阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说)、深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云。更多精彩内容请单击此处。

摘要:CarbonData是一种新型的Apache Hadoop本地文件格式,使用先进的列式存储、索引、压缩和编码技术,以提高计算效率,有助于加速超过PB数量级的数据查询,可用于更快的交互查询。同时,CarbonData也是一种将数据源与Spark集成的高性能分析引擎。
本文分享自华为云社区《【云小课】EI第40课 MRS基础原理之CarbonData入门》,作者:Hello EI 。
CarbonData是一种新型的Apache Hadoop本地文件格式,使用先进的列式存储、索引、压缩和编码技术,以提高计算效率,有助于加速超过PB数量级的数据查询,可用于更快的交互查询。同时,CarbonData也是一种将数据源与Spark集成的高性能分析引擎。

使用CarbonData的目的是对大数据即席查询提供超快速响应。从根本上说,CarbonData是一个OLAP引擎,采用类似于RDBMS中的表来存储数据。用户可将大量(10TB以上)的数据导入以CarbonData格式创建的表中,CarbonData将以压缩的多维索引列格式自动组织和存储数据。数据被加载到CarbonData后,就可以执行即席查询,CarbonData将对数据查询提供秒级响应。
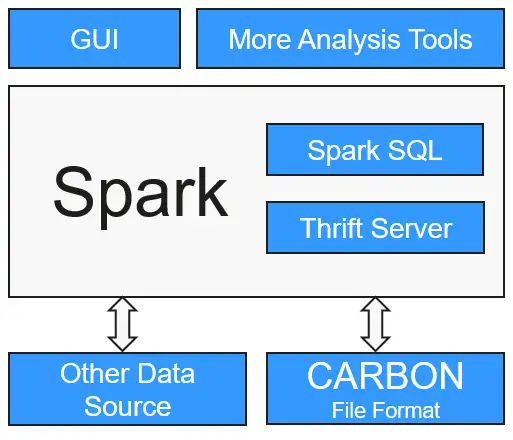
CarbonData将数据源集成到Spark生态系统,用户可使用Spark SQL执行数据查询和分析。也可以使用Spark提供的第三方工具JDBCServer连接到Spark SQL。
本文以从CSV文件加载数据到CarbonData Table为例,介绍创建CarbonData table、加载数据,以及查询数据的快速入门流程。
使用CarbonData需要安装Spark2x组件,并安装Spark2x的客户端。
准备加载到CarbonData Table的CSV文件。
1.在本地准备CSV文件,文件名为:test.csv。
13418592122,1001,MAC地址,2017-10-23 15:32:30,2017-10-24 15:32:30,62.50,74.56
13418592123,1002,MAC地址,2017-10-23 16:32:30,2017-10-24 16:32:30,17.80,76.28
13418592124,1003,MAC地址,2017-10-23 17:32:30,2017-10-24 17:32:30,20.40,92.94
13418592125,1004,MAC地址,2017-10-23 18:32:30,2017-10-24 18:32:30,73.84,8.58
13418592126,1005,MAC地址,2017-10-23 19:32:30,2017-10-24 19:32:30,80.50,88.02
13418592127,1006,MAC地址,2017-10-23 20:32:30,2017-10-24 20:32:30,65.77,71.24
13418592128,1007,MAC地址,2017-10-23 21:32:30,2017-10-24 21:32:30,75.21,76.04
13418592129,1008,MAC地址,2017-10-23 22:32:30,2017-10-24 22:32:30,63.30,94.40
13418592130,1009,MAC地址,2017-10-23 23:32:30,2017-10-24 23:32:30,95.51,50.17
13418592131,1010,MAC地址,2017-10-24 00:32:30,2017-10-25 00:32:30,39.62,99.132.将CSV文件导入客户端节点,例如“/opt”目录下。
3.进入客户端目录,上传CSV文件到HDFS的“/data”目录下:
cd /opt/client
source ./bigdata_env
source ./Spark2x/component_env
kinit sparkuser
hdfs dfs -put /opt/test.csv /data/在对CarbonData进行任何一种操作之前,首先需要连接到CarbonData。
cd ./Spark2x/spark/bin
./spark-beeline在Spark Beeline被连接到JDBCServer之后,需要创建一个CarbonData table用于加载数据和执行查询操作。
例如下面是创建一个简单的表的命令:
create table x1 (imei string, deviceInformationId int, mac string, productdate timestamp, updatetime timestamp, gamePointId double, contractNumber double) STORED AS carbondata TBLPROPERTIES ('SORT_COLUMNS'='imei,mac');命令执行结果如下:
+---------+
| Result |
+---------+
+---------+
No rows selected (1.093 seconds)创建CarbonData table之后,可以从CSV文件加载数据到所创建的表中。
表的列名需要与CSV文件的列名匹配。
LOAD DATA inpath 'hdfs://hacluster/data/test.csv' into table x1 options('DELIMITER'=',', 'QUOTECHAR'='"','FILEHEADER'='imei, deviceinformationid,mac, productdate,updatetime, gamepointid,contractnumber');其中,“test.csv”为准备的CSV文件,“x1”为示例的表名。
命令执行结果如下:
+------------+
|Segment ID |
+------------+
|0 |
+------------+
No rows selected (3.039 seconds)创建CarbonData table并加载数据之后,可以执行所需的数据查询操作。以下为一些查询操作举例。
为了获取在CarbonData table中的记录数,可以运行以下命令。
select count(*) from x1;为了获取不重复的deviceinformationid记录数,可以运行以下命令。
select deviceinformationid,count (distinct deviceinformationid) from x1 group by deviceinformationid;为了获取特定deviceinformationid的记录,可以运行以下命令。
select * from x1 where deviceinformationid='1010';在执行数据查询操作后,如果查询结果中某一列的结果含有中文字等非英文字符,会导致查询结果中的列不能对齐,这是由于不同语言的字符在显示时所占的字宽不尽相同。
创建CarbonData table并加载数据之后,可以执行所需的查询操作,例如filters,groupby等。
用户若需要在Spark-shell上使用CarbonData,需通过如下方式创建CarbonData Table,加载数据到CarbonData Table和在CarbonData中查询数据的操作。
spark.sql("CREATE TABLE x2(imei string, deviceInformationId int, mac string, productdate timestamp, updatetime timestamp, gamePointId double, contractNumber double) STORED AS carbondata")
spark.sql("LOAD DATA inpath 'hdfs://hacluster/data/x1_without_header.csv' into table x2 options('DELIMITER'=',', 'QUOTECHAR'='\"','FILEHEADER'='imei, deviceinformationid,mac, productdate,updatetime, gamepointid,contractnumber')")
spark.sql("SELECT * FROM x2").show好了,本期云小课就介绍到这里,快去体验MapReduce(MRS)更多功能吧!猛戳这里
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
(本文是网络的宏观的概念铺垫)目录计算机网络背景网络发展认识"协议"网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型报头以太网碰撞路由器IP地址和MAC地址IP地址与MAC地址总结IP地址MAC地址计算机网络背景网络发展 是最开始先有的计算机,计算机后来因为多项技术的水平升高,逐渐的计算机变的小型化、高效化。后来因为计算机其本身的计算能力比较的快速:独立模式:计算机之间相互独立。 如:有三个人,每个人做的不同的事物,但是是需要协作的完成。 而这三个人所做的事是需要进行协作的,然而刚开始因为每一台计算机之间都是互相独立的。所以前面的人处理完了就需要将数据
文章目录1.任务背景2.任务目标3.相关知识点4.任务实操4.1安装配置JDK4.2启动FISCOBCOS4.3下载解压WeBASE-Front4.4拷贝sdk证书文件4.5启动节点4.6访问节点4.7检查运行状态5.任务总结1.任务背景FISCOBCOS其实是有控制台管理工具,用来对区块链系统进行各种管理操作。但是对于初学者来说,还是可视化界面更友好,本节就来介绍WeBASE管理平台,这是一款微众银行开源的自研区块链中间件平台,可以降低区块链使用的门槛,大幅提高区块链应用的开发效率。微众银行是腾讯牵头设立的民营银行,在国内民营银行里还是比较出名的。微众银行参与FISCOBCOS生态建设,一定
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记