docker pull nacos/nacos-server:v2.1.2
docker run -d --name nacos -p 8848:8848 -e MODE=standalone nacos/nacos-server:v2.1.2
查看运行过程:docker logs -f nacos
ps:如果启动失败可能是服务器内存过小,如果要限制nacos 占用的内存大小,使用以下语句
docker run --name nacos -e JVM_XMS=256m -e JVM_XMX=256m -e MODE=standalone -p 8848:8848 -d nacos/nacos-server:v2.1.2
安装后也可以修改容器的内存大小 :
docker stop nacos
docker update -m 256M --memory-swap 512M nacos-quick
docker start nacos
docker cp nacos:/home/nacos /usr/local
ps:nacos在docker中的默认存放位置为/home/nacos
docker rm -f nacos
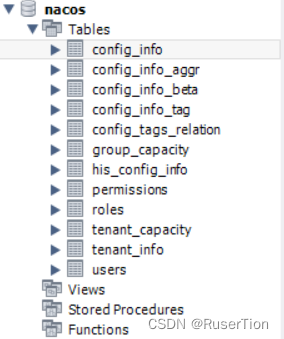
找到/usr/local/nacos/config下的mysql-schema.sql文件,复制里面的内容在mysql中运行,然后会自动生成数据表
docker run -d --name nacos \
-p 8848:8848 \
-p 9848:9848 \
-p 9849:9849 \
–restart always \
-v /usr/local/nacos/logs:/home/nacos/logs \
-v /usr/local/nacos/data:/home/nacos/data \
-v /usr/local/nacos/config:/home/nacos/config \
-e MODE=standalone \
-e SPRING_DATASOURCE_PLATFORM=mysql \
-e MYSQL_SERVICE_HOST=数据库所在ip \
-e MYSQL_SERVICE_PORT=3306 \
-e MYSQL_SERVICE_DB_NAME=nacos \
-e MYSQL_SERVICE_USER=root \
-e MYSQL_SERVICE_PASSWORD=数据库密码 \
nacos/nacos-server:v2.1.2
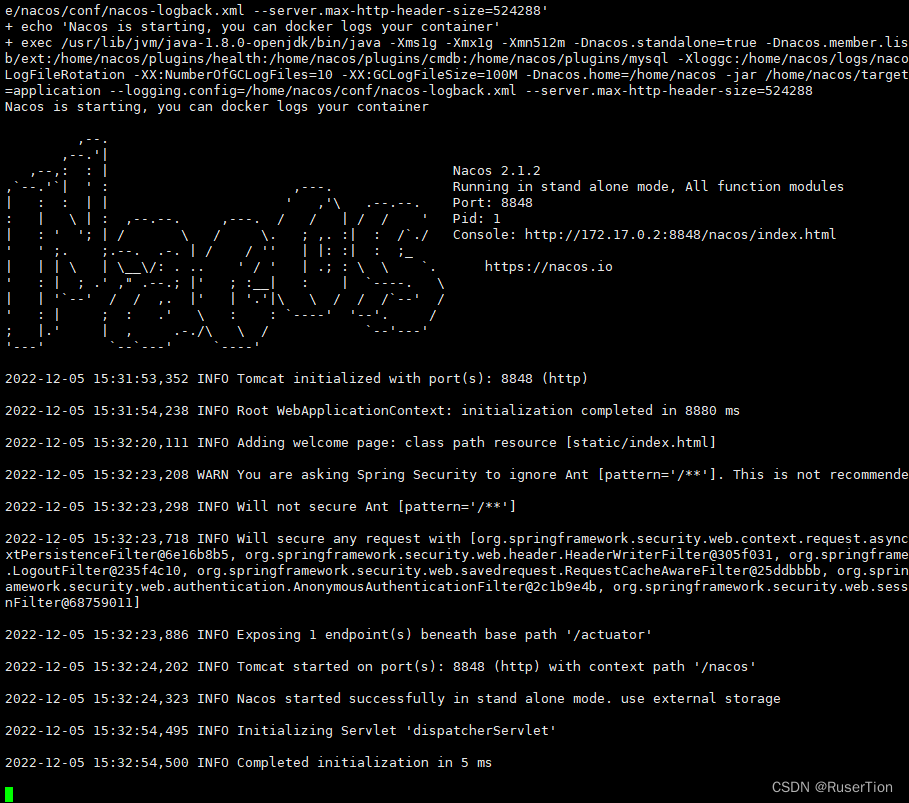
查看运行过程:docker logs -f nacos
nacos1
docker run -d --name nacos-cluster \
-p 8848:8848 \
-p 9848:9848 \
-p 9849:9849 \(9848、9849为nacos2.X新增端口,不加的话SpringBoot服务会注册失败)
–net host \(从桥接模式改成主机模式,用主机的ip地址,不然注册服务可能会出错)
–restart always \(前面为两个短杠,记得修改)
-v /usr/local/nacos/logs:/home/nacos/logs \
-v /usr/local/nacos/data:/home/nacos/data \
-v /usr/local/nacos/config:/home/nacos/config \
-e MODE=cluster \
-e NACOS_SERVERS=192.168.137.133:8848 \(此处为指向其他集群服务的ip地址,如果有多个ip则用单引号括起来)
-e SPRING_DATASOURCE_PLATFORM=mysql \
-e MYSQL_SERVICE_HOST=192.168.137.134 \
-e MYSQL_SERVICE_PORT=3306 \
-e MYSQL_SERVICE_DB_NAME=nacos \
-e MYSQL_SERVICE_USER=root \
-e MYSQL_SERVICE_PASSWORD=数据库密码 \
-e TZ=Asia/Shanghai \(不加时间注册服务时可能会报错)
nacos/nacos-server:v2.1.2
nacos2
docker run -d --name nacos-cluster \
-p 8848:8848 \
-p 9848:9848 \
-p 9849:9849 \(9848、9849为nacos2.X新增端口,不加的话SpringBoot服务会注册失败)
–net host \(从桥接模式改成主机模式,用主机的ip地址,不然注册服务可能会出错)
–restart always \(前面为两个短杠,记得修改)
-v /usr/local/nacos/logs:/home/nacos/logs \
-v /usr/local/nacos/data:/home/nacos/data \
-v /usr/local/nacos/config:/home/nacos/config \
-e MODE=cluster \
-e NACOS_SERVERS=192.168.137.134:8848 \(此处为指向其他集群服务的ip地址,如果有多个ip则用单引号括起来)
-e SPRING_DATASOURCE_PLATFORM=mysql \
-e MYSQL_SERVICE_HOST=192.168.137.134 \
-e MYSQL_SERVICE_PORT=3306 \
-e MYSQL_SERVICE_DB_NAME=nacos \
-e MYSQL_SERVICE_USER=root \
-e MYSQL_SERVICE_PASSWORD=数据库密码 \
-e TZ=Asia/Shanghai \(不加时间注册服务时可能会报错)
nacos/nacos-server:v2.1.2
后续有待补充。。。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情
这应该是一个简单的问题,但我找不到任何相关信息。给定一个Ruby中的正则表达式,对于每个匹配项,我需要检索匹配的模式$1、$2,但我还需要匹配位置。我知道=~运算符为我提供了第一个匹配项的位置,而string.scan(/regex/)为我提供了所有匹配模式。如果可能,我需要在同一步骤中获得两个结果。 最佳答案 MatchDatastring.scan(regex)do$1#Patternatfirstposition$2#Patternatsecondposition$~.offset(1)#Startingandendingpo