代码心得:
1、计算链表节点个数:
f1. 封装计算链表节点个数的API: int getLinkNodeNum(struct Test *head); 形参head用来接收链表头
f1.1 while,控制循环的变量是链表头head,当head!=NULL 时,进入循环
//内在逻辑:当结构体指针head不等于NULL时,说明没有访问到链表尾巴的后面
f1.1.1 修改代表节点个数的变量cnt: cnt++; //注意一开始要将cnt初始化成0
f1.1.2 修改代表节点的循环变量head,让head往后走: head = head->next;
f1.2 返回代表节点个数的变量cnt
#include <stdio.h>
struct Test
{
int idata;
struct Test *next;
};
int getLinkNodeNum(struct Test *head);
int main(int argc, char const *argv[])
{
int cnt = 0;
struct Test t1 = {1,NULL};
struct Test t2 = {2,NULL};
struct Test t3 = {3,NULL};
struct Test t4 = {4,NULL};
t1.next = &t2;
t2.next = &t3;
t3.next = &t4;
cnt = getLinkNodeNum(&t1);
printf("node numbers: %d\n", cnt);
return 0;
}
int getLinkNodeNum(struct Test *head)
{
int cnt = 0;
while(head != NULL){
cnt++;
head = head->next;
}
return cnt;
}
f1. 封装链表查找的API: int searchLink(struct Test *head, int idata);
形参head用来接收链表头,形参idata是想要找的整型数据
f1.1 while,控制循环的变量是链表头head,当head!=NULL 时,进入循环
//内在逻辑:当结构体指针head不等于NULL时,说明没有访问到链表尾巴的后面
f1.1.1 通过结构体指针间接访问成员变量idata,判断head->idata是否等于idata
f1.1.1.1 如果是,
那么,返回1
f1.1.2 修改代表节点的循环变量head,让head往后走: head = head->next;
f1.2 返回0
//内在逻辑:如果顺利通过f1.1,说明没有提前退出循环,也就是没找到idata
#include <stdio.h>
struct Test
{
int idata;
struct Test *next;
};
int searchLink(struct Test *head, int idata);
int main(int argc, char const *argv[])
{
struct Test t1 = {1,NULL};
struct Test t2 = {2,NULL};
struct Test t3 = {3,NULL};
struct Test t4 = {4,NULL};
t1.next = &t2;
t2.next = &t3;
t3.next = &t4;
if(searchLink(&t1, 5)){
puts("找到了");
}else{
puts("没找到");
}
return 0;
}
int searchLink(struct Test *head, int idata)
{
while(head != NULL){
if(head->idata == idata){
return 1;
}
head = head->next;
}
return 0;
}
代码心得:
知识点:插入新节点有两种方式,每种方式中修改节点指向时,需要注意赋值的顺序
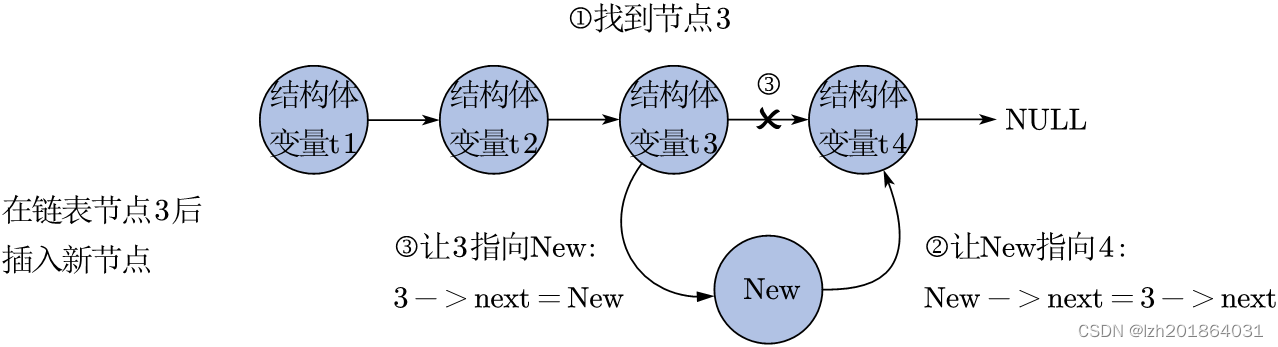
1、节点后插入的方式:
f1. 封装在链表某节点后插入新节点的API:
int inserFromBehind(struct Test *head, int nodePosition, struct Test *new);
形参head用来接收链表头,形参nodePosition代表想要在第几个节点后插入,形参new代表新节点
f1.1 新定义一个代表节点的结构体指针变量p,用来保存链表头head
f1.2 while循环,控制循环的变量是链表头p,当p!=NULL 时,进入循环,找出位置插入新节点new
//内在逻辑:当结构体指针head不等于NULL时,说明没有访问到链表尾巴的后面
f1.2.1 通过结构体指针间接访问成员变量node(node代表当前第几个节点),
判断 p->node 是否等于nodePosition
f1.2.1.1 如果是,
f1.2.1.1.1 修改代表找到设定节点位置nodePosition的变量flag: flag = 1;
//内在逻辑:用flag=1代表找到了位置插入,flag=0代表没有找到位置插入,可以初始化成0
f1.2.1.1.2 让节点new先指向节点p原先的指向: new->next = p->next;
f1.2.1.1.3 让节点p指向节点new,断开节点p和它原先后面节点的连接
f1.2.1.1.4 修改节点new中的成员node: new->node = nodePosition + 1;
//内在逻辑:找到可插入位置并插入后,把代表节点编号的node成员变量修改一下
f1.2.1.1.5 插入成功后,提前退出循环,不急着退出函数,一会来改后面节点的node
f1.2.1.2 修改代表节点的循环变量p,让p往后走: p = p->next;
f1.3 判断代表找到设定节点位置nodePosition的变量flag是否等于1
//内在逻辑:插入成功后,在return 1之前,修改新插入节点后面节点的节点位置标志node,让它们加1。
f1.3.1 如果是,接下来让new节点后面的节点中的node成员变量自增1
f1.3.1.1 修改代表节点的变量p,让p往后走: p = p->next;
f1.3.1.2 修改代表节点的变量p,让p往后走: p = p->next;
//内在逻辑:两次往后走是因为想跳过新插入的节点
f1.3.1.3 while循环,控制循环的变量p,当p!=NULL 时,进入循环
f1.3.1.3.1 修改循环变量p中的node成员变量,自增1: p->node = p->node + 1;
f1.3.1.3.2 修改代表节点的循环变量p,让p往后走: p = p->next;
f1.3.1.4 修改完毕,返回1,结束函数。
f1.3.2 否则,代表插入失败(比如新节点插入的位置输入的过大)
那么,返回0
#include <stdio.h>
struct Test
{
int node;
struct Test *next;
};
void printLink(struct Test *head);
int inserFromBehind(struct Test *head, int nodePosition, struct Test *new);
int main(int argc, char const *argv[])
{
struct Test t1 = {1,NULL};
struct Test t2 = {2,NULL};
struct Test t3 = {3,NULL};
struct Test t4 = {4,NULL};
t1.next = &t2;
t2.next = &t3;
t3.next = &t4;
struct Test new = {0,NULL}; //新插入的节点new的指向要设置成NULL
int nodePosition;
puts("插入新节点以前");
printLink(&t1);
puts("请输入在哪个节点后插入新节点");
scanf("%d", &nodePosition);
inserFromBehind(&t1, nodePosition, &new);
puts("插入新节点以后");
printLink(&t1);
return 0;
}
void printLink(struct Test *head)
{
while(head != NULL){
printf("%d ", head->node);
head = head->next;
}
putchar('\n');
}
int inserFromBehind(struct Test *head, int nodePosition, struct Test *new)
{
struct Test *p = head;
int flag = 0;
while(p != NULL){
if(p->node == nodePosition){
flag = 1;
new->next = p->next;
p->next = new;
new->node = nodePosition + 1;
break;
}
p = p->next;
}
if(flag == 1){
p = p->next;
p = p->next;
while(p != NULL){
p->node = p->node + 1;
p = p->next;
}
return 1;
}else{
return 0;
}
}
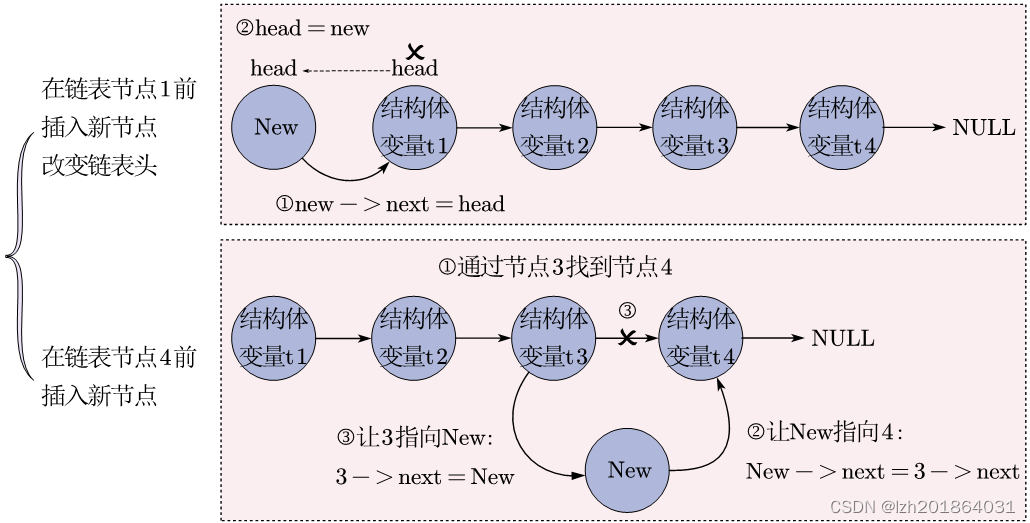
2、节点前插入的方式:
f1. 封装在链表某节点前插入新节点的API:
struct Test* inserFromFront(struct Test *head, int nodePosition, struct Test *new);
形参head用来接收链表头,形参nodePosition代表想要在第几个节点前插入,形参new代表新节点,
返回值是结构体指针,用来修改main函数的链表头head
f1.1 新定义一个代表节点的结构体指针变量p,用来保存链表头head
f1.2 判断是否要在第一个节点前插入新节点,
f1.2.1 如果是,说明链表头需要改动
f1.2.1.1 让新节点指向旧链表头,让节点new成为新链表头: new->next = head;
f1.2.1.2 修改节点new的node为1: new->node = 1;
f1.2.1.3 while循环,控制循环的变量p,当p!=NULL 时,进入循环,把后面所有节点的node+1
f1.2.1.3.1 从节点p开始,也就是从旧链表头开始,修改node: p->node = p->node + 1;
f1.2.1.3.2 修改代表节点的循环变量p,让p往后走: p = p->next;
f1.2.1.4 返回new节点,提前结束函数: return new;
f1.3 while循环,控制循环的变量是链表头p,当p->next!=NULL 时,进入循环,找出位置插入新节点new
//内在逻辑1:如果跳过了f1.2,那么说明不用修改链表头,接下来就正常插入
//内在逻辑2:因为我们希望通过设定节点的上一个节点来找设定节点,不能等到p移到设定节点的位置才插入
f1.3.1 通过前一个节点访问后一个节点的node,判断 p->next->node 是否等于nodePosition
f1.3.1.1 如果是,
f1.3.1.1.1 修改代表找到设定节点位置nodePosition的变量flag: flag = 1;
//内在逻辑:用flag=1代表找到了位置插入,flag=0代表没有找到位置插入,flag初始化成0
f1.3.1.1.2 让节点new先指向节点p原先的指向: new->next = p->next;
f1.3.1.1.3 让节点p指向节点new,断开节点p和它原先后面节点的连接: p->next = new;
f1.3.1.1.4 修改节点new的node: new->node = nodePosition;
//内在逻辑:找到可插入位置并插入后,把代表节点编号的node成员变量修改一下
f1.3.1.1.5 插入成功后,提前退出循环,不急着退出函数,一会来改后面节点的node
f1.3.1.2 修改代表节点的循环变量p,让p往后走: p = p->next;
f1.4 判断代表找到设定节点位置nodePosition的变量flag是否等于1
//内在逻辑:插入成功后,在return head之前,修改新插入节点后面节点的node,让它们加1。
f1.4.1 如果是,接下来让new节点后面的节点中的node成员变量自增1
f1.4.1.1 修改代表节点的变量p,让p往后走: p = p->next;
f1.4.1.2 修改代表节点的变量p,让p往后走: p = p->next;
//内在逻辑:两次往后走是因为想跳过新插入的节点
f1.4.1.3 while循环,控制循环的变量p,当p!=NULL 时,进入循环
f1.4.1.3.1 修改循环变量p中的node成员变量,自增1: p->node = p->node + 1;
f1.4.1.3.2 修改代表节点的循环变量p,让p往后走: p = p->next;
f1.4.1.4 修改完毕,返回head,结束函数。
//内在逻辑,不需要修改链表头时,直接返回原先的链表头即可
f1.4.2 否则,代表插入失败(比如新节点插入的位置输入的过大)
那么,返回head
//内在逻辑:即使插入失败,我们也不希望链表头发生改变
#include <stdio.h>
struct Test
{
int node;
struct Test *next;
};
void printLink(struct Test *head);
struct Test* inserFromFront(struct Test *head, int nodePosition, struct Test *new);
int main(int argc, char const *argv[])
{
struct Test *head;
struct Test t1 = {1,NULL};
struct Test t2 = {2,NULL};
struct Test t3 = {3,NULL};
struct Test t4 = {4,NULL};
t1.next = &t2;
t2.next = &t3;
t3.next = &t4;
head = &t1;
struct Test new = {0,NULL};
int nodePosition;
puts("插入新节点以前");
printLink(head);
puts("请输入在哪个节点前插入新节点");
scanf("%d", &nodePosition);
head = inserFromFront(head, nodePosition, &new);
puts("插入新节点以后");
printLink(head);
return 0;
}
void printLink(struct Test *head)
{
while(head != NULL){
printf("%d ", head->node);
head = head->next;
}
putchar('\n');
}
struct Test* inserFromFront(struct Test *head, int nodePosition, struct Test *new)
{
int flag = 0;
struct Test *p = head;
if(nodePosition == 1){
new->next = head;
new->node = 1;
while(p != NULL){
p->node = p->node + 1;
p = p->next;
}
return new;
}
while(p->next != NULL){
if(p->next->node == nodePosition){
flag = 1;
new->next = p->next;
p->next = new;
new->node = nodePosition;
break;
}
p = p->next;
}
if(flag == 1){
p = p->next;
p = p->next;
while(p != NULL){
p->node = p->node + 1;
p = p->next;
}
return head;
}else{
puts("插入失败");
return head;
}
}
代码心得:
知识点:
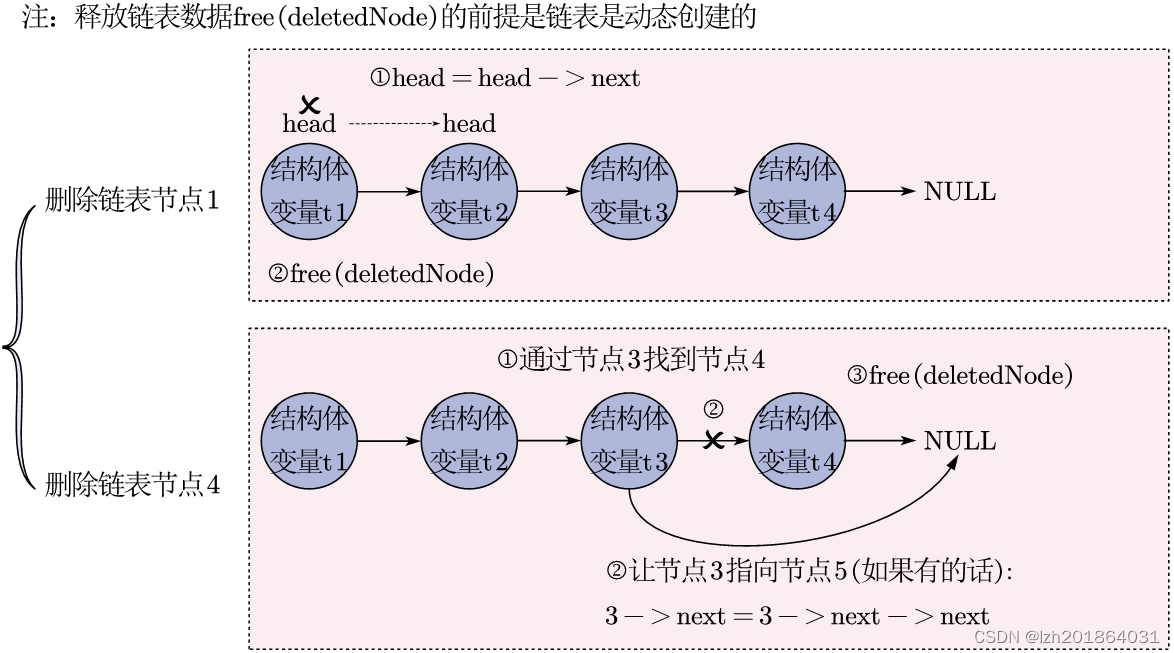
1、删除链表节点的方式:
f1. 封装删除静态链表某节点的API: struct Test* delNode(struct Test *head, int nodePosition);
形参head用来接收链表头,形参nodePosition代表想要删除第几个,
返回值是结构体指针,用来修改main函数的链表头head
f1.1 新定义一个代表节点的结构体指针变量p,用来保存链表头head
f1.2 判断是否删除的是第1个节点
f1.2.1 如果是,说明链表头需要改动
f1.2.1.1 修改链表头的指向,让head指向节点2: head = head->next;
f1.2.1.2 将节点p移动到新链表头,接下来准备修改往后各个节点的node: p = head;
f1.2.1.3 while循环,控制循环的变量p,当p!=NULL 时,进入循环,把后面所有节点的node-1
f1.2.1.3.1 从节点p开始,也就是从新链表头开始,修改node: p->node = p->node - 1;
f1.2.1.3.2 修改代表节点的循环变量p,让p往后走: p = p->next;
f1.2.1.4 返回节点head,提前结束函数: return new;
f1.3 while循环,控制循环的变量是链表头p,当p->next!=NULL 时,进入循环,找出位置插入新节点new
//内在逻辑1:如果跳过了f1.2,那么说明不用修改链表头,接下来就正常删除
//内在逻辑2:因为我们希望通过设定节点的上一个节点来找设定节点,不能等到p移到设定节点的位置才删除
f1.3.1 通过前一个节点访问后一个节点的node,判断 p->next->node 是否等于nodePosition
f1.3.1.1 如果是,
f1.3.1.1.1 修改代表找到设定节点位置nodePosition的变量flag: flag = 1;
//内在逻辑:用flag=1代表找到了位置删除,flag=0代表没有找到位置删除,flag初始化成0
f1.3.1.1.2 让节点p指向设定删除节点的后一个节点,断开节点p和它原先后面节点的连接:
p->next = p->next->next;
f1.3.1.1.3 删除成功后,提前退出循环,不急着退出函数,一会来改后面节点的node
f1.3.1.2 修改代表节点的循环变量p,让p往后走: p = p->next;
f1.4 判断代表找到设定节点位置nodePosition的变量flag是否等于1
//内在逻辑:删除成功后,在return head之前,修改被删除节点后面节点的node,让它们减1。
f1.4.1 如果是,接下来让被删节点后面的节点中的node成员变量自减1
f1.4.1.1 修改代表节点的变量p,让p往后走: p = p->next;
//内在逻辑:比如说删除节点4之后,那么就从节点3跳到节点5,从原先的节点5位置开始修改node
f1.4.1.2 while循环,控制循环的变量p,当p!=NULL 时,进入循环
f1.4.1.3.1 修改循环变量p中的node成员变量,自减1: p->node = p->node - 1;
f1.4.1.3.2 修改代表节点的循环变量p,让p往后走: p = p->next;
f1.4.1.4 修改完毕,返回head,结束函数。
//内在逻辑,不需要修改链表头时,直接返回原先的链表头即可
f1.4.2 否则,代表删除失败(比如被删节点的位置输入的过大)
那么,返回head
//内在逻辑:即使删除失败,我们也不希望链表头发生改变
#include <stdio.h>
struct Test
{
int node;
struct Test *next;
};
void printLink(struct Test *head);
struct Test* delNode(struct Test *head, int nodePosition);
int main(int argc, char const *argv[])
{
struct Test *head;
struct Test t1 = {1,NULL};
struct Test t2 = {2,NULL};
struct Test t3 = {3,NULL};
struct Test t4 = {4,NULL};
t1.next = &t2;
t2.next = &t3;
t3.next = &t4;
head = &t1;
int nodePosition;
puts("删除节点以前");
printLink(head);
puts("请输入删除哪个节点");
scanf("%d", &nodePosition);
head = delNode(head, nodePosition);
puts("删除节点以后");
printLink(head);
return 0;
}
void printLink(struct Test *head)
{
while(head != NULL){
printf("%d ", head->node);
head = head->next;
}
putchar('\n');
}
struct Test* delNode(struct Test *head, int nodePosition)
{
int flag = 0;
struct Test *p = head;
if(nodePosition == 1){
head = head->next;
p = head;
while(p != NULL){
p->node = p->node - 1;
p = p->next;
}
return head;
}
while(p->next != NULL){
if(p->next->node == nodePosition){
flag = 1;
p->next = p->next->next;
break;
}
p = p->next;
}
if(flag == 1){
p = p->next;
while(p != NULL){
p->node = p->node - 1;
p = p->next;
}
return head;
}else{
puts("删除失败");
return head;
}
}
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
这个问题在这里已经有了答案:Checktoseeifanarrayisalreadysorted?(8个答案)关闭9年前。我只是想知道是否有办法检查数组是否在增加?这是我的解决方案,但我正在寻找更漂亮的方法:n=-1@arr.flatten.each{|e|returnfalseife
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
尝试在我的RoR应用程序中实现计数器缓存列时出现错误Unknownkey(s):counter_cache。我在这个问题中实现了模型关联:Modelassociationquestion这是我的迁移:classAddVideoVotesCountToVideos0Video.reset_column_informationVideo.find(:all).eachdo|p|p.update_attributes:videos_votes_count,p.video_votes.lengthendenddefself.downremove_column:videos,:video_vot
我正在尝试按0-9和a-z的顺序创建数字和字母列表。我有一组值value_array=['0','1','2','3','4','5','6','7','8','9','a','b','光盘','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','','u','v','w','x','y','z']和一个组合列表的数组,按顺序,这些数字可以产生x个字符,比方说三个list_array=[]和一个当前字母和数字组合的数组(在将它插入列表数组之前我会把它变成一个字符串,]current_combo['0','0','0']
在Ruby中是否有Gem或安全删除文件的方法?我想避免系统上可能不存在的外部程序。“安全删除”指的是覆盖文件内容。 最佳答案 如果您使用的是*nix,一个很好的方法是使用exec/open3/open4调用shred:`shred-fxuz#{filename}`http://www.gnu.org/s/coreutils/manual/html_node/shred-invocation.html检查这个类似的帖子:Writingafileshredderinpythonorruby?