目录
创建maven web项目有两种方式,一种是使用骨架方式,一种是不使用骨架的方式
1.打开idea,按照步骤创建一个新的项目
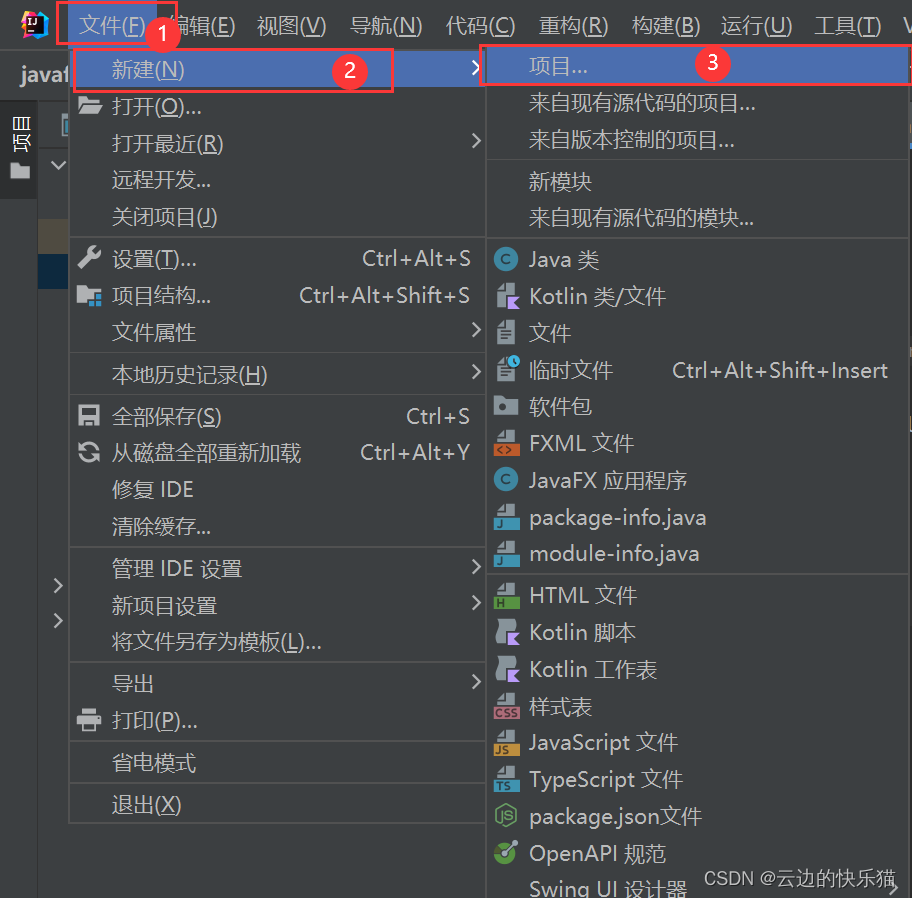
2.点击Maven Archetype(骨架),自定义项目名,选择这个web骨架,点击创建
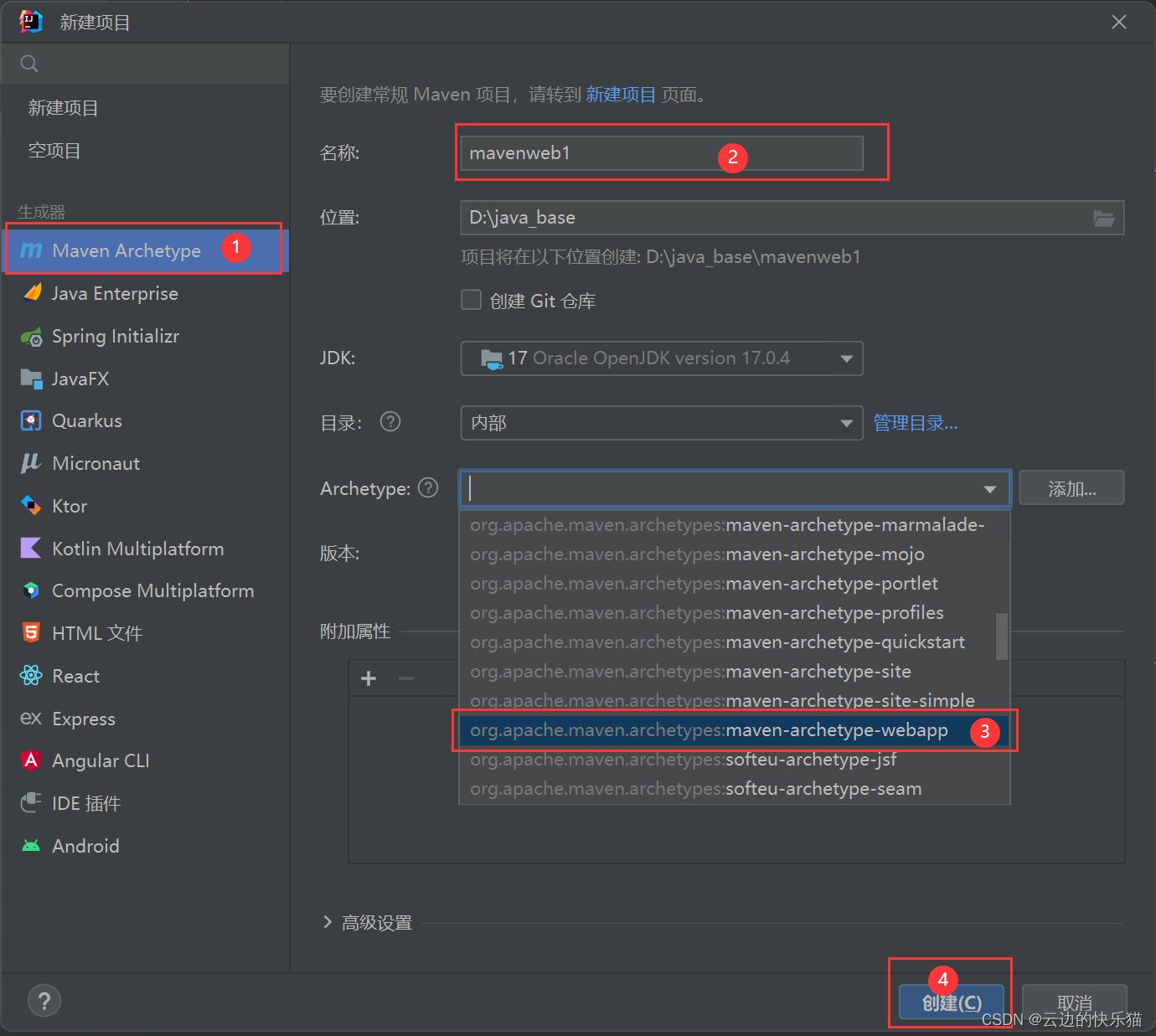
3.构建中
PS:这个一般时间比较长(因为有墙,maven的中央仓库在国外),会卡在[INFO] Generating project in Batch mode这里比较久,可以选择
1.关闭重新创建
2.耐心等待
3.或者去(本地磁盘中安装maven的位置--conf包--settings.xml中配置阿里云仓库--这个在我的其他文章中有教学)
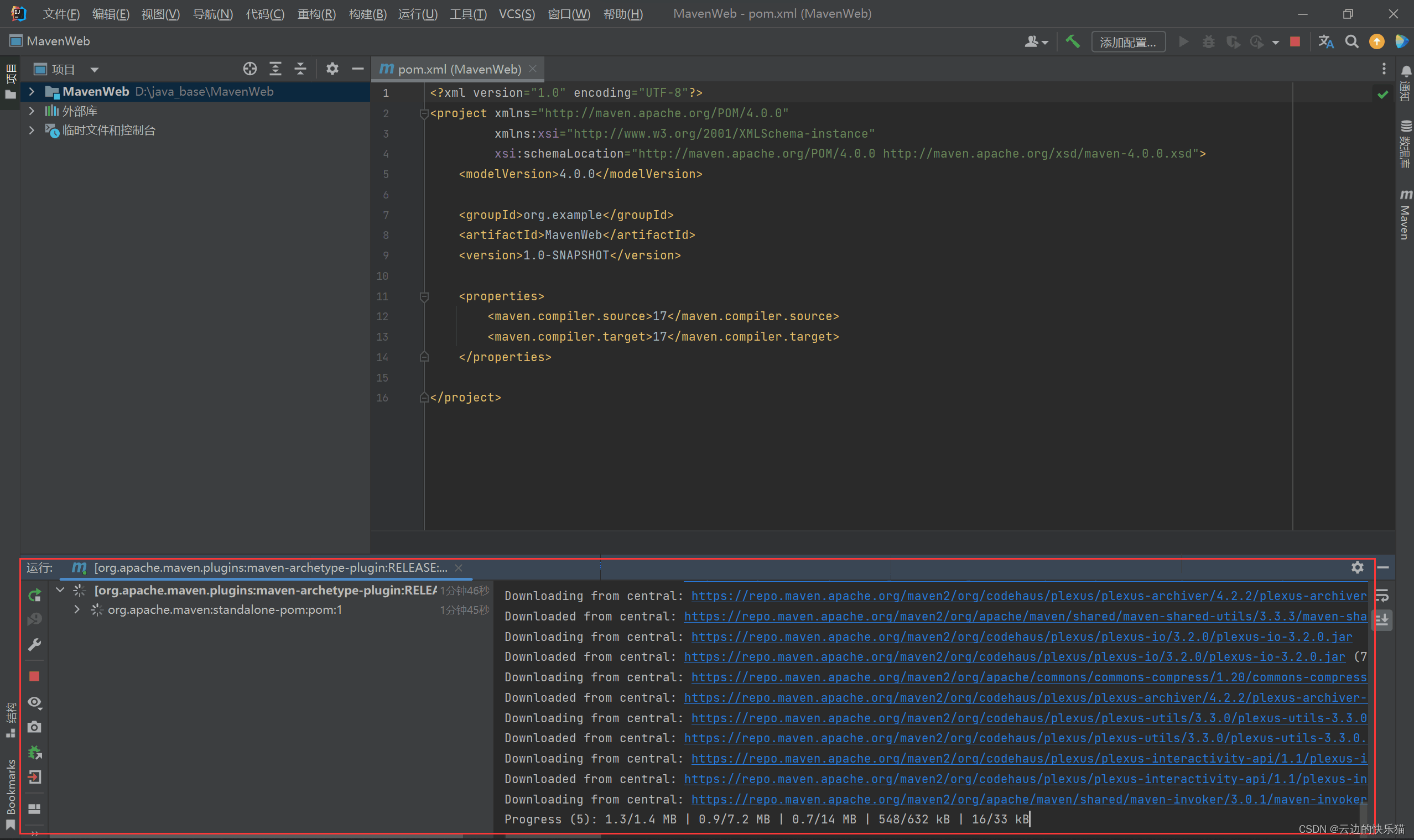
4.这样就是构建成功:
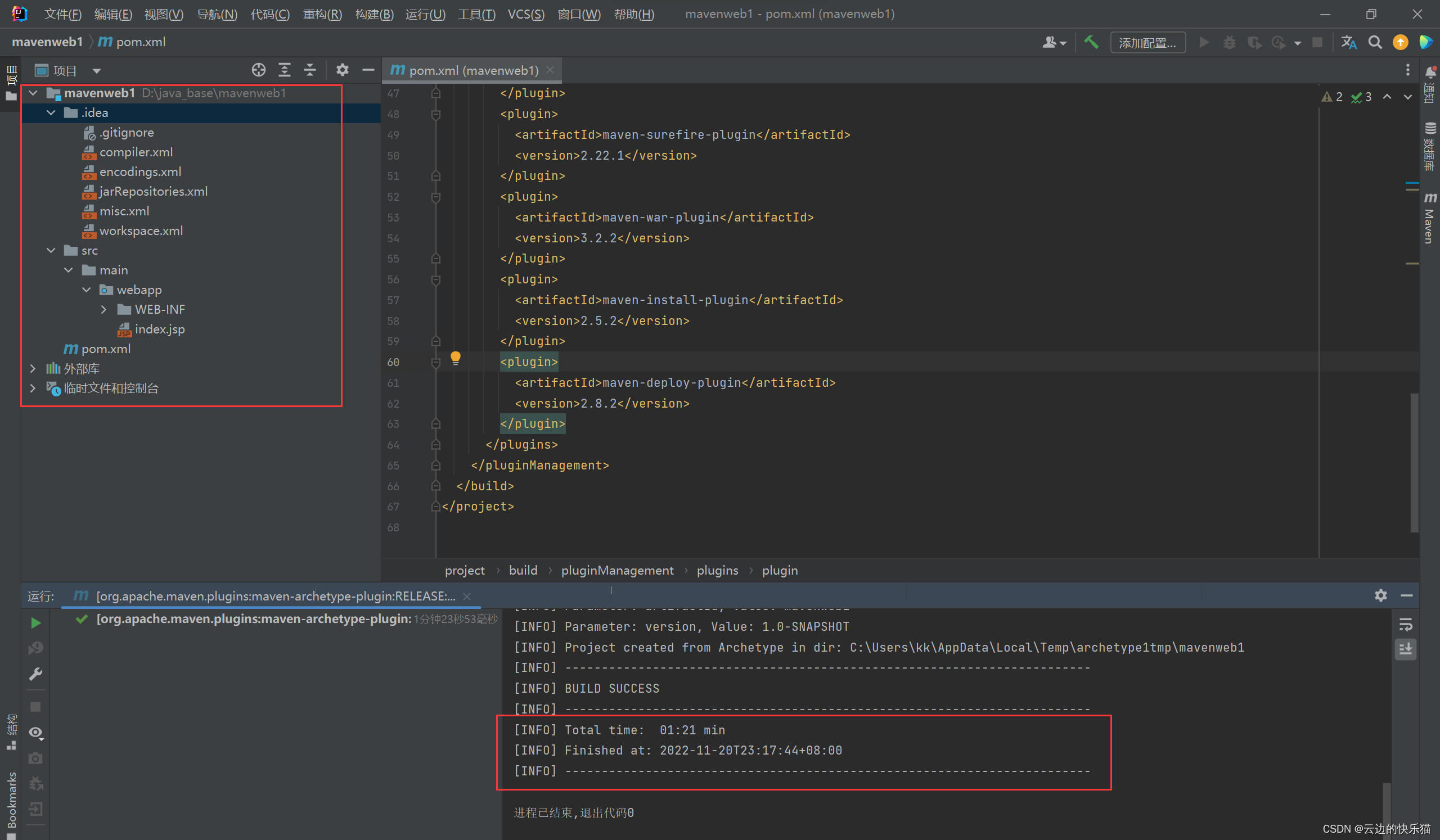
5.删除pom.xml中多余的插件,从war往下删到剩一个</project>
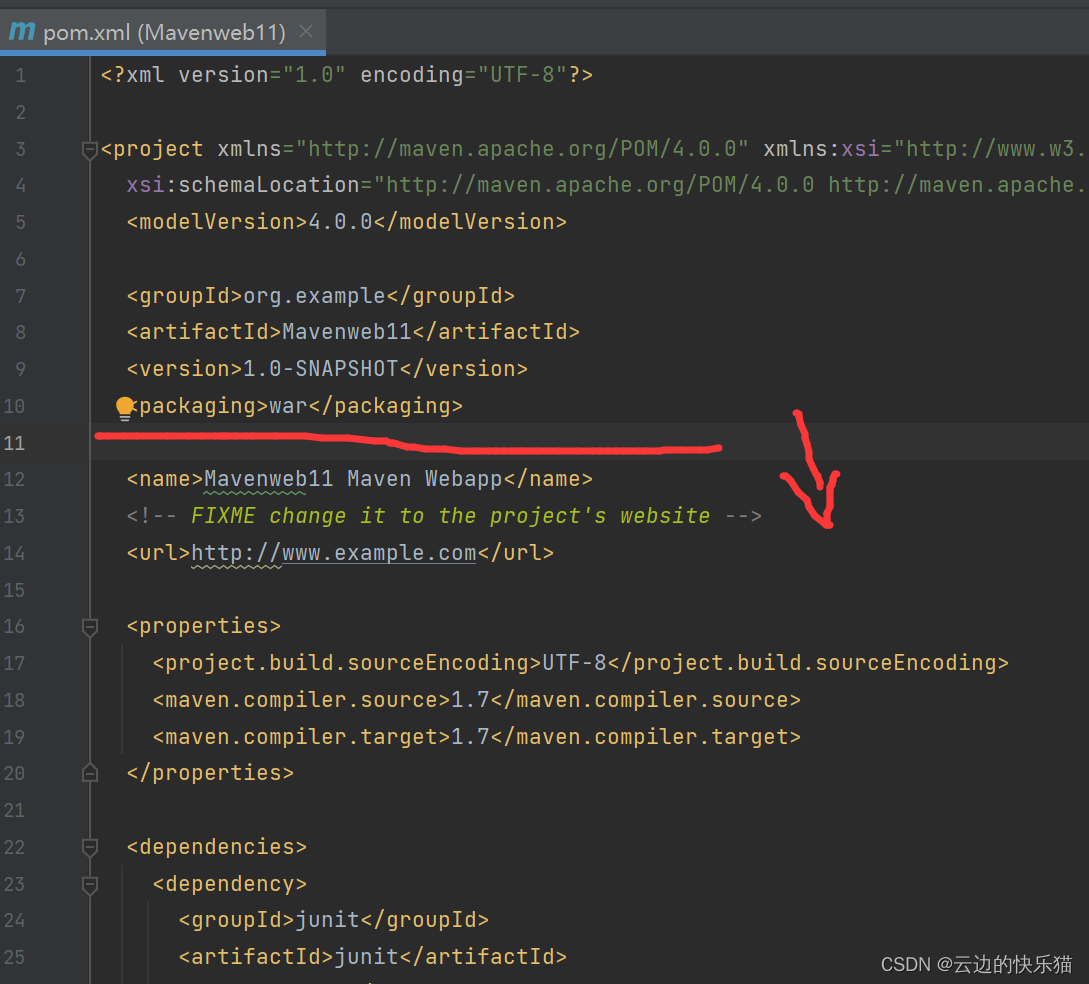
成果:
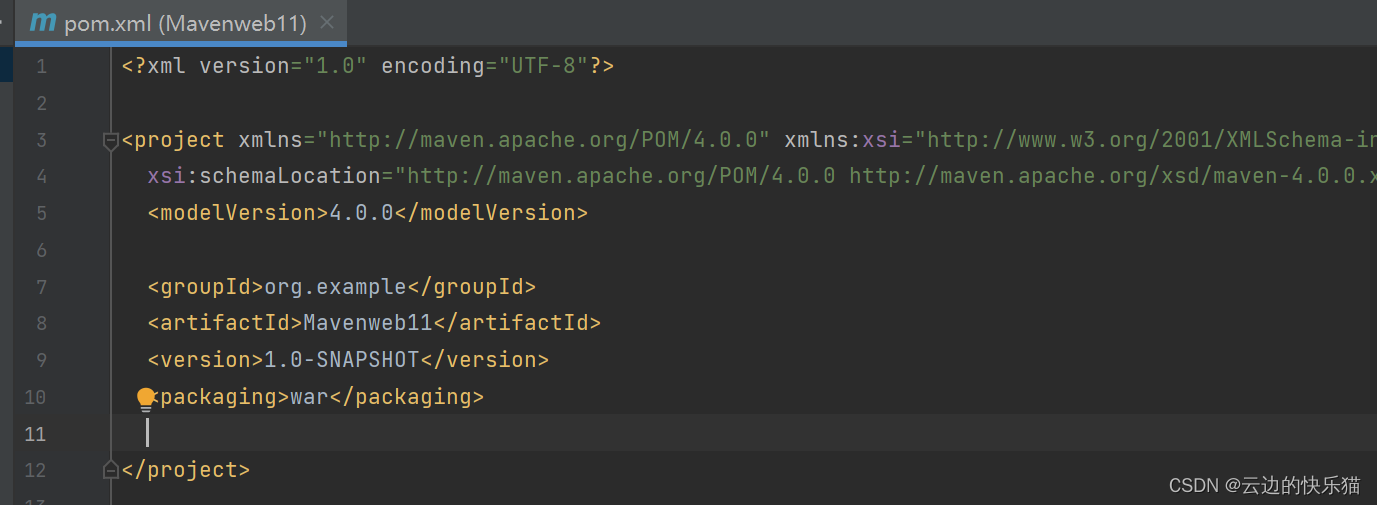
6.右键main-->新建-->目录
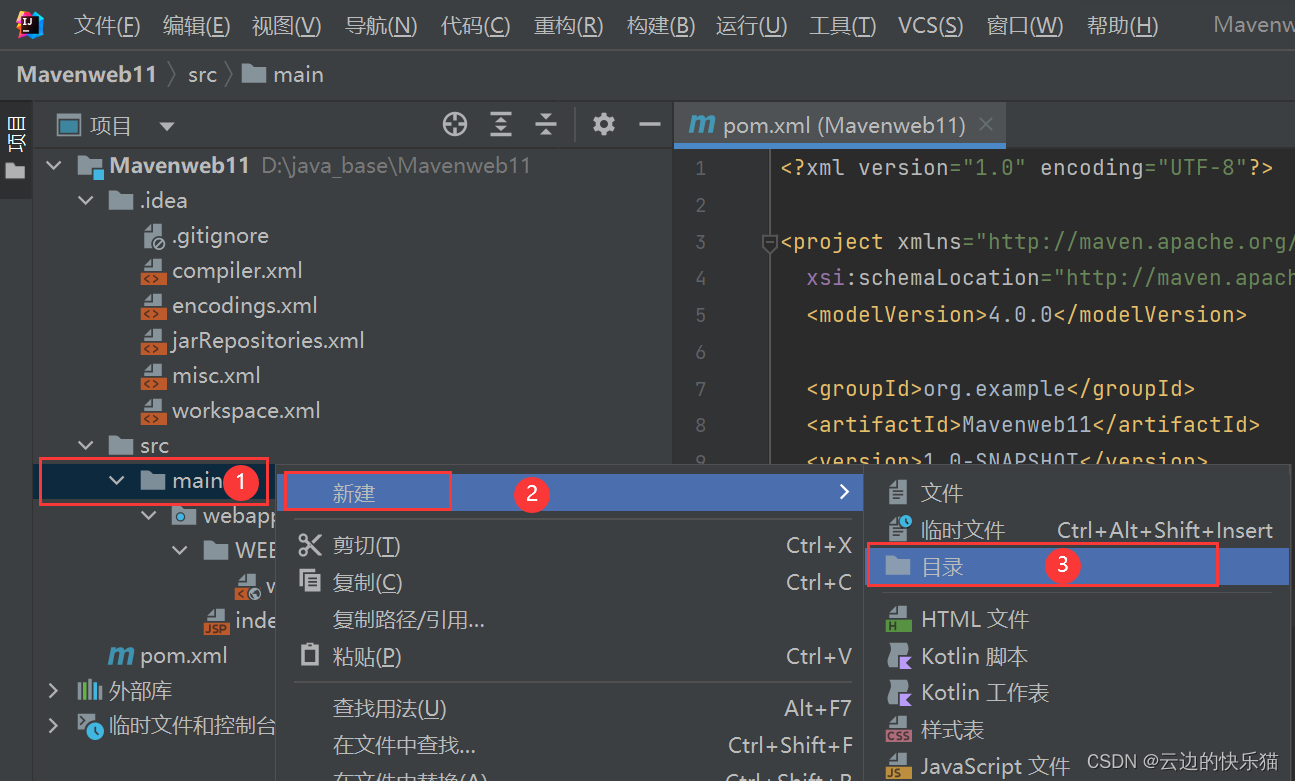
7.根据提示补齐这两个目录(分两次添加进来就好了)
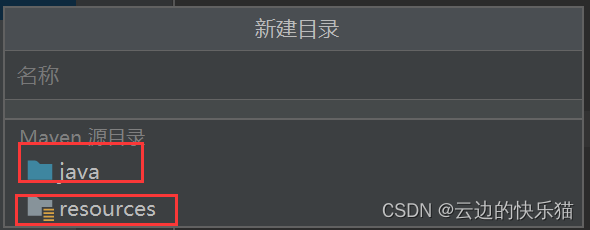
成果:这样就补齐成功了
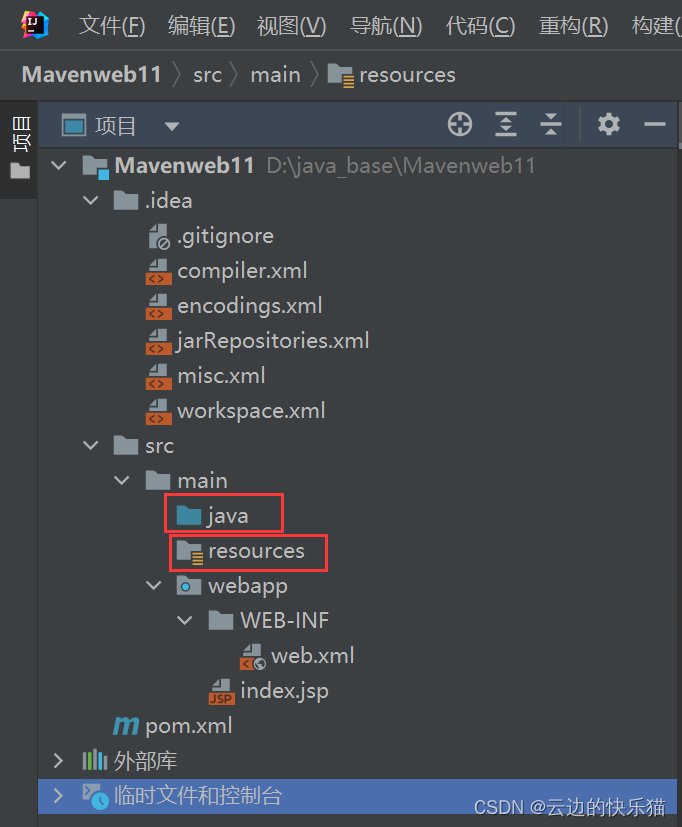
8.添加补齐测试包。右键点击src-->新建-->目录
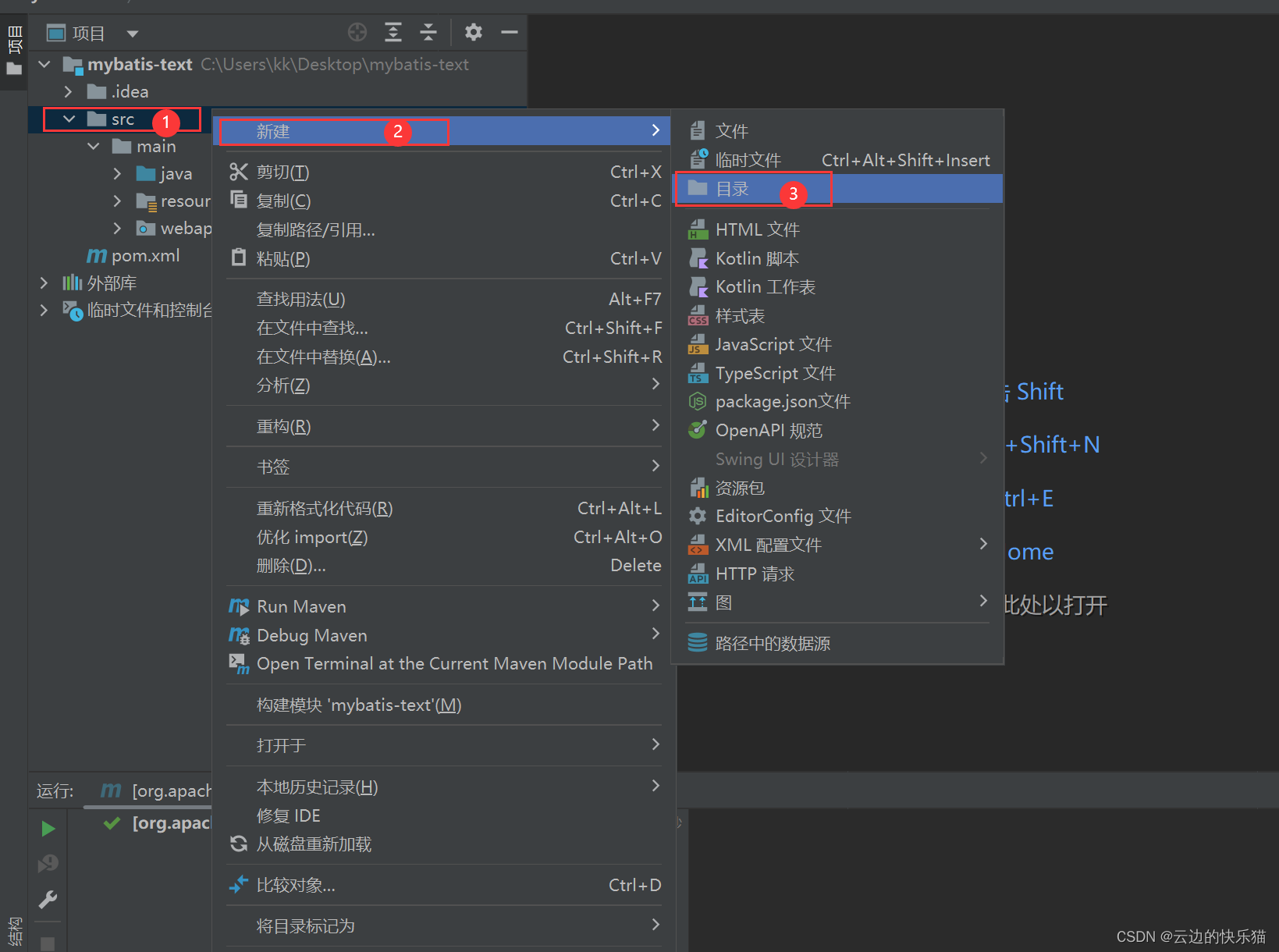
9.根据提示选择回车键补齐这两个目录就好了
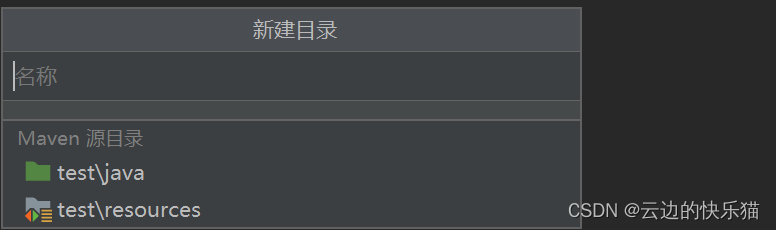
最终成果展示
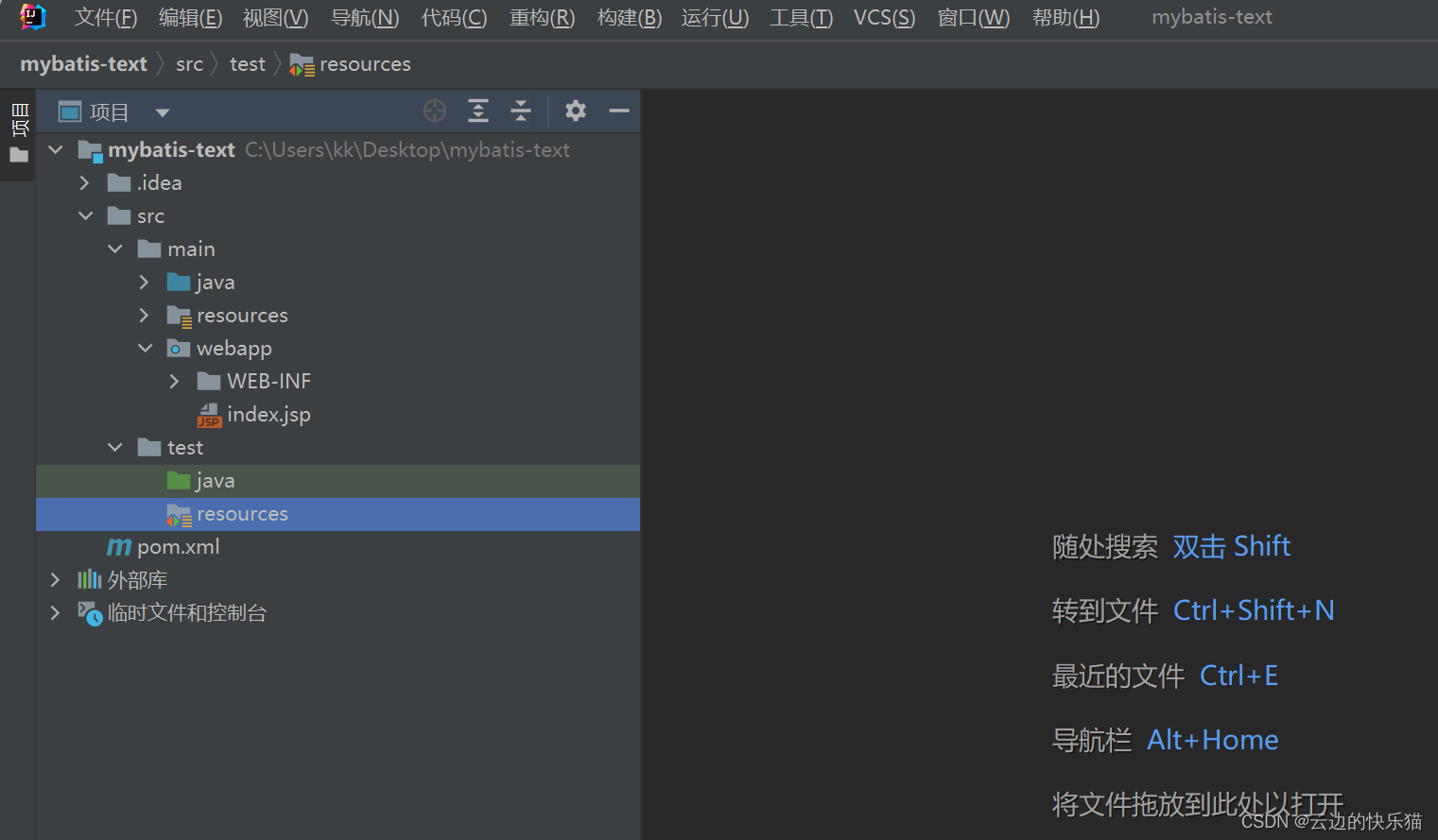
这样骨架的maven web项目就建立完成了
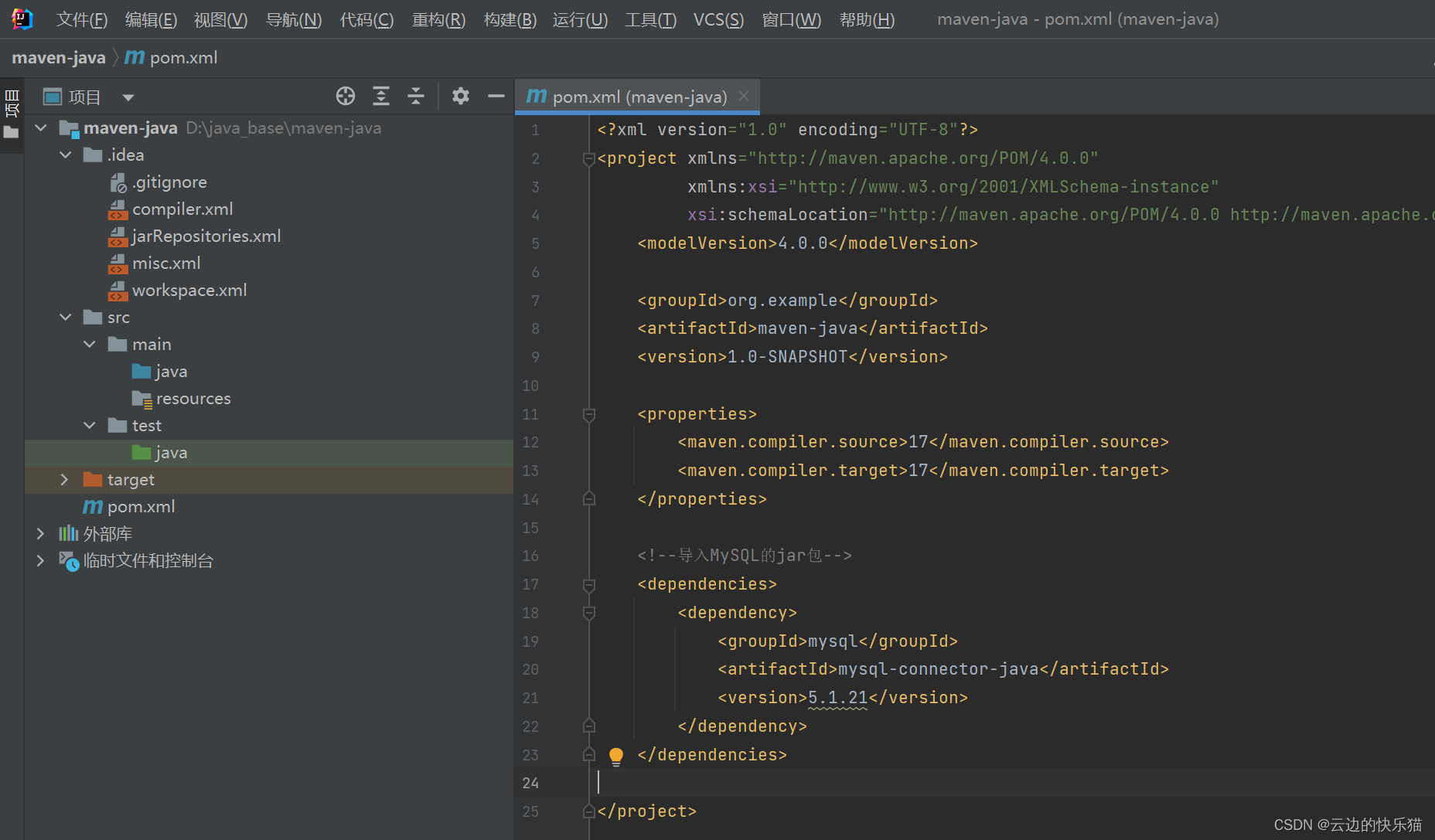
2.在这个maven项目里面的pom.xml这里添加下面这个
<packaging>war</packaging>然后右上角有个刷新的记得刷新一下
成果:

3.鼠标双击项目中的java
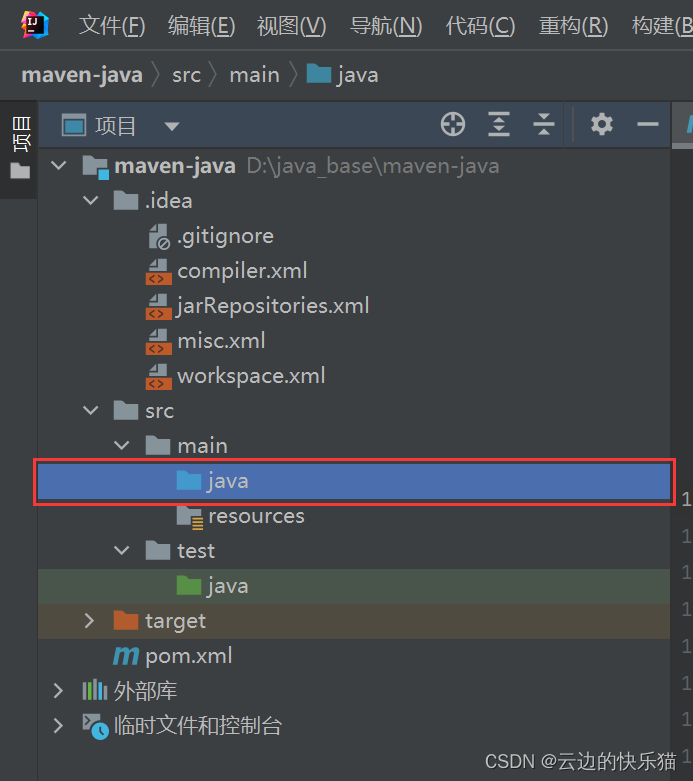
4.跟着图片步骤进行就好了,出现的弹窗都点击确定就好了
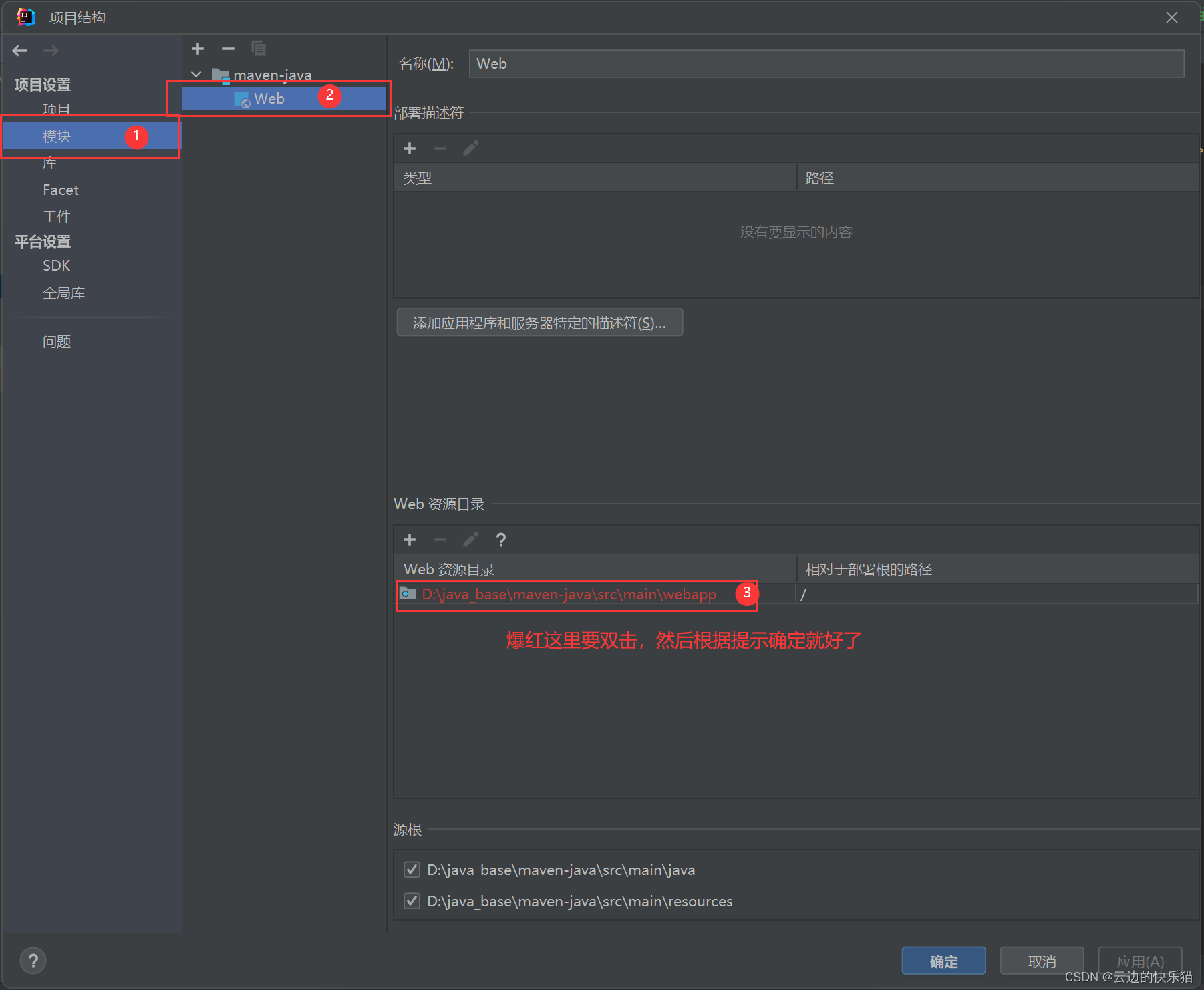
5.跟着图片步骤进行就好了

弹出来的窗口点击确定就好了,再点击整体页面的确定就好了
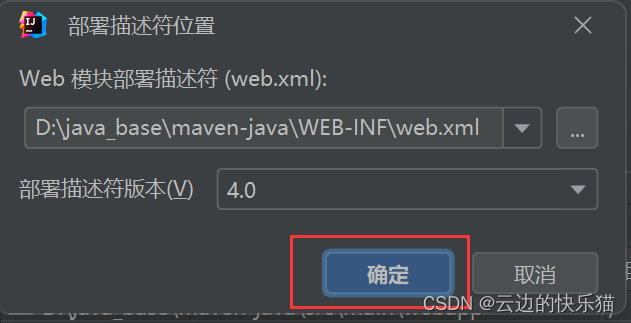
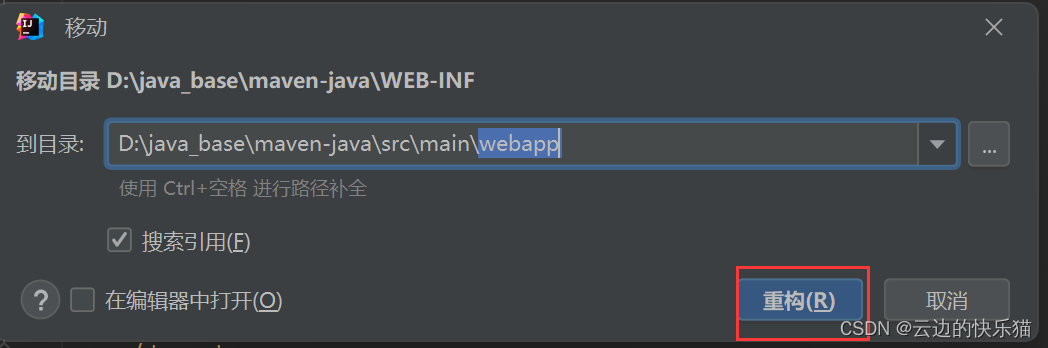
6.用鼠标把这个WEB-INF拖到webapp里面就好了

拖的时候会弹出来一个页面,点击重构就好了
成果:
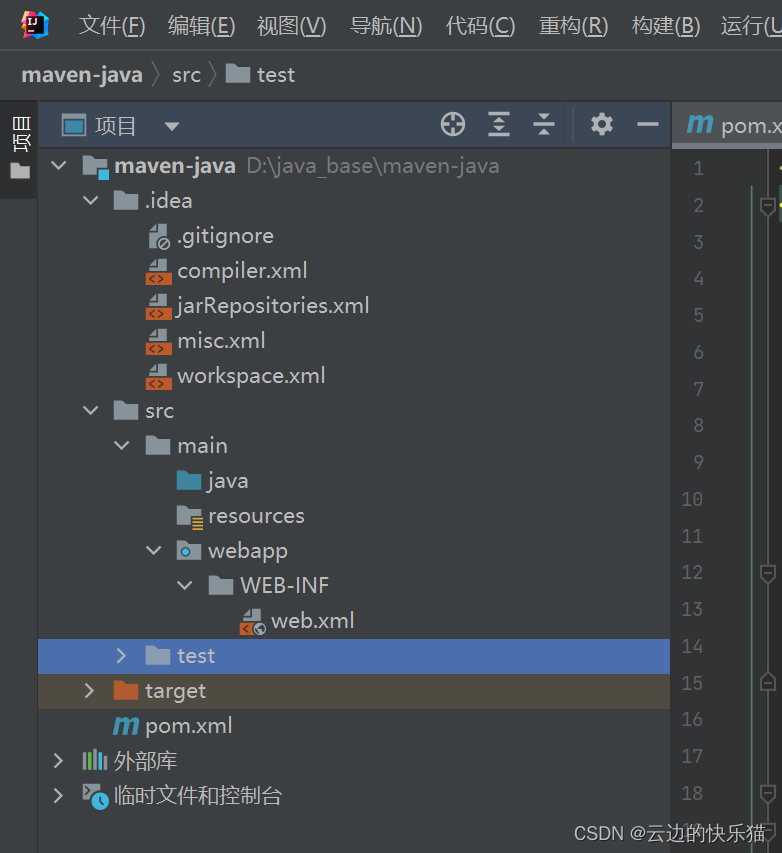
这样不用骨架逐步创建的maven项目就创建好了
在maven项目里面想要运行起来项目,那么就需要配置tomcat
这两种创建出来的都一样,如果第一种骨架方式加载快的情况,我还是喜欢用第一种方式,如果骨架加载慢,可以使用第二种逐步创建的方式
如果你觉得本篇文章对你有所帮助的,给个一键三连吧!!!
点赞关注收藏,抱拳了!
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我对最新版本的Rails有疑问。我创建了一个新应用程序(railsnewMyProject),但我没有脚本/生成,只有脚本/rails,当我输入ruby./script/railsgeneratepluginmy_plugin"Couldnotfindgeneratorplugin.".你知道如何生成插件模板吗?没有这个命令可以创建插件吗?PS:我正在使用Rails3.2.1和ruby1.8.7[universal-darwin11.0] 最佳答案 随着Rails3.2.0的发布,插件生成器已经被移除。查看变更日志here.现在
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?