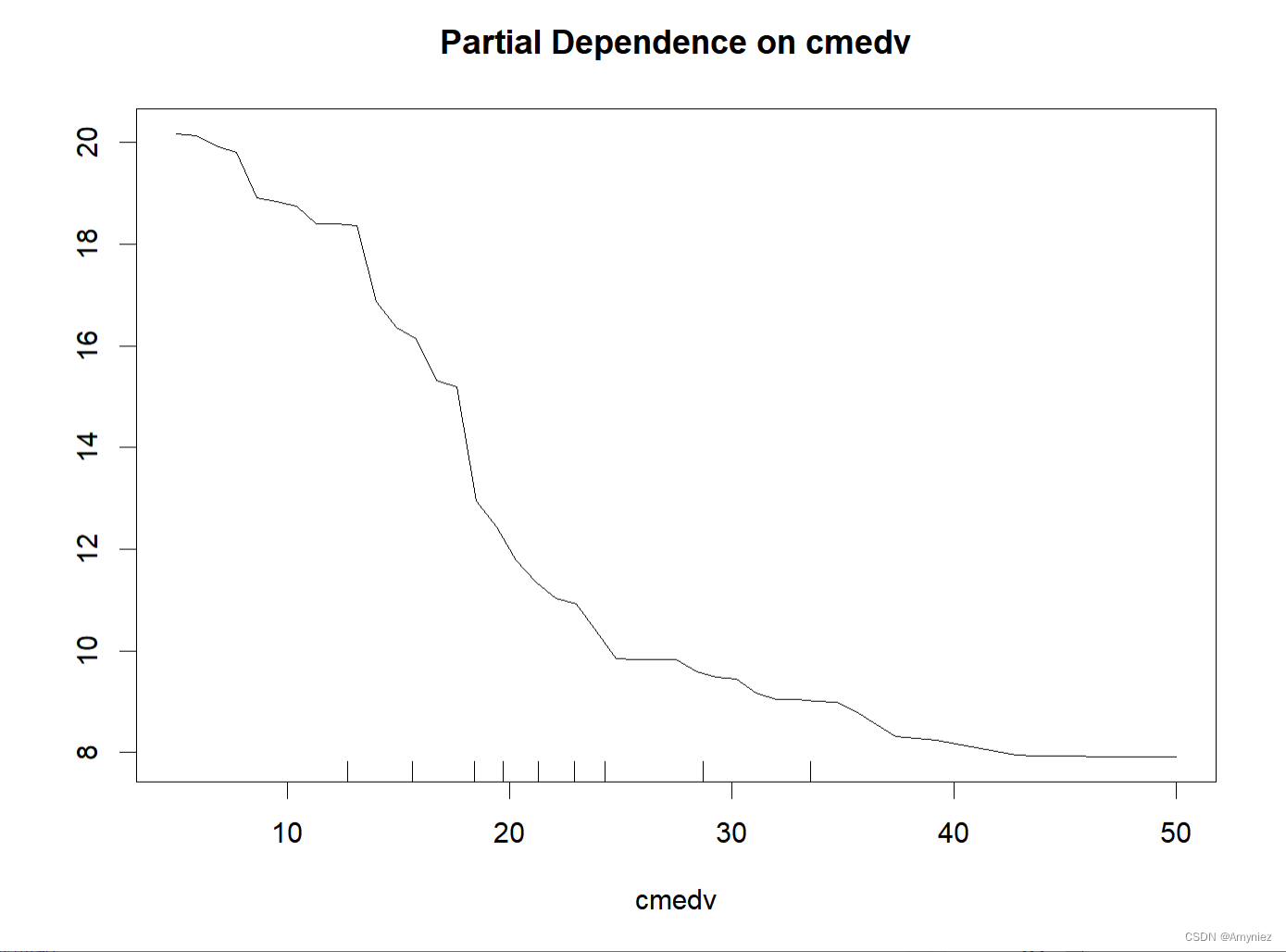
部分依赖图可以显示目标和特征之间的关系是线性的、单调的还是更复杂的
缺点: 部分依赖函数中现实的最大特征数是两个,这不是PDP的错,而是2维表示(纸或屏幕)的错,是我们无法想象超过3维的错。
partialPlot(x = rf_train,
pred.data = traindata,
x.var = cmedv
)
PDP图:
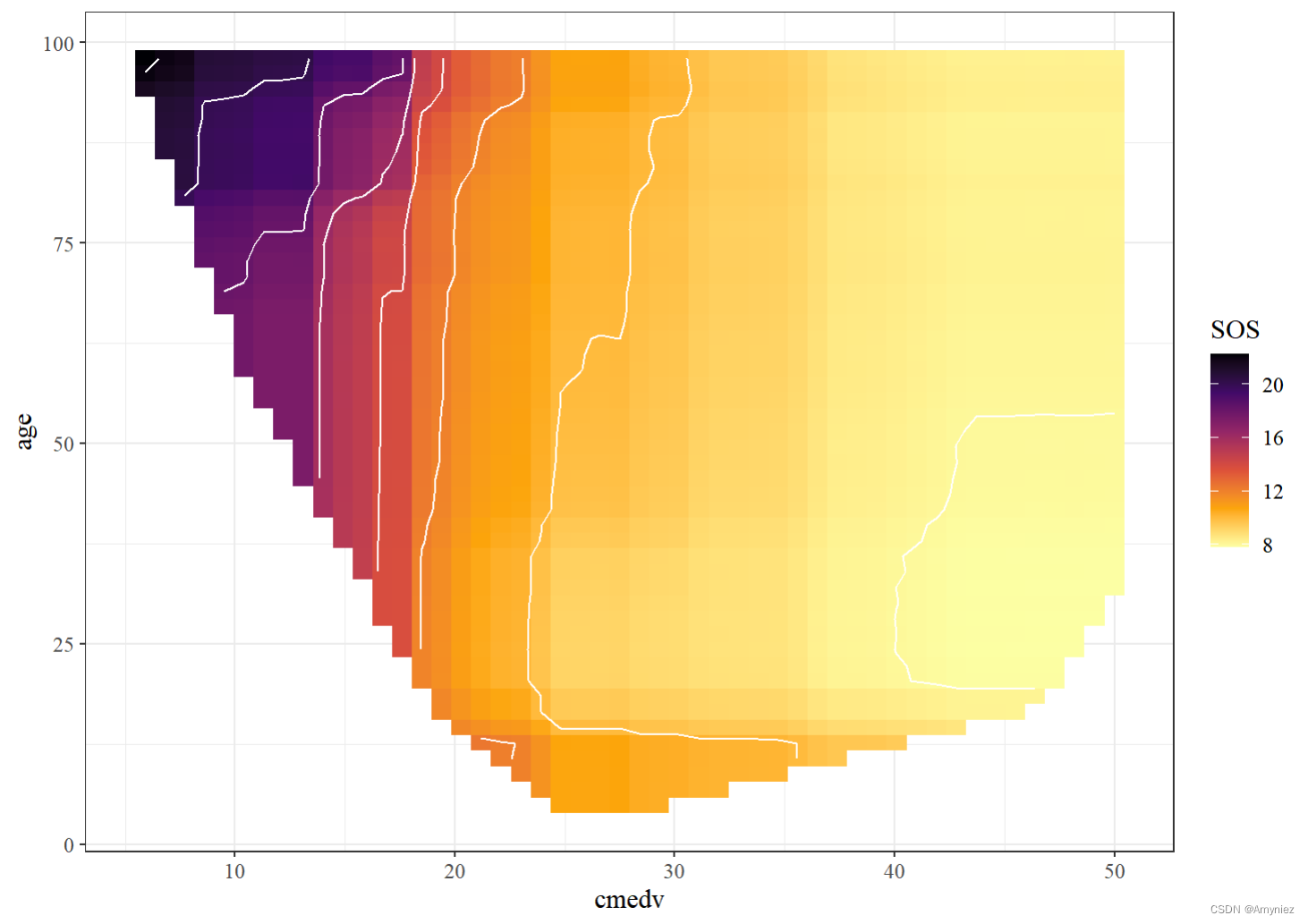
rf_train %>%
partial(pred.var = c("cmedv", "age"), chull = TRUE, progress = TRUE) %>%
autoplot(contour = TRUE, legend.title = "SOS",
option = "B", direction = -1) + theme_bw()+
theme(text=element_text(size=12, family="serif"))
交互结果展示:
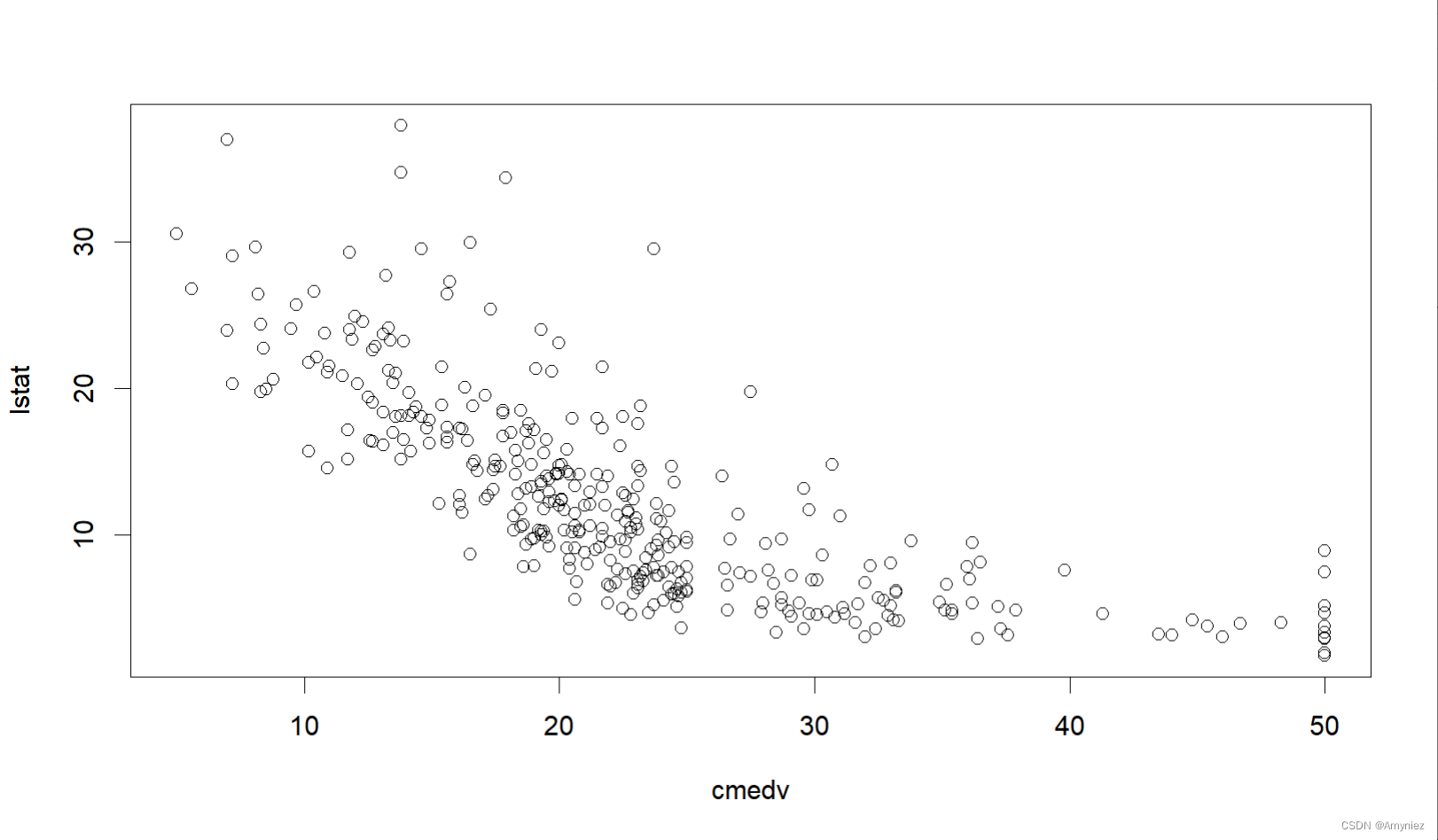
#预测与指标的关系散点图
plot(lstat ~ cmedv, data = traindata)
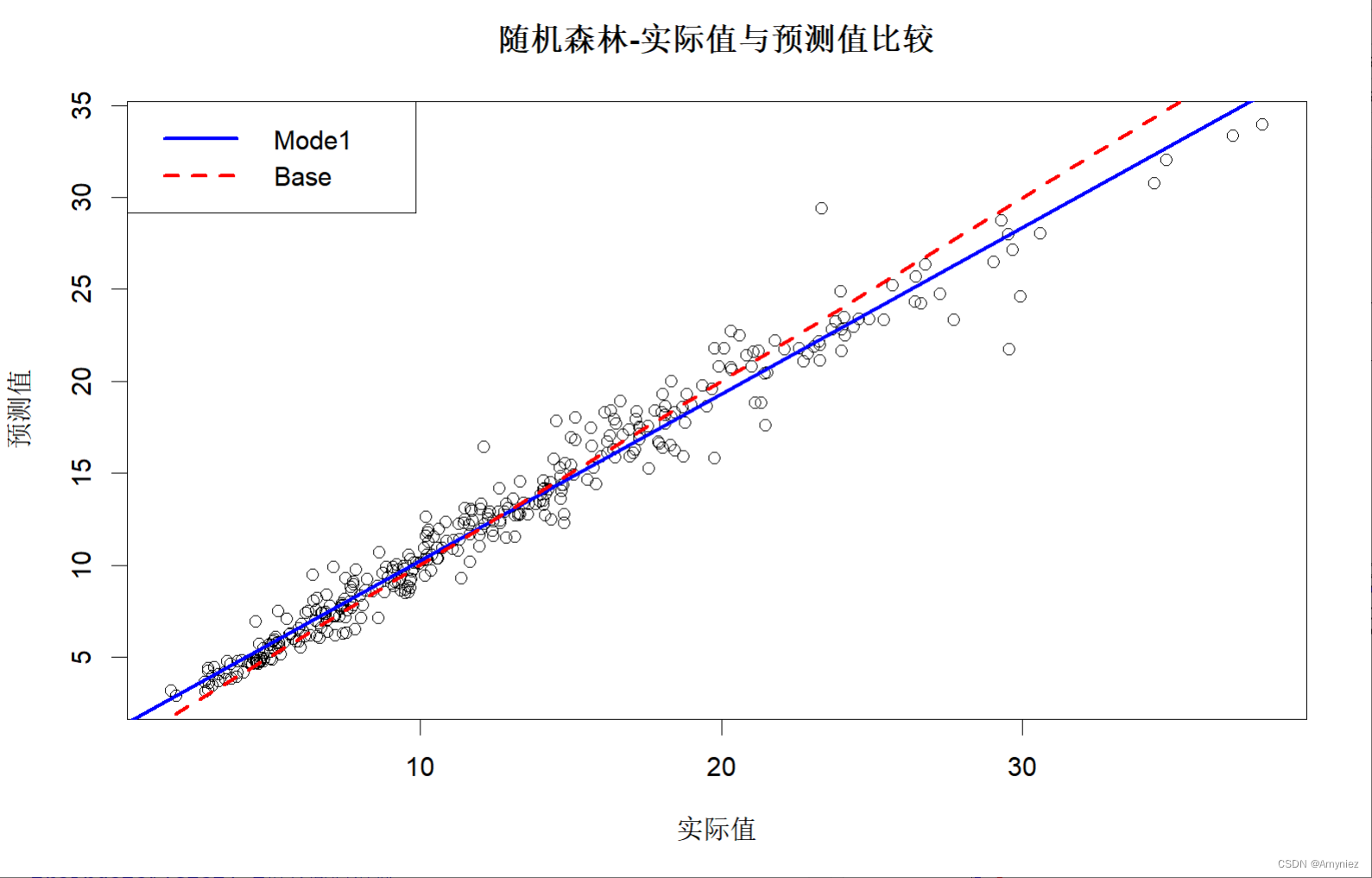
#图示训练集预测结果
plot(x = traindata$lstat,
y = trainpred,
xlab = "实际值",
ylab = "预测值",
main = "随机森林-实际值与预测值比较"
)
trainlinmod <- lm(trainpred ~ traindata$lstat) #拟合回归模型
abline(trainlinmod, col = "blue",lwd =2.5, lty = "solid")
abline(a = 0,b = 1, col = "red",lwd =2.5, lty = "dashed")
legend("topleft",legend = c("Mode1","Base"),col = c("blue","red"),lwd = 2.5,lty = c("solid","dashed"))
#测试集预测结果
testpred <- predict(rf_train,newdata = testdata)
#测试集预测误差结果
defaultSummary(data.frame(obs = testdata$lstat,pred = testpred))
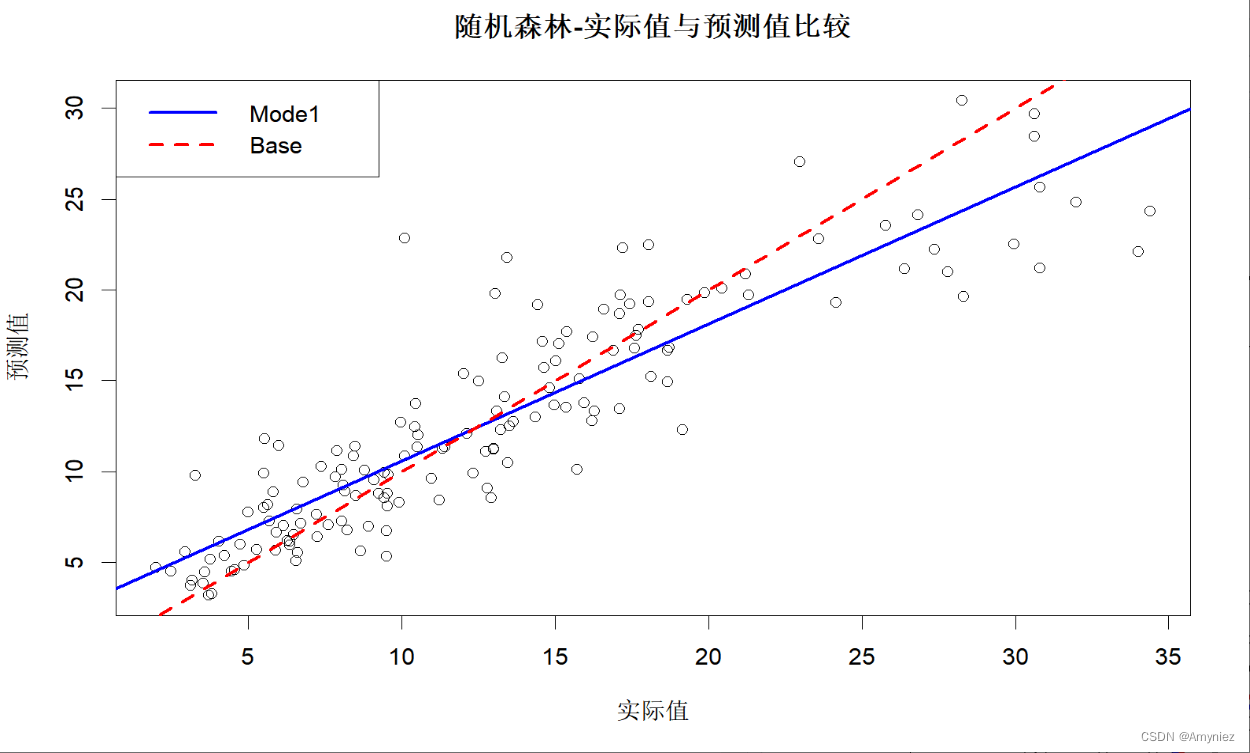
#图示测试集结果
plot(x = testdata$lstat,
y = testpred,
xlab = "实际值",
ylab = "预测值",
main = "随机森林-实际值与预测值比较"
)
testlinmod <- lm(testpred ~ testdata$lstat)
abline(testlinmod, col = "blue",lwd =2.5, lty = "solid")
abline(a = 0,b = 1, col = "red",lwd =2.5, lty = "dashed")
legend("topleft",legend = c("Mode1","Base"),col = c("blue","red"),lwd = 2.5,lty = c("solid","dashed"))
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg