CDC(Change-Data-Capture)正被广泛应用于数据缓存、更新查询索引、创建派生视图、异构数据同步等场景,Debezium 作为 CDC 的代表项目之一,它收集数据库中的事务日志(变化事件)并以统一的事件流格式输出(支持「Kafka Connect」及「内嵌到程序中」两种应用形式)。
数据库的事务日志往往会进行定期清理,这就导致了仅使用事务日志无法涵盖所有的历史数据信息,因此 Debezium 在进行事件流捕获前通常会执行 consistent snapshot(一致性快照) 以获取当前数据库中的完整数据。默认情况下,事件流的捕获会在 consistent snapshot 完成之后 开启,不同数据量情况下,这个过程可能会耗费数小时乃至数天,并且一旦这个过程由于某些异常因素停止,那重新开启后,它将从头开始执行。
为了解决一致性快照的这些痛点问题,Debezium 提出了一个新的设计方案,并在 DDD-3 中详细介绍了该方案的核心理论,借鉴了 DBLog 中的思想,使用一种基于 Watermark 的框架,实现了 Incremental snapshotting。
下面详细介绍 DBLog 论文中的方案。
select from 对数据库进行快照的同时捕获数据库的变化事件流,并使用相同的格式对 select 快照和事务日志捕捉进行输出。这意味着 DBLog 可选择在任意时刻开始执行快照,而不仅限于事件日志捕获开始前。DBLog 的架构如下图所示:

下面将详细介绍 DBLog 的事务日志捕获和快照机制。
事务日志捕获依赖于数据库的支持,如 MySQL 和 PostgreSQL 都提供了 replication 协议,DBLog 将作为数据库主节点的一个从节点,数据库主节点在事务执行完成后会向 replication 从节点发送事务日志(经由 TCP)。通常的事务日志中包含 create、update 和 delete 类型的事件,DBLog 对这些事件进行处理,最终包装为一种统一的格式输出,输出的结果将包含各 column 在事务发生时的状态(事务发生前后的值),每个事件的包装都会以一个 8-byte 且严格单调递增的 LSN(Log Sequence Number)标识,该 LSN 表示该事件在事务日志中的偏移量。上述处理后的输出结果将会存储在 DBLog 进程的内存中,由另外的辅助线程将这些结果搬运到最终的目的地(如 Kafka、DB 等)。
事务日志中还包含了 schema 变化相关的事件,需要妥善处理,但不是本文讨论的重点,这里暂且忽略不提。
事务日志由于定期清理等原因,通常无法保存当前数据库的所有历史状态,而在许多应用场景(如同步)中,都需要保证能完整重现源库的所有数据,这就需要提供一种扩展的 Full state capture 机制。一种较为直观的手段是对每个表建立相应的 copy 表,并将原表中的数据按批(Chunk)写入到 copy 表中,这些写入操作就会按照正确的顺序产生一系列的事务日志事件,在后续处理中就可以正确消费到这些事件(此时正常的事务事件可以同时生成)。这种方式的缺点在于需要消耗 IO 和磁盘空间,虽然可以使用诸如 MySQL bloackhole engine 规避,但实现方式依赖于数据库提供商的特性,没有泛用性。
DBLog 提供了一种更为通用且对源库影响较小策略,它无需将所有的源表中的数据写入到事务日志中,而是采用分批处理的方式,以 Chunk 为单位将源表中的数据查询出来(严格要求每次查询都以主键排序),将这些数据处理成为 DBLog 中的事件结果,并添加到该过程中产生的正常事务事件结果之后。执行过程中需要在外部存储(如 Zookerper)中存储上一个已完成的 Chunk 的最后一行的主键值,这样当这个过程被挂起后,就可以根据这个主键值恢复定位到最近一次执行成功的位置。
下图为 Chunk 的示例,该表中的主键为 c1,且查询时按 c1 进行排序,Chunk size 为 3。当执行 Chunk2 的查询时,会从存储中取出一个表示 Chunk1 最后一行数据的主键 4,而后执行的 Chunk2 查询就会增加条件 c1 > 4。

由于在查询 Chunk 过程中,正常的事务事件仍然同时在产生和执行,为了保证这个过程中不会发生「新数据」被「旧数据」覆盖的情况,每个 Chunk 在与正常事件合并前需要进行特殊处理。核心算法就是在正常的事务事件流中人为插入 Watermark 事件以标记 Chunk 的起止位置,Watermark 就是我们在源端库中创建的一张特殊的表,它由唯一的名称标识,保证不与现有的任何表名冲突,这个表中仅存储 一行一列 的数据,该记录中的数据为一个永不重复的 UUID,这样每当对这个记录进行 update 时,就会在事务日志中产生一条有 UUID 标识的事件,这个事件就称为 watermark event。
下面算法就是整个 Full state capture 的核心步骤:
Algorithm: Watermark-based Chunk Selection
Input: table
(1) pause log event processing
lw := uuid(), hw := uuid()
(2) update watermark table set value = lw
(3) chunk := select next chunk from table
(4) update watermark table set value = hw
(5) resume log event processing
inwindow := false
// other steps of event processing loop
while true do
e := next event from changelog
if not inwindow then
if e is not watermark then
append e to outputbuffer
else if e is watermark with value lw then
inwindow := true
else
if e is not watermark then
(6) if chunk contains e.key then
remove e.key from chunk
append e to outputbuffer
else if e is watermark with value hw then
(7) for each row in chunk do
append row to outputbuffer
// other steps of event processing loop
...
该算法流程会一直循环,直至表中的所有数据都被处理完成。
lw、hw。注意这里是暂停 DBLog 对事件的捕获,而不是暂停源端数据库的日志写入,这个暂停过程中仍然可以有很多的写入事件发生,这个暂停的过程较为短暂,在步骤 5 中会恢复;lw 和 hw 去修改 Watermark 表中的记录,这将会在事务日志中记录两个 update 事件;lw 前,则直接添加到输出结果的内存中;e 进入到了 lw 和 hw 的区间中,则会在步骤 3 中的结果 chunk 中剔除与 e 具有相同主键的记录,lw 和 hw 窗口内到达的事件表示在查询 Chunk 过程中有更「新」的数据达到,因此剔除掉 chunk 结果中的「旧数据」,保证「新数据」能够被最终结果应用;e 已经超过了 hw,则直接将 chunk 结果中剩余的所有记录附加到输出结果末尾。下面以一个具体的例子来演示一下算法的过程:
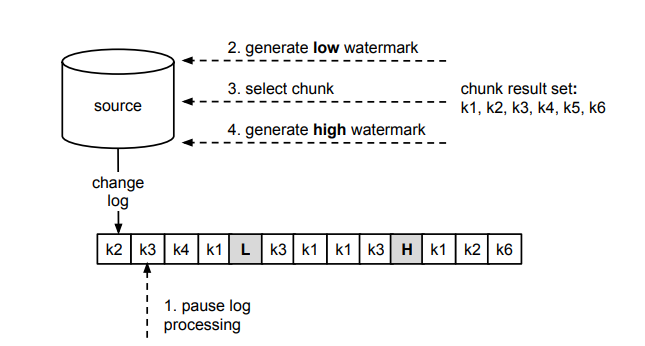
上图中以 k1-k6 表示一张表中的主键值,change log 中的每个事务日志事件也以主键标识为对该行数据的修改,步骤 1-4 与算法中的步骤编号相对应。图中表示了某次 Chunk 的查询过程,暂停事件日志捕获后,先后执行了步骤 2-4,在内存中产生了一个 chunk 结果,并在源数据库的事务日志中记录了两条 watermark。
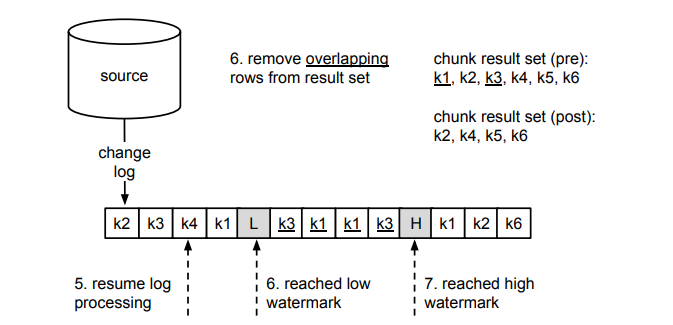
上图中是步骤 5-7 的过程,我们以主键作为依据,从 chunk 结果中剔除了 L 和 H 窗口中修改数据事件对应的相关记录。

最终,将剩余的 chunk 结果附加到 H 之后,就完成了一个 Chunk 的选择过程。
本文详细介绍了 Debezium 的 Incremental snapshot 的实现基础——DBLog,它在原有的 CDC 基础上使用一种基于 Watermark 的框架,扩展了 Full state capture 的功能,能够在事务日志事件捕获开启的同时执行快照,支持挂起和恢复操作,且用户能在任何时间点开启该快照操作。
Enjoy GreatSQL ?
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
捉虫活动详情:https://greatsql.cn/thread-97-1-1.html
社区博客有奖征稿详情:https://greatsql.cn/thread-100-1-1.html

微信:扫码添加
GreatSQL社区助手微信好友,发送验证信息加群。
 )
)
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
使用RubyonRails,我使用给定的增量(例如每30分钟)用时间填充“选择”。目前我正在YAML文件中写出所有的可能性,但我觉得有一种更巧妙的方法。我想我想提供一个开始时间、一个结束时间、一个增量,并且目前只提供一个名为“关闭”的选项(想想“business_hours”)。所以,我的选择可能会显示:'Closed'5:00am5:30am6:00am...[allthewayto]...11:30pm谁能想出更好的方法,或者只是将它们全部“拼写”出来的最佳方法? 最佳答案 此答案基于@emh的答案。defcreate_hour
以下代码导致了我的问题:classFoodefinitialize(n=0)@n=nendattr_accessor:ndefincn+=1endend调用Foo.new.inc引发NoMethodError:undefinedmethod'+'fornil:NilClass调用Foo.new.n返回0为什么Foo.new.inc会引发错误?我可以毫无问题地执行Foo.new.n+=1。 最佳答案 tldr;某种形式的self.n=x必须始终用于分配给setter。考虑n+=x扩展为n=n+x其中n被绑定(bind)为局部变量因为它
我有一个字符串形式的URL。向其中添加一些参数最简洁的方法是什么?例如base='http://example.com'uri1=some_magical_method(base,:p1=>'v1')#=>http://example.com/?p1=v1uri2=some_magical_method(uri1,:p2=>'v2')#=>http://example.com/?p1=v1&p2=v2uri3=some_magical_method(uri2,:p3=>nil)#=>http://example.com/?p1=v1&p2=v21)在Ruby中?2)在Rails中?
数据同步的方式数据同步的2大方式基于SQL查询的CDC(ChangeDataCapture):离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据。也就是我们说的基于SQL查询抽取;无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;不保障实时性,基于离线调度存在天然的延迟;工具软件以Kettle(ApacheHop最新版)、DataX为代表,需要结合任务调度系统使用。基于日志的CDC:实时消费日志,流处理,例如MySQL的binlog日志完整记录了数据库中的变更,可以把binlog文件当作流的数据源;保障数据一致性,因为binlog文件包含了所有历史变更
我有一个图片模型,其中包含一个用于查看次数(整数)的变量。每次有人查看Picture对象时,查看计数都会增加+1。在完成这件事时,有什么区别@picture.view_count+=1@picture.save和@picture.increment(:view_count,1)另外,如果我使用增量,是否需要.save? 最佳答案 increment的来源如下,如果nil将属性初始化为零,并添加传递的值(默认为1),它不保存,所以.save仍然是必要的。defincrement(attribute,by=1)self[attribut
这个问题在这里已经有了答案:Whydoesn'tRubysupporti++ori--(increment/decrementoperators)?(9个回答)关闭9年前。在Java中,i++会把i加1。我可以用Ruby做什么?肯定有比i=i+1更好的方法吗?
所以我像这样遍历一个范围:(1..100).eachdo|n|#n=1#n=2#n=3#n=4#n=5end但我想做的是以10为单位进行迭代。因此,不是将n增加1,下一个n实际上是10,然后是20、30,等等。 最佳答案 参见http://ruby-doc.org/core/classes/Range.html#M000695获取完整的API。基本上您使用step()方法。例如:(10..100).step(10)do|n|#n=10#n=20#n=30#...end 关于Ruby:如何
这个问题在这里已经有了答案:关闭12年前。PossibleDuplicate:Whydoesn'tRubysupporti++ori—forfixnum?为什么Ruby中没有自增运算符?例如i++++i++运算符是否用于其他用途?这有真正的原因吗?
我正在使用firebase的foreach从这个url中获取树中的每个child目标,当页面加载时从firebase中随机获取一个项目并显示它数据结构grabbit(tablename)active(foractiveitemsforsale)category(thecategoryoftheitemiewomensClothes,MensShoesetc)uniqueidoftheitem在页面加载时进入http://gamerholic.firebase.com/grabbit/active并捕获任何一个类别并将其返回..脚本vargrabbitRef=newFirebase('h