摘要:JDK1.5及之后的版本中,提供的线程安全的容器,一般被称为并发容器。与同步容器一样,并发容器在总体上也可以分为四大类,分别为:List、Set、Map和Queue。
本文分享自华为云社区《【高并发】要想学好并发编程,这些并发容器的坑是你必须要注意的!!(建议收藏)》,作者:冰 河 。
其实,在JDK1.5之前的线程安全的容器,大多数都是指同步容器,使用同步容器进行并发编程时,最大的问题就是性能很差。因为同步容器中的所有方法都是使用synchronized锁进行互斥,串行度太高了,无法真正的做到并行。
所以,在JDK1.5之后,JDK中提供了并发性能更好的容器。JDK1.5及之后的版本中,提供的线程安全的容器,一般被称为并发容器。
与同步容器一样,并发容器在总体上也可以分为四大类,分别为:List、Set、Map和Queue。总体上如下图所示。
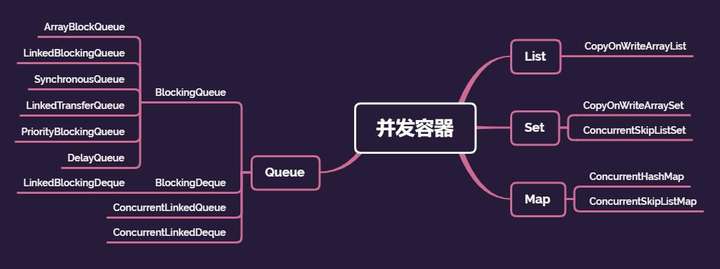
接下来,我们分别介绍下这些并发容器在使用时的注意事项和避免踩到的坑。
并发容器中的List相对来说比较简单,就一个CopyOnWriteArrayList。大家可以从字面的意思中就能够体会到:CopyOnWrite,在写的时候进行复制操作,也就是说在进行写操作时,会将共享变量复制一份。那这样做有什么好处呢?最大的好处就是:读操作可以做到完全无锁化。
在CopyOnWriteArrayList内部维护了一个数组,成员变量array指向这个数组,其核心源代码如下所示。
private transient volatile Object[] array;
final Object[] getArray() {
return array;
}
final void setArray(Object[] a) {
array = a;
}当进行操作时,都是基于array指向的这个内部数组进行的。例如,我们使用Iterator迭代器遍历这个数组时,会按照下图所示的方式进行读操作。

如果在遍历CopyOnWriteArrayList时发生写操作,例如,向数组中增加一个元素时,CopyOnWriteArrayList则会将内部的数组复制一份出来,然后会在新复制出来的数组上添加新的元素,添加完再将array指向新的数组,如下图所示。

对于CopyOnWriteArrayList的其他写操作和添加元素的操作原理相同,这里就不再赘述了。
使用CopyOnWriteArrayList时需要注意的是:
对于Set接口来说,并发容器中主要有两个实现类,一个是CopyOnWriteArraySet,另一个是ConcurrentSkipListSet。其中,CopyOnWriteArraySet的使用场景、原理与注意事项和CopyOnWriteArrayList一致。而ConcurrentSkipListSet的使用场景、原理和注意事项和下文的ConcurrentSkipListMap一致。这里,我就不再赘述啦。
在并发容器中,Map接口的实现类主要有ConcurrentHashMap和ConcurrentSkipListMap,而ConcurrentHashMap和ConcurrentSkipListMap最大的区别就是:ConcurrentHashMap的Key是无序的,而ConcurrentSkipListMap的Key是有序的。
在使用ConcurrentHashMap和ConcurrentSkipListMap时,需要注意的是:ConcurrentHashMap和ConcurrentSkipListMap的Key和Value都不能为空。
这里,我们可以将Map相关的类总结成一个表格,如下所示。
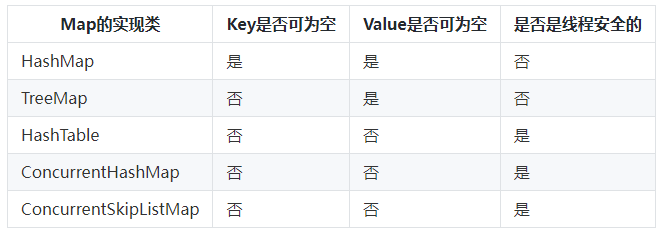
这样,大家记忆起来就方便多了。
这里,ConcurrentSkipListMap是基于“跳表”实现的,跳表的插入、删除、查询的平均时间复杂度为O(log n),这些时间复杂度在理论上与线程数没有关系。如果要追求性能的话,可以尝试使用ConcurrentSkipListMap。
在Java的并发容器中,Queue相对来说比较复杂。我们先来了解几个概念:
我们可以将上述的队列进行组合,将队列分为单端阻塞队列、双端阻塞队列、单端非阻塞队列和双端非阻塞队列。
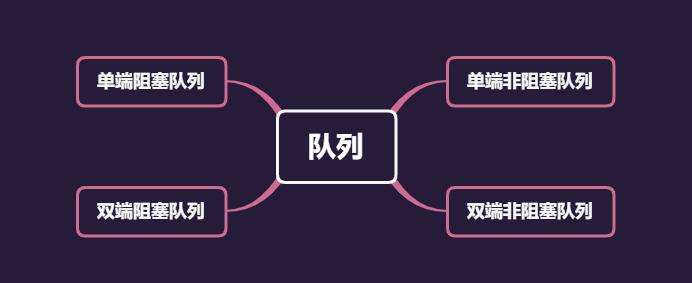
在Java的并发容器中,会使用明显的标识来区分不同类型的队列。
接下来,我们就分别简单聊聊这四种类型的队列。
在Java的并发容器中,单端阻塞队列的主要实现是BlockingQueue,主要包括:ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、LinkedTransferQueue、PriorityBlockingQueue和DelayQueue。
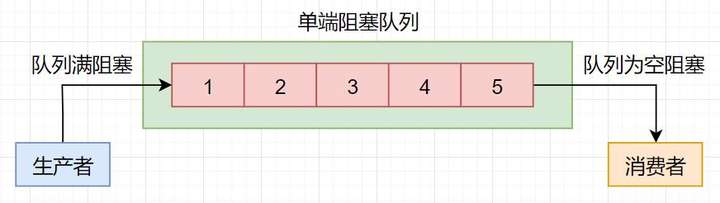
单端阻塞队列的内部一般会有一个队列。
在实现上,内部的队列可以是数组,例如ArrayBlockingQueue,也可以是链表,例如LinkedBlockingQueue。
也可以在内部不存在队列,例如SynchronousQueue,SynchronousQueue实现了生产者的入队操作必须等待消费者的出队操作完成之后才能进行。
LinkedTransferQueue集成了LinkedBlockingQueue和SynchronousQueue的优点,并且性能比LinkedBlockingQueue好。
PriorityBlockingQueue实现了按照优先级进行出队操作,也就是说,队列元素在PriorityBlockingQueue内部可以按照某种规则进行排序。
DelayQueue是延时队列,实现了在一段时间后再出队的操作。
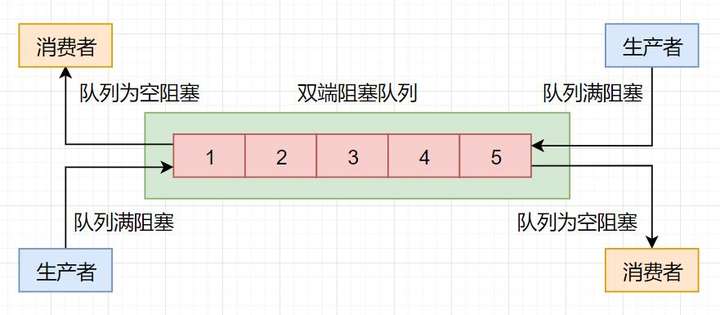
双端阻塞队列的实现主要是LinkedBlockingDeque。示意图如下所示。
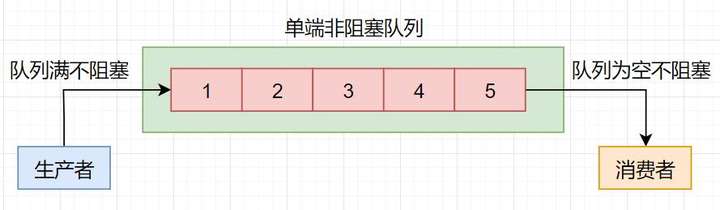
单端非阻塞队列的实现主要是ConcurrentLinkedQueue,示意图如下所示。
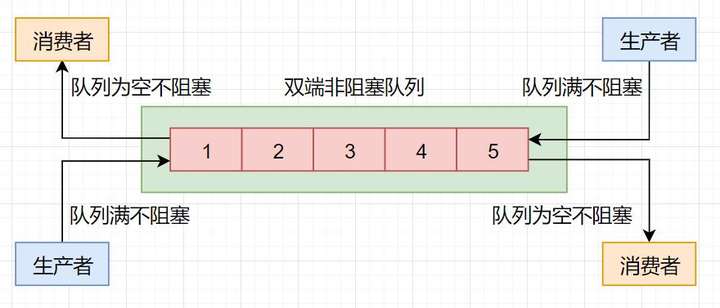
双端非阻塞队列的实现主要是ConcurrentLinkedDeque,示意图如下所示。
使用队列时,还要注意队列的有界与无界问题,也就是在使用队列时,需要注意队列是否有容量限制。
在实际工作中,一般推荐使用有界队列。因为无界队列很容易导致内存溢出的问题。在Java的并发容器中,只有ArrayBlockingQueue和LinkedBlockingQueue支持有界,其他的队列都是无界队列。
在使用时,一定要注意内存溢出问题。
今天我们主要介绍了JDK1.5之后提供的并发容器,主要包括:List、Set、Map和Queue,而Queue又可以分为:单端阻塞队列、双端阻塞队列、单端非阻塞队列和双端非阻塞队列。对于每种并发容器,我们简单介绍了其基本原理和注意事项。
在我的路线文件中我有:match'graphs/(:id(/:action))'=>'graphs#(:action)'如果是GET请求(工作)或POST请求(不工作),我想匹配它我知道我可以使用以下方法在资源中声明POST请求:post'/'=>:show,:on=>:member但是我怎样才能为比赛做到这一点呢?谢谢。 最佳答案 如果你同时想要POST和GETmatch'graphs/(:id(/:action))'=>'graphs#(:action)',:via=>[:get,:post]编辑默认值可以设置如下match'g
这个问题在这里已经有了答案:WhydoRubysettersneed"self."qualificationwithintheclass?(3个答案)关闭29天前。给定这段代码:classSomethingattr_accessor:my_variabledefinitialize@my_variable=0enddeffoomy_variable=my_variable+3endends=Something.news.foo我收到这个错误:test.rb:9:in`foo':undefinedmethod`+'fornil:NilClass(NoMethodError)fromtes
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭9年前。Improvethisquestion首先,我想避免一场关于语言的口水战。可供选择的语言有Perl、Python和Ruby。我想提一下,我对所有这些都很满意,但问题是我不能只专注于一个。例如,如果我看到一个很棒的Perl模块,我必须尝试一下。如果我看到一个不错的Python应用程序,我必须知道它是如何制作的。如果我看到RubyDSL或一些Ruby巫术,我就会迷上Ruby一段时间。目前我是一名Java开发人员,但计划在不久的将来
我一直在研究ruby的并行/异步处理能力,并阅读了许多文章和博客文章。我查看了EventMachine、Fibers、Revactor、Reia等。不幸的是,我无法为这个非常简单的用例找到简单、有效(且非IO阻塞)的解决方案:File.open('somelogfile.txt')do|file|whileline=file.gets#(R)ReadfromIOline=process_line(line)#(P)Processthelinewrite_to_db(line)#(W)WritetheoutputtosomeIO(DBorfile)endend你看到了吗,我的小脚本正
我有生产服务器(Nginx+Passenger)。当我尝试从另一台计算机ab-n3-c3myhost.ru/时,我在我的nginxerror.log中收到此错误日志:[pid=21160thr=139775297914624file=ext/nginx/HelperAgent.cpp:584time=2011-08-3115:25:49.22]:UncaughtexceptioninPassengerServerclientthread:exception:Cannotreadresponsefrombackendprocess:Connectionresetbypeer(104)ba
“架设一个亿级高并发系统,是多数程序员、架构师的工作目标。许多的技术从业人员甚至有时会降薪去寻找这样的机会。但并不是所有人都有机会主导,甚至参与这样一个系统。今天我们用12306火车票购票这样一个业务场景来做DDD领域建模。”开篇要实现软件设计、软件开发在一个统一的思想、统一的节奏下进行,就应该有一个轻量级的框架对开发过程与代码编写做一定的约束。虽然DDD是一个软件开发的方法,而不是具体的技术或框架,但拥有一个轻量级的框架仍然是必要的,为了开发一个支持DDD的框架,首先需要理解DDD的基本概念和核心的组件。一.什么是领域驱动设计(DDD)首先要知道DDD是一种开发理念,核心是维护一个反应领域概
目录需求基于JavaCV跨平台执行ffmpeg命令[^1]坑一内存不足坑二多个ffmpeg进程并行导致IO负载大,进而导致ioerror?坑三使用Java操作ffmpeg时,有时会卡死坑四Process的waitFor死锁问题及解决办法需求给透明背景的视频自动叠加一张背景图片基于JavaCV跨平台执行ffmpeg命令1我测试发现的本需求的最小依赖:dependency>groupId>org.bytedecogroupId>artifactId>ffmpeg-platform-gplartifactId>version>5.0-1.5.7version>dependency>核心代码:Stri
在执行所有promise后,我正在尝试进行一些计算。但是proc从不调用:cbr_promise=Concurrent::Promise.execute{CbrRatesService.call}bitfinex_promise=Concurrent::Promise.execute{BitfinexService.call}proc=Proc.newdoputs10endConcurrent::Promise.all?([cbr_promise,bitfinex_promise]).then{proc}使用concurrent-ruby制作gem。例如,我是否应该创建一个每100毫秒
在我使用rbenv更新我的Ruby版本后,我无法使用Heroku命令行工具。我收到此错误:>herokurbenv:heroku:commandnotfoundThe`heroku'commandexistsintheseRubyversions:2.0.0-p195从toolbelt.heroku.com重新安装工具带没有帮助。 最佳答案 我切换到我以前的Ruby版本2.0.0p195并卸载了gem'heroku'rbenvglobal2.0.0p195gemuninstallheroku然后我切换到最新的Ruby版本2.0.0p
如何处理并发ruby线程池中的异常(http://ruby-concurrency.github.io/concurrent-ruby/file.thread_pools.html)?例子:pool=Concurrent::FixedThreadPool.new(5)pool.postdoraise'somethinggoeswrong'end#howtorescuethisexceptionhere更新:这是我的代码的简化版本:defprocesspool=Concurrent::FixedThreadPool.new(5)products.eachdo|product|new_