Redis作为一款简洁、高效的键值型内存数据库,2015年在G行引入,应用于多个业务系统,为高频次、大并发交易提供了有效的热点数据访问加速方案。
随着部署数量的加大,面临着资源快速供给、规范化部署、软件版本统一、集中运维管理等诸多挑战。为此,G行启动了分布式缓存平台建设项目,旨在打造一个具备快速部署、集中管理、弹性伸缩、服务高可用的缓存服务化平台。
基于G行全栈云IaaS层敏捷特性,通过对计算、存储、网络等资源的统一调度编排,实现缓存服务的快速部署和弹性伸缩,推出分布式缓存PaaS服务,助力应用系统敏捷开发。
通过统一控制台,实现Redis服务跨云集中管理;提供运行状态分析、慢查询分析、内存分析、统计数据展示、日常巡检等功能,协助运维人员进行缓存性能优化、故障快速定位和日常运维管理。实现运维向运营转型,提升精细化管理水平和服务化输出能力。
将Redis高可用架构与全栈云架构深度融合,感知底层架构,打造可用区容灾能力,实现故障快速感知和自动切换,提升Redis服务的高可用性和可维护性。
分布式缓存平台定位于服务开发、测试、运维人员,满足用户各种场景的使用需求:支持开发和测试人员自助申请服务资源,查看服务运行状态和资源使用情况,定位性能瓶颈;支持运维人员实现缓存全生命周期管理,包括配置变更、故障定位与处置、性能分析等;同时,支持对缓存服务整体情况进行多维度展示。基于此,分布式缓存平台包括七大功能模块:
门户模块:展示业务系统及纳管服务的整体情况,包括系统健康度、告警汇总、重点监控等内容。
监控模块:提供完善的监控告警能力,包括:将采集的运行指标进行多维度分析展示;支持用户自定义监控项及调整阈值;支持差异化告警策略的制定;支持历史告警详情查看。
运维和管理模块:将常规运维操作自动化,通过平台页面进行标准化操作,最大限度减少手工命令输入,预防误操作和减少不当操作的风险。
审计和日志模块:提供平台用户登录次数统计及操作记录审计功能。
统计模块:对日常关注的运营数据进行汇总展示,帮助运维人员快速了解服务整体运行情况和资源使用情况。
后台管理模块:实现平台的权限控制、定时任务管理、以及与关联系统的统一对接管理等。
技术支持模块:支持查阅用户手册和技术文档,提供问题反馈渠道,提升用户体验。
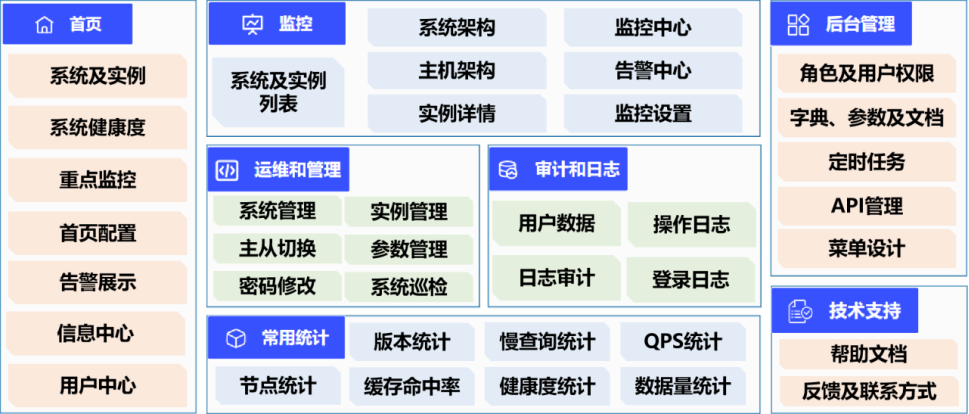
图1.功能架构图
2.1服务高可用
服务高可用从自动故障切换和物理容灾两方面进行设计。首先,通过Redis Sentinel和Redis Cluster支持缓存节点的故障感知和故障切换能力;同时,采用3AZ(可用区)物理部署方式,将同一组副本均匀部署在3个AZ中,提供AZ级别的高可用容灾能力。
2.2自动化部署
用户自助提交Redis服务需求,经管理员审批完成后,实现分钟级缓存服务交付。自动化部署打破了传统交付模式,覆盖了需求沟通、服务器资源申请、网络资源申请、安装部署、服务交付等流程。实现了Redis服务的快速和标准部署,同时大幅减少了人工运维成本,提升了整体运维效率和服务质量。
2.3运行分析
一方面,对Redis运行指标进行实时采集和分类展示,便于运维人员发现服务运行风险、进行服务性能优化及故障原因快速定位。
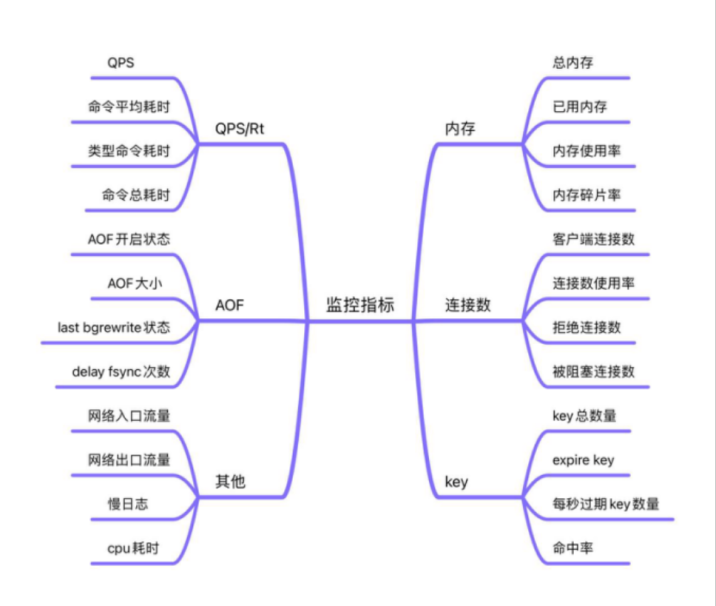
图2.监控指标项
另一方面,从业务系统维度展示Redis服务健康度。通过服务可用性、内存使用、连接数、慢日志等性能指标,建立服务健康度评分模型,方便运维人员全面掌握Redis运行情况、提高管控能力和管理效率。

图3.健康度分析
智能化运维集成了实例管理、参数修改、主从切换、系统巡检等功能,使常规运维操作自动化,复杂操作流程化,提升了运维操作、跟踪审计和执行能力。
实例管理支持对实例节点进行增加、删除、重启、命令查询操作。
参数修改支持对maxmemory、maxclients、requirepass等参数的在线修改,同时支持实例间的参数一致性对比校验。
主从切换支持一键完成主从切换,并支持批量操作和查看切换状态。
系统巡检通过每天定时任务生成业务系统巡检报告,包括资源使用情况、容量风险情况、基线合规情况等,并主动推送给相关人员。
分布式缓存平台主要面向数据库管理员、应用管理员、开发和测试人员,权限控制需要保证用户只能访问其负责的业务系统,同时保证具备合理的操作权限。平台基于RBAC(Role-based access control)模型实现权限控制,用户登录平台后,后台通过查询CMDB,获取用户关联的业务系统信息,为用户分配业务系统权限,同时查询用户角色信息,通过对不同角色授予对应权限,实现平台权限控制体系。
分布式缓存平台建设从G行实际出发,是实现技术服务化、运维向运营转型的重要举措,为业务快速发展提供了敏捷化、高可用的缓存服务,同时提升了缓存服务的运维效率和交付效率,降低了运维管理成本。未来,分布式缓存平台将在云原生方向持续探索,提供更高效可靠的缓存服务能力,为G行业务高质量发展提供更有力的支撑和保障。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我试过重新启动apache,缓存的页面仍然出现,所以一定有一个文件夹在某个地方。我没有“公共(public)/缓存”,那么我还应该查看哪些其他地方?是否有一个URL标志也可以触发此效果? 最佳答案 您需要触摸一个文件才能清除phusion,例如:touch/webapps/mycook/tmp/restart.txt参见docs 关于ruby-如何在Ubuntu中清除RubyPhusionPassenger的缓存?,我们在StackOverflow上找到一个类似的问题:
尝试在我的RoR应用程序中实现计数器缓存列时出现错误Unknownkey(s):counter_cache。我在这个问题中实现了模型关联:Modelassociationquestion这是我的迁移:classAddVideoVotesCountToVideos0Video.reset_column_informationVideo.find(:all).eachdo|p|p.update_attributes:videos_votes_count,p.video_votes.lengthendenddefself.downremove_column:videos,:video_vot
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
参见下面的示例,我想最好使用第二种方法,但第一种也可以。哪种方法最好,使用另一种的后果是什么?classTestdefstartp"started"endtest=Test.newtest.startendclassTest2defstartp"started"endendtest2=Test2.newtest2.start 最佳答案 我肯定会说第二种变体更有意义。第一个不会导致错误,但对象实例化完全过时且毫无意义。外部变量在类的范围内不可见:var="string"classAvar=A.newendputsvar#=>strin
如果我构建了一个应用程序来访问来自Gmail、Twitter和Facebook的一些数据,并且我希望用户只需输入一次他们的身份验证信息,并且在几天或几周后重置,那会怎样是在Ruby中动态执行此操作的最佳方法吗?我看到很多人只是拥有他们客户/用户凭证的配置文件,如下所示:gmail_account:username:myClientpassword:myClientsPassword这看起来a)非常不安全,b)如果我想为成千上万的用户存储此类信息,它就无法工作。推荐的方法是什么?我希望能够在这些服务之上构建一个界面,因此每次用户进行交易时都必须输入凭据是不可行的。
当我尝试进行bundle安装时,我的gem_path和gem_home指向/usr/local/rvm/gems/我没有写入权限,并且由于权限无效而失败。因此,我已将两个路径都更改为我具有写入权限的本地目录。这样做时,我进行了bundle安装,我得到:bruno@test6:~$bundleinstallFetchinggemmetadatafromhttps://rubygems.org/.........Fetchinggemmetadatafromhttps://rubygems.org/..Bundler::GemspecError:Couldnotreadgemat/afs/