Verilog是一种硬件描述语言,以文本形式来描述数字系统硬件的结构和行为的语言,用它可以表示逻辑电路图、逻辑表达式,还可以表示数字逻辑系统所完成的逻辑功能。
Verilog 和 C 的区别:
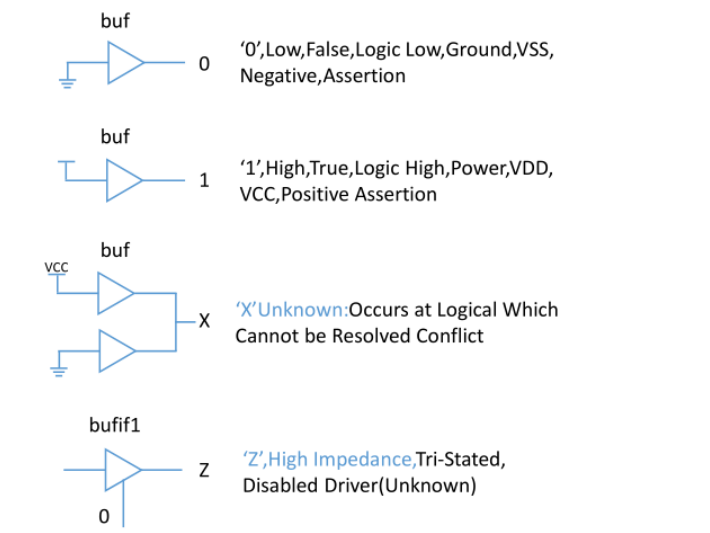
逻辑电路中有四种值,即四种状态
用于定义模块名、端口名和信号名等
Verilog的标识符可以是任意一组字母、数字、$和_(下划线)符号的组合,但标识符的第一个字符必须是字母或者下划线。区分大小写
不建议大小写混合使用,普通内部信号建议全部小写,参数定义建议大写
建议:
用有意义的有效的名字如sum、cpu_addr等
用下划线区分词语组合,如cpu_addr
采用一些前缀或后缀
比如:时钟采用clk前缀:clk_50m,clk_cpu;低电平采用_n后缀:enable_n
统一缩写,如全局复位信号rst
同一信号在不同层次保持一致性,如同一时钟信号必须在各模块保持一致。
自定义的标识符不能与保留字(关键词)同名
参数统一采用大写,如定义参数使用SIZE
Verilog数字进制格式包括二进制、八进制、十进制和十六进制,一般常用的为二进制、十进制和十六进制。
当没有指定数字的位宽与进制时,默认为32位的十进制,比如100,实际上表示的值为32’d100。
主要有三大类数据类型,即寄存器类型、线网类型和参数类型。真正在数字电路中起作用的数据类型是寄存器类型和线网类型。
寄存器类型表示一个抽象的数据存储单元,它只能在always语句和initial语句中被赋值,并且它的值从一个赋值到另一个赋值过程中被保存下来。
如果语句描述的是时序逻辑,即always语句带有时钟信号,则该寄存器变量对应为寄存器;如果该过程语句描述的是组合逻辑,即always语句不带有时钟信号则该寄存器变量对应为硬件连线
寄存器类型的缺省值是x(未知状态)。
寄存器数据类型有很多种,如reg、integer、real等,其中最常用的就是reg类型
reg [31:0] delay_cnt; // 延时计数器
reg key_flag; // 按键标志
线网表示Verilog结构化元件间的物理连线。
值由驱动元件的值决定,例如连续赋值或门的输出。
如果没有驱动元件连接到线网,线网的缺省值为z(高阻态)。
线网类型,如tri和wire等,其中最常用的就是wire类型,它的使用方法如下:
wire data_en; // 数据使能信号
wire [7:0] data; // 数据
参数其实就是一个常量,常被用于定义状态机的状态、数据位宽和延迟大小等
可以在编译时修改参数的值,因此又常被用于一些参数可调的模块中,使用户在实例化模块时,可以根据需要配置参数。
在定义参数时,可以一次定义多个参数,参数与参数之间需要用逗号隔开。
要注意的是参数的定义是局部的,只在当前模块中有效。
parameter DATA_WIDTH = 8; // 数据位宽为8
类型:
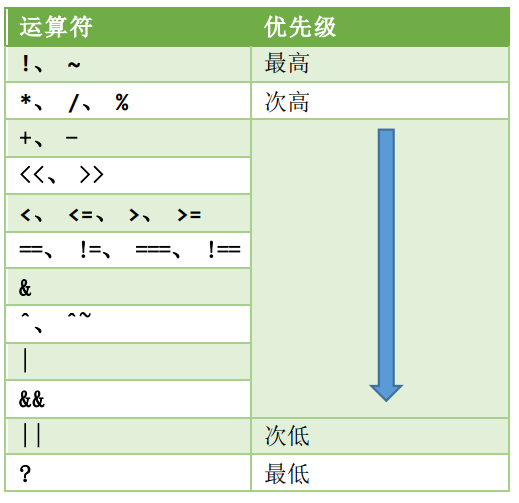
算术运算符
+ - * / %
Verilog实现乘除比较浪费组合逻辑资源,尤其是除法。一般2的指数次幂的乘除法使用移位运算来完成运算.
非2的指数次幂的乘除法一般是调用现成的IP,QUARTUS/ISE等工具软件会有提供,不过这些工具软件提供的IP也是由最底层的组合逻辑(与或非门等)搭建而成的。
关系运算符
> < >= <= == !=
用来进行条件判断,在进行关系运算符时,如果声明的关系是假的,则返回值是0,如果声明的关系是真的,则返回值是1;
所有的关系运算符有着相同的优先级别,关系运算符的优先级别低于算术运算符的优先级别
逻辑运算符
! && ||
连接多个关系表达式,可实现更加复杂的判断,一般不单独使用,都需要配合具体语句来实现完整的意思
条件运算符
? :
从两个输入中选择一个作为输出的条件选择结构,功能等同于always中的if-else语句
位运算符
~ & | ^
直接对应数字逻辑中的与、或、非门等逻辑门
位运算符一般用在信号赋值上
移位运算符
<< >>
移位运算符包括左移位运算符和右移位运算符,这两种移位运算符都用0来填补移出的空位。
一般使用左移位运算代替乘法,右移位运算代替除法,但是只能表示2的指数次幂的乘除法。
拼接运算符
{a,b}
可以把两个或多个信号的某些位拼接起来进行运算操作
/* */
//
建议使用 //
常用关键字
区分大小写
LED流水灯程序
module led(
input sys_clk, // 系统时钟,50M
input sys_rst_n, // 系统复位,低电平有效
output reg[3:0] led // 4位led灯
);
// parameter define
parameter WIDTH = 25;
parameter COUNT_MAX = 25_000_000; // 分频
// reg define
reg [WIDTH-1:0] counter;
reg [1:0] led_ctrl_cnt;
wire counter_en;
// 计数到最大值时产生高电平使能信号 --> 不做分频而是产生一个使能信号
assign counter_en = (counter == (COUNT_MAX - 1'b1)) ? 1'b1:1'b0;
// 产生0.5秒使能信号的计数器
always @ (posedge sys_clk or negedge sys_rst_n) begin
if(sys_rst_n == 1'b0)
counter <= 1'b0;
else if(counter_en)
counter <= 1'b0;
else
counter <= counter + 1'b1;
end
// led流水控制计数器
always @(posedge sys_clk or negedge sys_rst_n) begin
if(sys_rst_n == 1'b0)
led_ctrl_cnt <= 2'b0;
else if(counter_en)
led_ctrl_cnt <= led_ctrl_cnt + 2'b1;
end
// 通过控制IO口的高低电平实现发光二极管的亮灭
always @ (posedge sys_clk or negedge sys_rst_n) begin
if(sys_rst_n == 1'b0)
led <= 4'b0;
else begin
case(led_ctrl_cnt)
2'd0: led <= 4'b0001;
2'd1: led <= 4'b0010;
2'd2: led <= 4'b0100;
2'd3: led <= 4'b1000;
default: ;
endcase
end
end
endmodule
在一个always块中,后面的语句会受到前语句的影响,具体来说,在同一个always中,一条阻塞赋值语句如果没有执行结束,那么该语句后面的语句就不能被执行,即被“阻塞”。
也就是说always块内的语句是一种顺序关系
符号“=”用于阻塞的赋值(如:b = a;),阻塞赋值“=”在begin和end之间的语句是顺序执行,属于串行语句。
其后面的赋值语句从概念上来讲是在前面一条语句赋值完成后才执行的。
符号“<=”用于非阻塞赋值(如:b <= a;),非阻塞赋值是由时钟节拍决定,在时钟上升到来时,执行赋值语句右边,然后将begin-end之间的所有赋值语句同时赋值到赋值语句的左边,
begin—end之间的所有语句,一起执行,且一个时钟只执行一次,属于并行执行语句。
非阻塞赋值的操作过程可以看作两个步骤:
赋值开始的时候,计算RHS( 等号右边的表达式 );
赋值结束的时候,更新LHS( 等号左边的表达式 )。
非阻塞的概念是指,在计算非阻塞赋值的RHS以及LHS期间,允许其它的非阻塞赋值语句同时计算RHS和更新LHS。
在描述组合逻辑电路的时候,使用阻塞赋值,比如assign赋值语句和不带时钟的always赋值语句,这种电路结构只与输入电平的变化有关系
assign data = (data_en == 1'b1)?8'd255:8'd0;
always@(*)begin
if(en) begin
a = a0;
b = b0;
end
else begin
a = a1;
b = b1;
end
end
在描述时序逻辑的时候,使用非阻塞赋值,综合成时序逻辑的电路结构,比如带时钟的always语句;这种电路结构往往与触发沿有关系,只有在触发沿时才可能发生赋值的变化
always @(poseedge sys_clk or negedge sys_rst_n) begin
if(!sys_rst_n) begin
a<= 1'b0;
b<= 1'b0;
end
else begin
a <= c;
b <= d;
end
end
assign 语句使用时不能带时钟。
always 语句可以带时钟,也可以不带时钟。
在always不带时钟是,逻辑功能和assign 完全一致,都是只产生组合逻辑。
比较简单的组合逻辑推荐使用assign语句,比较复杂的组合逻辑推荐使用always语句。
带时钟 和 不带时钟的always:
always 语句可以带时钟,也可以不带时钟。
在always不带时钟时,逻辑功能和assign完全一致,虽然产生的信号定义为reg类型,但是该语句产生的还是组合逻辑
在always带时钟信号时,这个逻辑语句才能产生真正的寄存器
latch指锁存器,是一种对脉冲电平敏感的存储单元电路
锁存器和寄存器都是基本存储单元,锁存器是电平触发的存储器,寄存器是边沿触发的存储器。
两者的基本功能是一样的,都可以存储数据。
锁存器是组合逻辑产生的,而寄存器是在时序电路中使用,由时钟触发产生的。
latch的主要危害是会产生毛刺(glitch),这种毛刺对下一级电路是很危险的。并且其隐蔽性很强,不易查出。
在设计中,应尽量避免latch的使用。
代码里出现latch的两个原因是在组合逻辑中, if或者case语句不完整的描述,比如if缺少else分支,case缺少default分支,导致代码在综合过程中出现了latch。解决办法就是if必须带else分支,case必须带default分支。
只有不带时钟的always语句if或者case语句不完整才会产生latch,带时钟的语句if或者case语句不完整描述不会产生latch。
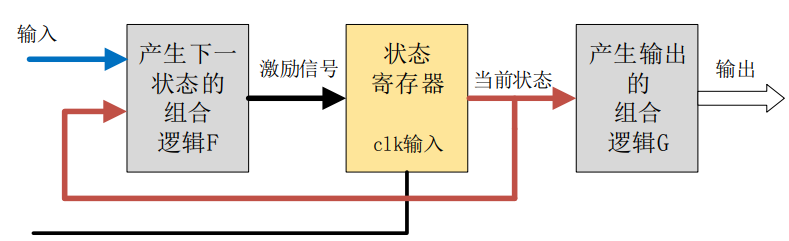
Verilog是硬件描述语言,硬件电路是并行执行的,当需要按照流程或者步骤来完成某个功能时,代码中通常会使用很多个if嵌套语句来实现,这样就增加了代码的复杂度,以及降低了代码的可读性,这个时候就可以使用状态机来编写代码。
状态机相当于一个控制器,它将一项功能的完成分解为若干步,每一步对应于二进制的一个状态,通过预先设计的顺序在各状态之间进行转换,状态转换的过程就是实现逻辑功能的过程。
状态机,全称是有限状态机(Finite State Machine,缩写为FSM),是一种在有限个状态之间按一定规律转换的时序电路,可以认为是组合逻辑和时序逻辑的一种组合。状态机通过控制各个状态的跳转来控制流程,使得整个代码看上去更加清晰易懂,在控制复杂流程的时候,状态机优势明显,因此基本上都会用到状态机,如SDRAM控制器等。
根据状态机的输出是否与输入条件相关,可将状态机分为两大类,即摩尔(Moore)型状态机和米勒(Mealy)型状态机
Mealy状态机:组合逻辑的输出不仅取决于当前状态,还取决于输入状态
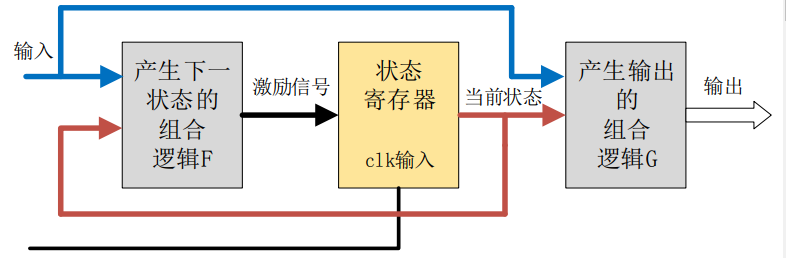
Moore状态机:组合逻辑的输出只取决于当前状态。
根据状态机的实际写法,状态机还可以分为一段式、二段式和三段式状态机。
一段式:整个状态机写到一个always模块里面,在该模块中既描述状态转移,又描述状态的输入和输出。
不推荐,一般都会要求把组合逻辑和时序逻辑分开,组合逻辑和时序逻辑混合在一起不利于代码维护和修改
二段式:用两个always模块来描述状态机,其中一个always模块采用同步时序描述状态转移;另一个模块采用组合逻辑判断状态转移条件,描述状态转移规律以及输出,需要定义两个状态,现态和次态,然后通过现态和次态的转换来实现时序逻辑
三段式:在两个always模块描述方法基础上,使用三个always模块,一个always模块采用同步时序描述状态转移,一个always采用组合逻辑判断状态转移条件,描述状态转移规律,另一个always模块描述状态输出(可以用组合电路输出,也可以时序电路输出)。
三段式状态机的基本格式是:第一个always语句实现同步状态跳转;第二个always语句采用组合逻辑判断状态转移条件;第三个always语句描述状态输出(可以用组合电路输出,也可以时序电路输出)。
demo
7分频
状态跳转
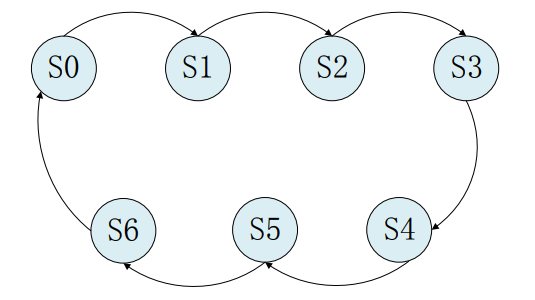
module divider7_fsm (
//系统时钟与复位
input sys_clk ,
input sys_rst_n ,
//输出时钟
output reg clk_divide_7
);
// 状态参数
parameter S0 = 7'b0000001; //独热码定义方式
parameter S1 = 7'b0000010;
parameter S2 = 7'b0000100;
parameter S3 = 7'b0001000;
parameter S4 = 7'b0010000;
parameter S5 = 7'b0100000;
parameter S6 = 7'b1000000;
// 定义两个7位的寄存器,一个用来表示当前状态,一个用来表示下一状态
reg [6:0] curr_st ; //当前状态
reg [6:0] next_st ; //下一个状态
// 三个always语句
// 第一个always采用同步时序描述状态转移
// 第二个always采用组合逻辑判断状态转移条件
// 第三个always描述状态输出
//***************************
//** main code
//***************************
// 描述状态转移
always @(posedge sys_clk or negedge sys_rst_n) begin
if(!sys_rst_n)
curr_st <= S0;
else
curr_st <= next_st;
end
// 判断状态转移条件
always @(*)begin
case(curr_st)
S0: next_st = S1;
S1: next_st = S2;
S2: next_st = S3;
S3: next_st = S4;
S4: next_st = S5;
S5: next_st = S6;
S6: next_st = S0;
default: next_st = S0; // 防止latch
endcase
end
// 状态输出
always @(posedge sys_clk or negedge sys_rst_n) begin
if(!sys_rst_n)
clk_divide_7 <= 1'b0;
else if((curr_st == S0) | (curr_st == S1) | (curr_st == S2) | (curr_st == S3))
clk_divide_7 <= 1'b1;
else if ((curr_st == S4) | (curr_st == S5) | (curr_st == S6))
clk_divide_7 <= 1'b0;
else ;
end
endmodule
状态机的第三段可以使用组合逻辑输出,也可以使用时序逻辑输出一般推荐使用时序电路输出,使用同步时序方式设计,可以提高设计的稳定性,消除毛刺。
划分模块的基本原则是子模块功能相对独立、模块内部联系尽量紧密、模块间的连接尽量简单。
在进行模块化设计中,对于复杂的数字系统,我们一般采用自顶向下的设计方式。可以把系统划分成几个功能模块,每个功能模块再划分成下一层的子模块;每个模块的设计对应一个module,一个module设计成一个Verilog程序文件。因此,对一个系统的顶层模块,我们采用结构化的设计,即顶层模块分别调用了各个功能模块。
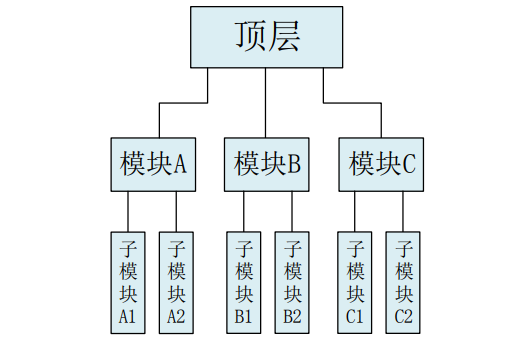
FPGA逻辑设计中通常是一个大的模块中包含了一个或多个功能子模块,Verilog通过模块调用或称为模块实例化的方式来实现这些子模块与高层模块的连接,有利于简化每一个模块的代码,易于维护和修改。
如果子模块内部使用parameter定义了一些参数,Verilog也支持对参数的例化(也叫参数的传递),即顶层模块可以通过例化参数来修改子模块内定义的参数。
子模块名是指被例化模块的模块名,而例化模块名相当于标识,当例化多个相同模块时,可以通过例化名来识别哪一个例化,一般命名为“u_”+“子模块名”
参数的例化,参数的例化是在模块例化的基础上,增加了对参数的信号定义
// 例子
time_count #(
.MAX_NUM (TIME_SHOW) // 参数例化
)u_time_count(
.clk (sys_clk),
.rst_n (sys_rst_n), // 信号例化
.flag (add_flag)
);
localparam代表的意思同样是参数定义,用法和parameter基本一致,区别在于parameter定义的参数可以做例化,而localparam定义的参数是指本地参数,上层模块不可以对localparam定义的参数做例化。
工程的组织形式一般包括如下几个部分,分别是doc、par、rtl和sim四个部分
doc:一般存放工程相关的文档,包括该项目用到的datasheet(数据手册)、设计方案等。
par:主要存放工程文件和使用到的一些IP文件
rtl:主要存放工程的rtl代码,是工程的核心,文件名与module名称应当一致,建议按照模块的层次分开存放
sim:主要存放工程的仿真代码,复杂的工程里面,仿真也是不可或缺的部分,可以极大减少调试的工作量。
每一个Verilog文件的开头,都必须有一段声明的文字。
包含文件的版权、作者、创建日期,以及内容简介等等
//*************************************Copyright(c)*******************//
// FileName:
// Last modified Date:
// Last Version:
// Descriptions:
//*******************************************************************//
一个.v只包括一个module,这样模块会比较清晰易懂
module led(
input sys_clk, // 系统时钟
input sys_rst_n , // 系统复位
output reg [3:0] led // 4位LED灯
);
一个module中的wire/reg变量声明需要集中放在一起,不建议随处乱放
由于不同的解释器对于TAB翻译不一致,所以建议不使用TAB,全部使用空格
我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
在Ruby类中,我重写了三个方法,并且在每个方法中,我基本上做同样的事情:classExampleClassdefconfirmation_required?is_allowed&&superenddefpostpone_email_change?is_allowed&&superenddefreconfirmation_required?is_allowed&&superendend有更简洁的语法吗?如何缩短代码? 最佳答案 如何使用别名?classExampleClassdefconfirmation_required?is_a
可能已经问过了,但我找不到它。这里有2个常见的情况(对我来说,在编程Rails时......)用ruby编写是令人沮丧的:"astring".match(/abc(.+)abc/)[1]在这种情况下,我得到一个错误,因为字符串不匹配,因此在nil上调用[]运算符。我想找到的是比以下内容更好的替代方法:temp="astring".match(/abc(.+)abc/);temp.nil??nil:temp[1]简而言之,如果不匹配,则简单地返回nil而不会出错第二种情况是这样的:var=something.very.long.and.tedious.to.writevar=some
我正在学习Ruby的基础知识(刚刚开始),我遇到了Hash.[]method.它被引入a=["foo",1,"bar",2]=>["foo",1,"bar",2]Hash[*a]=>{"foo"=>1,"bar"=>2}稍加思索,我发现Hash[*a]等同于Hash.[](*a)或Hash.[]*一个。我的问题是为什么会这样。是什么让您将*a放在方括号内,是否有某种规则可以在何时何地使用“it”?编辑:我的措辞似乎造成了一些困惑。我不是在问数组扩展。我明白了。我的问题基本上是:如果[]是方法名称,为什么可以将参数放在括号内?这看起来几乎——但不完全是——就像说如果你有一个方法Foo.d
我正在尝试使用ruby编写一个双线程客户端,一个线程从套接字读取数据并将其打印出来,另一个线程读取本地数据并将其发送到远程服务器。我发现的问题是Ruby似乎无法捕获线程内的错误,这是一个示例:#!/usr/bin/rubyThread.new{loop{$stdout.puts"hi"abc.putsefsleep1}}loop{sleep1}显然,如果我在线程外键入abc.putsef,代码将永远不会运行,因为Ruby将报告“undefinedvariableabc”。但是,如果它在一个线程内,则没有错误报告。我的问题是,如何让Ruby捕获这样的错误?或者至少,报告线程中的错误?
这个问题在这里已经有了答案:WhatisRuby'sdouble-colon`::`?(12个答案)关闭8年前。什么是::?@song||=::TwelveDaysSong.new
在添加一些空格以使代码更具可读性时(与上面的代码对齐),我遇到了这个:classCdefx42endendm=C.new现在这将给出“错误数量的参数”:m.x*m.x这将给出“语法错误,意外的tSTAR,期待$end”:2/m.x*m.x这里的解析器到底发生了什么?我使用Ruby1.9.2和2.1.5进行了测试。 最佳答案 *用于运算符(42*42)和参数解包(myfun*[42,42])。当你这样做时:m.x*m.x2/m.x*m.xRuby将此解释为参数解包,而不是*运算符(即乘法)。如果您不熟悉它,参数解包(有时也称为“spl
我使用Jekyll运行博客,并认为我会解决RedcarpetMarkdown解释器,因为它是developedandusedbyGitHub.好吧,我只是碰巧遇到了一个错误,去检查问题,然后foundthis.Maintainersays,"Asyouprobablyhavenoticed(harharharhar)Idon'thavetimetomaintainRedcarpetanymore.It'snotapriorityforme(IfindMarkdownthoroughlyboring)andit'snotapriorityforGitHub,becausewenolong
方法应返回-1,0或1分别表示“小于”、“等于”和“大于”。对于某些类型的可排序对象,通常将排序顺序基于多个属性。以下是可行的,但我认为它看起来很笨拙:classLeagueStatsattr_accessor:points,:goal_diffdefinitializepts,gd@points=pts@goal_diff=gdenddefothercompare_pts=pointsother.pointsreturncompare_ptsunlesscompare_pts==0goal_diffother.goal_diffendend尝试一下:[LeagueStats.new(