与树的遍历类似,图的遍历指从图的某一节点出发,按照某种搜索方式对图中的所有节点都仅访问一次。图的遍历可以解决很多搜索问题,实际应用非常广泛。图的遍历根据搜索方式的不同,分为广度优先遍历和深度优先遍历。
广度优先搜索(Breadth First Search,BFS)又被称为宽度优先搜索,是最常见的图搜索方法之一。
广度优先搜索指从某个节点(源点)出发,一次性访问所有未被访问的邻接点,再依次从这些已访问过的邻接点出发,一层一层地访问。如下图所示,广度优先遍历是按照广度优先搜索的方式对图进行遍历的。
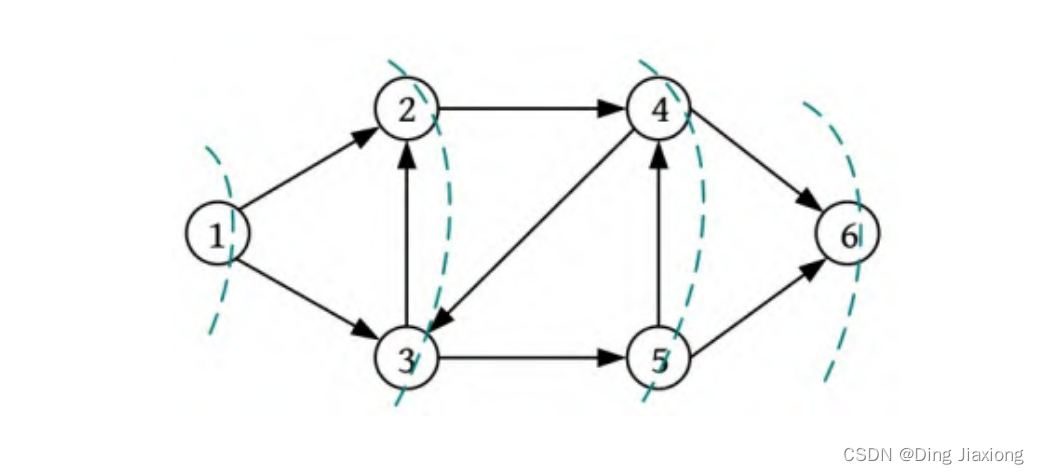
假设源点为1,从1出发访问1的邻接点2、3,从2出发访问4,从3出发访问5,从4出发访问6,访问完毕。访问路径如下图所示。
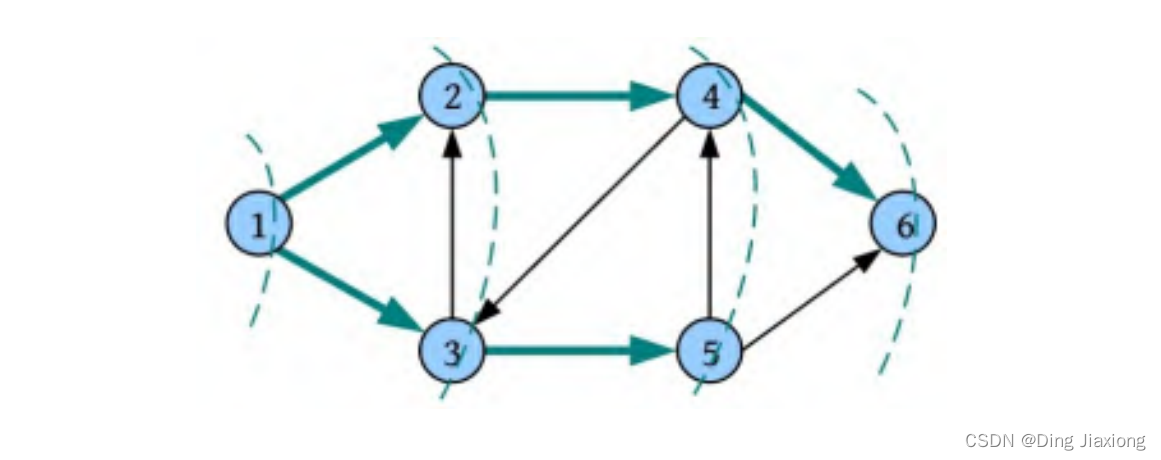
广度优先遍历的秘籍:先被访问的节点,其邻接点先被访问。
根据广度优先遍历的秘籍,先来先服务,这可以借助于队列实现。
因为对每个节点只访问一次,所以可以设置一个辅助数组visited[i]=false,表示第i 个节点未被访问;visited[ i ]=true,表示第i 个节点已被访问。
【算法步骤】
① 初始化所有节点均未被访问,并初始化一个空队列。
② 从图中的某个节点v 出发,访问v 并标记其已被访问,将v入队。
③ 如果队列非空,则继续执行,否则算法结束。
④ 将队头元素v 出队,依次访问v 的所有未被访问的邻接点,标记已被访问并入队。转向步骤3。
【完美图解】
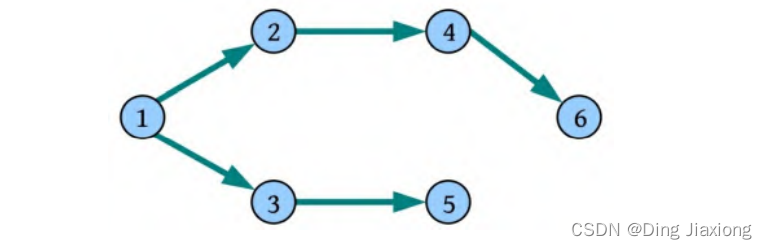
例如,一个有向图如下图所示
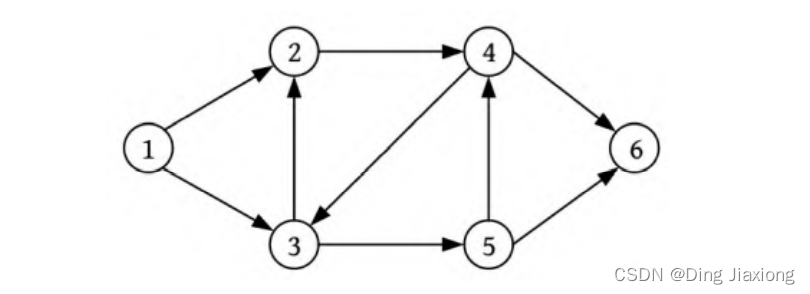
广度优先遍历:
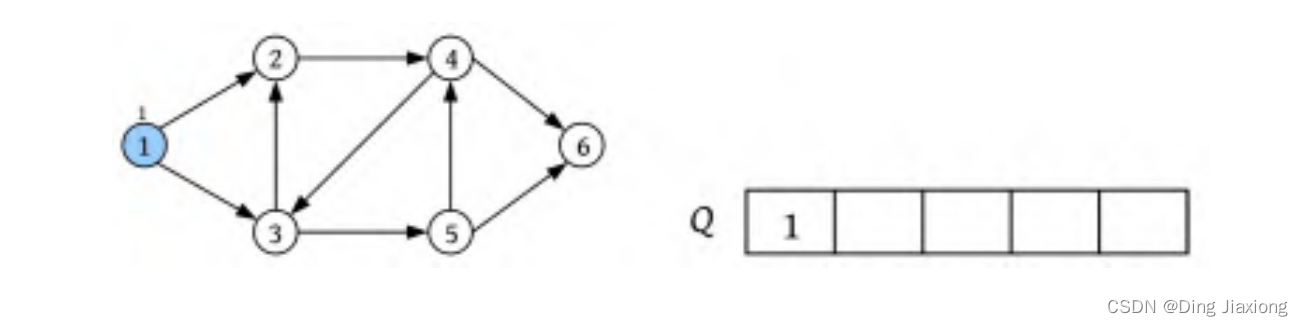
① 初始化所有节点均未被访问,visited[i ]=false,i =1,2,…,6。并初始化一个空队列Q 。
② 从节点1出发,标记其已被访问,visited[1]=true,将节点1入队。
③ 将队头元素1出队,依次访问1的所有未被访问的邻接点2、3,标记其已被访问并将其入队。
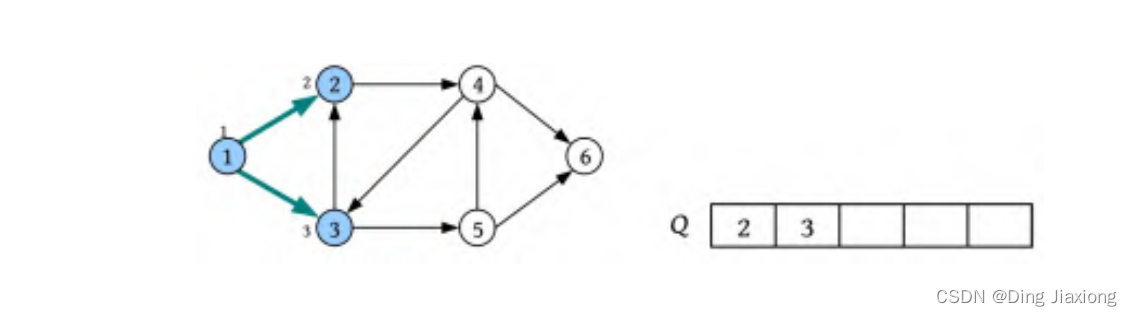
④ 将队头元素2出队,将2的未被访问的邻接点4标记为已被访问,并将其入队。
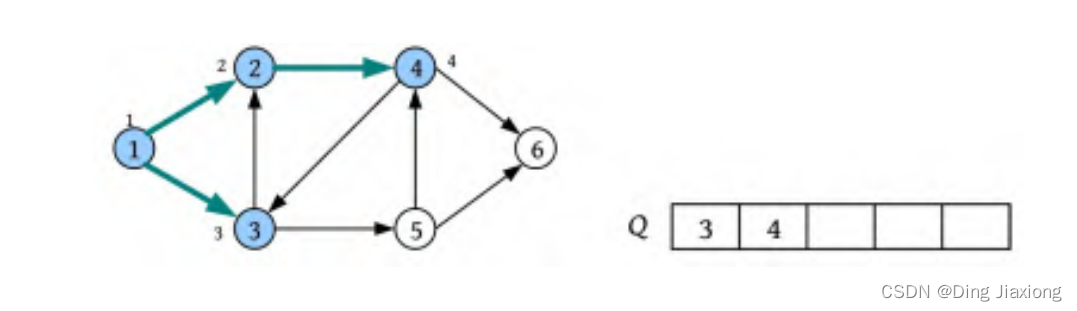
⑤ 将队头元素3出队,3的邻接点2已被访问,将未被访问的邻接点5标记为已被访问,并将其入队。
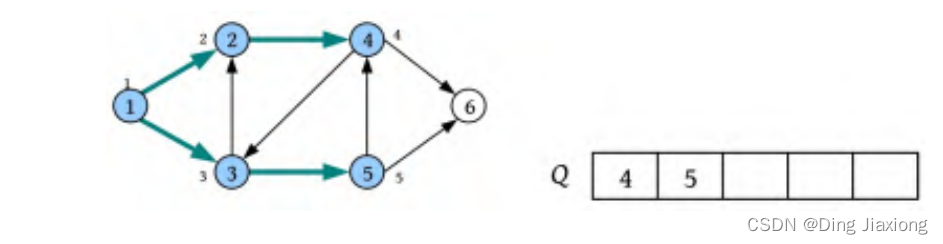
⑥ 将队头元素4出队,4的邻接点3已被访问,将未被访问的邻接点6标记为已被访问,并将其入队。
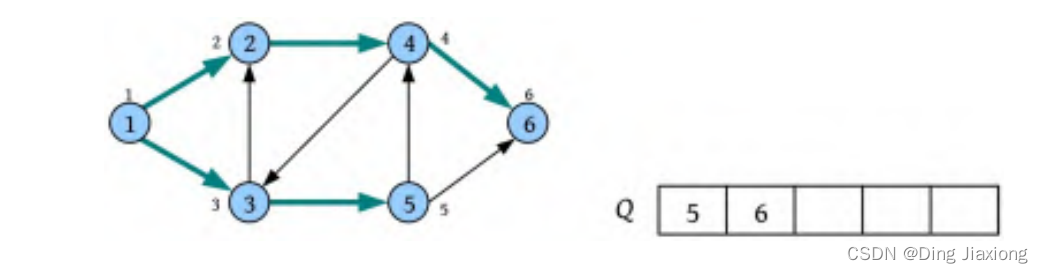
⑦ 将队头元素5出队,5的邻接点4、6均已被访问,没有未被访问的邻接点。
⑧ 将队头元素6出队,6没有邻接点。
⑨ 队列为空,算法结束。广度优先遍历序列为1 2 3 4 5 6。
广度优先遍历经过的节点及边,被称为广度优先生成树。如果广度优先遍历非连通图,则每一个连通分量都会产生一棵广度优先生成树。
【算法实现】
① 基于邻接矩阵的广度优先遍历。
void BFS_AM(AMGragh G , int v){ //基于邻接矩阵的广度优先遍历
int u , w;
queue<int>Q; //创建一个普通队列(先进先出)存放int 类型
cout << G.Vex[v] << "\t";
visited[v] = true;
Q.push(v); //将源点v 入队
while(!Q.empty()){ //如果队列不为空
u = Q.front(); //则取出队头元素并赋值给u
Q.pop(); //将队头元素出队
for(w = 0 ; w < G.vexnum ; w++){ //依次检查u 的所有邻接点
if(G.Edge[u][w] && !visited[w]){ //u、w邻接并且w 未被访问
cout << G.Vex[w] << "\t";
visited[w] = true;
Q.push(w);
}
}
}
}
② 基于邻接表的广度优先遍历
void BFS_AL(ALGragh G , int v){ //基于邻接表的广度优先遍历
int u , w;
AdjNode *p;
queue<int>Q; //创建一个普通队列(先进先出)存放int 类型
cout << G.Vex[v].data = "\t";
visited[v] = true;
Q.push(v); //将源点v 入队
while(!Q.empty()){ //如果队列不空
u = Q.front(); //则取出队头元素赋值给u
Q.pop(); //将队头元素出队
p = G.Vex[u].first;
while(p){ //依次检查 u 的所有邻接点
w = p->v; //w 为 u 的邻接点
if(!visited[w]){ //w 未被访问
cout << G.Vex[w].data << "\t";
visited[w] = true;
Q.push(w);
}
p = p->next;
}
}
}
③ 基于非连通图的广度优先遍历
void BFS_AL(ALGragh G){ //非连通图的广度优先遍历
for(int i = 0 ; i < G.vexnum; i ++){ //对非连通图需要查漏点,检查未被访问的节点
if(!visited[i]){ //i 未被访问,以i 为起点再次广度优先遍历
BFS_AL(G , i); //基于邻接表,也可以替换为基于邻接矩阵的BFS_AM(G , i)
}
}
}
【算法分析】
广度优先遍历的过程实质上是对每个节点都搜索其邻接点的过程,图的存储方式不同,其算法复杂度也不同。
① 基于邻接矩阵的广度优先遍历算法。
查找每个节点的邻接点需要O (n )时间,共n 个节点,总的时间复杂度为O (n^2 )。这里使用了一个辅助队列,每个节点只入队一次,空间复杂度为O (n )。
② 基于邻接表的广度优先遍历算法。
查找节点vi 的邻接点需要O (d (vi ))时间,d (vi )为vi 的出度,对有向图而言,所有节点的出度之和等于边数e ;对无向图而言,所有节点的度之和等于2e ,因此查找邻接点的时间复杂度为O (e ),加上初始化时间O (n ),总的时间复杂度为O (n +e )。这里使用了一个辅助队列,每个节点只入队一次,空间复杂度为O (n )。
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
所以这可能有点令人困惑,但请耐心等待。简而言之,我想遍历具有特定键值的所有属性,然后如果值不为空,则将它们插入到模板中。这是我的代码:属性:#===DefaultfileConfigurations#default['elasticsearch']['default']['ES_USER']=''default['elasticsearch']['default']['ES_GROUP']=''default['elasticsearch']['default']['ES_HEAP_SIZE']=''default['elasticsearch']['default']['MAX_OP
我们有一个字符串:“”这个正则表达式://i如何从当前字符串中获取所有匹配项? 最佳答案 "".scan(//)参见scan在ruby-docs上 关于ruby-如何遍历Ruby中所有正则表达式匹配的字符串?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/6857852/
我想从0到2循环@a:0,1,2,0,1,2。defset_aif@a==2@a=0else@a=@a+1endend也许有更好的方法? 最佳答案 (0..2).cycle(3){|x|putsx}#=>0,1,2,0,1,2,0,1,2item=[0,1,2].cycle.eachitem.next#=>0item.next#=>1item.next#=>2item.next#=>0... 关于ruby-循环遍历数组的元素,我们在StackOverflow上找到一个类似的问题:
我在MySql中进行了查询,但在Rails和mysql2gem中工作。信息如下:http://sqlfiddle.com/#!2/9adb8/6查询工作正常,没有问题,并显示以下结果:UNITV1A1N1V2A2N2V3A3N3V4A4N4V5A5N5LIFE200120000000000ROB010012000000000-为rails2.3.8安装了mysql2gemgeminstallmysql2-v0.2.6-创建Controller:classPolicyController这是日志:SQL(0.9ms)selectdistinct@sql:=concat('SELECTpb
我一直在尝试使用简单的递归方法在Ruby中为一个更大的程序的一部分实现目录遍历。但是我发现Dir.foreach不包括其中的目录。我怎样才能列出它们?代码:defwalk(start)Dir.foreach(start)do|x|ifx=="."orx==".."nextelsifFile.directory?(x)walk(x)elseputsxendendend 最佳答案 问题是每次递归,你传递给File.directory?的路径isno只是实体(文件或目录)名称;所有上下文都丢失了。所以说你进入one/two/three/检
在以下示例中,我无法理解Ruby运算符的优先级:x=1&&y=2由于&&的优先级高于=,我的理解是类似于+和*运算符:1+2*3+4解析为1+(2*3)+4它应该等于:x=(1&&y)=2但是,所有Ruby源代码(包括内部语法解析器Ripper)都将其解析为x=(1&&(y=2))为什么?编辑[08.01.2016]让我们关注一个子表达式:1&&y=2根据优先规则,我们应该尝试将其解析为:(1&&y)=2这没有意义,因为=需要特定的LHS(变量、常量、[]数组项等)。但是既然(1&&y)是一个正确的表达式,那么解析器应该如何处理呢?我试过咨询Ruby的parse.y,但它太像意大利面条
我想遍历目录中的每个jpg/jpeg文件以及每个子目录和该子目录的每个子目录等等。我希望能够浏览文件夹中的每个图像文件。有没有一种简单的方法可以做到这一点,或者递归方法是否效果最好? 最佳答案 Dir.glob("your_directory/**/*.{jpg,jpeg}") 关于ruby-遍历目录和子目录中的每个.jpg或.jpeg文件,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questi
题目描述小张买了 n 件白色的衣服,他觉得所有衣服都是一种颜色太单调,希望对这些衣服进行染色,每次染色时,他会将某种颜色的所有衣服寄去染色厂,第 i 件衣服的邮费为 ai 元,染色厂会按照小张的要求将其中一部分衣服染成同一种任意的颜色,之后将衣服寄给小张,请问小张要将 n 件衣服染成不同颜色的最小代价是多少?输入描述第一行为一个整数 n ,表示衣服的数量。第二行包括 n 个整数a1,a2...an 表示第 i 件衣服的邮费为 ai 元。(1≤n≤10^5,1≤ai≤10^9 )输出描述输出一个整数表示小张所要花费的最小代价。输入输出样例输入551321输出25 思考🤔:题意:意思是