1、准备好待处理文本。
2、客户端submit()前,获取待处理数据的信息,然后根据参数配置,形成一个任务分配的规划。
3、客户端向Yarn请求创建MrAppMaster并提交切片等相关信息:job.split、wc.jar、job.xml。Yarn调用ResourceManager来创建MrAppMaster,而MrAppMaster则会根据切片的个数来创建MapTask。
其中切片规划: InputFormat(默认为TextInputFormat)通过getSplits 方法对输入目录中的文件进行逻辑切片,并序列化成job.split文件。默认情况下,HDFS上的一个block对应一个InputSplit,一个InputSplit对应开启一个MapTask。
1、Read阶段:由RecordReader对象(默认是LineRecordReader)进行读取,以换行符 (\n) 作为分隔符,每读取一行数据,就返回一对<Key,Value>供Mapper使用。Key表示该行的起始字节偏移量,Reduce表示这一行的内容。
2、Map阶段: 将解析出的<Key,Value>交给用户重写的map()函数处理,每一行数据会调用一次map()函数。
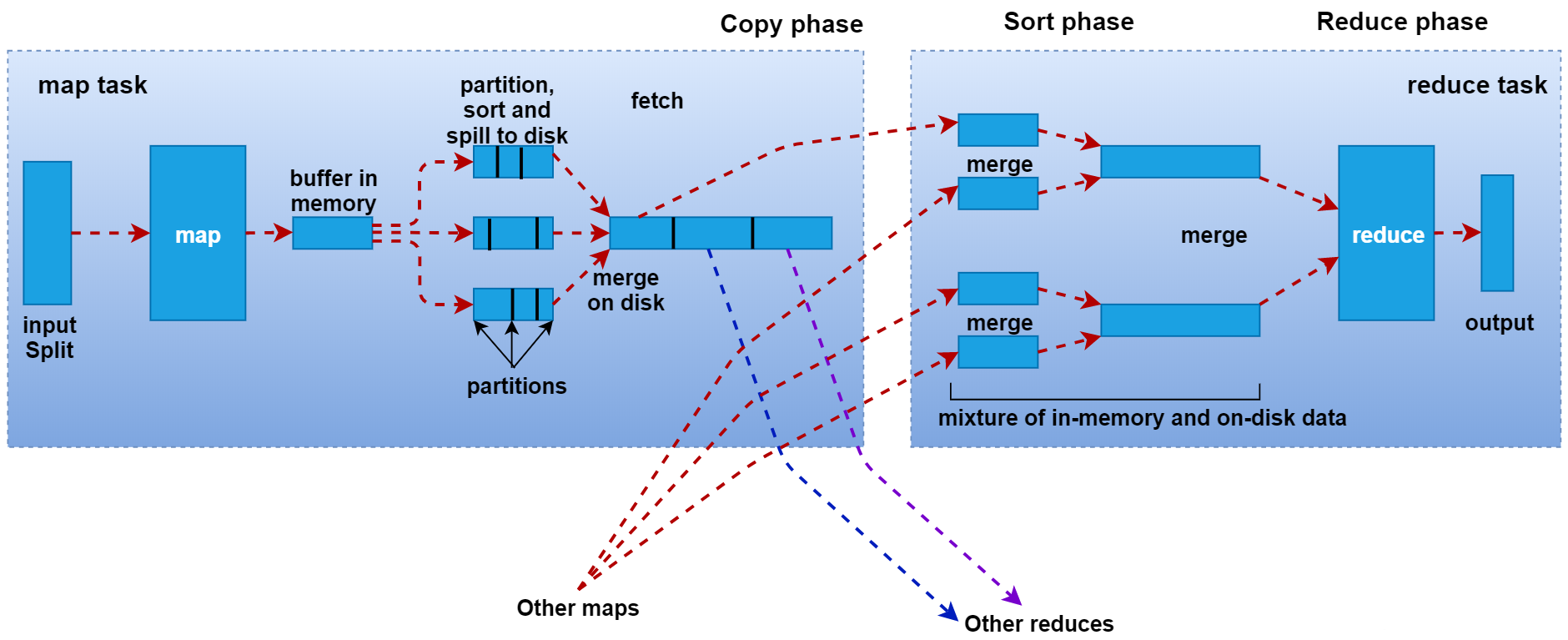
3、Collect阶段:map()函数中将数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value进行分区处理(调用Partitioner,默认为HashPartitioner),并写入一个环形内存缓冲区中。
4、Spill阶段(溢写):当环形缓冲区的数据达到溢写比例时(80%),会将数据溢写到本地磁盘上,生成一个临时文件。溢写之前,还会对数据进行排序,必要时进行合并、压缩操作。
5、Merge阶段:当Mapper输出全部文件后,产生多个临时文件。MapTask将所有临时文件以分区为单位,进行归并排序,最终得到一个大文件,等待Reduce端的拉取。
1、Copy阶段:每个ReduceTask从各个MapTask上拉取对应分区的数据。拉取数据后先存储到内存中,内存不够时,再刷写到磁盘。
2、Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
3、Sort阶段:用户编写的reduce()函数的输入数据是按Key进行聚集的一组数据。为了将相同Key的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经对自己的处理结果进行了分区内局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
4、Reduce阶段:相同Key的一组键值对调用一次Reduce方法,进行聚合处理。之后通过context.write,默认以TextOutputFormat格式经RecordWriter写入到HDFS文件中。
其中Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。

1、每个 MapTask都有一个环形内存缓冲区(默认大小为100M)用于批量收集Mapper结果,以减少磁盘IO的开销。当缓冲区的数据达到溢写比例时(默认为80%),溢写线程启动。此时MapTask仍继续将结果写入缓冲区,如果缓冲区被写满,MapTask就会阻塞直到溢出线程结束。如果数据量很小,达不到80M溢写的话,就等所有文件都读完后完成一次溢写。
2、在溢写之前,会采取快速排序算法对缓冲区内的数据按照Key进行字典顺序排序:先把数据划分到相应的分区(Partition),然后按照key进行排序。经过排序后,相同分区的数据聚集在一起,同一分区内的数据按照key有序。
3、如果设置了Combiner 函数,则在排序后,溢写前对每个分区中的数据进行局部聚合操作,以减轻 Shuffle 过程中网络传输压力。
4、开始溢写:按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。每次内存缓冲区达到溢出阈值,就会新建一个溢出文件(spill file),当Mapper输出全部文件时,会产生多个溢写文件,最终会被合并成一个已分区且已排序的输出文件。
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion在首页我有:汽车:VolvoSaabMercedesAudistatic_pages_spec.rb中的测试代码:it"shouldhavetherightselect"dovisithome_pathit{shouldhave_select('cars',:options=>['volvo','saab','mercedes','audi'])}end响应是rspec./spec/request
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
使用Ruby1.9.2运行IDE提示说需要gemruby-debug-base19x并提供安装它。但是,在尝试安装它时会显示消息Failedtoinstallgems.Followinggemswerenotinstalled:C:/ProgramFiles(x86)/JetBrains/RubyMine3.2.4/rb/gems/ruby-debug-base19x-0.11.30.pre2.gem:Errorinstallingruby-debug-base19x-0.11.30.pre2.gem:The'linecache19'nativegemrequiresinstall
我知道全局变量$!包含最新的异常对象,但我对下面的语法感到困惑。谁能帮助我理解以下语法?rescue$! 最佳答案 此构造可防止异常停止您的程序并使堆栈跟踪冒泡。它还会将该异常作为值返回,这很有用。a=get_me_datarescue$!在此行之后,a将保存请求的数据或异常。然后您可以分析该异常并采取相应措施。defget_me_dataraise'Nodataforyou'enda=get_me_datarescue$!puts"Executioncarrieson"pa#>>Executioncarrieson#>>#更现实的
我在我正在处理的一些代码中发现了这一点。它旨在解决从磁盘读取key文件的要求。在生产环境中,key文件的内容位于环境变量中。旧代码:key=File.read('path/to/key.pem')新代码:key=File.read('|echo$KEY_VARIABLE')这是如何工作的? 最佳答案 来自IOdocs:Astringstartingwith“|”indicatesasubprocess.Theremainderofthestringfollowingthe“|”isinvokedasaprocesswithappro
我今天看到了一个ruby代码片段。[1,2,3,4,5,6,7].inject(:+)=>28[1,2,3,4,5,6,7].inject(:*)=>5040这里的注入(inject)和之前看到的完全不一样,比如[1,2,3,4,5,6,7].inject{|sum,x|sum+x}请解释一下它是如何工作的? 最佳答案 没有魔法,符号(方法)只是可能的参数之一。这是来自文档:#enum.inject(initial,sym)=>obj#enum.inject(sym)=>obj#enum.inject(initial){|mem
我刚刚有一个关于RubyonRails和模型(Rails3)中的attr_accessible属性的一般性问题。有人可以解释应该在那里定义哪些模型属性吗?我记得一些关于批量分配风险的事情,虽然我在这方面不太了解......谢谢:) 最佳答案 想象一个带有一些字段的订单类:Order.new({:type=>'Corn',:quantity=>6})现在假设订单也有折扣代码,比如:price_off。您不想将:price_off标记为attr_accessible。这会阻止恶意代码制作最终会执行如下操作的帖子:Order.new({: