经过了两天的摸索,对于这个问题,终于圆满的解决了,对于一个深度学习的小白来说,面对这样的问题,实在太难受了。
在这几天里,不断去找一些博客的经验,很多都说把num_workers设置为0,但是却没有具体的关于如何设置的教程,使我在这个问题上特别难受。现在终于找到了解决办法了,希望能帮助到有同样问题的朋友。
由于在windows中是不能使用多个子进程加载数据的,在linux系统中可以。所以在windows中要将num_workers设置为0的。
具体怎么做呢,请往下看:
本文的例子问李沐老师的深度学习的示例(Lenet):
代码如下:
import torch
from torch import nn
from d2l import torch as d2l
from torch.utils import data
class Reshape(torch.nn.Module):
def forward(self,x):
return x.view(-1,1,28,28)
net = torch.nn.Sequential(
Reshape(),nn.Conv2d(1,6,kernel_size=5,padding=2),nn.Sigmoid(),
nn.AvgPool2d(2,stride=2),
nn.Conv2d(6,16,kernel_size=5),nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2,stride=2),nn.Flatten(),#把低维保持,高维的拉成一维,最终为一维向量
nn.Linear(16*5*5,120),nn.Sigmoid(),
nn.Linear(120,84),nn.Sigmoid(),
nn.Linear(84,10)
)
X = torch.rand(size=(1,1,28,28),dtype=torch.float32)
for layer in net:
X = layer(X)
#print(layer.__class__.__name__,'output shape:\t',X.shape)
# 模型训练
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
#使⽤GPU计算数据集
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使⽤GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""⽤GPU训练模型(在第六章定义)"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
d2l.plt.show()
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()window中,要是直接运行将会出现以下错误:
RuntimeError: DataLoader worker (pid(s) 8548, 6916) exited unexpectedly.
解决方法如下(把num_workers设置为0):
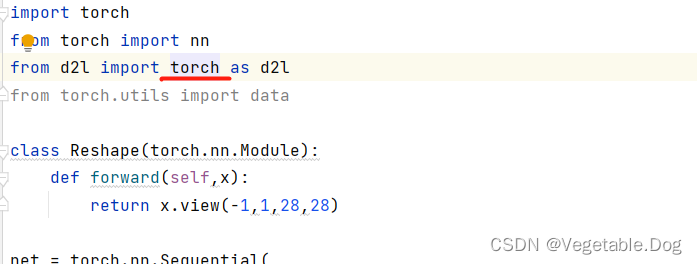
按住Ctrl键,然后点击进入torch.py文件,搜索“get_dataloader_workers”,到达以下函数的位置:
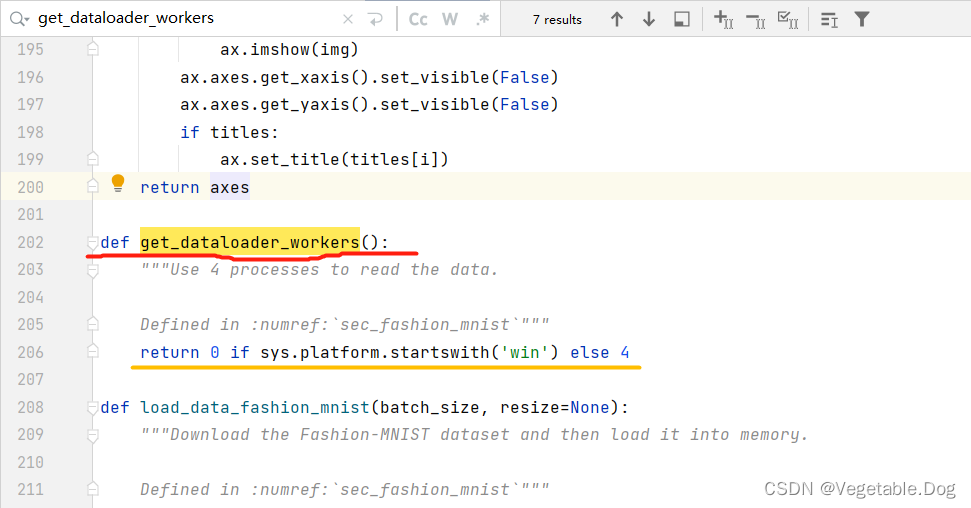
到达红线处的位置,然后把里面的函数体修改为黄线的语句:
def get_dataloader_workers():
"""Use 4 processes to read the data.
Defined in :numref:`sec_fashion_mnist`"""
return 0 if sys.platform.startswith('win') else 4把torch函数做了以上修改之后,就可以解决这个问题了。
下面是本人运行的结果:
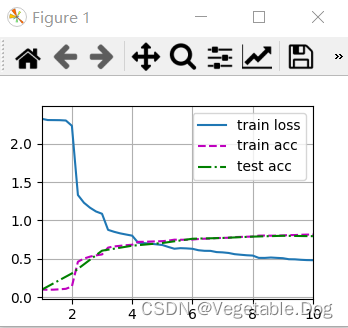
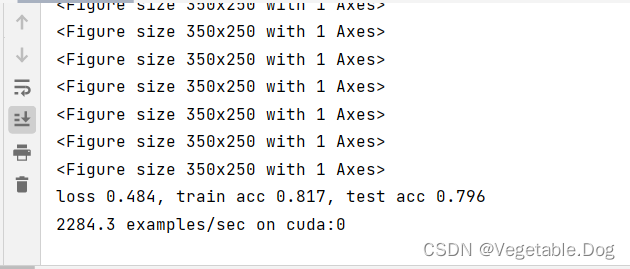
看到结果的我超级无敌激动。
以上就是我解决问题“RuntimeError: DataLoader worker (pid(s) 8548, 6916) exited unexpectedly”的方法,希望能帮助到有需要的人,希望能够帮助到更多人避坑。
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
RuntimeError:CUDAerror:device-sideasserttriggered问题描述解决思路发现问题:总结问题描述当我在调试模型的时候,出现了如下的问题/opt/conda/conda-bld/pytorch_1656352465323/work/aten/src/ATen/native/cuda/IndexKernel.cu:91:operator():block:[5,0,0],thread:[63,0,0]Assertion`index>=-sizes[i]&&index通过提示信息可以知道是个数组越界的问题。但是如图一中第二行话所说这个问题可能并不出在提示的代码段
为了停止Sidekiq,我需要使用:$bundleexecsidekiqctlstop/Users/me/Documents/sites/some_site/tmp/pid/sidekiq.pid20我告诉Sidekiq在config.yml文件中创建一个pid文件:#/Users/me/Documents/sites/some_site/config.yml:pidfile:/Users/me/Documents/sites/some_site/tmp/pids/sidekiq.pid:concurrency:25并告诉Sidekiq这个配置文件在哪里使用:$bundleexecsi
我尝试通过以下命令在我的计算机上安装gem(Mechanize):>>geminstallmechanize--platform=ruby>>geminstallmechanize错误ERROR:Errorinstallingmechanize:ERROR:Failedtobuildgemnativeextension."C:/ProgramFiles/Ruby200-x64/bin/ruby.exe"extconf.rbC:/ProgramFiles/Ruby200-x64/bin/ruby.exe:invalidswitchinRUBYOPT:-F(RuntimeError)在我尝
我在查看一些代码示例时发现了这一行:puts"child#$$accepting..."哪些输出>>child7231accepting...看起来$$是PID,它利用了普通#{$$}字符串插值语法的一些简写形式。不过我找不到这方面的文档。我很好奇还有哪些速记技巧可用(或者会让我感到困惑)。文档在哪里?为什么这很特别? 最佳答案 Ruby允许您省略全局($var)、实例(@var)和类(@@var)的大括号)进行字符串插值时的变量。 关于ruby-为什么ruby让我使用#$$在字符串
在我们的rails3.1.4应用程序中,rspec用于测试应用程序Controller中的公共(public)方法require_signin。这是require_signin方法:defrequire_signinif!signed_in?flash.now.alert="Loginfirst!"redirect_tosignin_pathendend这是rspec代码:it"shouldinvokerequire_signinforthosewithoutlogin"docontroller.send(:require_signin)controller{shouldredirec
我正在使用Ubuntu11.04在RubyonRails中开发一个应用程序。在应用程序中,我需要生成pdf文档。所以我正在使用wicked_pdf和wkhtmltopdf二进制gem。在我系统的开发环境中,一切正常。但是一旦我使用Phusion在CentOS5.6上部署应用程序乘客,当我尝试动态生成pdf时,出现以下错误:RuntimeError(wkhtmltopdf位置未知)我正在使用Ruby1.9.2.p136rails3.1.1任何帮助将不胜感激......谢谢。 最佳答案 另一种方法是通过Gemfile安装二进制文件。只需
我正在将开发中的应用程序从Rails4.2升级到Rails5beta1.1。应用程序在升级前运行良好。我已经完成了基本的升级步骤(更新Ruby、更新Rails和相关步骤:http://edgeguides.rubyonrails.org/upgrading_ruby_on_rails.html)。Gemfile也已更新为最新的Gems。当我运行$railsmiddleware或$railsconsole或$railsserver时,出现以下错误:Nosuchmiddlewaretoinsertafter:ActionDispatch::ParamsParser.../.rvm/gems
当我在Windows764位系统上运行bundleexecrspecspec/时,我收到以下错误:invalidswitchinRUBYOPT:-F(RuntimeError)我正在运行ruby1.9.2p136(2010-12-25)[i386-mingw32](安装在c:\ProgramFiles(x86)\Ruby192)和bundler1.0.15(作为rubygem安装).关于如何解决这个问题的任何线索?谢谢,本 最佳答案 Bundler不喜欢Ruby的路径包含空格这一事实。为了解决这个问题,我编辑了runtime
今天升级到Ruby-1.9.3-p392后,REXML在尝试检索超过一定大小的XML响应时抛出运行时错误-一切正常,当接收到25条以下的XML记录时不会抛出错误,但是一旦达到特定的XML响应长度阈值,我收到此错误:Erroroccurredwhileparsingrequestparameters.Contents:RuntimeError(entityexpansionhasgrowntoolarge):/.rvm/rubies/ruby-1.9.3-p392/lib/ruby/1.9.1/rexml/text.rb:387:in`blockinunnormalize'我意识到这在最