文章目录

官方文档:https://cn.dubbo.apache.org/zh-cn/#td-block-1
基于接口的远程调用 、 容错和负载均衡、服务的自动注册与发现 。Dubbo 框架广泛的在阿里巴巴内部使用,以及京东、当当、去哪儿、考拉等都在使用。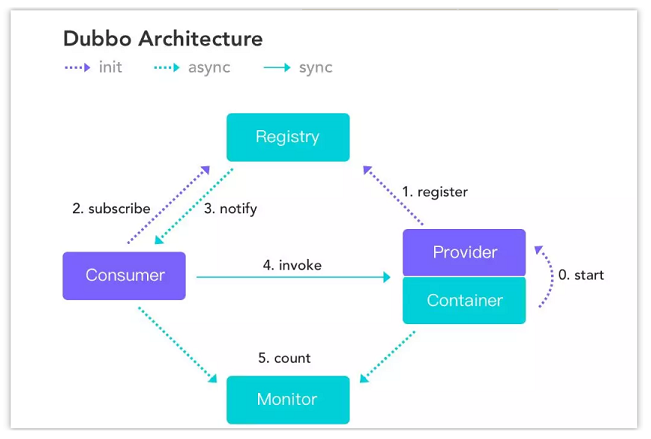
节点角色说明:
核心流程
notify 通知消费者。invoke 调用提供方提供的服务了,这个服务调用属于RPC远程服务调用,归属于Dubbo管理。
ZooKeeper 是一个开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现,是 Hadoop 和 Hbase 的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
官方下载地址:Apache Downloads(Zookeeper 是用 Java 编写的,所以需要先有 JDK)
参考文章:ZooKeeper单机与集群搭建
windows 下的安装与配置:
①下载并解压 apache-zookeeper-3.8.0-bin.tar.gz
②在解压好的目录下,创建 data 目录和 log 目录

③配置文件:将 conf 目录下的 zoo_sample.cfg 文件复制一份,并重命名为 zoo.cfg,修改内容:
clientPort=2181
admin.serverPort=8888
dataDir=D:\\apache-zookeeper-3.8.0-bin\\data
dataLogDir=D:\\apache-zookeeper-3.8.0-bin\\log
注意:此处的路径一定要使用双斜杠 \\
④在 bin 目录下,启动 zookeeper
zkServer.cmd:启动服务端后,客户端就可以连接上了,服务也能注册到 zookeeper 中了。
zkCli.cmd:启动客户端后,就可以查看 zookeeper 中的节点信息了,客户端基础命令使用。
官方教程:https://cn.dubbo.apache.org/zh-cn/overview/mannual/java-sdk/quick-start/spring-boot
官方是将一个完整的服务分为三个模块,比如图书服务可分为:API(提供 BookService 接口)、服务端(提供API的实现类 BookServiceImpl)、消费端(BookServer,真正的图书服务模块)。

我们还是以之前的 图书借阅系统 为例进行学习,但不会这么麻烦,主要展示 Dubbo+Zookeeper 实现服务远程调用。
在父工程中添加 Dubbo + Zookeeper 的依赖管理:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>2.7.10</version>
</dependency>
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-dependencies-zookeeper</artifactId>
<version>2.7.10</version>
<type>pom</type>
</dependency>
</dependencies>
</dependencyManagement>
我们将 bookService 和 userService 作为服务端,所以下面的操作在这两个模块上都要进行一次。
①添加依赖
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-dependencies-zookeeper</artifactId>
<type>pom</type>
<!--排除SLF4J多种实现的冲突: logback-classic 和 slf4j-log4j12-->
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
②启动类添加 @EnableDubbo 注解
@SpringBootApplication
@EnableDubbo
public class BookApplication {
public static void main(String[] args) {
SpringApplication.run(BookApplication.class, args);
}
}
③yml 配置文件:配置 Dubbo 和 注册中心
dubbo:
application:
name: book-provider
registry: #注册中心
address: zookeeper://127.0.0.1:2181
protocol: #协议,不同模块的端口不能一致
name: dubbo
port: 20880
④暴露服务:将对外提供的服务实现类用 @DubboService 注解修饰
@Service
@DubboService
public class BookServiceImpl implements BookService {
@Resource
private BookMapper bookMapper;
@Override
public Book getBookById(int bid) {
return bookMapper.getBookById(bid);
}
}
我们将 borrowService 作为消费端。
①添加依赖,还需要依赖两个服务端模块
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-dependencies-zookeeper</artifactId>
<type>pom</type>
<!--排除SLF4J多种实现的冲突: logback-classic 和 slf4j-log4j12-->
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.wangshaoyu</groupId>
<artifactId>book-service</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.wangshaoyu</groupId>
<artifactId>user-service</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
②消费端的启动类不需要添加 @EnableDubbo 注解
@SpringBootApplication
public class BorrowApplication {
public static void main(String[] args) {
SpringApplication.run(BorrowApplication.class, args);
}
}
③yml 配置文件:配置 Dubbo 和 注册中心
dubbo:
application:
name: book-provider
registry: #注册中心
address: zookeeper://127.0.0.1:2181
protocol: #协议,不同模块的端口不能一致
name: dubbo
port: 20882
④调用服务:使用 @DubboReference 来注入远程的服务类
@Service
public class BorrowServiceImpl implements BorrowService {
@Resource
private BorrowMapper borrowMapper;
@DubboReference
private UserService userService;
@DubboReference
private BookService bookService;
@Override
public UserBorrowView getBorrowViewByUid(int uid) {
List<Borrow> borrowList = borrowMapper.getBorrowsByUid(uid);
User user = userService.getUserById(uid);
List<Book> bookList = borrowList
.stream()
.map(b -> bookService.getBookById(b.getBid()))
.collect(Collectors.toList());
return new UserBorrowView(user, bookList);
}
}
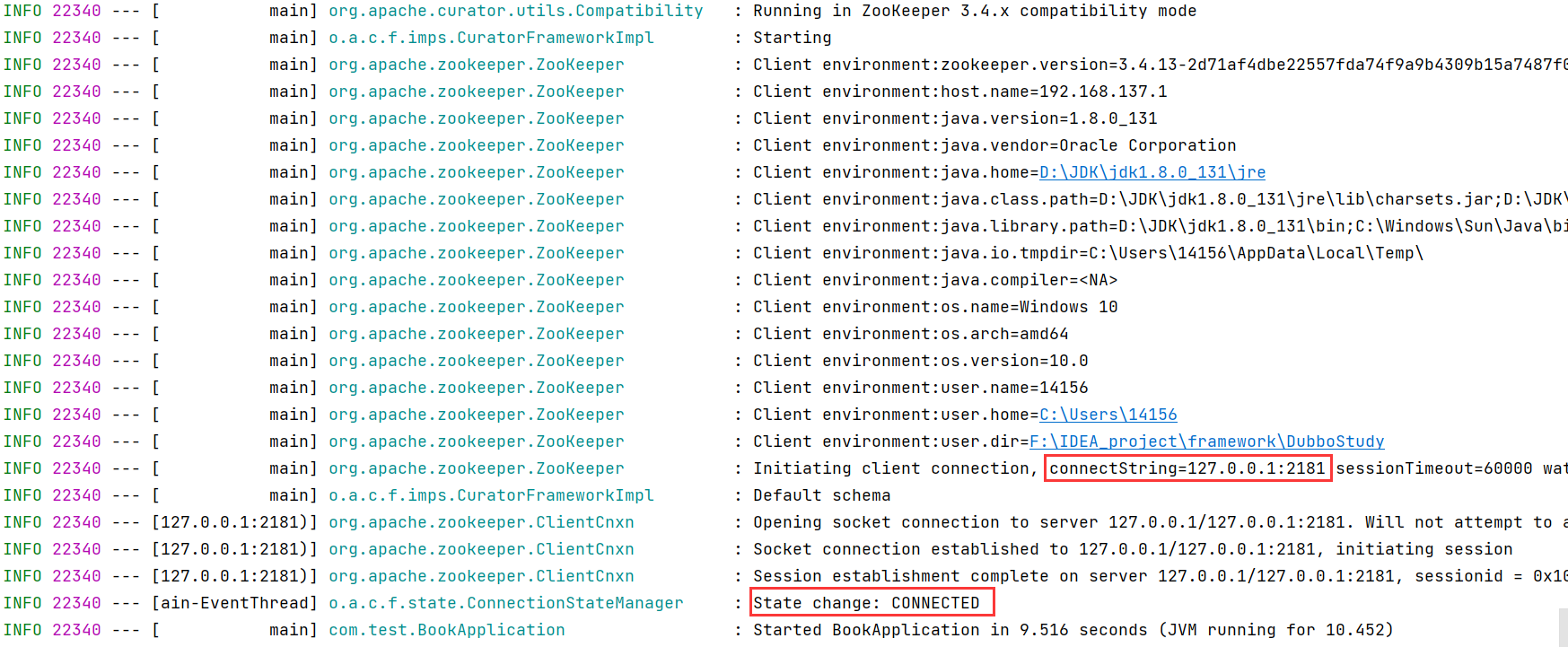
①启动服务端:发现连接成功。
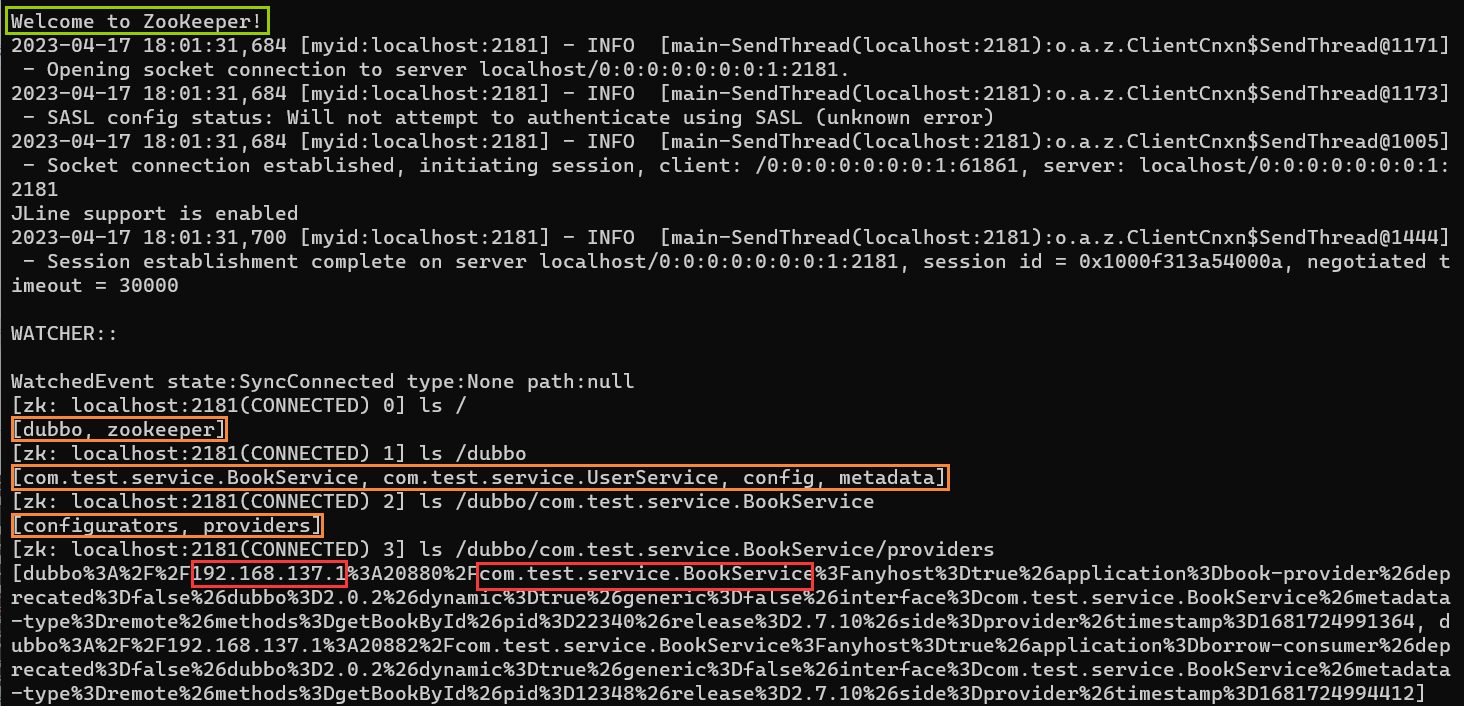
②启动 zookeeper 客户端:可以通过指令查看节点了。
官方部署教程:https://cn.dubbo.apache.org/zh-cn/overview/reference/admin/architecture
我们先下载官方源码,我的云盘里有 dubbo-admin.zip
https://github.com/apache/dubbo-admin.git
解压可以看到里面有这两个文件夹,因为 Dubbo-Admin 是前后端分离的两个工程项目。

①修改配置文件:application.properties,先根据自己注册中心的信息修改
admin.registry.address=zookeeper://127.0.0.1:2181
admin.config-center=zookeeper://127.0.0.1:2181
admin.metadata-report.address=zookeeper://127.0.0.1:2181
admin.root.user.name=root
admin.root.user.password=root
②开始打包,如果已经有了 target 则先删除。 在 dubbo-admin-server 目录下进入终端,执行以下指令。
mvn clean compile package
打包成功后,就是这样的画面。。。打包时出错,可参考文章:mvn 无法识别解决方案
最终,我们会在 target 下看到 jar 包

③启动服务器
方法一:我们可以在 target 目录下进入终端,然后执行以下指令启动服务器:
java -jar dubbo-admin-server-0.2.0-SNAPSHOT.jar
方法二:我们可以放到 IDEA 中管理,便于频繁的启动和关闭。

注意:不要修改 dubbo-admin-server 的端口,它默认是 8080,修改后前端就连接不上了。
①先下载安装 node.js,参考文章:安装 nodejs 和 npm 教程

npm info vue 报错参考文章:npm安装报错
②安装依赖并启动,在 dubbo-admin-ui 目录下进入终端执行以下指令:
# 安装依赖,仅需执行依次
npm install
# 启动指令
npm run dev
可参考文章:解决npm install 安装慢!!!
③启动成功,会进入这个页面。

启动前端工程后,我们会得到访问地址:http://localhost:8081
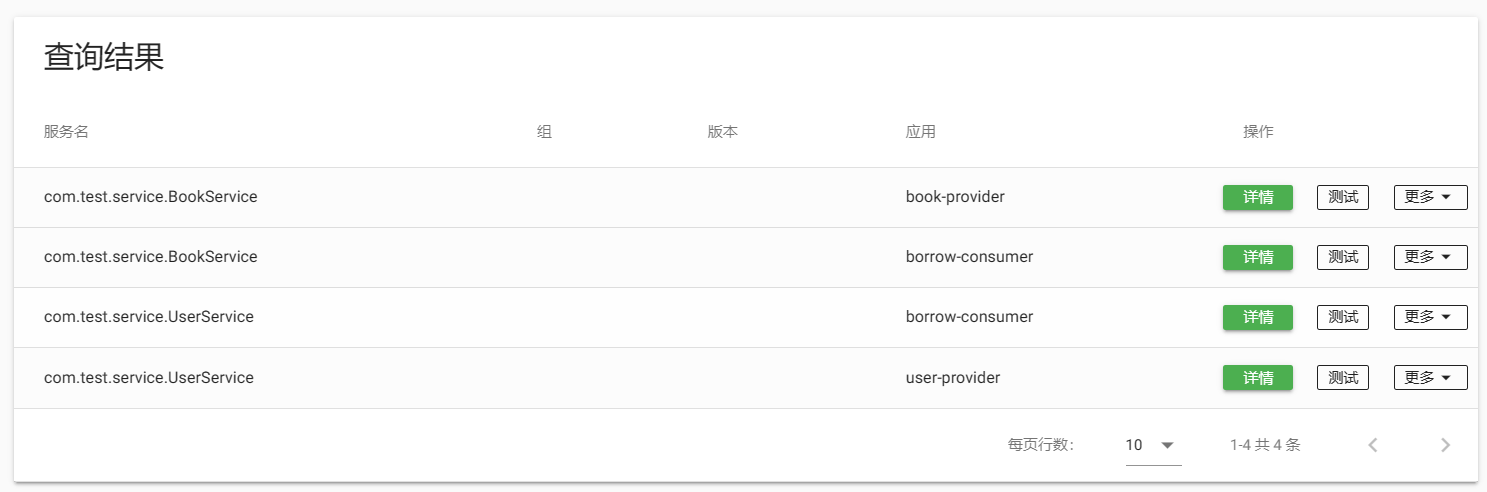
服务查询结果:
总结:
提示:这里对文章进行总结:
本文是对Dubbo的入门学习,先通过官方架构图了解了启动流程,又安装了zookeeper注册中心,随之学习了SpringBoot整合Dubbo,实现了服务间的远程调用,最后安装了Dubbo-Admin管理服务,并且访问了管理页面。之后的学习内容将持续更新!!!
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我正在尝试编写一个将文件上传到AWS并公开该文件的Ruby脚本。我做了以下事情:s3=Aws::S3::Resource.new(credentials:Aws::Credentials.new(KEY,SECRET),region:'us-west-2')obj=s3.bucket('stg-db').object('key')obj.upload_file(filename)这似乎工作正常,除了该文件不是公开可用的,而且我无法获得它的公共(public)URL。但是当我登录到S3时,我可以正常查看我的文件。为了使其公开可用,我将最后一行更改为obj.upload_file(file
如何在ruby中调用C#dll? 最佳答案 我能想到几种可能性:为您的DLL编写(或找人编写)一个COM包装器,如果它还没有,则使用Ruby的WIN32OLE库来调用它;看看RubyCLR,其中一位作者是JohnLam,他继续在Microsoft从事IronRuby方面的工作。(估计不会再维护了,可能不支持.Net2.0以上的版本);正如其他地方已经提到的,看看使用IronRuby,如果这是您的技术选择。有一个主题是here.请注意,最后一篇文章实际上来自JohnLam(看起来像是2009年3月),他似乎很自在地断言RubyCL
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www