
📃个人主页:「小杨」的csdn博客
🔥系列专栏:【JavaScript速成之路】
🐳希望大家多多支持🥰一起进步呀!
文章目录
📜前言:小杨在上一篇带着大家一起学习了JavaScript中的内置的数组对象,想必大家对JavaScript的内置的数组对象已经有所了解了,那么今天我们将继续带着大家学习一下JavaScript的内置对象中的字符串对象这部分相关知识,希望大家收获多多!
<script>
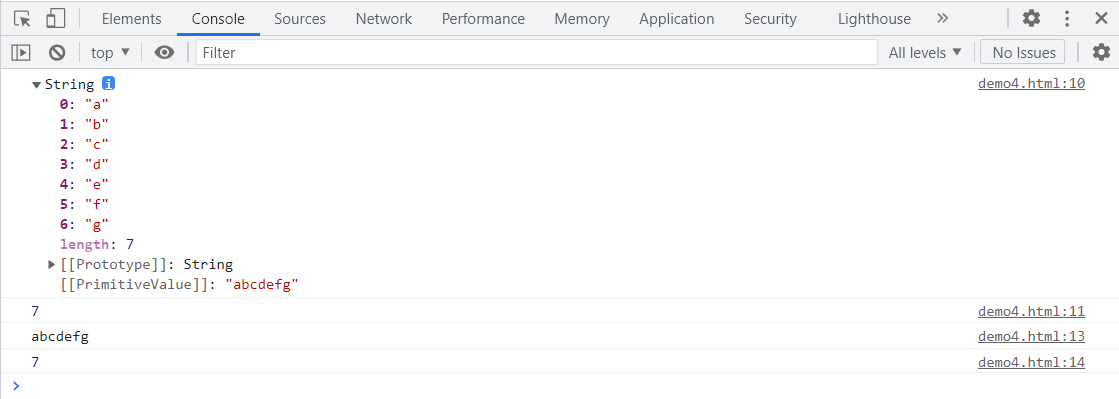
var str = new String('abcdefg');
console.log(str);
console.log(str.length);
var str = 'abcdefg';
console.log(str);
console.log(str.length);
</script>
示例结果:
拓展1:字符串对象String与字符串变量str的区别
为了更好地了解字符串对象String与字符串变量str的区别,示例如下:
<script>
//String字符串对象 与 str 字符串变量区别
var obj = new String('abcdef');
console.log(typeof obj);
console.log(obj instanceof String);
var str = 'abcdef';
console.log(typeof str);
console.log(str instanceof String);
</script>
示例结果:

| 成员 | 作用 |
|---|---|
| indexOf(searchValue) | 获取searchValue在字符串中首次出现的位置 |
| lastIndexOf(searchValue) | 获取searchValue在字符串中最后出现的位置 |
为了更好地理解上述方法的使用,示例如下:
<script>
//根据字符返回位置
var str = 'abcdefedc';
console.log(str.indexOf('d'));
console.log(str.lastIndexOf('d'));
</script>
示例结果:

| 成员 | 作用 |
|---|---|
| charAt(index) | 获取index位置的字符,位置从0开始计算 |
| charCodeAt(index) | 获取index位置的字符的ASCll码 |
| str[index] | 获取指定index位置处的字符(HTML5新增) |
为了更好理解上述方法的使用,示例如下:
<script>
//根据位置返回字符
var str = 'abcdef';
console.log(str.charAt(2));
console.log(str.charCodeAt(2));
console.log(str[2]);
</script>
示例结果:

| 成员 | 作用 |
|---|---|
| concat(str1,str2,…) | 连接多个字符串,等效于+,+更实用 |
| slice(start,end) | 截取从start位置到end位置之间的一个子字符串,截取范围为[start,end-1] |
| substring(start,end) | 截取从start位置到end位置之间的一个子字符串,基本和slice相同,但不接收负值 |
| substr(start,end) | 截取从start位置开始到length长度的子字符串 |
| toLowerCase() | 获取字符串的小写形式 |
| toUpperCase() | 获取字符串的大写形式 |
| split(separator,limit) | 使用separator分隔符将字符串分隔成数组,limit用于限制数量 |
| replace(str1,str2) | 使用str2替换字符串中的str1,返回替换结果,只会替换第1个字符 |
为了更好地理解上述方法的使用,现对上述方法逐一介绍:
1)concat()方法
concat()方法,连接多个字符串
<script>
var str1 = 'abc';
console.log(str1.concat('de')); //连接一个字符串
console.log(str1.concat('de','fg')); //连接两个字符串
console.log(str1.concat('de','fg','h')); //连接三个字符串
console.log(str1); //查看方法对原字符串的影响
</script>
示例结果:

2)slice()方法
slice()方法,截取从start位置到end位置之间的一个子字符串,截取范围为[start,end-1]
<script>
var str2 = 'abcdefg';
console.log(str2.slice()); //无参数,默认截取字符串,截取范围:[0,len-1]
console.log(str2.slice(2)); //有参数start,从start开始截取字符串,截取范围:[start,len-1]
console.log(str2.slice(2,4)); //有参数start和end,从start开始截取字符串,截取范围:[start,end-1]
console.log(str2); //查看方法对原字符串的影响
</script>

3)substr()方法
substr()方法,截取从start位置开始到length长度的子字符串
<script>
var str3 = 'abcdefg';
console.log(str3.substr()); //无参数,默认截取字符串,截取范围:[0,len-1]
console.log(str3.substr(2)); //有参数start,从start开始截取字符串,截取范围:[start,len-1]
console.log(str3.substr(2,2)); //有参数start和length,从start开始截取字符串,截取长度:length
console.log(str3.substr(0,2)); //有参数length,从0开始截取字符串,截取长度:length
console.log(str3); //查看方法对原字符串的影响
</script>
示例结果:

4)toLowerCase(),toUpperCase()
toLowerCase()方法,获取字符串的小写形式
toUpperCase()方法,获取字符串的大写形式
<script>
var str4 = 'ABCdef';
console.log(str4.toLowerCase()); //将字符串转为小写形式
console.log(str4.toUpperCase()); //将字符串转为大写形式
console.log(str4); //查看方法对原字符串的影响
</script>
示例结果:

5)split()方法
split()方法,使用separator分隔符将字符串分隔成数组,limit用于限制数量
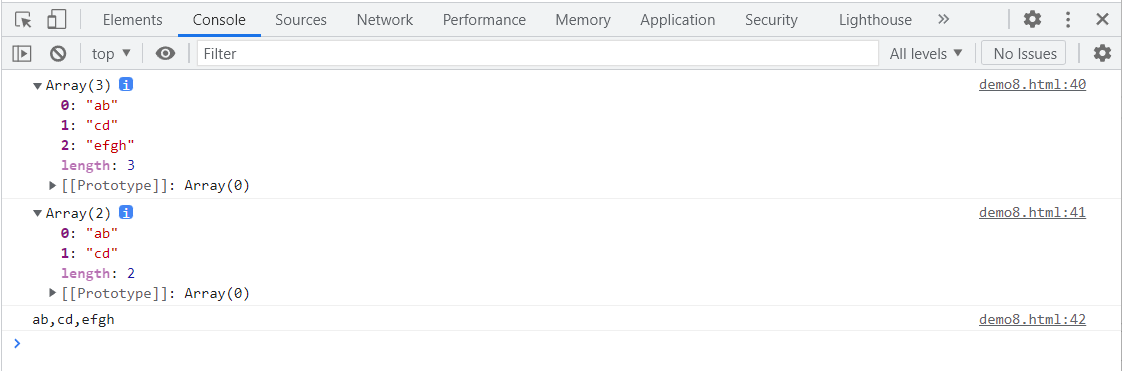
<script>
var str5 = 'ab,cd,efgh';
console.log(str5.split(',')); //有参数separator,以分隔符将字符串分隔成数组
console.log(str5.split(',',2)); //有参数separator和limit,以分隔符将字符串分隔成数组,limit限制个数
console.log(str5);
</script>
示例结果:
6)replace()方法
replace()方法,使用str2替换字符串中的str1,返回替换结果,只会替换第1个字符
<script>
//replace()方法,使用str2替换字符串中的str1,返回替换结果,只会替换第1个字符
var str6 = 'abcdefg';
console.log(str6.replace('a','b')); //将字符串中的str1替换为str2,返回替换结果,只会替换第1个字符
console.log(str6);
</script>
示例结果:

为了方便操作基本数据类型,JavaScript还提供了三个特殊的引用类型:String、Number和Boolean。基本包装类型就是把简单数据类型包装成为复杂数据类型,这样基本数据类型就有了属性和方法。
var str = 'andy' ;
console.log(str. length);
按道理基本数据类型是没有属性和方法的,而对象才有属性和方法,但上面代码却可以执行,这是因为js 会把基本数据类型包装为复杂数据类型,其执行过程如下︰
//1.生成临时变量,把简单类型包装为复杂数据类型
var temp = new string ( 'andy' );
//2.赋值给我们声明的字符变量
str = temp;
//3.销毁临时变量
temp = null;
字符串的不变性指的是里面的值不可变,虽然看上去可以改变内容,但其实是地址变了,内存中新开辟了一个内存空间。
<script>
var str = 'abc';
console.log(str);
var str = 'bcd'; //当重新给str赋值的时候,常量"abc'不会被修改,
console.log(str); //依然在内存中重新给字符串赋值,会重新在内存中开辟空间,这个特点就是字符串的不可变
</script>
示例结果:

注意:由于字符串的不可变,在大量拼接字符串的时候会有效率问题。
这就是本期博客的全部内容啦,想必大家已经对JavaScript中的内置对象中的字符串对象的相关内容有了全新地认识和理解吧,如果有什么其他的问题无法自己解决,可以在评论区留言哦!
最后,如果你觉得这篇文章写的还不错的话或者有所收获的话,麻烦小伙伴们动动你们的小手,给个三连呗(点赞👍,评论✍,收藏📖),多多支持一下!各位的支持是我最大的动力,后期不断更新优质的内容来帮助大家,一起进步。那我们下期见!

总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
在我的Rails(2.3,Ruby1.8.7)应用程序中,我需要将字符串截断到一定长度。该字符串是unicode,在控制台中运行测试时,例如'א'.length,我意识到返回了双倍长度。我想要一个与编码无关的长度,以便对unicode字符串或latin1编码字符串进行相同的截断。我已经了解了Ruby的大部分unicode资料,但仍然有些一头雾水。应该如何解决这个问题? 最佳答案 Rails有一个返回多字节字符的mb_chars方法。试试unicode_string.mb_chars.slice(0,50)
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我有一大串格式化数据(例如JSON),我想使用Psychinruby同时保留格式转储到YAML。基本上,我希望JSON使用literalstyle出现在YAML中:---json:|{"page":1,"results":["item","another"],"total_pages":0}但是,当我使用YAML.dump时,它不使用文字样式。我得到这样的东西:---json:!"{\n\"page\":1,\n\"results\":[\n\"item\",\"another\"\n],\n\"total_pages\":0\n}\n"我如何告诉Psych以想要的样式转储标量?解