声明:本文为学习笔记,欢迎各位大佬的意见与建议,侵权删
所用函数:pandas.read_csv(file_path)
数据挖掘时我们更多得会使用CSV文件,而不是Excel文件。如果数据本身以Excel的形式存储,只需打开,另存为CSV文件即可。
读取CSV文件需要调用pandas包,没有的自行pip一下哦。
举例:
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv",encoding="GBK")
/*一般情况下,读取CSV文件只需要pandas.read_csv(file_path)即可,
而我这里再后面加了个变量encoding="GBK",
是因为我的CSV文件里有中文字符,是非ASCII码。
GBK是解析中文的编码格式。不加会无法解析。*/
print(data)运行结果:
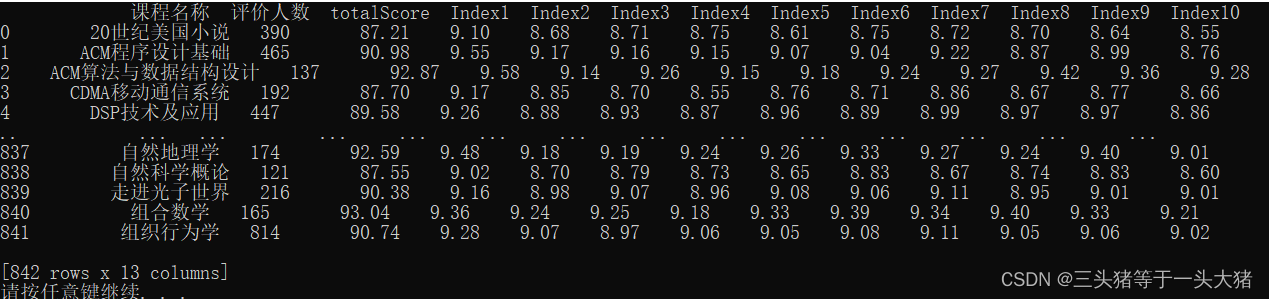
那么有时候我们会遇到另一种CSV文件,里面的数据用“::”分割,(通常CSV文件里数据用“,”分隔)按上面的方法直接读文件就会就像这样:

这时候需要在read_csv()函数中加一个参数sep,表示分隔符,默认是","。同时发现,这份数据里没有表头(好像是叫这个吧,就是一般第一行都是说明每一列表示的是什么数据),那么还需要两个参数header="None",表明没有表头,names=[],表明表头应该是啥。像这样
import pandas
data = pandas.read_csv(r"D:\Python Code\dataMining\ratings.csv",sep="::",header=None,names = ["用户id","电影id","评分","评分时间"])
print(data)运行结果:
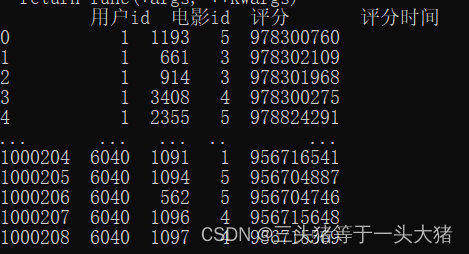
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv",usecols=["totalScore"],encoding = "GBK")
print(data)
/*
输出:
totalScore
0 87.21
1 90.98
2 92.87
3 87.70
4 89.58
.. ...
837 92.59
838 87.55
839 90.38
840 93.04
841 90.74
*/
---------------------------------------分割线------------------------------------------
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv",encoding="GBK")
print(data["totalScore"])
/*
输出:
0 87.21
1 90.98
2 92.87
3 87.70
4 89.58
...
837 92.59
838 87.55
839 90.38
840 93.04
841 90.74
Name: totalScore, Length: 842, dtype: float64
*/
---------------------------------------分割线------------------------------------------
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv",encoding="GBK")
print(data["totalScore"].array)
/*
输出:
<PandasArray>
[87.21, 90.98, 92.87, 87.7, 89.58, 91.35, 89.5, 91.61, 89.55, 90.54,
...
90.46, 88.52, 83.23, 90.83, 92.82, 92.59, 87.55, 90.38, 93.04, 90.74]
Length: 842, dtype: float64
即把某一列的数据转成array的形式输出
*/
---------------------------------------分割线------------------------------------------
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv",encoding="GBK")
print(data["totalScore"].array[0])
/*
输出:
87.21
即:把某列数据转成array后,就可以对它做array的相关操作了
*/
---------------------------------------分割线------------------------------------------
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv",encoding="GBK")
print(data["日期"].dt.year)
/*
data[].dt.year/month...是用来处理CSV中的日期类型的数据的
我这份数据里没有日期类型的数据,所以这里只是模拟一下,并没有实际输出
另外,如果原数据里关于日期的数据并非标准的日期类型(year-month-date)
那么可以用pandas.to_datetime()函数将他们转变为日期类型,具体用法自行百度哈哈
*/
更改某列的所有数据/添加新的一列数据:data["index"] = ...
例子:
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv",encoding="GBK")
#“number”这一列本身不存在原数据中,但可以通过下面这个方法在末尾加一列“日期”
data["number"] = [1]*842
#现在已经成功添加了"number”这一列数据,然后再对他整体更改
data["number"] = data["number"]+1
print(data)运行结果(可以看到末尾添加了一列number):
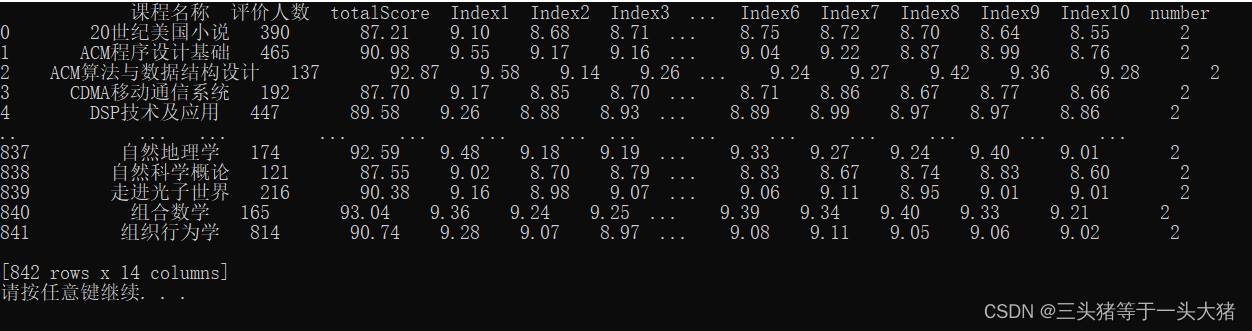
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv", encoding="GBK")
first = data["Index1"]
second = data["Index2"]
third = data["Index3"]
newIndex = pandas.concat([first,second,third],axis=1)
newIndex.columns = ["INDEX1","INDEX2","INDEX3"]
print(newIndex)运行结果:
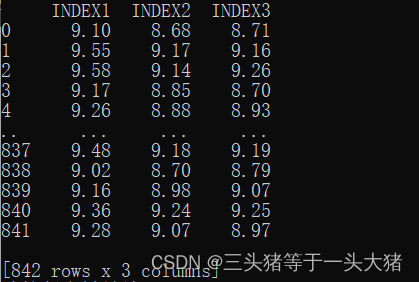
所用函数:to_csv(path)
例子(index = False指不将行索引信息写入第一列):
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv",usecols=["totalScore"],encoding = "GBK")
data.to_csv(r"D:\数据挖掘\大作业\pjsj_raw_totalScore.csv",index=False)运行结果:

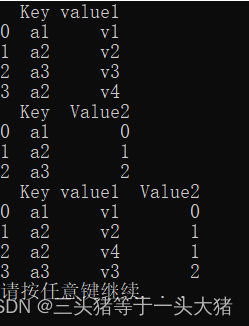
所用函数:merge(csv1,csv2)
例子(merge函数默认的连接方法为内连接/等值连接(inner),当然也有outer(外链接)、left(左连接)、right(右连接)):
import pandas
data_1 = pandas.read_csv(r"D:\Python Code\dataMining\test_1_2.csv")
data_2 = pandas.read_csv(r"D:\Python Code\dataMining\test_3.csv")
print(data_1)
print(data_2)
data_all = pandas.merge(data_1,data_2)
print(data_all)运行结果:
拿到一份数据后,先要对数据进行清洗。分为三个步骤:
1、识别并处理缺失值
2、识别并处理异常值
3、识别并处理重复值
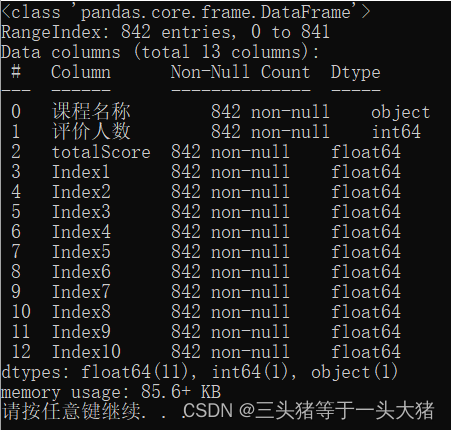
检测是否有缺失值:data.info() //data就是上面那个例子里的data,即读取到的CSV文件对象
函数会输出每个列项的相关数据统计【格式:行号 列值 每列的非空数据的总数 数据类型】,
例子:
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv",encoding="GBK")
data.info()运行结果(这份数据总行数842行,所有列项都是842个非空数据,因此没有缺失值。如果某行有缺失值,那么该行的Non-Null Count 应小于总行数):
筛选出缺失值:布尔索引,data[data[Index].isnull()]
删除缺失值:data.drop()
例子:
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv",encoding="GBK")
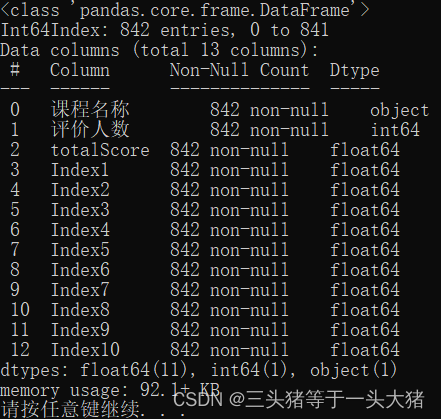
nullData = data[data["Index1"].isnull()]
data.drop(index = nullData.index, inplace=True)
data.info()输出结果(我这份数据因为没有缺失值,所以没变化。如果有缺失值,那么处理完之后,总行数应该会变少,且所有列项的非空行数相等,都等于总行数):
删除空值还有一个简单的方法:dropna()
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv",encoding="GBK")
data.dropna()注意,数据异常的标准是灵活多变的,主观判断的。比如我这份数据是教评数据,所以教评每个指标的分数不会是负数,也不会大于10(这里设定评分最高为10),如果出现了这个区间之外的数据,那么就是异常值。
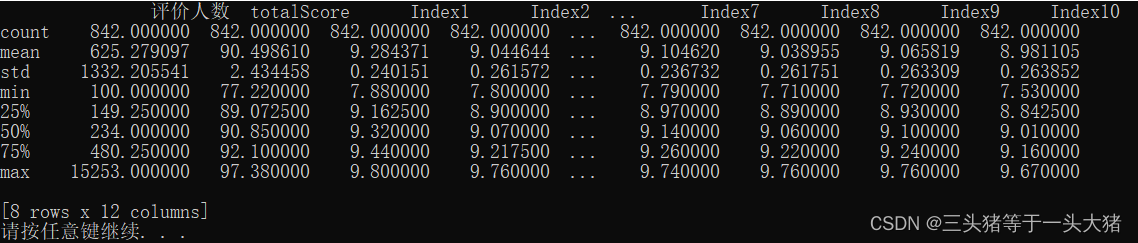
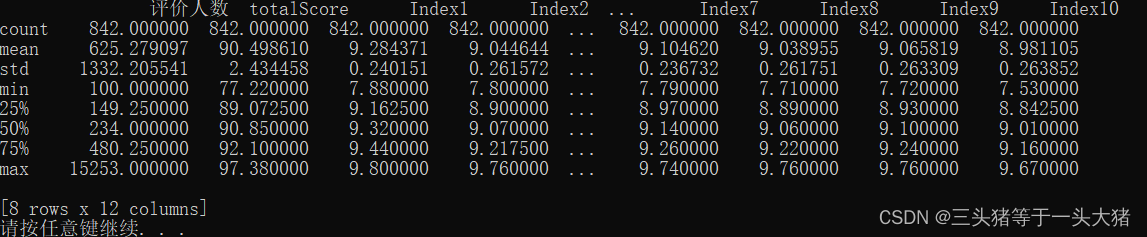
数据描述:data.describe() //输出数据最值、标准差、平均数等描述的标准。
通过数据描述,可以对数据有个整体直观的了解。
例子:
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv",encoding="GBK")
print(data.describe())运行结果:
异常数据筛除:利用布尔索引,把正常数据筛选出来
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv",encoding="GBK")
siftedData = data[(data["Index1"] >= 0) & (data["Index1"] <= 10)] #这里只对Index1做了筛选
print(siftedData.describe())运行结果(可以看到处理后没变化,因为我的数据很乖,没有异常,嘿嘿):
查找重复的数据:data.duplicated()
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv",encoding="GBK")
duplicateData = data[data.duplicated()]
print(duplicateData)运行结果(显示empty dataframe说明没有重复值):

删除重复值:看这篇文章,我觉得讲的全面清晰
看这里
这里用另一份数据,结构如下

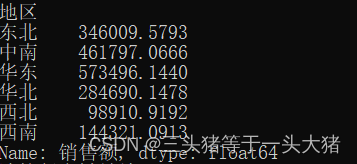
应用例子(对消费额,根据地区分组,求出消各地的消费额总和):
groupByArea =data["销售额"].groupby(data['地区']).sum()
#sum()函数默认为竖着加,如果写成sum(axis=1)则是横着加
print(groupByArea)运行结果:
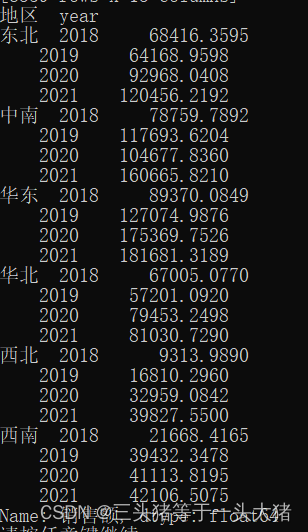
如果分组的条件比较苛刻,有多重的要求,比如,对消费额,根据地区以及年份分组,求出各地每年的消费额,那么:
groupByArea =data["销售额"].groupby([data['地区'],data["year"]]).sum()
print(groupByArea)运行结果:
再复杂一点, 对消费额,根据地区、省/自治区以及年份分组,求出各省/自治区每年的消费额,那么:
groupByArea =data["销售额"].groupby([data['地区'],data["省/自治区"],data["year"]]).sum()
print(groupByArea)
运行结果:

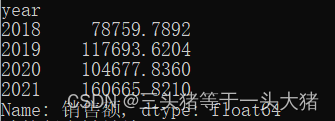
再进一步,如果需要指定具体某地区,每年的销售额,那么可以用loc()函数,loc和iloc函数先关内容看这里,例如:
groupByArea =data["销售额"].groupby([data['地区'],data["year"]]).sum()
print(groupByArea.loc["中南"])
运行结果:
使用函数:sort_values()
例子:
import pandas
data = pandas.read_csv(r"D:\数据挖掘\大作业\pjsj_raw.csv", encoding="GBK")
#按totalScore 递增 排序
data = data.sort_values(by="totalScore",ascending=True)
#输出前三个
print(data.iloc[0:3])运行结果:

接下来就可以进一步对这些得到的数据进行画图啊啥的操作了。
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
CSV.open(name,"r").eachdo|row|putsrowend我得到以下错误:CSV::MalformedCSVErrorUnquotedfieldsdonotallow\ror\n文件名是一个.txt制表符分隔文件。我是专门做的。我有一个.csv文件,我转到excel,并将文件保存为.txt制表符分隔的文件。所以它是制表符分隔的。CSV.open不应该能够读取制表符分隔的文件吗? 最佳答案 尝试像这样指定字段分隔符:CSV.open("name","r",{:col_sep=>"\t"}).eachdo|row|
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_