现代的软件系统都是比较复杂的,设计师处理复杂系统的一个常见方法便是将其"分而治之",把一个系统划分为几个较小的子系统。如果把医院作为一个子系统,按照部门职能,这个系统可以划分为挂号、门诊、划价、化验、收费、取药等。看病的病人要与这些部门打交道,就如同一个子系统的客户端与一个子系统的各个类打交道一样,不是一件容易的事情。
首先病人必须先挂号,然后门诊。如果医生要求化验,病人必须首先划价,然后缴费,才可以到化验部门做化验。化验后再回到门诊室。
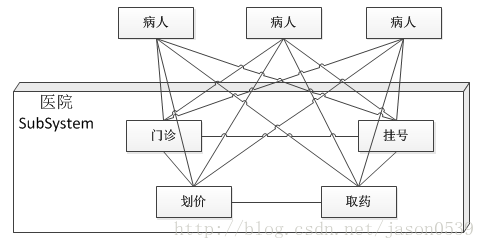
上图描述的是病人在医院里的体验,图中的方框代表医院。
解决这种不便的方法便是引进门面模式,医院可以设置一个接待员的位置,由接待员负责代为挂号、划价、缴费、取药等。这个接待员就是门面模式的体现,病人只接触接待员,由接待员与各个部门打交道。
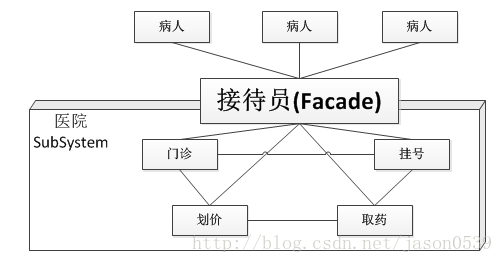
门面模式没有一个一般化的类图描述,最好的描述方法实际上就是以一个例子说明。
由于门面模式的结构图过于抽象,因此把它稍稍具体点。假设子系统内有三个模块,分别是ModuleA、ModuleB和ModuleC,它们分别有一个示例方法,那么此时示例的整体结构图如下:
在这个对象图中,出现了两个角色:
子系统角色中的类: 门面角色类: 客户端角色类: Facade类其实相当于A、B、C模块的外观界面,有了这个Facade类,那么客户端就不需要亲自调用子系统中的A、B、C模块了,也不需要知道系统内部的实现细节,甚至都不需要知道A、B、C模块的存在,客户端只需要跟Facade类交互就好了,从而更好地实现了客户端和子系统中A、B、C模块的解耦,让客户端更容易地使用系统。 使用门面模式还有一个附带的好处,就是能够有选择性地暴露方法。一个模块中定义的方法可以分成两部分,一部分是给子系统外部使用的,一部分是子系统内部模块之间相互调用时使用的。有了Facade类,那么用于子系统内部模块之间相互调用的方法就不用暴露给子系统外部了。 比如,定义如下A、B、C模块。 这样定义一个ModuleFacade类可以有效地屏蔽内部的细节,免得客户端去调用Module类时,发现一些不需要它知道的方法。比如a2()和a3()方法就不需要让客户端知道,否则既暴露了内部的细节,又让客户端迷惑。对客户端来说,他可能还要去思考a2()、a3()方法用来干什么呢?其实a2()和a3()方法是内部模块之间交互的,原本就不是对子系统外部的,所以干脆就不要让客户端知道。 在门面模式中,通常只需要一个门面类,并且此门面类只有一个实例,换言之它是一个单例类。当然这并不意味着在整个系统里只有一个门面类,而仅仅是说对每一个子系统只有一个门面类。或者说,如果一个系统有好几个子系统的话,每一个子系统都有一个门面类,整个系统可以有数个门面类。 初学者往往以为通过继承一个门面类便可在子系统中加入新的行为,这是错误的。门面模式的用意是为子系统提供一个集中化和简化的沟通管道,而不能向子系统加入新的行为。比如医院中的接待员并不是医护人员,接待员并不能为病人提供医疗服务。 松散耦合: 门面模式松散了客户端与子系统的耦合关系,让子系统内部的模块能更容易扩展和维护。 简单易用: 门面模式让子系统更加易用,客户端不再需要了解子系统内部的实现,也不需要跟众多子系统内部的模块进行交互,只需要跟门面类交互就可以了。 更好的划分访问层次: 通过合理使用Facade,可以帮助我们更好地划分访问的层次。有些方法是对系统外的,有些方法是系统内部使用的。把需要暴露给外部的功能集中到门面中,这样既方便客户端使用,也很好地隐藏了内部的细节。 原文地址:https://blog.csdn.net/jason0539/article/details/22775311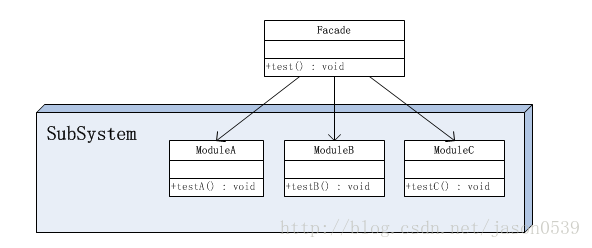
源代码
public class ModuleA {
//示意方法
public void testA(){
System.out.println("调用ModuleA中的testA方法");
}
}
public class ModuleB {
//示意方法
public void testB(){
System.out.println("调用ModuleB中的testB方法");
}
}
public class ModuleC {
//示意方法
public void testC(){
System.out.println("调用ModuleC中的testC方法");
}
}
public class Facade {
//示意方法,满足客户端需要的功能
public void test(){
ModuleA a = new ModuleA();
a.testA();
ModuleB b = new ModuleB();
b.testB();
ModuleC c = new ModuleC();
c.testC();
}
}
public class Client {
public static void main(String[] args) {
Facade facade = new Facade();
facade.test();
}
}
门面模式的实现
public class ModuleA {
/**
* 提供给子系统外部使用的方法
*/
public void a1(){};
/**
* 子系统内部模块之间相互调用时使用的方法
*/
private void a2(){};
private void a3(){};
}
public class ModuleB {
/**
* 提供给子系统外部使用的方法
*/
public void b1(){};
/**
* 子系统内部模块之间相互调用时使用的方法
*/
private void b2(){};
private void b3(){};
}
public class ModuleC {
/**
* 提供给子系统外部使用的方法
*/
public void c1(){};
/**
* 子系统内部模块之间相互调用时使用的方法
*/
private void c2(){};
private void c3(){};
}
public class ModuleFacade {
ModuleA a = new ModuleA();
ModuleB b = new ModuleB();
ModuleC c = new ModuleC();
/**
* 下面这些是A、B、C模块对子系统外部提供的方法
*/
public void a1(){
a.a1();
}
public void b1(){
b.b1();
}
public void c1(){
c.c1();
}
}
一个系统可以有几个门面类
为子系统增加新行为
门面模式的优点
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我将应用程序升级到Rails4,一切正常。我可以登录并转到我的编辑页面。也更新了观点。使用标准View时,用户会更新。但是当我添加例如字段:name时,它不会在表单中更新。使用devise3.1.1和gem'protected_attributes'我需要在设备或数据库上运行某种更新命令吗?我也搜索过这个地方,找到了许多不同的解决方案,但没有一个会更新我的用户字段。我没有添加任何自定义字段。 最佳答案 如果您想允许额外的参数,您可以在ApplicationController中使用beforefilter,因为Rails4将参数
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/