📅大四是整个大学期间最忙碌的时光,一边要忙着准备考研,考公,考教资或者实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
本次分享的课题是
🎯opencv的人脸面部识别
现在,面部识别已成为生活中的一部分。我们在手机、平板电脑等设备中使用人脸信息进行解锁的时候,这时就要求获取我们的实时面部图像,并将其储存在数据库中以进一步表明我们的身份。
通过对输入图像进行迭代和预测可以完成这个过程。同样,实时人脸识别可与OpenCV框架python的实现配合使用。再将它们组合在一个组合级别中,以实现用于实时目的的模型。
OpenCV 有三种人脸识别的算法:
Eigenfaces 是通过 PCA(主成分分析)实现的,它识别人脸数据集的主成分,并计算出待识别图像区域相对于数据集的发散程度(0~20k),该值越小,表示差别越小,0值表示完全匹配。低于4k~5k都是相当可靠的识别。
FisherFaces 是从 PCA发展而来,采用更复杂的计算,容易得到更准确的结果。低于4k~5k都是相当可靠的识别。
LBPH 将人脸分成小单元,并将其与模型中的对应单元进行比较,对每个区域的匹配值产生一个直方图。它允许待检测人脸区域可以和数据集中图像的形状、大小不同,更方便灵活。参考值低于50则算是好的识别,高于80则认为比较差。
当然,除了这三种预定义的算法外,我们可以自己写深度学习算法或者其他机器学习的分类算法来进行人脸识别,这里不再详述。
不管使用哪种算法都需要有训练集。从视频或者动图创建训练集的效率比较高。我从网上下载了一些明星的动图,然后分解,检测人脸区域,全部存为200X200的灰度图,存入对应的文件夹中,创建训练集。
from PIL import Imageimport osimport cv2def gifSplit2Array(gif_path):import numpy as npimg = Image.open(gif_path)for i in range(img.n_frames):img.seek(i)new = Image.new("RGBA", img.size)new.paste(img)arr = np.array(new).astype(np.uint8) # image: img (PIL Image):yield arr[:,:,2::-1] # 逆序(RGB 转BGR), 舍弃alpha通道, 输出数组供openCV使用def face_generate(img):gray =cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)front_face_cascade = cv2.CascadeClassifier(r'E:\Python36\MyPythonFiles\my OpenCV\face_detection\cascades/haarcascade_frontalface_default.xml')#检测正脸faces0 = front_face_cascade.detectMultiScale(gray, 1.02, 5)#eye_cascade = cv2.CascadeClassifier('./cascades/haarcascade_eye.xml')#检测眼睛eye_cascade = cv2.CascadeClassifier(r'E:\Python36\MyPythonFiles\my OpenCV\face_detection\cascades/haarcascade_eye_tree_eyeglasses.xml')#检测眼睛for (x, y, w, h) in faces0:face_area = gray[y: y+h, x: x+w] # (疑似)人脸区域quasi_eyes = eye_cascade.detectMultiScale(face_area, 1.03, 5, 0)#在人脸区域检测眼睛if len(quasi_eyes) ==0: continuequasi_eyes = tuple(filter(lambda x : x[2]/w>0.18 and x[1]<0.5*h, quasi_eyes)) # ex,ey,ew,eh; ew/w>0.18 #尺寸过滤 ,且眼睛在脸的上半部if len(quasi_eyes) <1 : continueyield cv2.resize(face_area, (200,200))i = 0for gif_path in ("Yangme5.gif","Yangme6.gif","Shishi.gif","Shishi2.gif","Shishi3.gif","Shishi3.gif" ,"Yangzi.gif","Yangzi2.gif","Yangzi3.gif","Zhenshuang.gif","ZDY.gif", "ZDY2.gif"):print(gif_path)for img in gifSplit2Array(gif_path):for face in face_generate(img):cv2.imwrite("./dataset/%s.pgm" % (i), face)print(i)i += 1
我们可以剔除掉其中一些效果不好的图片。
接着我们加载数据集,训练模型:
def load_dataset(datasetPath):names = []X = []y = []ID = 0for name in os.listdir(datasetPath):subpath = os.path.join(datasetPath, name)if os.path.isdir(subpath):names.append(name)for file in os.listdir(subpath):im = cv2.imread(os.path.join(subpath,file), cv2.IMREAD_GRAYSCALE)X.append(np.asarray(im, dtype = np.uint8))y.append(ID)ID += 1X = np.asarray(X)y = np.asarray(y, dtype = np.int32)return X, y, namesdatasetPath =".\dataset"X, y , names = load_dataset(datasetPath)#报错找不到face模块是因为只安装了主模块#pip uninstall opencv-python, pip install opencv0-contrib-python#创建人脸识别模型(三种识别模式)#model = cv2.face.EigenFaceRecognizer_create() #createEigenFaceRecognizer()函数已被舍弃#model = cv2.face.FisherFaceRecognizer_create()model = cv2.face.LBPHFaceRecognizer_create() #model.train(X, y)
最后我们将待预测的图像中的人脸区域与训练集中的图像进行比对预测:
def recognize(img):global model, namesgray =cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)front_face_cascade = cv2.CascadeClassifier(r'E:\Python36\MyPythonFiles\my OpenCV\face_detection\cascades/haarcascade_frontalface_default.xml')#检测正脸faces0 = front_face_cascade.detectMultiScale(gray, 1.025, 5)eye_cascade = cv2.CascadeClassifier(r'E:\Python36\MyPythonFiles\my OpenCV\face_detection\cascades/haarcascade_eye_tree_eyeglasses.xml')#检测眼睛for (x, y, w, h) in faces0:#print(x,y,w,h)face_area = gray[y: y+h, x: x+w] #疑似人脸区域quasi_eyes = eye_cascade.detectMultiScale(face_area, 1.03, 5, 0)#在人脸区域检测眼睛if len(quasi_eyes) ==0: continuequasi_eyes = tuple(filter(lambda x : x[2]/w>0.15, quasi_eyes)) # ex,ey,ew,eh; ew/w>0.18 #尺寸过滤#print(quasi_eyes)if len(quasi_eyes) <1 : continue#if len(quasi_eyes) <2 : continuecv2.rectangle(img, (x,y), (x+w,y+h), (0,0,255), 2) #画红色矩形框标记正脸roi = cv2.resize(face_area, (200,200), interpolation = cv2.INTER_LINEAR) #尺寸缩放到与训练集中图片的尺寸一致cv2.imwrite("e.pgm", roi) #若识别错误,可以添加到正确的数据集,提高后续的识别率ID_predict, confidence = model.predict(roi)#预测!!!name = names[ID_predict]print("name:%s, confidence:%.2f"%(name, confidence))text = name if confidence <70 else "unknow" #10000 for EigenFaces #70 for LBPHcv2.putText(img, text , (x, y-20), cv2.FONT_HERSHEY_SIMPLEX,1,(0,255,0),2)#绘制绿色文字return imgimgPath = "AA.jpg"img = cv2.imread(imgPath)cv2.imshow(imgPath, recognize(img))cv2.waitKey()cv2.destroyAllWindows()
下面是一些预测结果的展示:
单人照:


伪双人照:

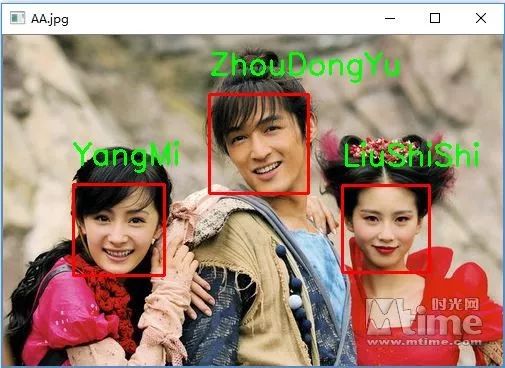
三人照(杀马特的诗诗......):
胡歌不在数据集中,所以肯定会识别错误,我们需舍弃置信度过差的结果:
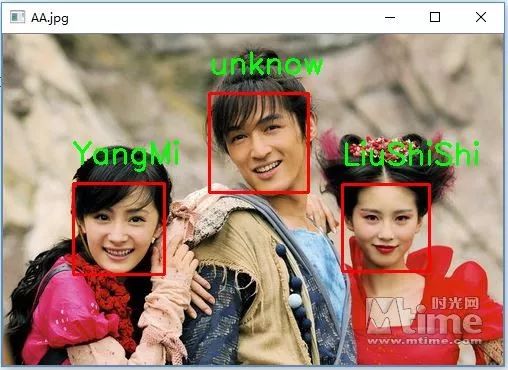
当然,真实的识别效果没这么理想,识别的准确度主要取决于我们的数据集的优劣。
🚀海浪学长的作品示例:
大数据算法项目
机器视觉算法项目


微信小程序项目
Unity3D游戏项目

🏆为帮助大家节省时间,如果对开题选题,或者相关的技术有不理解,不知道毕设如何下手,都可以随时来问学长,我将根据你的具体情况,提供帮助。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我将应用程序升级到Rails4,一切正常。我可以登录并转到我的编辑页面。也更新了观点。使用标准View时,用户会更新。但是当我添加例如字段:name时,它不会在表单中更新。使用devise3.1.1和gem'protected_attributes'我需要在设备或数据库上运行某种更新命令吗?我也搜索过这个地方,找到了许多不同的解决方案,但没有一个会更新我的用户字段。我没有添加任何自定义字段。 最佳答案 如果您想允许额外的参数,您可以在ApplicationController中使用beforefilter,因为Rails4将参数
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
Heroku支持人员告诉我,为了在我的Web应用程序中使用自定义字体(未安装在系统中,您可以在bash控制台中使用fc-list查看已安装的字体)我必须部署一个包含所有字体的.fonts文件夹里面的字体。问题是我不知道该怎么做。我的意思是,我不知道文件名是否必须遵循heroku的任何特殊模式,或者我必须在我的代码中做一些事情来考虑这种字体,或者如果我将它包含在文件夹中它是自动的......事实是,我尝试以不同的方式更改字体的文件名,但根本没有使用该字体。为了提供更多详细信息,我们使用字体的过程是将PDF转换为图像,更具体地说,使用rghostgem。并且最终图像根本不使用自定义字体。在
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
在我让另一个人重做我的前端UI之前,我的Rails应用程序运行平稳。我已经尝试解决此错误3天了。这是错误:Nosuchfileordirectory-identifyExtractedsource(aroundline#59):575859606162@post=Post.find(params[:id])authorize@postif@post.update_attributes(post_params)flash[:notice]="Postwasupdated."redirect_to[@topic,@post]else{"utf8"=>"✓","_method"=>"patc