目录
最近写了个项目,前端还没写,需要部署到服务器给女朋友实现前端,可是不熟悉Linux的我,蹑手蹑脚,真的是每一步都是bug,可谓是步步维艰,对世界很绝望,曾经怀疑自己的服务器有问题,甚至一度怀疑是自己的DaoBan IDE有问题,历时两天一夜,终于……部署好了。
1.购买一个服务器或者安装虚拟机(有点像废话)
2.安装docker(可以使用yum安装)
tips:安装好docker之后需要配置一下,输入下面这行代码,进入docker配置文件,在ExecStart=后添加配置,远程访问docker的端口为2375
sos:如果是服务器,这个修改后需要在服务器上面再配置一下这个端口号,不然ide会识别不出端口号,很重要(这个坑踩了很久,快陷进去了)

1.vim /lib/systemd/system/docker.service #输入,进到这个配置文件
2.-H tcp://0.0.0.0:2375 #复制粘贴这个
3.退出编辑界面:先按esc,然后":wq"退出
4.# 重启docker
systemctl daemon-reload
systemctl restart docker
3.到了第三步,说明咱们已经配置好docker了,现在需要在docker里面拉取MySQL映像
1.docker pull mysql:8.0(本人用8.0,需要什么版本号在后面改就好)
2.docker run -itd --name mysql -p 3306:3306-e MYSQL_ROOT_PASSWORD=root mysql:8.0
tips: 这一步也有个坑,如果你在安装docker之前,本地就安装了mysql,并且端口号也是3306,那必须让它处于关闭状态,否则会造成端口号冲突,windows的navigate或者小海豚就会连接不上虚拟机的mysql
4.到这一步,虚拟机的工作做完了,回到ide中,首先修改yml文件中mysql的连接地址,ip和端口号都需要改成虚拟机的,注意密码也要改哦。
其次呢,需要在pom文件添加docker-maven-plugin插件
<!-- docker-maven-plugin-->
<plugin>
<groupId>com.spotify</groupId>
<artifactId>docker-maven-plugin</artifactId>
<version>1.2.2</version>
<configuration>
<!-- Docker路径 -->
<dockerHost>http://虚拟机的ip:2375(刚开始设置的docker端口号)</dockerHost>
<!-- Dockerfile定义 -->
<baseImage>openjdk:11</baseImage>
<!-- 作者 -->
<maintainer>jackie</maintainer>
<resources>
<resource>
<!-- 复制jar包到docker容器指定目录 -->
<targetPath>/</targetPath>
<!-- 从哪个包拷贝文件,target包 -->
<directory>${project.build.directory}</directory>
<!-- 拷贝哪个文件 -->
<include>${project.build.finalName}.jar</include>
</resource>
</resources>
<workdir>/</workdir>
<entryPoint>
["java", "-jar", "${project.build.finalName}.jar"]
</entryPoint>
<forceTags>true</forceTags>
<!-- 镜像名 -->
<imageName>${project.artifactId}</imageName>
<!-- 镜像版本 -->
<imageTags>
<imageTag>${project.version}</imageTag>
</imageTags>
</configuration>
</plugin>
5.打包,先后顺序。
6.到这一步已经加载好docker插件了,打开这个插件,点一下build,如果运行最后显示BUID SUCESS,就说明成功传输package到虚拟机了,到虚拟机查看(这里如果不成功,大概率是2375那个端口号在服务器那里没有释放)
7.回到虚拟机,输入命令
docker images
如果看到

就成功了,现在来运行这个项目输入
docker run -d -p 80:80 项目名:0.0.1-SNAPSHOT
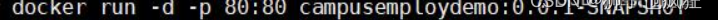
-d是后台运行,-p:绑定端口号 ,前面那个80是启动这个镜像对外暴露的端口(自定),第二个80是下载的镜像的端口(原项目端口) 。
接下来,查看自己的项目是否成功,输入命令,就会出现你的项目名字了,然后可以在本地浏览器查看一下项目。
docker ps
这个就是本次痛苦的历程,这种东西真的有点烦,需要有耐心,细心去一步一步操作,希望可以帮到你,不介意的话,可以点个赞哦。
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo