Apache DolphinScheduler是一个分布式、易扩展的可视化DAG工作流任务调度平台。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
DolphinScheduler的主要角色如下:
MasterServer 采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交、任务监控,并同时监听其它MasterServer和WorkerServer的健康状态。WorkerServer 也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。Alert服务,提供告警相关服务。API接口层,主要负责处理前端UI层的请求。UI,系统的前端页面,提供系统的各种可视化操作界面。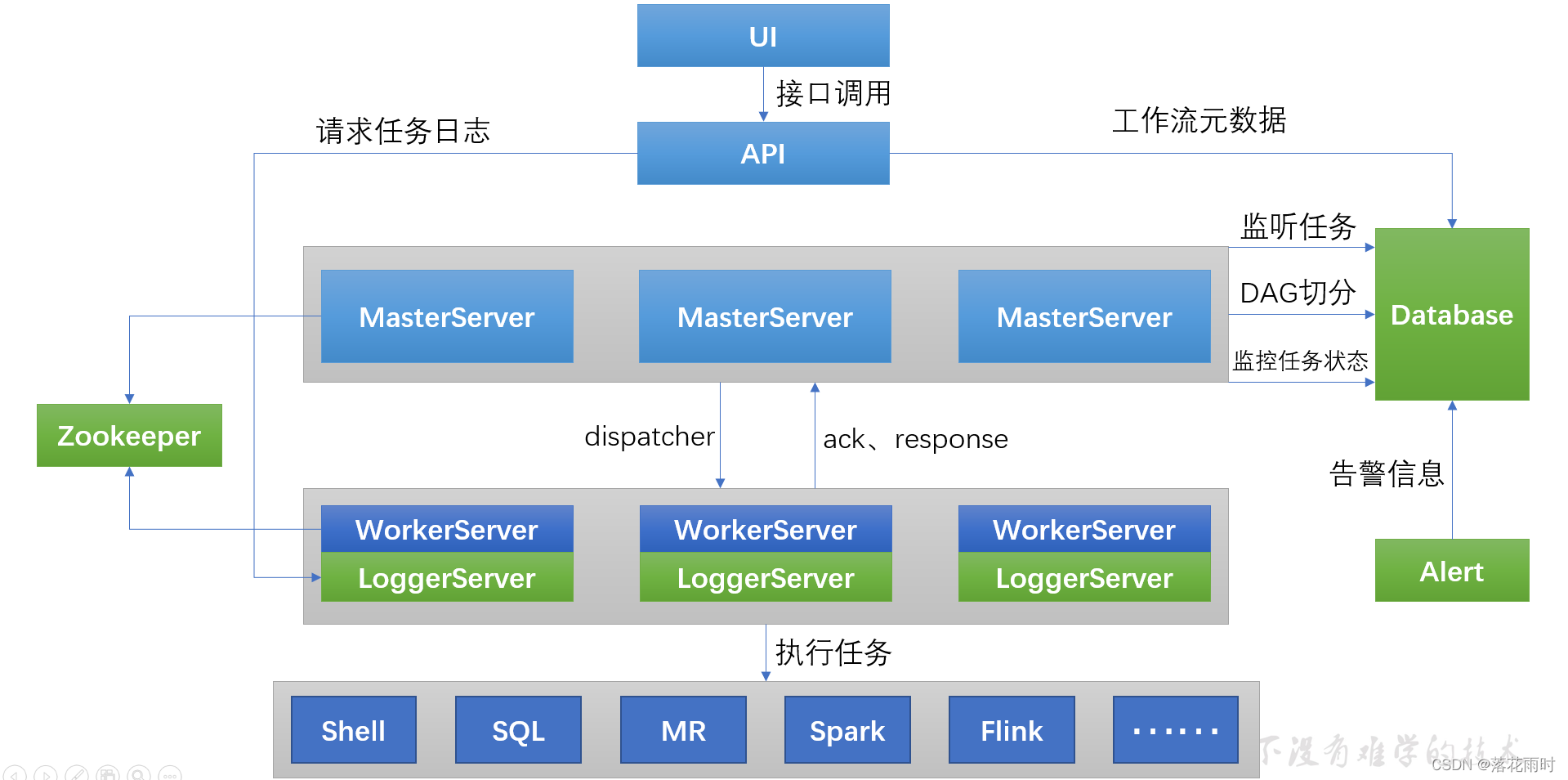
| 操作系统 | 版本 |
|---|---|
| Red Hat Enterprise Linux | 7.0 及以上 |
| CentOS | 7.0 及以上 |
| Oracle Enterprise Linux | 7.0 及以上 |
| Ubuntu LTS 16.04 | 及以上 |
| CPU | 内存 | 网络 |
|---|---|---|
| 4核+ | 8 GB+ | 千兆网卡 |
DolphinScheduler支持多种部署模式,包括单机模式(Standalone)、伪集群模式(Pseudo-Cluster)、集群模式(Cluster)等。
单机模式(standalone)模式下,所有服务均集中于一个StandaloneServer进程中,并且其中内置了注册中心Zookeeper和数据库H2。只需配置JDK环境,就可一键启动DolphinScheduler,快速体验其功能。
伪集群模式(Pseudo-Cluster)是在单台机器部署 DolphinScheduler 各项服务,该模式下master、worker、api server、logger server等服务都只在同一台机器上。Zookeeper和数据库需单独安装并进行相应配置。
集群模式(Cluster)与伪集群模式的区别就是在多台机器部署 DolphinScheduler各项服务,并且可以配置多个Master及多个Worker。
集群模式下,可配置多个Master及多个Worker。通常可配置2~3个Master,若干个Worker。由于集群资源有限,此处配置一个Master,三个Worker,集群规划如下。
| 节点 | 服务 |
|---|---|
| hadoop102 | master、worker |
| hadoop103 | worker |
| hadoop104 | worker |
1)三台节点均需部署JDK(1.8+),并配置相关环境变量。
2)需部署数据库,支持MySQL(5.7+)或者PostgreSQL(8.2.15+)。
3)需部署Zookeeper(3.4.6+)。
4)三台节点均需安装进程管理工具包psmisc。
[atguigu@hadoop102 ~]$ sudo yum install -y psmisc
[atguigu@hadoop103 ~]$ sudo yum install -y psmisc
[atguigu@hadoop104 ~]$ sudo yum install -y psmisc
1)上传DolphinScheduler安装包到hadoop102节点的/opt/software目录
2)解压安装包到当前目录
[atguigu@hadoop102 software]$ tar -zxvf apache-dolphinscheduler-1.3.9-bin.tar.gz
注:解压目录并非最终的安装目录
DolphinScheduler 元数据存储在关系型数据库中,故需创建相应的数据库和用户。
1)创建数据库
mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
2)创建用户
mysql> CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY 'dolphinscheduler';
注:
若出现以下错误信息,表明新建用户的密码过于简单。
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
可提高密码复杂度或者执行以下命令降低MySQL密码强度级别。mysql> set global validate_password_length=4; mysql> set global validate_password_policy=0;
3)赋予用户相应权限
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%';
mysql> flush privileges;
4)修改数据源配置文件
进入DolphinScheduler解压目录
cd /opt/software/apache-dolphinscheduler-1.3.9-bin/
修改conf目录下的datasource.properties文件
vim conf/datasource.properties
修改内容如下
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://hadoop102:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8
spring.datasource.username=dolphinscheduler
spring.datasource.password=dolphinscheduler
5)拷贝MySQL驱动到DolphinScheduler的解压目录下的lib中
cp /opt/software/mysql-connector-java-5.1.27-bin.jar lib/
6)执行数据库初始化脚本
数据库初始化脚本位于DolphinScheduler解压目录下的script目录中,即/opt/software/ds/apache-dolphinscheduler-1.3.9-bin/script/。
script/create-dolphinscheduler.sh
修改解压目录下的conf/config目录下的install_config.conf文件
vim conf/config/install_config.conf
修改内容如下
# postgresql or mysql
dbtype="mysql"
# db config
# db address and port
dbhost="hadoop102:3306"
# db username
username="dolphinscheduler"
# database name
dbname="dolphinscheduler"
# db passwprd
# NOTICE: if there are special characters, please use the \ to escape, for example, `[` escape to `\[`
password="dolphinscheduler"
# zk cluster
zkQuorum="hadoop102:2181,hadoop103:2181,hadoop104:2181"
# Note: the target installation path for dolphinscheduler, please not config as the same as the current path (pwd)
installPath="/opt/module/dolphinscheduler"
# deployment user
# Note: the deployment user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled, the root directory needs to be created by itself
deployUser="atguigu"
# resource storage type: HDFS, S3, NONE
resourceStorageType="HDFS"
# resource store on HDFS/S3 path, resource file will store to this hadoop hdfs path, self configuration, please make sure the directory exists on hdfs and have read write permissions. "/dolphinscheduler" is recommended
resourceUploadPath="/dolphinscheduler"
# if resourceStorageType is HDFS,defaultFS write namenode address,HA you need to put core-site.xml and hdfs-site.xml in the conf directory.
# if S3,write S3 address,HA,for example :s3a://dolphinscheduler,
# Note,s3 be sure to create the root directory /dolphinscheduler
defaultFS="hdfs://hadoop102:8020"
# resourcemanager port, the default value is 8088 if not specified
resourceManagerHttpAddressPort="8088"
# if resourcemanager HA is enabled, please set the HA IPs; if resourcemanager is single, keep this value empty
yarnHaIps=
# if resourcemanager HA is enabled or not use resourcemanager, please keep the default value; If resourcemanager is single, you only need to replace ds1 to actual resourcemanager hostname
singleYarnIp="hadoop103"
# who have permissions to create directory under HDFS/S3 root path
# Note: if kerberos is enabled, please config hdfsRootUser=
hdfsRootUser="atguigu"
# api server port
apiServerPort="12345"
# install hosts
# Note: install the scheduled hostname list. If it is pseudo-distributed, just write a pseudo-distributed hostname
ips="hadoop102,hadoop103,hadoop104"
# ssh port, default 22
# Note: if ssh port is not default, modify here
sshPort="22"
# run master machine
# Note: list of hosts hostname for deploying master
masters="hadoop102"
# run worker machine
# note: need to write the worker group name of each worker, the default value is "default"
workers="hadoop102:default,hadoop103:default,hadoop104:default"
# run alert machine
# note: list of machine hostnames for deploying alert server
alertServer="hadoop102"
# run api machine
# note: list of machine hostnames for deploying api server
apiServers="hadoop102"
1)启动Zookeeper集群
zk.sh start
2)一键部署并启动DolphinScheduler
./install.sh
3)查看DolphinScheduler进程
--------- hadoop102 ----------
29139 ApiApplicationServer
28963 WorkerServer
3332 QuorumPeerMain
2100 DataNode
28902 MasterServer
29081 AlertServer
1978 NameNode
29018 LoggerServer
2493 NodeManager
29551 Jps
--------- hadoop103 ----------
29568 Jps
29315 WorkerServer
2149 NodeManager
1977 ResourceManager
2969 QuorumPeerMain
29372 LoggerServer
1903 DataNode
--------- hadoop104 ----------
1905 SecondaryNameNode
27074 WorkerServer
2050 NodeManager
2630 QuorumPeerMain
1817 DataNode
27354 Jps
27133 LoggerServer
4)访问DolphinScheduler UI
DolphinScheduler UI地址为http://hadoop102:12345/dolphinscheduler
初始用户的用户名为:admin,密码为dolphinscheduler123
DolphinScheduler的启停脚本均位于其安装目录的bin目录下。
1)一键启停所有服务
./bin/start-all.sh
./bin/stop-all.sh
注意同Hadoop的启停脚本进行区分。
2)启停 Master
./bin/dolphinscheduler-daemon.sh start master-server
./bin/dolphinscheduler-daemon.sh stop master-server
3)启停 Worker
./bin/dolphinscheduler-daemon.sh start worker-server
./bin/dolphinscheduler-daemon.sh stop worker-server
4)启停 Api
./bin/dolphinscheduler-daemon.sh start api-server
./bin/dolphinscheduler-daemon.sh stop api-server
5)启停 Logger
./bin/dolphinscheduler-daemon.sh start logger-server
./bin/dolphinscheduler-daemon.sh stop logger-server
6)启停 Alert
./bin/dolphinscheduler-daemon.sh start alert-server
./bin/dolphinscheduler-daemon.sh stop alert-server
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(
我刚刚为fedora安装了emacs。我想用emacs编写ruby。为ruby提供代码提示、代码完成类型功能所需的工具、扩展是什么? 最佳答案 ruby-mode已经包含在Emacs23之后的版本中。不过,它也可以通过ELPA获得。您可能感兴趣的其他一些事情是集成RVM、feature-mode(Cucumber)、rspec-mode、ruby-electric、inf-ruby、rinari(用于Rails)等。这是我当前用于Ruby开发的Emacs配置:https://github.com/citizen428/emacs
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub