public interface LoadBalance {
}
public class RandomLoadBalance implements LoadBalance{
}public class ServiceLoaderDemo {
public static void main(String[] args) {
ServiceLoader<LoadBalance> loadBalanceServiceLoader = ServiceLoader.load(LoadBalance.class);
Iterator<LoadBalance> iterator = loadBalanceServiceLoader.iterator();
while (iterator.hasNext()) {
LoadBalance loadBalance = iterator.next();
System.out.println("获取到负载均衡策略:" + loadBalance);
}
}
}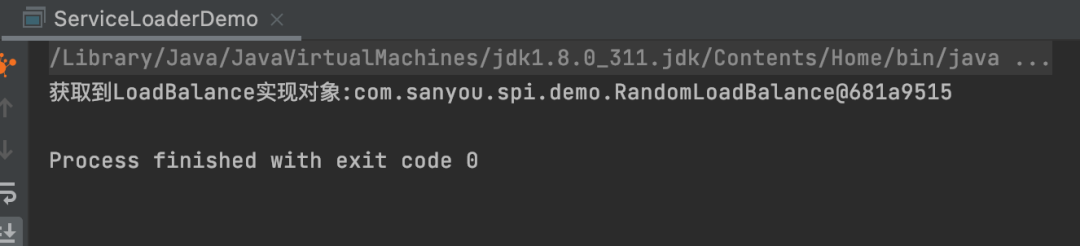 此时就成功获取到了实现。在实际的框架设计中,上面这段测试代码其实是框架作者写到框架内部的,而对于框架的使用者来说,要想自定义LoadBalance实现,嵌入到框架,仅仅只需要写接口的实现和spi文件即可。
此时就成功获取到了实现。在实际的框架设计中,上面这段测试代码其实是框架作者写到框架内部的,而对于框架的使用者来说,要想自定义LoadBalance实现,嵌入到框架,仅仅只需要写接口的实现和spi文件即可。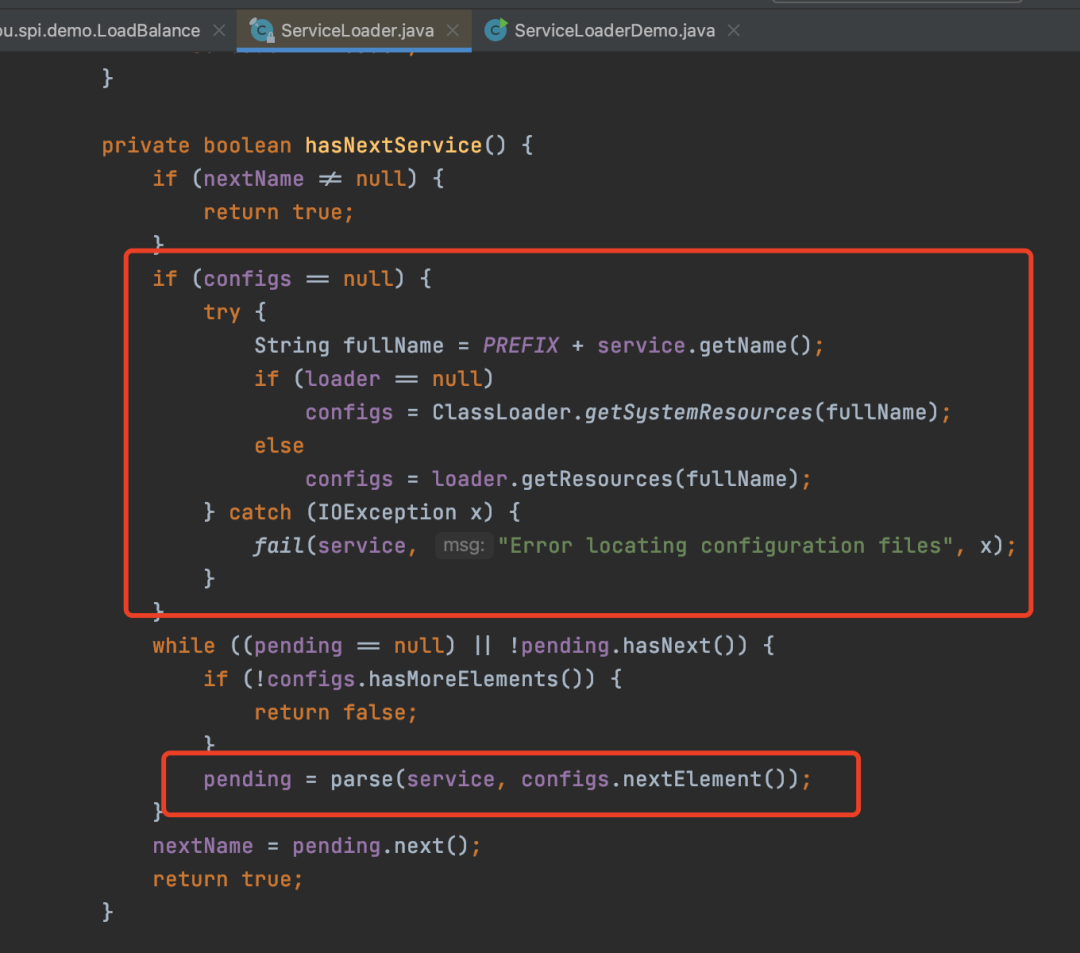 首先获取一个fullName,其实就是META-INF/services/接口的全限定名然后通过ClassLoader获取到资源,其实就是接口的全限定名文件对应的资源,然后交给parse方法解析资源
首先获取一个fullName,其实就是META-INF/services/接口的全限定名然后通过ClassLoader获取到资源,其实就是接口的全限定名文件对应的资源,然后交给parse方法解析资源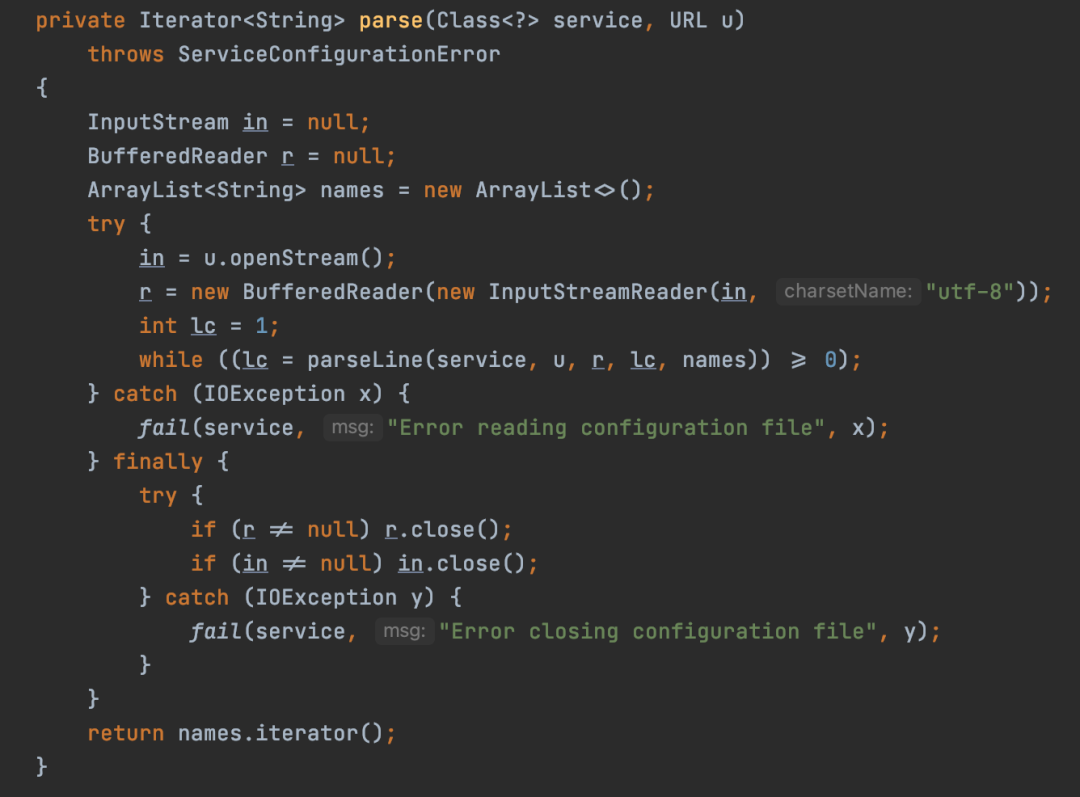 parse方法其实就是通过IO流读取文件的内容,这样就可以获取到接口的实现的全限定名再后面其实就是通过反射实例化对象,这里就不展示了。所以其实不难发现ServiceLoader实现原理比较简单,总结起来就是通过IO流读取META-INF/services/接口的全限定名文件的内容,然后反射实例化对象。
parse方法其实就是通过IO流读取文件的内容,这样就可以获取到接口的实现的全限定名再后面其实就是通过反射实例化对象,这里就不展示了。所以其实不难发现ServiceLoader实现原理比较简单,总结起来就是通过IO流读取META-INF/services/接口的全限定名文件的内容,然后反射实例化对象。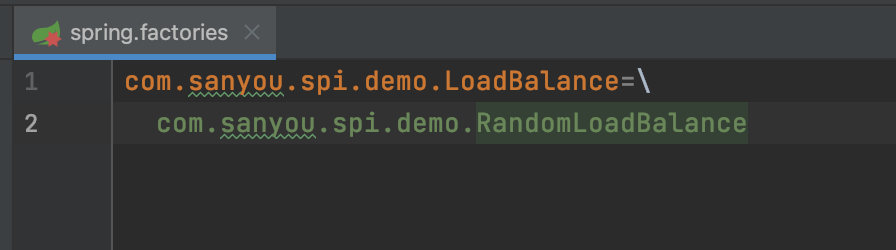 测试:
测试:public class SpringFactoriesLoaderDemo {
public static void main(String[] args) {
List<LoadBalance> loadBalances = SpringFactoriesLoader.loadFactories(LoadBalance.class, MyEnableAutoConfiguration.class.getClassLoader());
for (LoadBalance loadBalance : loadBalances) {
System.out.println("获取到LoadBalance对象:" + loadBalance);
}
}
} 成功获取到了实现对象。
成功获取到了实现对象。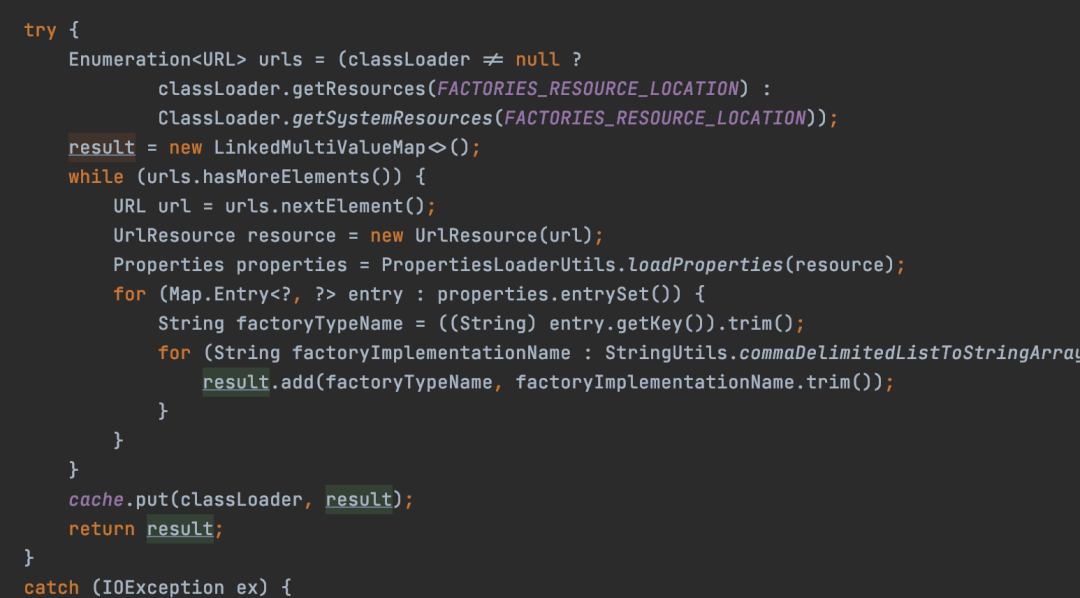 其实从这可以看出,跟Java实现的差不多,只不过读的是META-INF/目录下spring.factories文件内容,然后解析出来键值对。
其实从这可以看出,跟Java实现的差不多,只不过读的是META-INF/目录下spring.factories文件内容,然后解析出来键值对。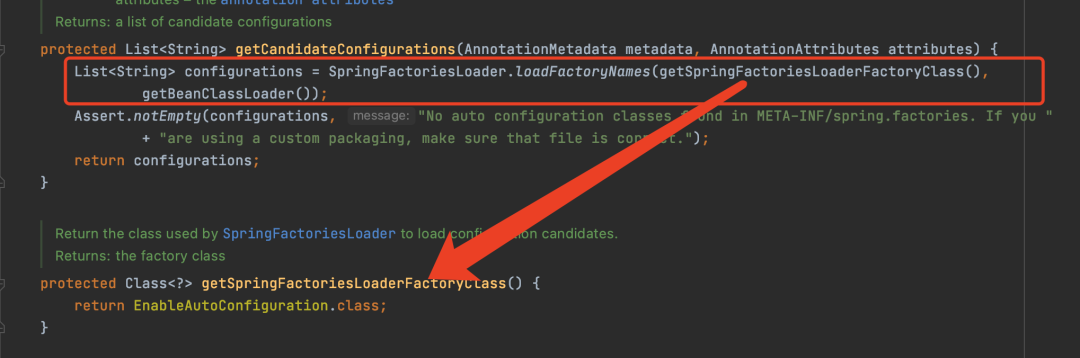 但是SpringBoot3.0之后不再使用SpringFactoriesLoader,而是Spring重新从META-INF/spring/目录下的org.springframework.boot.autoconfigure.AutoConfiguration.imports文件中读取了。
但是SpringBoot3.0之后不再使用SpringFactoriesLoader,而是Spring重新从META-INF/spring/目录下的org.springframework.boot.autoconfigure.AutoConfiguration.imports文件中读取了。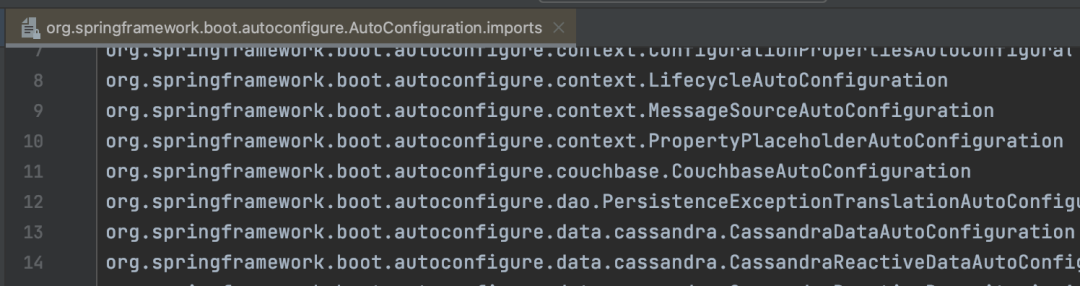 至于如何读取的,其实猜也能猜到就跟上面SPI机制读取的方式大概差不多,就是文件路径和名称不一样。
至于如何读取的,其实猜也能猜到就跟上面SPI机制读取的方式大概差不多,就是文件路径和名称不一样。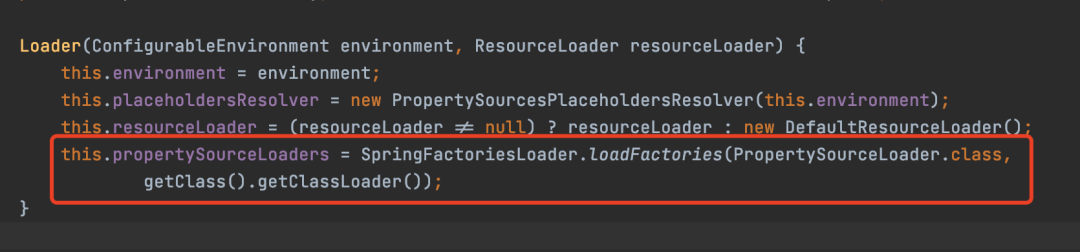
@SPI
public interface LoadBalance {
}random=com.sanyou.spi.demo.RandomLoadBalancepublic class ExtensionLoaderDemo {
public static void main(String[] args) {
ExtensionLoader<LoadBalance> extensionLoader = ExtensionLoader.getExtensionLoader(LoadBalance.class);
LoadBalance loadBalance = extensionLoader.getExtension("random");
System.out.println("获取到random键对应的实现类对象:" + loadBalance);
}
}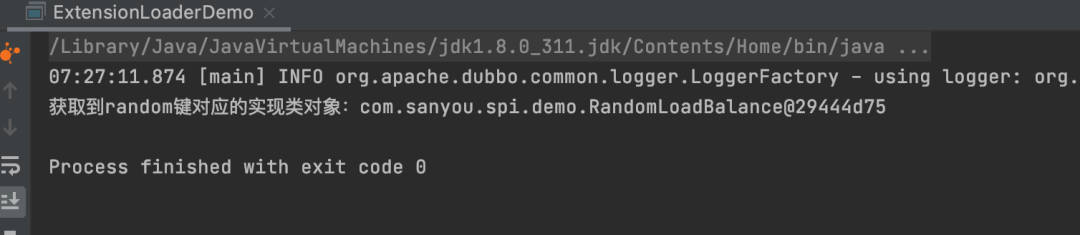 dubbo的SPI机制除了解决了无法获取指定实现类的问题,还提供了很多额外的功能,这些功能在dubbo内部用的非常多,接下来就来详细讲讲。
dubbo的SPI机制除了解决了无法获取指定实现类的问题,还提供了很多额外的功能,这些功能在dubbo内部用的非常多,接下来就来详细讲讲。@Adaptive
public class RandomLoadBalance implements LoadBalance{
}public class RoundRobinLoadBalance implements LoadBalance {
private LoadBalance loadBalance;
public void setLoadBalance(LoadBalance loadBalance) {
this.loadBalance = loadBalance;
}
}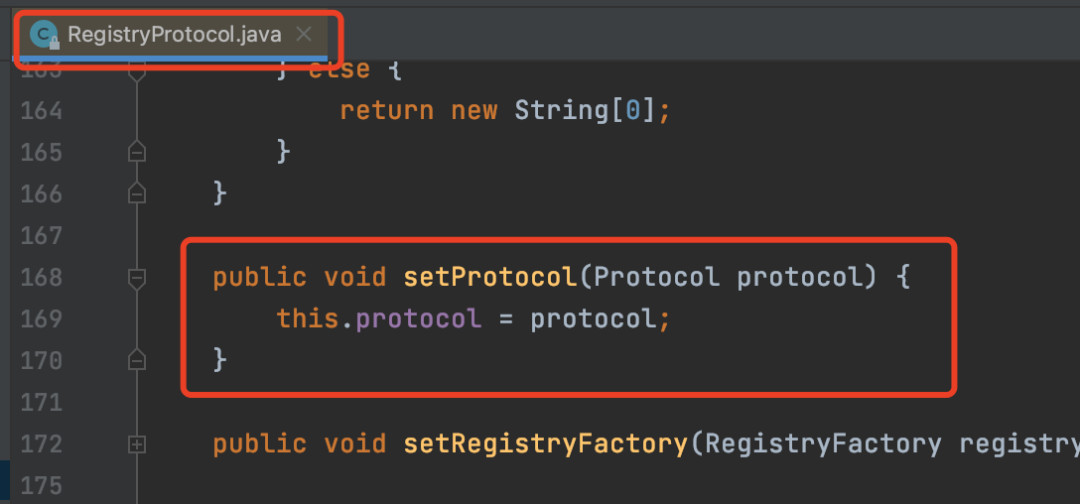 RegistryProtocol中会注入一个Protocol,其实这个注入的Protocol就是一个自适应对象。2.2、接口回调Dubbo也提供了一些类似于Spring的一些接口的回调功能,比如说,如果你的类实现了Lifecycle接口,那么创建或者销毁的时候就会回调以下几个方法
RegistryProtocol中会注入一个Protocol,其实这个注入的Protocol就是一个自适应对象。2.2、接口回调Dubbo也提供了一些类似于Spring的一些接口的回调功能,比如说,如果你的类实现了Lifecycle接口,那么创建或者销毁的时候就会回调以下几个方法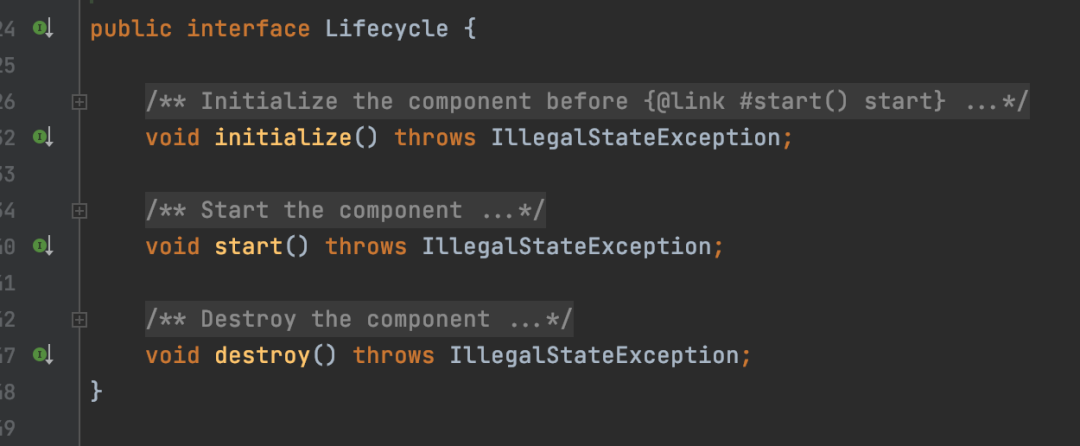 在dubbo3.x的某个版本之后,dubbo提供了更多接口回调,比如说ExtensionPostProcessor、ExtensionAccessorAware,命名跟Spring的非常相似,作用也差不多。2.3、自动包装自动包装其实就是aop的功能实现,对目标对象进行代理,并且这个aop功能在默认情况下就是开启的。在Dubbo中SPI接口的实现中,有一种特殊的类,被称为Wrapper类,这个类的作用就是来实现AOP的。判断Wrapper类的唯一标准就是这个类中必须要有这么一个构造参数,这个构造方法的参数只有一个,并且参数类型就是接口的类型,如下代码:
在dubbo3.x的某个版本之后,dubbo提供了更多接口回调,比如说ExtensionPostProcessor、ExtensionAccessorAware,命名跟Spring的非常相似,作用也差不多。2.3、自动包装自动包装其实就是aop的功能实现,对目标对象进行代理,并且这个aop功能在默认情况下就是开启的。在Dubbo中SPI接口的实现中,有一种特殊的类,被称为Wrapper类,这个类的作用就是来实现AOP的。判断Wrapper类的唯一标准就是这个类中必须要有这么一个构造参数,这个构造方法的参数只有一个,并且参数类型就是接口的类型,如下代码:public class RoundRobinLoadBalance implements LoadBalance {
private final LoadBalance loadBalance;
public RoundRobinLoadBalance(LoadBalance loadBalance) {
this.loadBalance = loadBalance;
}
}roundrobin=com.sanyou.spi.demo.RoundRobinLoadBalance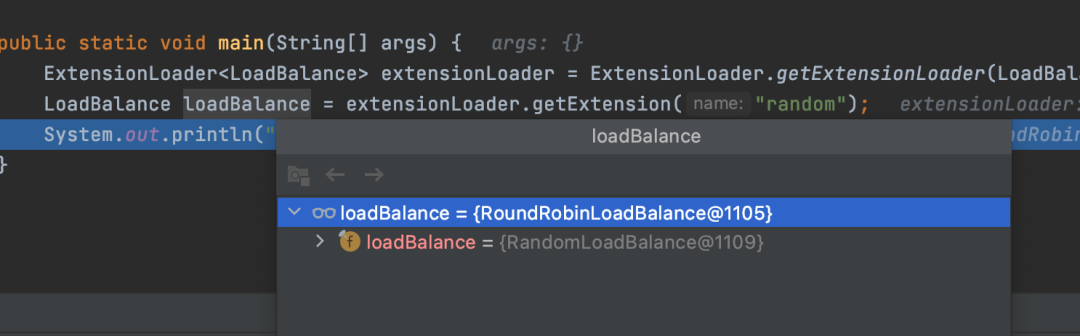 从结果可以看出,虽然指定了random,但是实际获取到的是RoundRobinLoadBalance,而RoundRobinLoadBalance内部引用了RandomLoadBalance。如果有很多的包装类,那么就会形成一个责任链条,一个套一个。所以dubbo的aop跟spring的aop实现是不一样的,spring的aop底层是基于动态代理来的,而dubbo的aop其实算是静态代理,dubbo会帮你自动组装这个代理,形成一条责任链。到这其实我们已经知道,dubbo的spi接口的实现类已经有两种类型了:
从结果可以看出,虽然指定了random,但是实际获取到的是RoundRobinLoadBalance,而RoundRobinLoadBalance内部引用了RandomLoadBalance。如果有很多的包装类,那么就会形成一个责任链条,一个套一个。所以dubbo的aop跟spring的aop实现是不一样的,spring的aop底层是基于动态代理来的,而dubbo的aop其实算是静态代理,dubbo会帮你自动组装这个代理,形成一条责任链。到这其实我们已经知道,dubbo的spi接口的实现类已经有两种类型了:@SPI("random")
public interface LoadBalance {
}@Activate
public interface RandomLoadBalance {
} Filter的一些实现类如上Filter有很多实现,所以为了能够区分Filter的实现是作用于provider的还是consumer端,所以就可以用自动激活的机制来根据入参来动态选择一批Filter实现。比如说ConsumerContextFilter这个Filter就作用于Consumer端。
Filter的一些实现类如上Filter有很多实现,所以为了能够区分Filter的实现是作用于provider的还是consumer端,所以就可以用自动激活的机制来根据入参来动态选择一批Filter实现。比如说ConsumerContextFilter这个Filter就作用于Consumer端。 ConsumerContextFilter最后,这里并没有对dubbo的SPI机制进行源码分析,感兴趣的同学可以看一下面试常问的dubbo的spi机制到底是什么?(上)和 面试常问的dubbo的spi机制到底是什么?(下)两篇文章。
ConsumerContextFilter最后,这里并没有对dubbo的SPI机制进行源码分析,感兴趣的同学可以看一下面试常问的dubbo的spi机制到底是什么?(上)和 面试常问的dubbo的spi机制到底是什么?(下)两篇文章。我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在使用Ruby2.1.1和Rails4.1.0.rc1。当执行railsc时,它被锁定了。使用Ctrl-C停止,我得到以下错误日志:~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`gets':Interruptfrom~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`verify_server_version'from~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于