文章目录
hello,大家好!我是黄昏,我们一起来学运维。如果喜欢博客,点个赞,关注下哟
对linux 云计算|华为|华三|思科等数通方向感兴趣,可以私信博主,可以分享相关教程
欢迎大家一起学习交流。
今天主要介绍一款类似于堡垒机的运维工具—BT 宝塔面板。非常适合对linux 初学者使用。
欢迎大家一起学习、讨论哦!
-
宝塔Linux面板是提升运维效率的服务器管理软件,支持一键LAMP/LNMP/集群/监控/网站/FTP/数据库/JAVA等100多项服务器管理功能。
有30个人的专业团队研发及维护,经过200多个版本的迭代,功能全,少出错且足够安全,已获得全球百万用户认可安装。对于非专业的人士,如果想快速建站,宝塔是一个不错的选择,今天给大家分享一篇BT相关知识。让你轻松建站、管理。
系统环境
| 系统名称 | 系统地址 |
|---|---|
| CentOS Linux release 7.6.1810 (Core) | 10.0.0.91/24 |
环境准备
#关闭firewalld ,关闭开机自启动。
[root@bt_server01~]# systemctl disable firewalld --now
#关闭seLinux
[root@bt_server01~]# sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config
#安装网络yum 源,这里使用阿里云源
[root@bt_server01~]# ls /etc/yum.repos.d/
CentOS-Base.repo epel.repo hbs.repo.backup
这里是环境基础准备,关闭防火墙,关闭selinux ,配置好 yum 源(阿里镜像源)
可以参考bt官方教程
https://www.bt.cn/bbs/thread-19376-1-1.html
[root@bt_server01~]# yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh

记住安装密码
==================================================================
Congratulations! Installed successfully!
==================================================================
外网面板地址: http://117.136.53.180:8888/a1e03d58
内网面板地址: http://10.0.0.91:8888/a1e03d58
username: ipuynwwf
password: 955f431b
If you cannot access the panel,
release the following panel port [8888] in the security group
若无法访问面板,请检查防火墙/安全组是否有放行面板[8888]端口
==================================================================
Time consumed: 4 Minute!
bt 命令管理
[root@bt_server01/www/server/panel]# bt
===============宝塔面板命令行==================
(1) 重启面板服务 (8) 改面板端口
(2) 停止面板服务 (9) 清除面板缓存
(3) 启动面板服务 (10) 清除登录限制
(4) 重载面板服务 (11) 取消入口限制
(5) 修改面板密码 (12) 取消域名绑定限制
(6) 修改面板用户名 (13) 取消IP访问限制
(7) 强制修改MySQL密码 (14) 查看面板默认信息
(22) 显示面板错误日志 (15) 清理系统垃圾
(23) 关闭BasicAuth认证 (16) 修复面板(检查错误并更新面板文件到最新版)
(24) 关闭谷歌认证 (17) 设置日志切割是否压缩
(25) 设置是否保存文件历史副本 (18) 设置是否自动备份面板
(0) 取消
===============================================
请输入命令编号:5
===============================================
正在执行(5)...
===============================================
请输入新的面板密码:rivers
|-用户名: rivers_bt
|-新密码: rivers
停止/启动/重启宝塔服务
/etc/init.d/bt stop|stop|restart
站点相关目录
# 站点默认目录
/www/wwwroot
#数据库备份目录
/www/backup/database
#站点配置文件目录
/www/server
#站点备份目录
/www/backup/site
#站点日志
/www/wwwlogs
卸载bt 宝塔服务
/etc/init.d/bt stop && chkconfig --del bt && rm -f /etc/init.d/bt && rm -rf /www/server/panel
查看当前面板端口
cat /www/server/panel/data/port.pl
修改面板端口
#修改面板端口,如要改成8881(centos 6 系统
echo '8881' > /www/server/panel/data/port.pl && /etc/init.d/bt restart
#修改面板端口,如要改成8881(centos 7 系统)
echo '8881' > /www/server/panel/data/port.pl && /etc/init.d/bt restart
修改面板密码,如修改成123456
# 修改面板密码,如要改成123456
cd /www/server/panel && python tools.py panel 123456
宝塔使用手册:https://www.bt.cn/btcode.html
浏览器http://10.0.0.91:8888/a1e03d58

安装 lnmp 架构
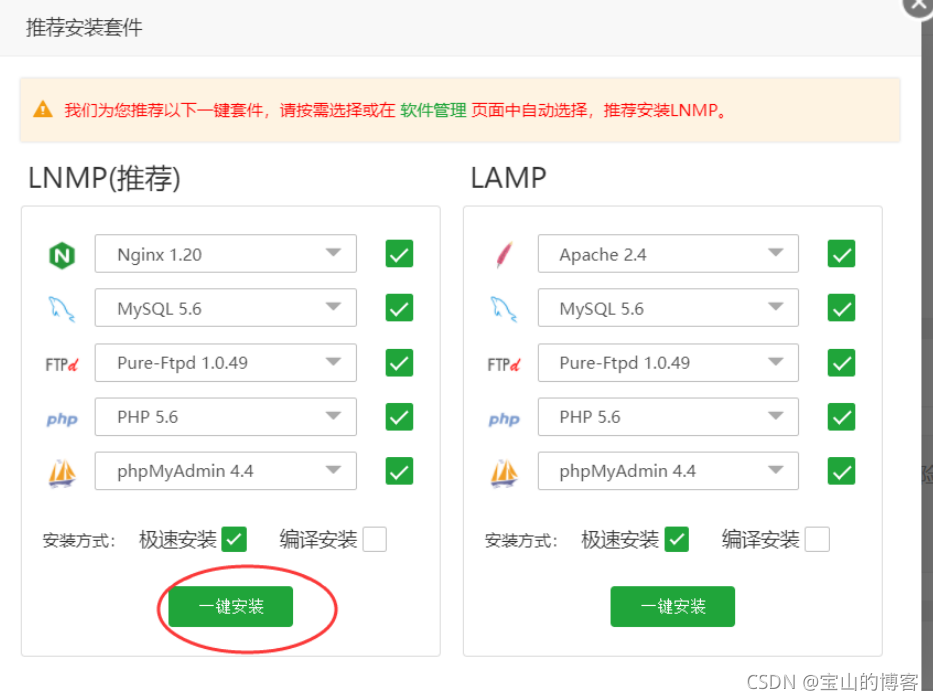
安装成功

快速建站,点击网站、添加站点

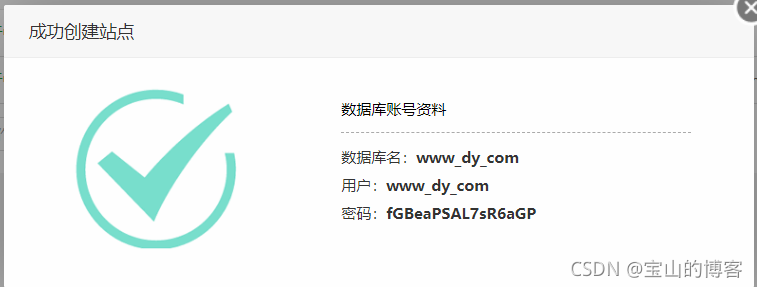
输入域名、安装mysql
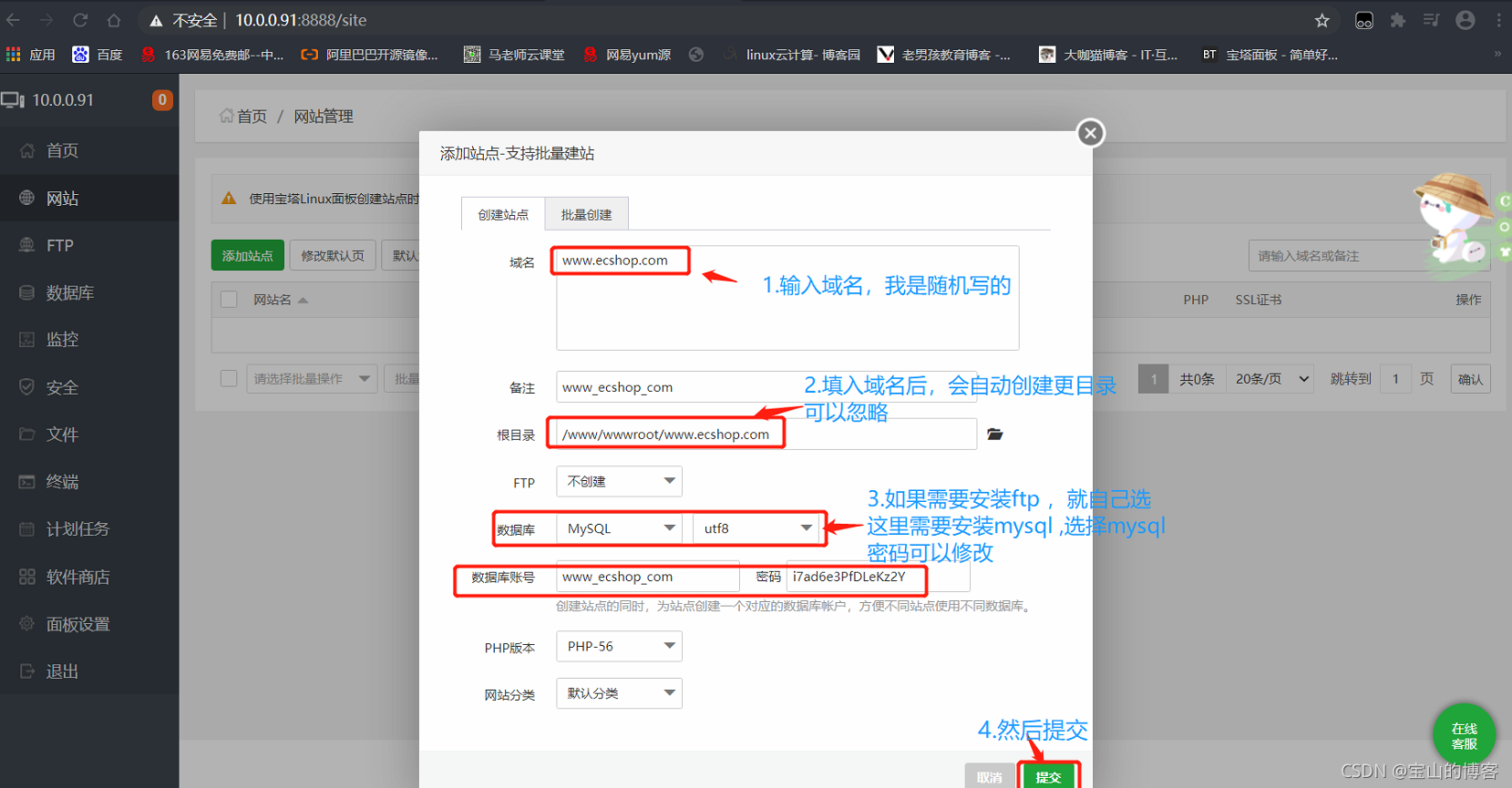
记录数据库账号、密码,防止后面忘了
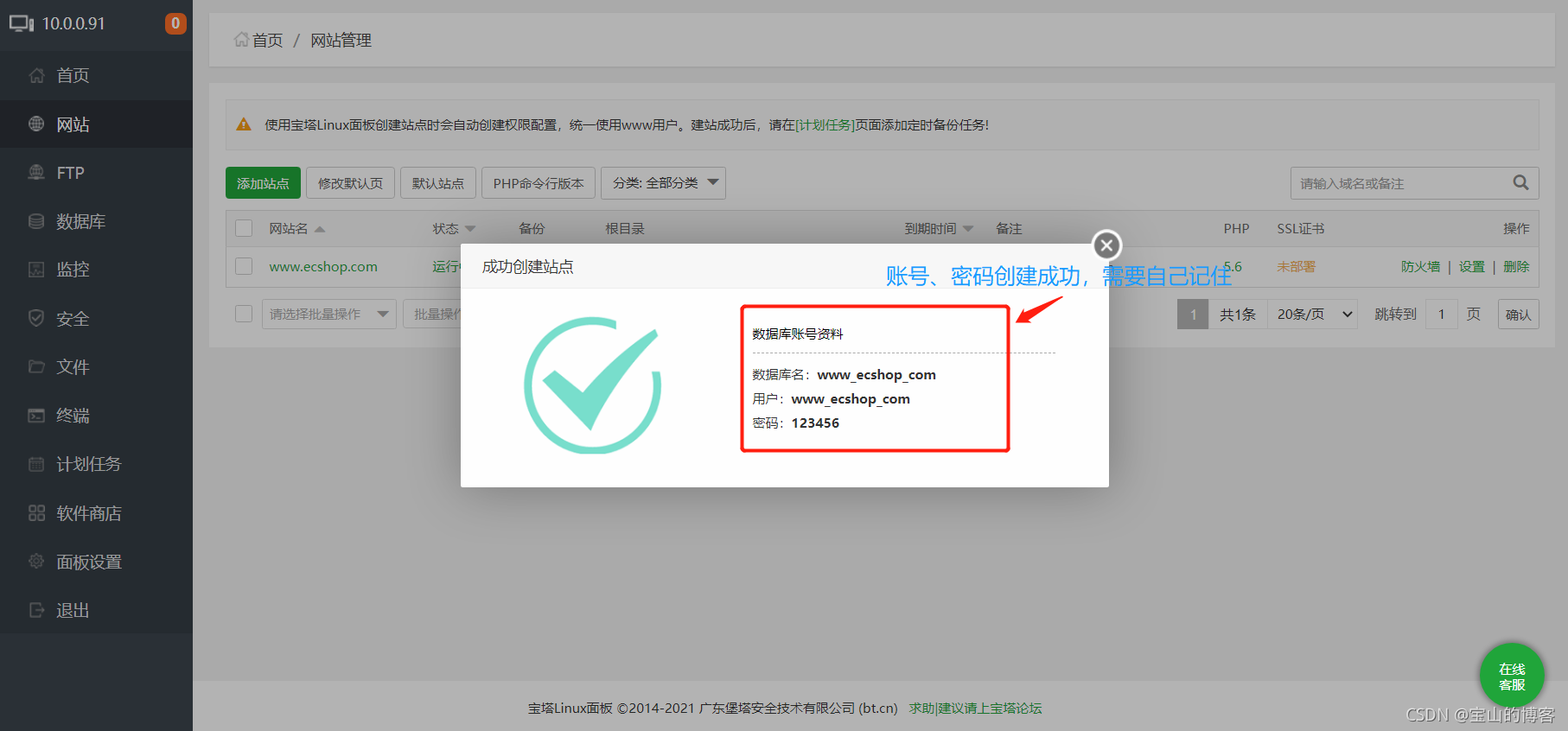
上传电商源代码、且部署
# 解压压缩包
[root@bt_server01~]# unzip ecshop.zip
[root@bt_server01~]# ls
anaconda-ks.cfg ecshop ecshop.zip install.sh
# 修改权限,默认属于www用户
[root@bt_server01~]# id www
uid=1001(www) gid=1001(www) groups=1001(www)
[root@bt_server01~]# chown -R www:www ecshop/*
# 将文件移动到 站点目录
[root@bt_server01~]# mv ecshop/* /www/wwwroot/www.ecshop.com/
补充:
这里为什么先修改权限 在移动站点资源文件?
站点根目录下会自动创建一个.user.ini 配置文件,改配置文件限制.php 能打开的文件目录。限制了 php 只能打开站点根目录下的文件以及/tmp目录。并且 该文件增加了i 权限 所以不能被修改。
这样站点环境会更安全一点
.user.ini 文件
[root@bt_server01~]# ls /www/wwwroot/www.ecshop.com/ -a
. brand.php favicon.ico js sitemaps.php
.. captcha.php feed.php languages snatch.php
404.html catalog.php flow.php message.php tag_cloud.php
activity.php category.php gallery.php mobile temp
admin cert goods.php myship.php themes
affiche.php certi.php goods_script.php package.php topic.php
affiliate.php chinabank_receive.php group_buy.php pick_out.php .user.ini
alipay.html comment.php .htaccess pm.php user.php
animated_favicon.gif compare.php htaccess.txt quotation.php vote.php
api cycle_image.php images receive.php wap
api.php data includes region.php wholesale.php
article_cat.php demo index.html respond.php widget
article.php ecmoban_qq index.php robots.txt
auction.php exchange.php install search.php
[root@bt_server01~]#
[root@bt_server01~]# cat /www/wwwroot/www.ecshop.com/.user.ini
open_basedir=/www/wwwroot/www.ecshop.com/:/tmp/
修改hosts 文件,将域名和ip绑定起来
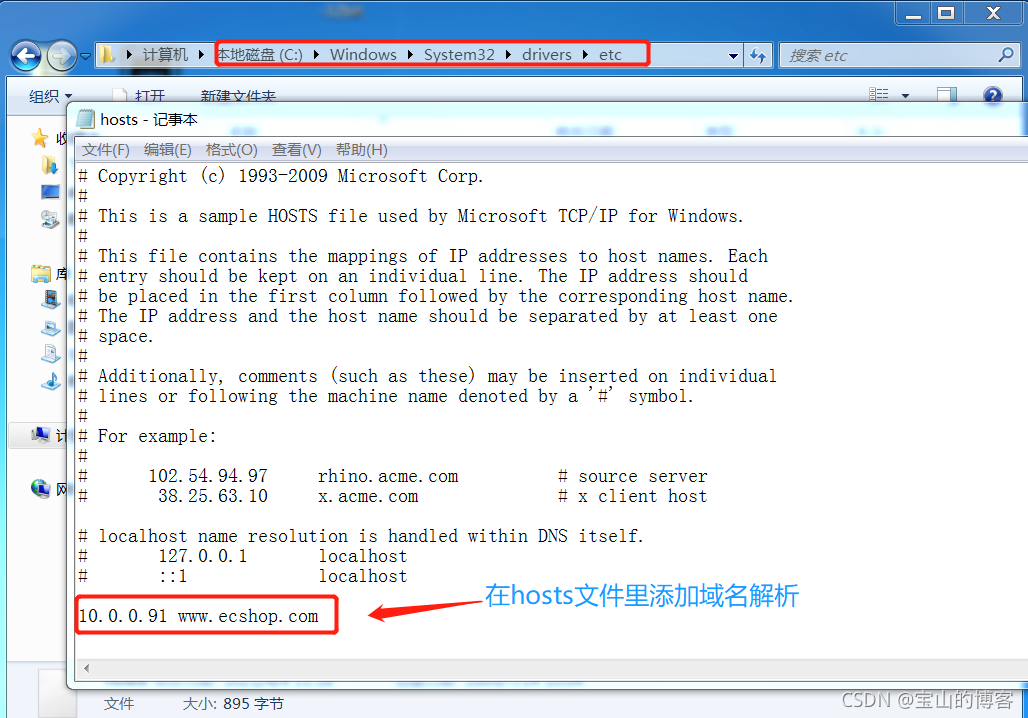
浏览器输入 域名,配置安装环境

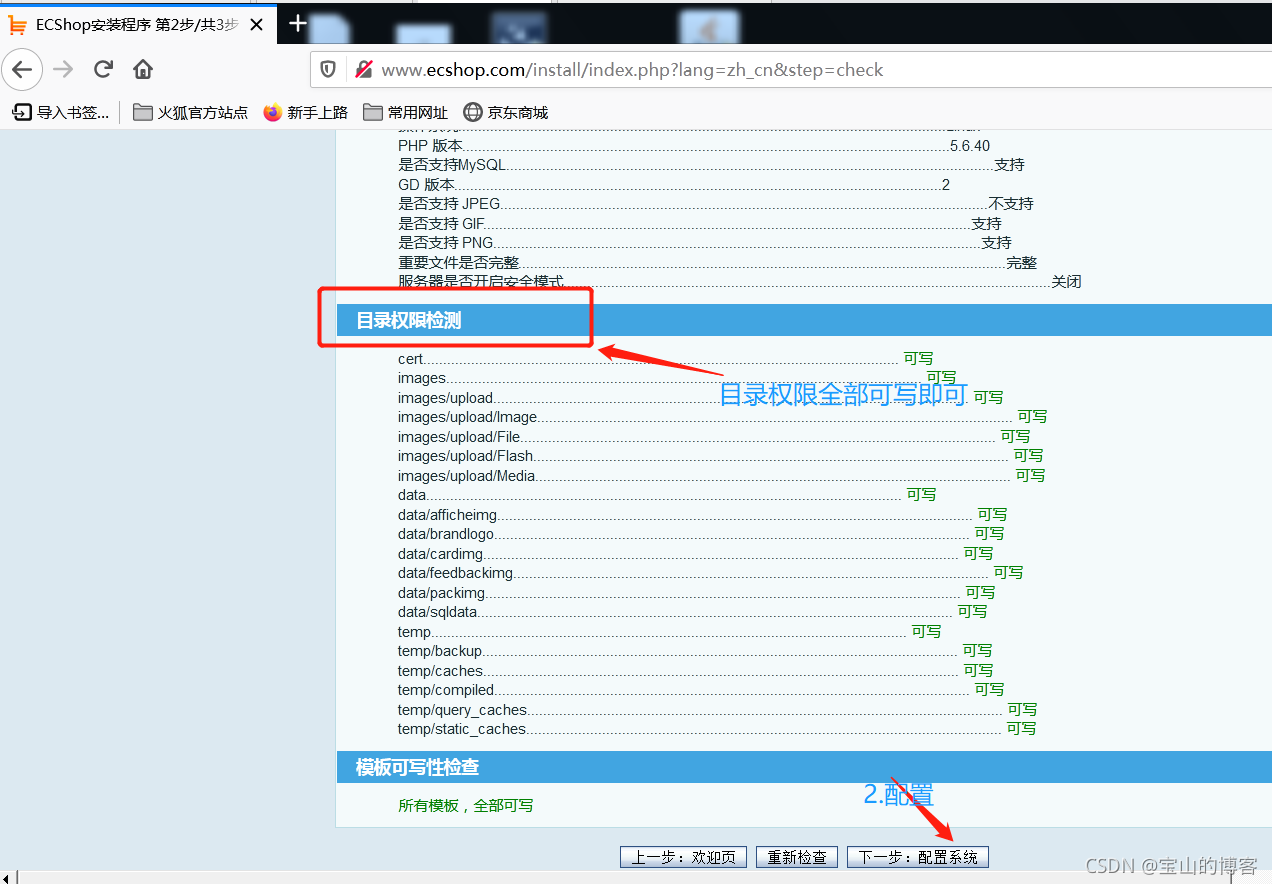
配置系统
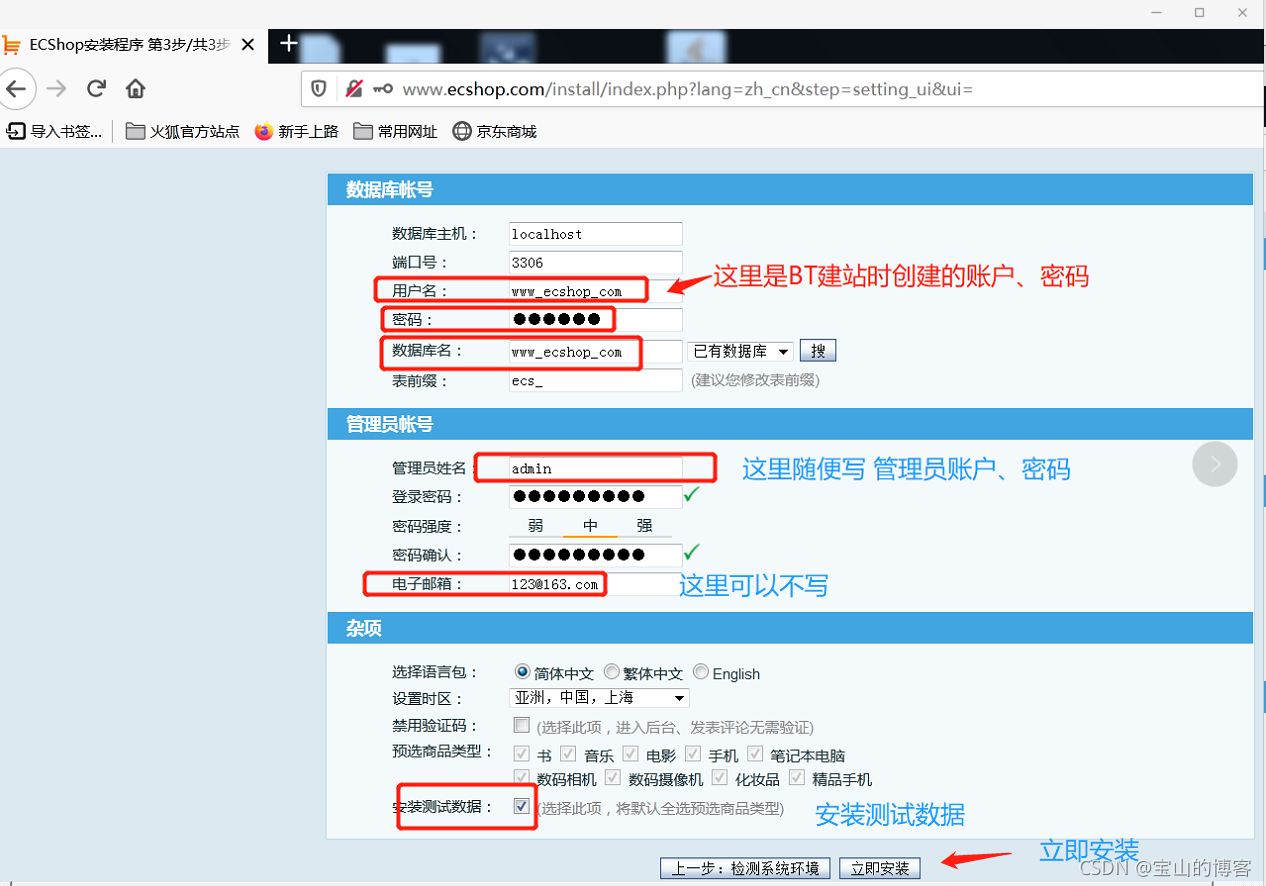
安装成功,测试

首页界面

后台登录界面
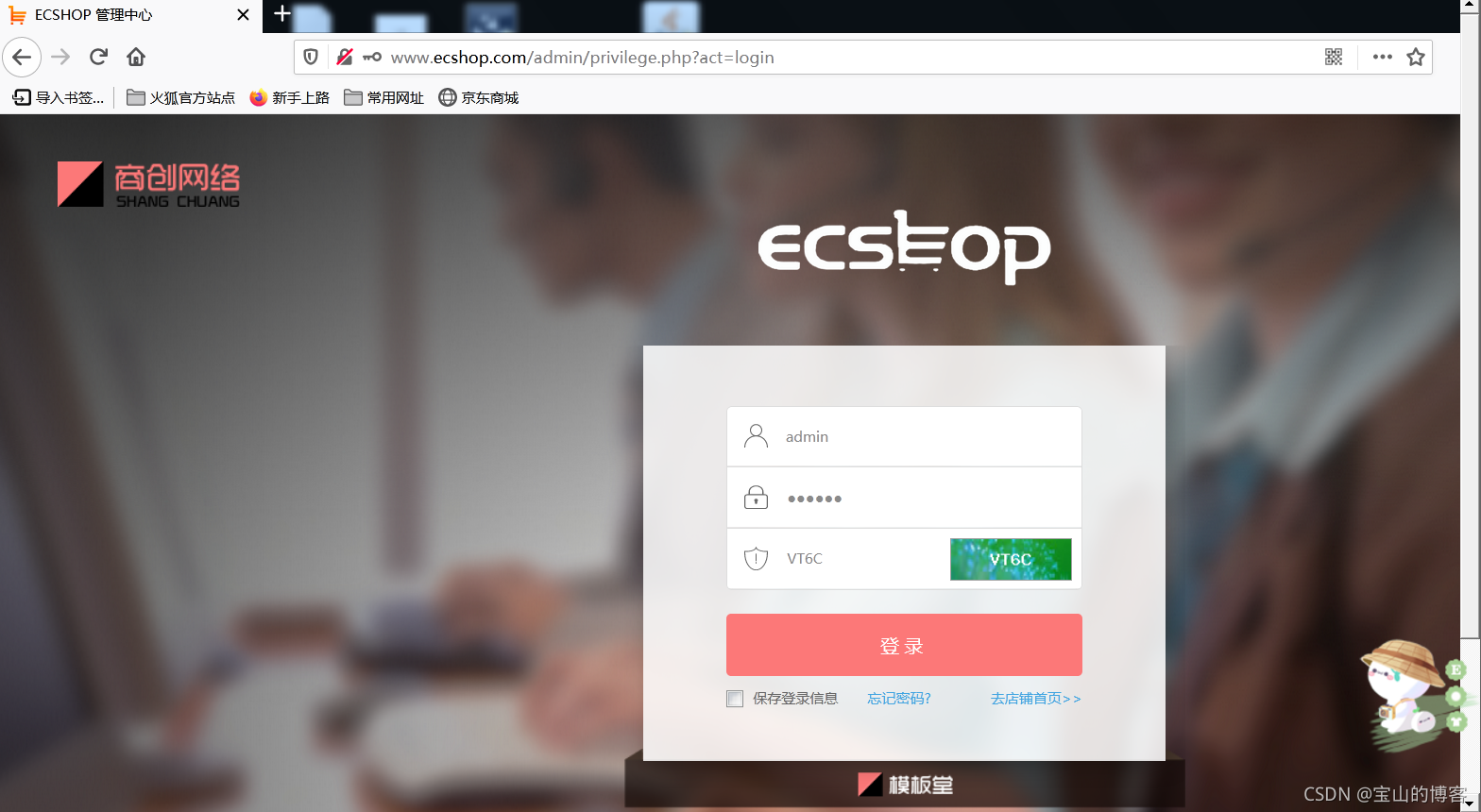
登录成功

浏览器搜索云小站,注册账号
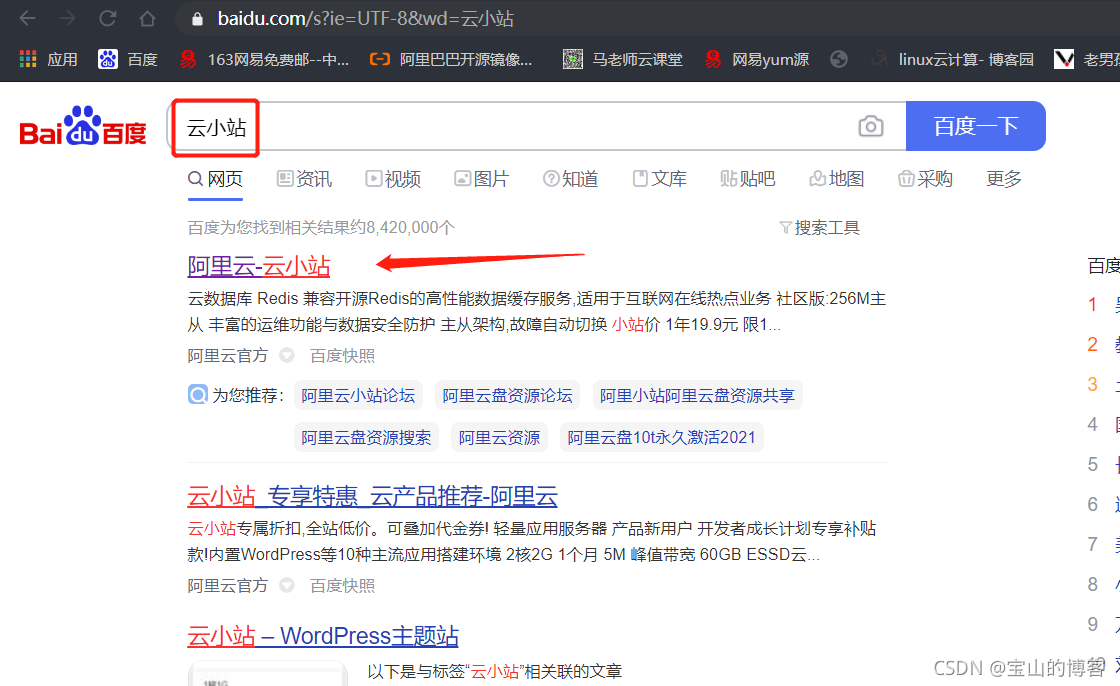

登录云 小站

购买 云主机

选择一款ECS云主机,进行购买

加入8888安全规则

加入8888端口
这里由于公网,所以我的firewalld防火墙开着的
# 查看防火墙状态
[root@aly_server01~]# firewall-cmd --state
running
# 开放端口
[root@aly_server01~]# firewall-cmd --zone=public --add-port=8888/tcp --permanent
success
# 重新加载防火墙
[root@aly_server01~]# firewall-cmd --reload
success
通过命令安装

快速建站

上传源代码
部署源代码
# 解压压缩包
[root@bt_server01~]# unzip maccms_v10_v2021.1000.2000_full.zip
# 移动到配置网站目录
[root@bt_server01~]# mv maccms10-main/* /www/wwwroot/www.dy.com/

这里购买了域名,还需要进行备案,只有备案了才可以用
浏览器输入地址
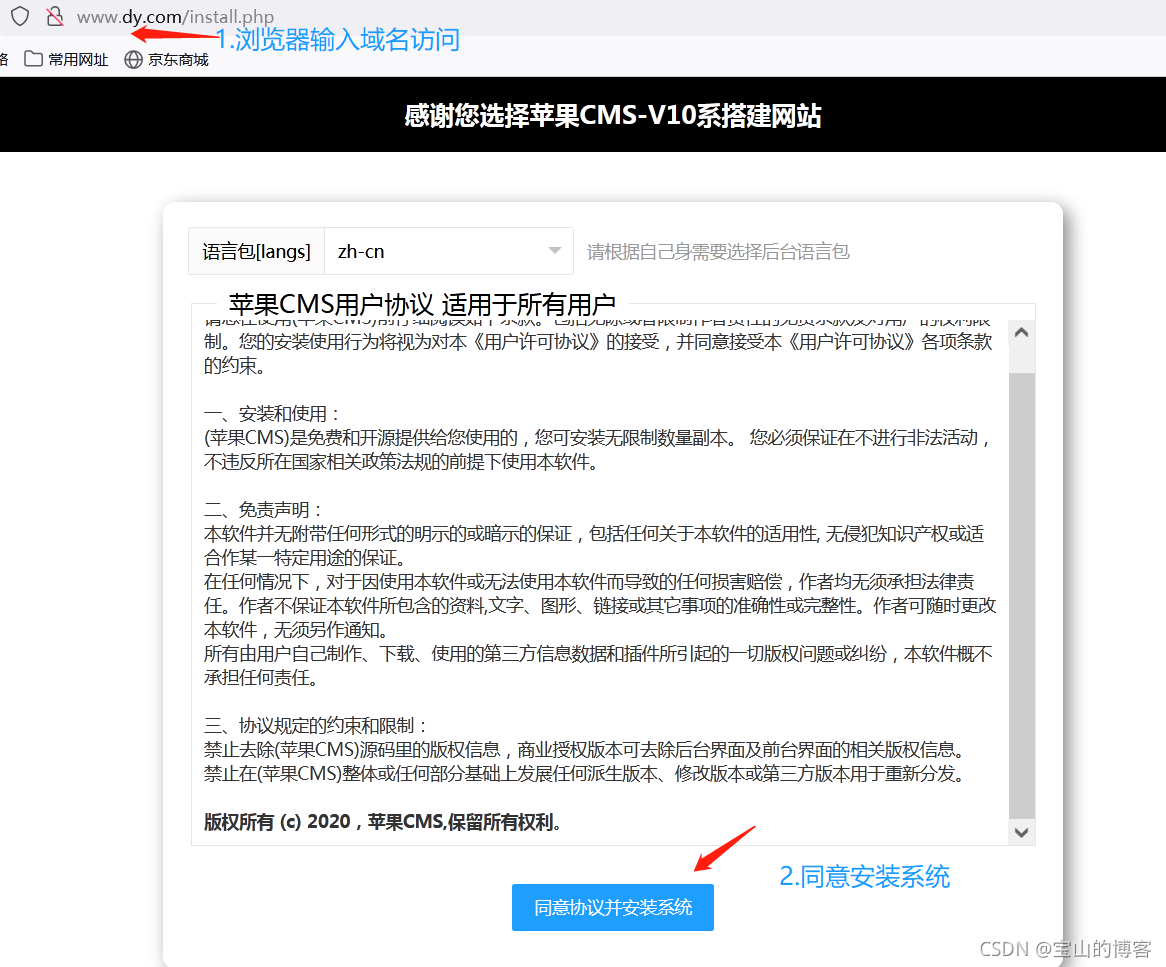

配置安装系统
故障处理
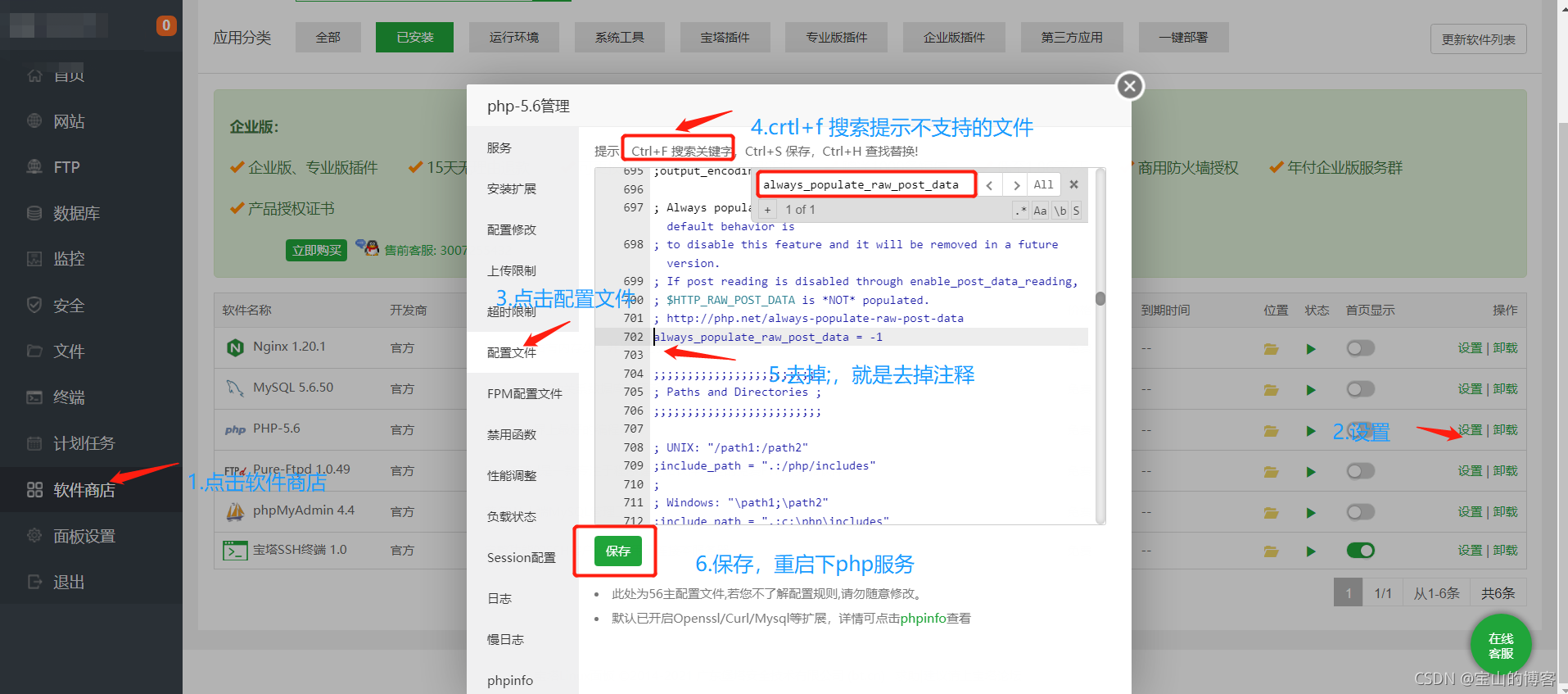
来到bt 界面,点击软件管理,找到php ,点击设置,然后安装fileinfo 模块
点击 配置文件,crtl+f 搜索 ,去掉注释。
在以后搭建论坛、网站时候,遇到大多数问题,都是PHP 的问题,优先考虑并处理


安装系统
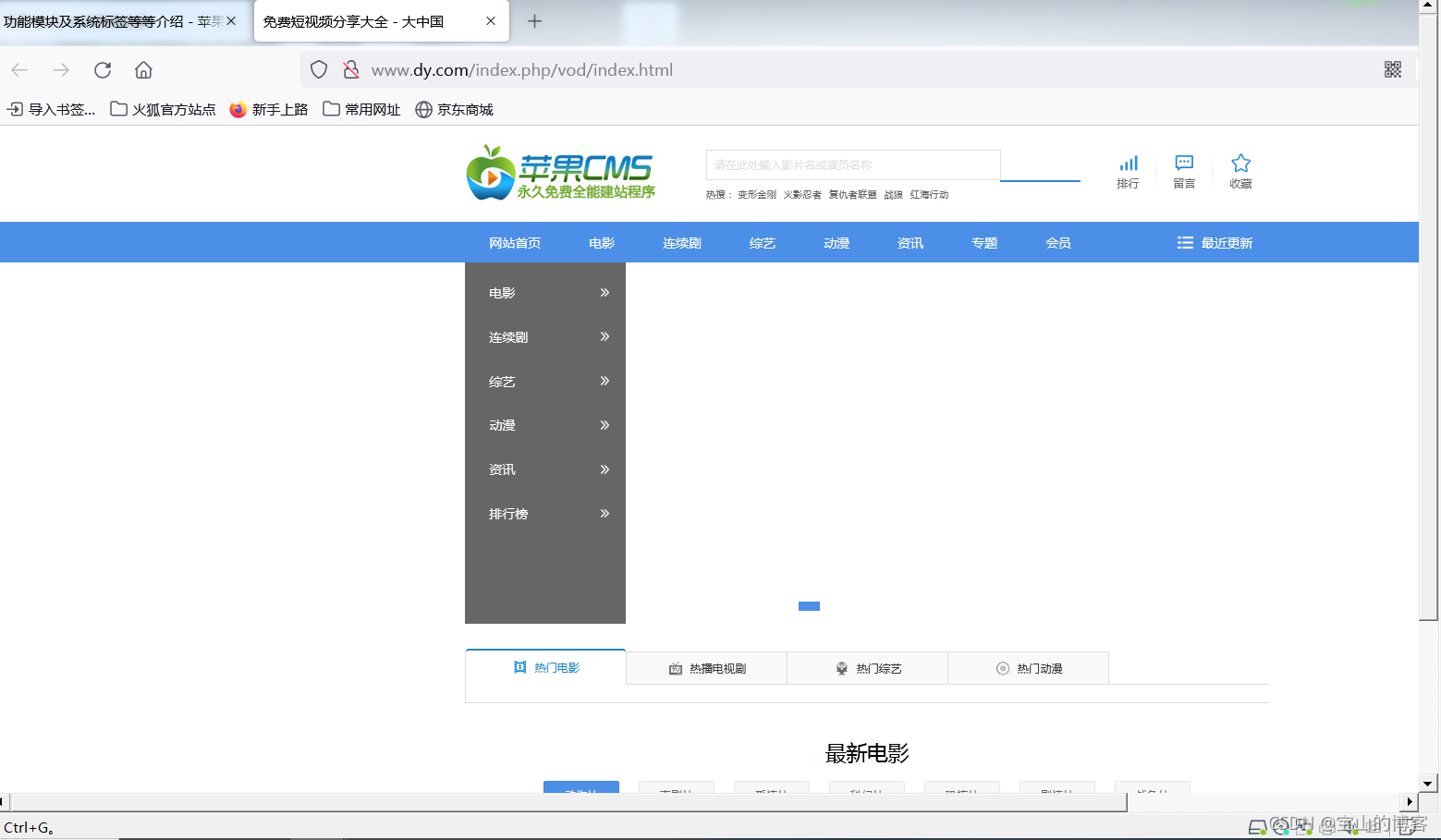
测试

国内2大域名厂家
1.万 网 被 阿里巴巴收购
2.新网 被腾讯收购
如果需要购买域名,可以去阿里云上 购买,然后做备案,直接绑定到云主机即可
简介
历史
nordu.net被注册域名层次
以 www.baidu.com 为例
一个域名可以有多个二级域名
域名注册
域名解析(DNS)
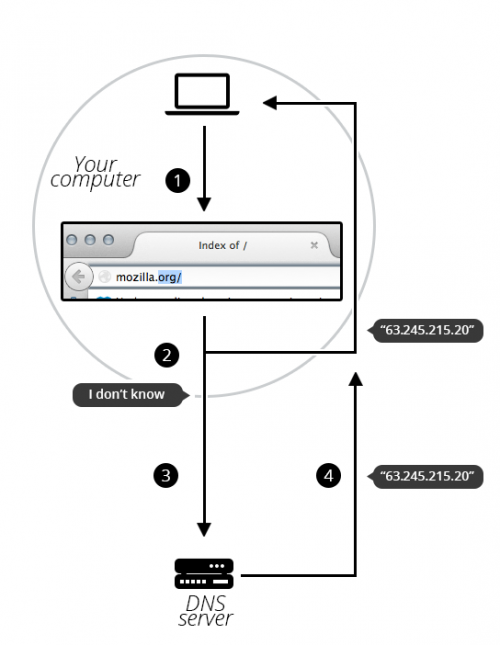
工作流程:
输入查询域名
浏览器查询本地缓存,查询到与网络服务交换内容,结束
向对应的顶级服务器下的子服务器发起请求,获得对应IP
浏览器去相应IP的网络服务器交互内容
域名解析配置
去域名服务商那添加域名解析
记录类型
主机记录
记录值
购买ssl 证书
申请网址:https://freessl.cn/ 或腾讯:https://cloud.tencent.com/act/pro/ssl
这里直接去某些网站,输入自己购买,备案的域名,直接申请即可
BT 使用ssl 证书

开启http 强制转换https

计划任务


开启监控
开启防火墙
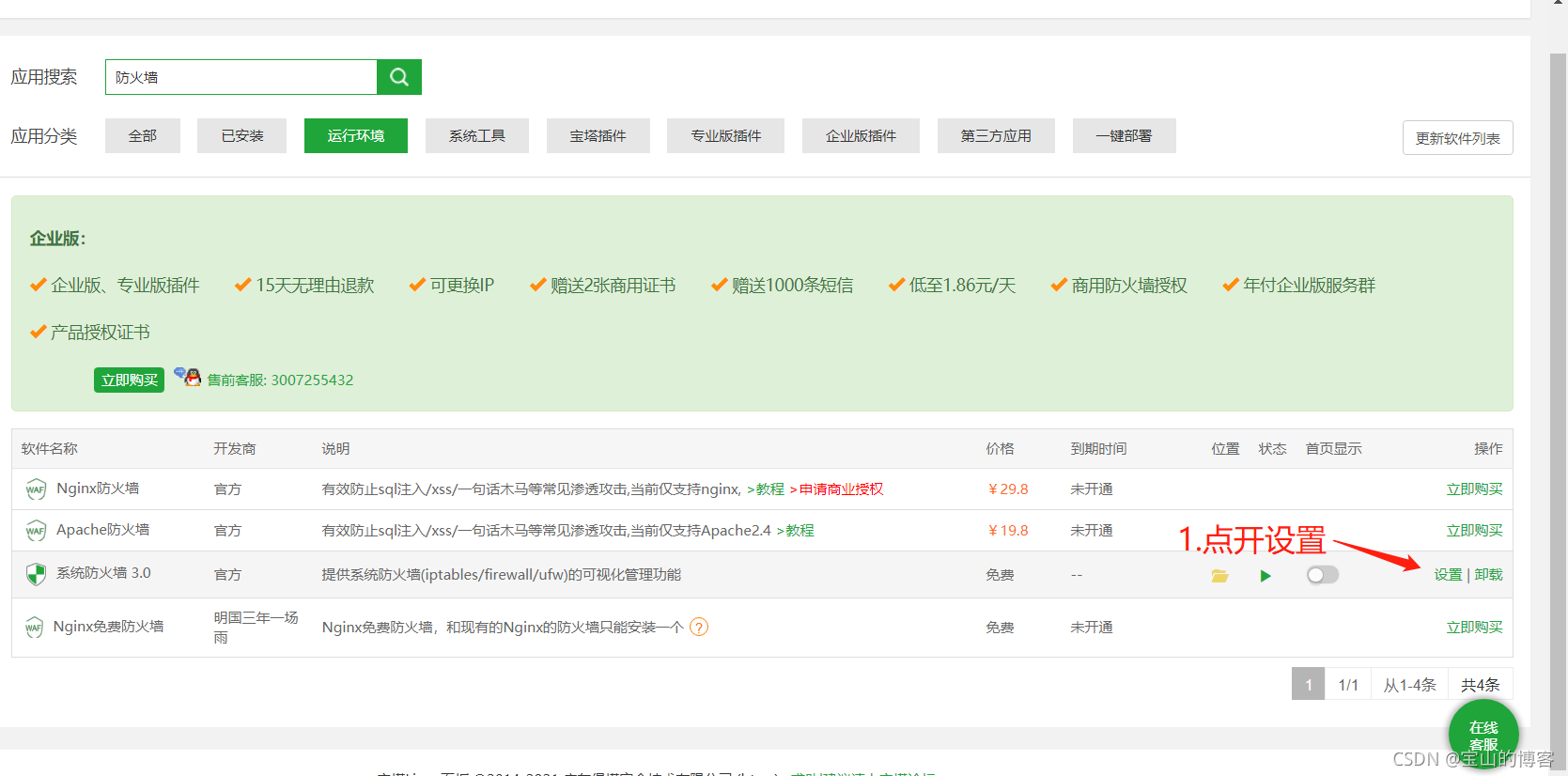
放行端口
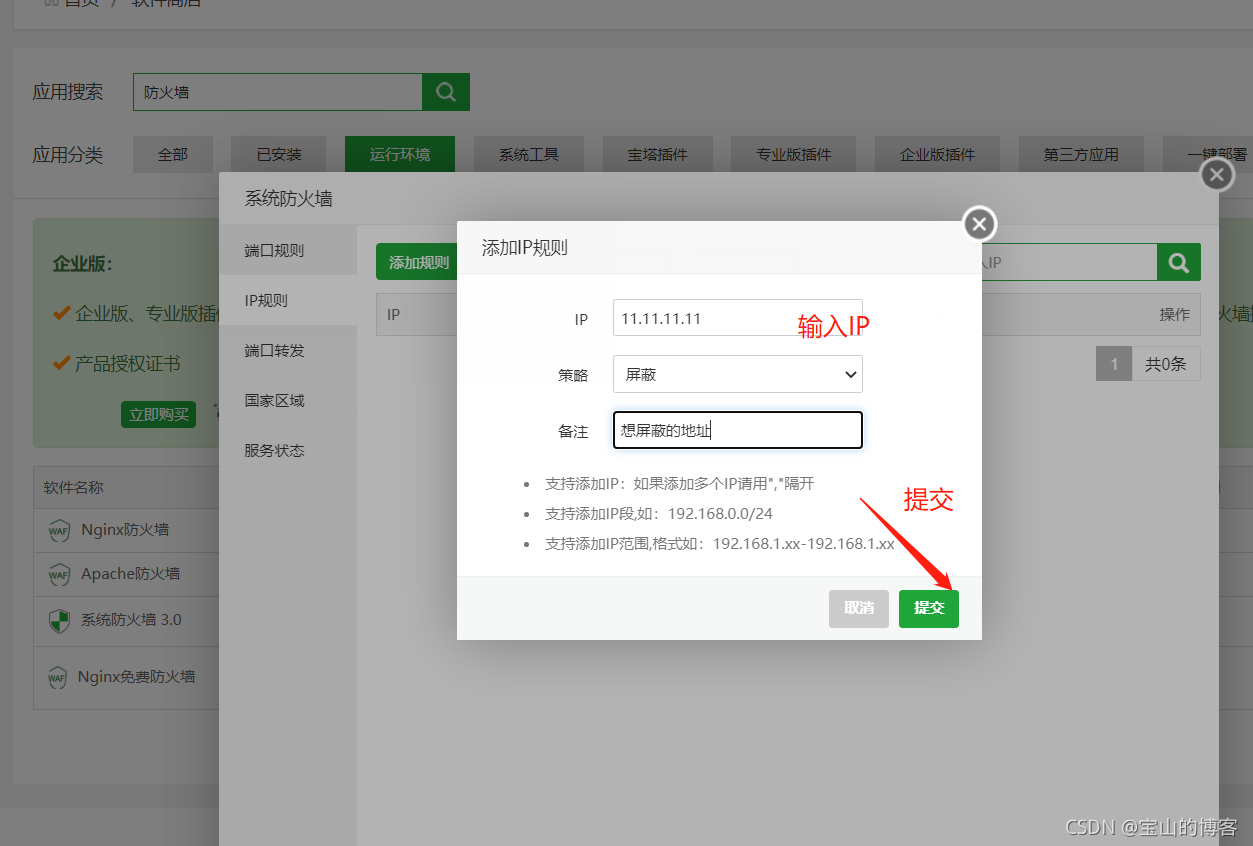
修改bt 登录入口http://10.0.0.91:8888/rivers
关于宝塔,目前就介绍到这里,在做阿里元相关配置的时候,需要注意开启安全策略。如果你的云主机开启了防火墙,也需相应的放行相关端口。
相关防火墙命令:
#查看防火墙运行转态 [root@aly_server01~]# firewall-cmd --state # 放行8888端口 [root@aly_server01~]# firewall-cmd --zone=public --add-port=8888/tcp --permanent #重新加载firewall [root@aly_server01~]# firewall-cmd --reload # 查看防火墙放行的端口 [root@aly_server01~]# firewall-cmd --list-all在工作学习中,遇到网站、博客、论坛搭建问题,大多缺少PHP包,或者需要修改配置文件,可根据提示进行排错。
如果你想学习搭建网站,需要源代码可以去逛网下载、或者私信我。

在Ruby中可以使用哪些替代方法来ping一个ip地址?标准库“ping”库的功能似乎非常有限。我对在这里滚动我自己的代码不感兴趣。有没有好的gem?我应该接受它并忍受它吗?(我在Linux上使用Ruby1.8.6编写代码) 最佳答案 net-ping值得一看。它允许TCPping(如标准rubyping),但也允许UDP、HTTP和ICMPping。ICMPping需要root权限,但其他则不需要。 关于ruby-Pingruby网站?,我们在StackOverflow上找到一个类
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我尝试安装CMS时出现错误。它说Bundler::GemfileNotFound此外,当我运行bundle时,它还会显示Bundler::GemfileNotFound我该如何解决这个问题?
我读过这个:Let’sstartwithasimpleRubyprogram.We’llwriteamethodthatreturnsacheery,personalizedgreeting.defsay_goodnight(name)result="Goodnight,"+namereturnresultend我的理解是,方法是定义在类中的函数或子程序,可以关联到类(类方法)或对象(实例方法)。那么,如果它不是在类中定义的,怎么可能是方法呢? 最佳答案 当你在Ruby中以这种方式在全局范围内定义一个函数时,它在技术上变成了Obje
我刚刚在我的Ubuntu9.10服务器上安装了TeamBox。我使用提供的服务器脚本在端口3000上启动并运行它。它的运行速度非常慢,从另一台计算机连接时每个HTTP请求最多需要30秒。我使用链接从shell加载TeamBox,一点也不花时间。然后我设置了一个SSH隧道,它再次运行得非常快。我通过此服务器上的apache以及SAMBA等运行了大约30个虚拟主机,没有任何问题。我该如何解决这个问题? 最佳答案 我的redmine(ruby,webrick)太慢了。现在我解决了这个问题:apt-getinstallmongrelruby
我不熟悉active_support,所以请多多包涵!Fox'slibrary允许通过谷歌的API进行搜索,但它需要积极的支持。我似乎无法让它工作!有什么想法吗?require'rubygems'require'active_support'require'google_search'pGoogleSearch.web:q=>"HelloWorld!"给我:NoMethodError:undefinedmethod‘cattr_accessor’forGoogleSearch:Class知道我做错了什么吗? 最佳答案 通过更多的谷歌
我需要从站点抓取数据,但它需要我先登录。我一直在使用hpricot成功地抓取其他网站,但我是使用mechanize的新手,我真的对如何使用它感到困惑。我看到这个例子经常被引用:require'rubygems'require'mechanize'a=Mechanize.newa.get('http://rubyforge.org/')do|page|#Clicktheloginlinklogin_page=a.click(page.link_with(:text=>/LogIn/))#Submittheloginformmy_page=login_page.form_with(:act
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
如何使用rubyonrails获取网络上某处其他网站的页面数据? 最佳答案 您可以使用httparty只是获取数据示例代码(来自example):requireFile.join(dir,'httparty')require'pp'classGoogleincludeHTTPartyformat:htmlend#google.comredirectstowww.google.comsothisislivetestforredirectionppGoogle.get('http://google.com')puts'','*'*7
我有一个循环,我在远程机器上执行一系列命令:ssh.exec('cd/vmfs/volumes/4c6d95d2-b1923d5d-4dd7-f4ce46baaadc/ghettoVCB;./ghettoVCB.sh-fvms_to_backup-ddryrun')do|ch,stream,data|if#{stream}=~/vmupgrade/putsvalue_hosts+"is"+dataputs#{stream}putsdataendend我想在do-end循环之外访问#{stream}和数据如果有任何帮助,我将不胜感激。谢谢,嗨,约格,我实现了您的建议,但现在出现错误:Wr
我正在使用RubyonRailsv3.0.9,我想检索我设置了链接的每个网站的favicon.ico图像。也就是说,如果在我的应用程序中我设置了http://www.facebook.com/URL,我想检索Facebook的图标并在我的网页中使用\插入它。当然,我也想为所有其他网站这样做。如何以“自动”方式从网站检索favicon.ico图标(“自动”是指在网站中搜索图标并获取它的链接-我认为不是,因为并非所有网站都有一个名为“favicon.ico”的图标。我想以“自动”方式识别它)?P.S.:我想做的是像Facebook在您的Facebook页面中添加链接\URL时所做的那样:它