
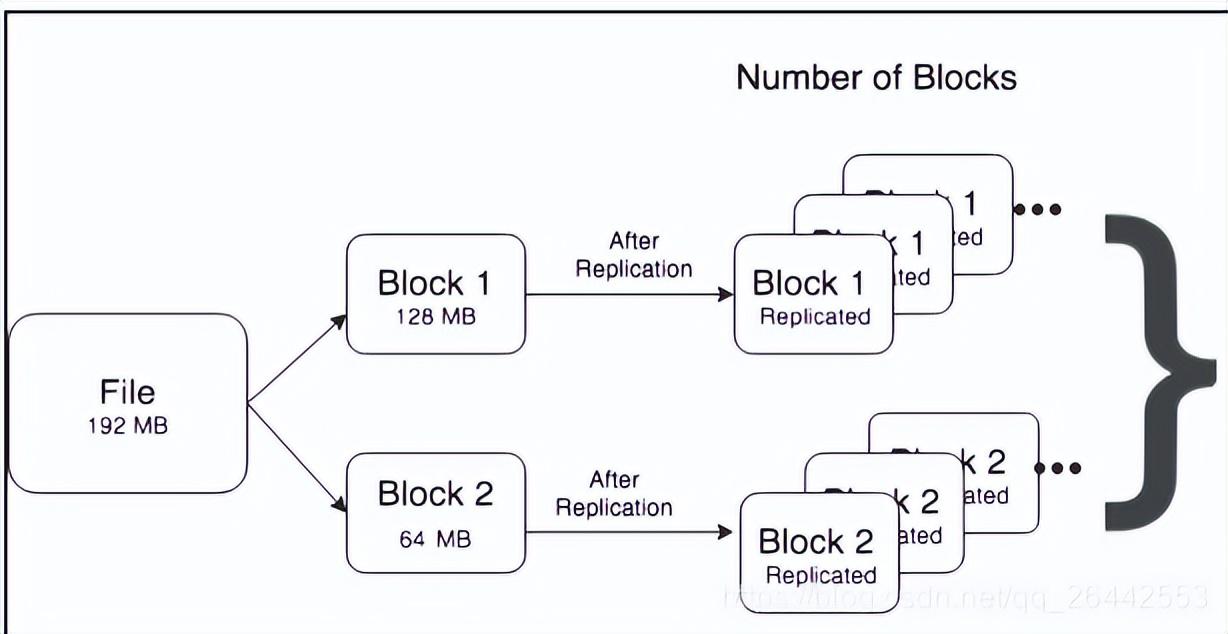
 图1
图1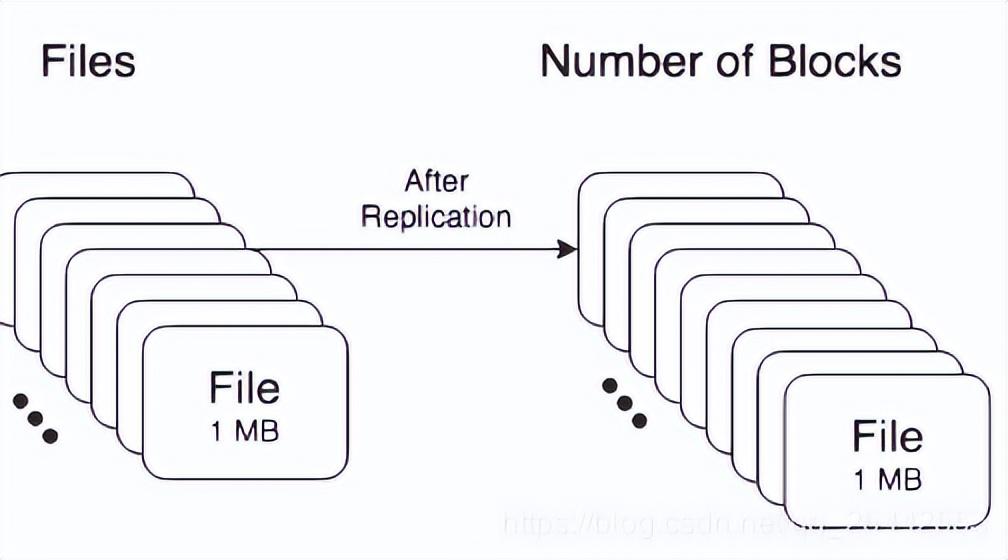 图2namenode的namespace中主要占存储对象是文件的目录个数,文件(文件名长度)以及文件block数。根据namenode实际使用经验来看,一个存储对象大概占用150字节的空间。HDFS上存储文件占用的namenode内存计算公式如下:Memory=150bytes*(1个文件inode+(文件的块数*副本个数))如上图1 ,一个文件192Mb,默认blocksize=128Mb,副本个数为3,存储为2个block,需要namenode内存=150*(1+2*3)=1050 Bytes同理,图2 一个文件192Mb,默认blocksize=128Mb,副本个数为3,存储为192个block,需要namenode内存=150 x (192 + (192 x 3)) = 115200 Bytes尖叫总结:1 .从上面可以看出,同样的一个文件,大小不同形态的存储占用namenode的内存之比相差了109倍之多。所以如果对于单namenode的集群来说,大量的小文件的会占用大量的namenode堆内存空间,给集群的存储造成瓶颈。有些人可能会说我们联邦,多组namenode不就没有这个问题了,其实不然,且往下看2.当 NameNode 重新启动时(虽然生产上这种情况很少),它必须将文件系统元数据fsimage从本地磁盘加载到内存中。这意味着如果 namenode 元数据很大,重启会更慢(以我们公司3亿block,5万多个文件对象来说,重启一次1.5小时,期间应用不可用)其次,datanode 还通过网络向 NameNode 报告块更改;更多的块意味着要通过网络报告更多的变化,等待时间更长。3.更多的文件,更多的block,意味着更多的读取请求需要由 NameNode 提供服务,这将增加 RPC 队列和处理延迟,进而导致namenode性能和响应能力下降。官方介绍说接近 40K~50K RPCs/s 人为是极高的负载。实际使用来看比这低时对于namenode来说性能都会打很大的折扣。
图2namenode的namespace中主要占存储对象是文件的目录个数,文件(文件名长度)以及文件block数。根据namenode实际使用经验来看,一个存储对象大概占用150字节的空间。HDFS上存储文件占用的namenode内存计算公式如下:Memory=150bytes*(1个文件inode+(文件的块数*副本个数))如上图1 ,一个文件192Mb,默认blocksize=128Mb,副本个数为3,存储为2个block,需要namenode内存=150*(1+2*3)=1050 Bytes同理,图2 一个文件192Mb,默认blocksize=128Mb,副本个数为3,存储为192个block,需要namenode内存=150 x (192 + (192 x 3)) = 115200 Bytes尖叫总结:1 .从上面可以看出,同样的一个文件,大小不同形态的存储占用namenode的内存之比相差了109倍之多。所以如果对于单namenode的集群来说,大量的小文件的会占用大量的namenode堆内存空间,给集群的存储造成瓶颈。有些人可能会说我们联邦,多组namenode不就没有这个问题了,其实不然,且往下看2.当 NameNode 重新启动时(虽然生产上这种情况很少),它必须将文件系统元数据fsimage从本地磁盘加载到内存中。这意味着如果 namenode 元数据很大,重启会更慢(以我们公司3亿block,5万多个文件对象来说,重启一次1.5小时,期间应用不可用)其次,datanode 还通过网络向 NameNode 报告块更改;更多的块意味着要通过网络报告更多的变化,等待时间更长。3.更多的文件,更多的block,意味着更多的读取请求需要由 NameNode 提供服务,这将增加 RPC 队列和处理延迟,进而导致namenode性能和响应能力下降。官方介绍说接近 40K~50K RPCs/s 人为是极高的负载。实际使用来看比这低时对于namenode来说性能都会打很大的折扣。
 转载本文请联系「涤生大数据」公众号。
转载本文请联系「涤生大数据」公众号。 有没有办法配置(例如,可以使用Fastfile)或以更简洁的方式执行FaSTLane?它目前打印出很多信息,这些信息通常会使开发人员对警告和错误视而不见。主要问题是需要花费一些时间在大量无用消息中滚动和搜索黄色/红色文本,直到您了解发生了什么。默认设置会打印所有内容,令人惊讶的是甚至还有--verbosemode对于CLI,但我找不到任何相反的东西,例如--quiet模式。编辑:下面是一些我希望能够抑制的输出示例。考虑到我使用了来自gitrepo的Fastfile,gym、match、cocoapods、get_version_number、increment_version_numb
我的问题很简单:我是否必须在使用RubyonRails的类上require'csv'?如果我打开一个railsconsole并尝试使用CSVgem它可以工作,但我必须在文件中这样做吗? 最佳答案 CSVlibrary是ruby标准库的一部分;它不是gem(即第三方库)。与所有标准库(与核心库不同)一样,csv不会由ruby解释器自动加载。所以是的,在您的应用程序中某处您确实需要要求它:irb(main):001:0>CSVNameError:uninitializedconstantCSVfrom(irb):1from/Us
Ruby是完全面向对象的语言。在ruby中,一切都是对象,因此属于某个类。例如5属于Objectclass1.9.3p194:001>5.class=>Fixnum1.9.3p194:002>5.class.superclass=>Integer1.9.3p194:003>5.class.superclass.superclass=>Numeric1.9.3p194:005>5.class.superclass.superclass.superclass=>Object1.9.3p194:006>5.class.superclass.superclass.superclass.su
我的感觉是Camping和Sinatra之间的差异不是很大,您可以安全地选择其中任何一个并且没问题。但我想问问Ruby专家,这是不是真的。Sinatra和Camping微框架之间实际上有什么重要区别吗?您将如何决定使用哪一个? 最佳答案 我知道的唯一显着区别是Camping像Rails一样基于MVC模式,并且与ActiveRecord耦合。Sinatra更加不可知。Camping也不再维护,而Sinatra正在积极开发中。仅这一点就足以让我们先看看Sinatra。编辑:感谢Philippe的更正,很高兴听到Camping的开发正在进
有人知道为什么我的rails3.0.7cli这么慢吗?当我运行railss或railsg时,他大约需要5秒才能真正执行命令...有什么建议吗?谢谢 最佳答案 更新:我正在将我的建议从rrails切换到rails-sh,因为前者支持REPL,而rrails不是用例。此外,当与ruby环境结合使用时,修补似乎确实可以提高性能变量,现在反射(reflect)在答案中。一个可能的原因可能是这个performancebuginruby每当在ruby代码中使用“require”时,它就会调用一些代码(更多详细信息here)。在使用Rai
下面两个语句除了编码风格有区别吗?/regex/=~"some_string_with_regex""some_string_with_regex"=~/regex/ 最佳答案 是的,有区别。正如在http://www.ruby-doc.org/core/classes/Regexp.html#M001232中提到的If=~isusedwitharegexpliteralwithnamedcaptures,capturedstrings(ornil)isassignedtolocalvariablesnamedbythecaptur
最近火热的“数字藏品”,你真正了解吗?其实有很多人会把数字藏品跟NFT混为一谈,但其实这两者还是有差别的。数字藏品并不等同于NFT数字藏品是什么?直观来看,它可能就是一张数字化照片或视频,甚至就只是一串数字。但它却是一件对应特定作品、艺术品生成的包含着大量数字信息且拥有唯一加密信息的可以买卖交易的收藏品。NFT则是指一种基于以太坊区块链的“非同质化代币”。它在百度百科里的释义是“用于表示数字资产(包括jpg和视频剪辑形式)的唯一加密货币令牌,可以买卖”。比如已被很多人认识的比特币就是NFT的一种。NFT在元宇宙中发挥的作用是巨大的,目前正是它在支撑着元宇宙中的经济体系。数字藏品其实也是NFT的
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
我正在开发Rails5应用程序并使用Assets管道。它在开发模式下运行良好,但如果我尝试在生产模式下运行它,它无法正确加载图像和样式。我查了一下,发现是因为config.assets.compile=false在config/environments/production.rb中除非我将其设置为真,否则它根本不起作用。我知道实时编译不适合生产,有什么解决方案? 最佳答案 有两个与在Rails服务器中提供Assets相关的选项:Assets编译config.assets.compile=true指Assets编译。也就是说,当Rai
有人可以向我解释一下,为什么不初始化first_idx和last_idx会导致代码无法运行??当我运行它时,出现此错误“未定义的局部变量或方法last_idx”。我知道建议总是初始化变量,但我不明白为什么。毕竟first_idx和last_idx总是会在循环中得到一个值,因为参数letter总是出现在字符串中(在这个特定问题中)。我真的很感激一些(简单的)见解。谢谢!P.S,我也知道在Ruby中使用#index和#rindex很容易解决这个问题,但我不允许使用直接的方法来解决它。deffind_for_letter(string,letter)first_idx=nil0.upto(s