“本文主要介绍了华为云原生开发GDE AI 下的AI Model Foundry模块, 华为云为开发者提供了丰富的云原生免费体验平台,并发布了众多云原生开发教程,有助于云原生开发者深入学习云开发相关知识,成为高级云原生工程师。”
- (文末附华为云官方云原生开发教程、华为云开发者免费注册体验指南、华为云原生GDE AI开发入口)
本文三大主要板块:
GDE AI平台是面向GTS AI开发者的一站式开发平台,提供海量数据预处理、样本自动化标注、大规模分布式训练、自动化模型生成及按需部署预测服务的能力;并提供了图像、文字、知识图谱、自然语言处理、预测性维护等多种AI领域通用服务,使企业能快速开发和构建AI业务,并且支持电信网终端制造等行业自动化、智能化解决方案实现。

GDE平台辅助组成元素:
关键特性:效率高、门槛低、性能优、运维易。

流程图:

优势:
①价值样本数量多,数据复用率高。
②样本标注工具极其丰富。
③能快速克隆样本,并有样本增强的能力,可以优化样本质量。

GDE平台提供丰富、一站式的开发工具链,通过Notebook在线开发和PyCharm本地开发、远程调试的方式,能够有效提升AI开发效率,通过导航式开发可以有效降低AI应用开发门槛。
支持的开发方式:Notebook在线开发;PyCharm本地开发、任务远端执行测试;基于模板的导航式开发。

a.推理服务的基本能力:
①支持预测服务的运行状态监控、日志分析。
②支持滚动升级和灰度发布。
③支持模型监控及重训练。
④支持不同框架模型格式(例如:.pb/.pkl/.h5)。
⑤支持Tensorflow/Pytorch/Spark MLlib框架。
⑥支持深度学习任务GPU加速执行。
b.推理服务与传统自部署模型对比:

c.推理服务的调用方式:
①在线推理(通过API接口调用)
特点:高并发、低延时、自动弹性伸缩、推理效率高、支持多模型灰度发布。
②批量推理
特点:高效率分布式计算、可处理大量数据推理、支持GPU加速。

什么是AI?——能够“自主学习到一个函数”的程序。
示例:
在语音识别领域,给定一段语音波形,AI能够自主学习到一个函数将语音波形转化为文字。
在图像识别领域,给定一张图片,AI能够自主学习到一个函数将图像识别。

Model Foundry——解决AI开发的主要痛点
AI开发痛点一:专业门槛高、技术栈多
传统AI开发所需部分技能:高等数学基础、AI相关理论知识、编程技术能力

AI开发痛点二:开发流程长、集成难度高、无资产复用和沉淀
AI开发流程概览:

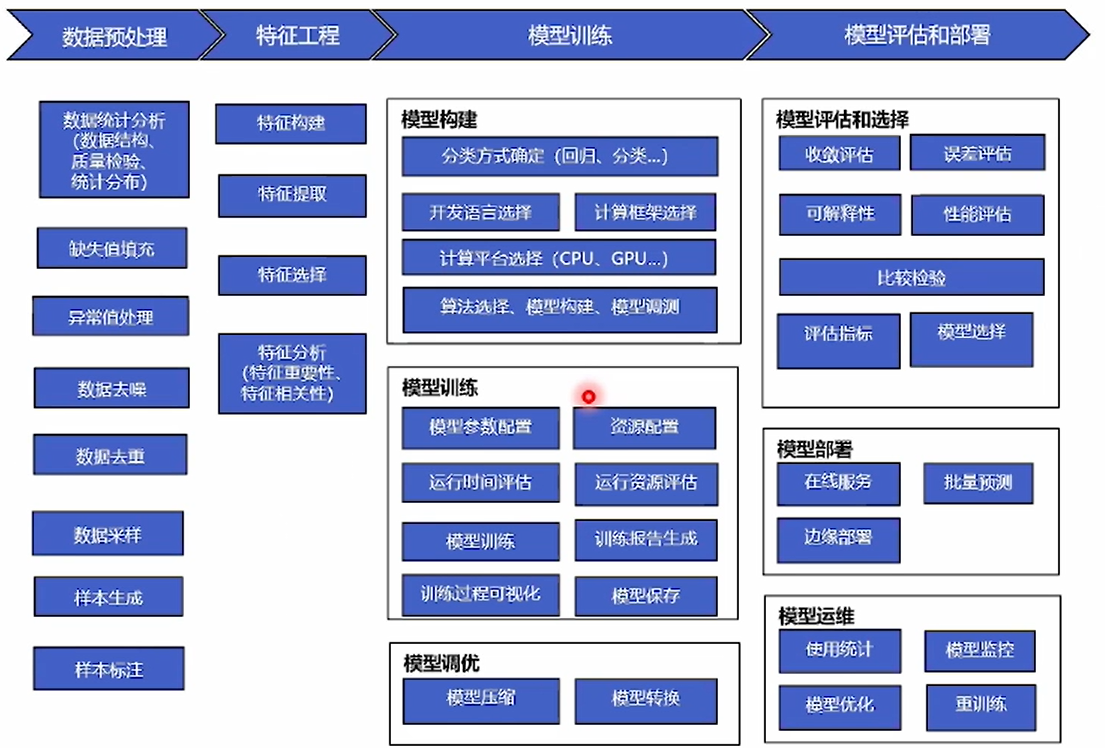
①能力可复用、高效建模、节省人力。
②向导式开发,可视化建模、准入门槛低。
③AI模型全生命周期管理,可持续监控、持续训练。

附:传统AI开发模式开发人力资源 VS AI Model Foundry 开发人力资源

附:传统AI开发现实体验 VS AI Model Foundry 开发现实体验

①基础设施:兼容主流基础设施,如:docker、私有云、公有云等。
②基础框架:兼容丰富的基础框架,如:PyTorch等.
③Model Foundry:提供模板引擎以及针对不同应用场景的AI模板库。
④应用领域:支持电信领域、工业领域、通用业务等多领域的应用。

特点:
①基于Jupyter Notebook的开发环境(对接ADC编排)。
②提供可视化开发调试插件(例如:PyTorch)。

③提供丰富的SDK开发组件和预置算子支持。
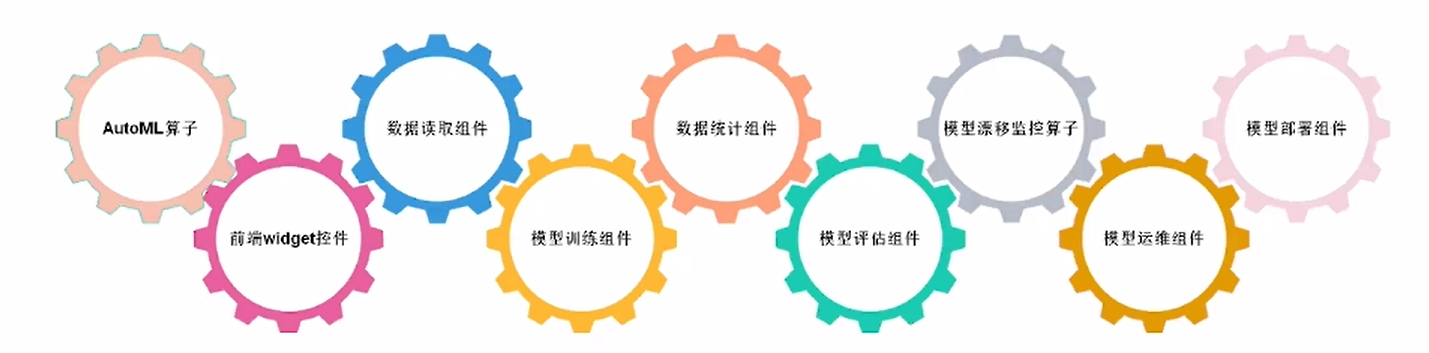
模板开发:通过模板引擎提供的流水线(Pipeline),实现各个模块的功能,进行基于模板的从零开发。
模板开发的六个子流程:
开发态:
①数据:进行数据源的配置,数据模型定义,特征工程的处理等(如:数据标注)。
②算法:算法配置,设定训练的目标,算法结果评估等。
③模型:工作流程的编排,模型安全的制定等。
运行态:
④服务:模型部署(上线、离线),安全验证,模型包解析加载,服务管理等。
⑤评估:模型监控,精度跟踪,模型验证评估等。
⑥调优:模型优化,优化对比等。(可选)

开发模板的基本概念:(层次从高到低)模板 → Pipeline → Stage → Component

①Pipeline:指机器学习开发应用过程中从数据读取到数据预处理、特征工程、模型训练和模型评估和部署监控的一个完整的机器学习过程。模型生命周期过程中涉及多个独立的处理流程,每个流程抽象为一个Pipeline。比如:模型训练、模型评估优化和模型推理。Pipeline由一系列的步骤(Stage)顺序组成。

②Stage:Stage步骤是机器学习工作流中各个阶段的抽象,是最小的调度执行单元(不同步骤可运行在不同的计算引擎上),对应导航式中的操作步骤页,将复杂的DAG图转换为导航式步骤页面。每个Stage包含若干组件(component)。

③Component:Component组件是满足一定功能的最小逻辑单元,整个ML Pipeline由一系列的component组成一个DAG。
每个component包含三部分:输入——运行参数和前一个component的输出,运行参数通过在界面UI组件配置;输出——是后一个component的输入,也可以指定UI组件进行结果的可视化呈现;执行逻辑——业务处理逻辑。
④实例:模板实例简称实例,是模板实例化运行的结果,模板与实例的关系类似于面向对象编程中类的实例化过程。
⑤Job: 指Pipeline执行(每个AI处理过程)的实例化结果,支持手动和周期性触发运行。
⑥Run: 指Job的每一次执行的实例化结果,包括周期性作业的每次执行。
实例化:

模板二次开发:若当前模板无法通过数据集增强及超参数调整的优化方式满足业务需求,可使用Notebook提供的模板二次开发功能,对当前模板进行二次开发,引入新的算法。
二次开发步骤:(以图像分割模板为例)
新建Notebook——配置Notebook参数——下载预置模板——修改模块包的代码——生成新模板包——发布模板包——二次开发完成
流程图:


正在上传…重新上传取消

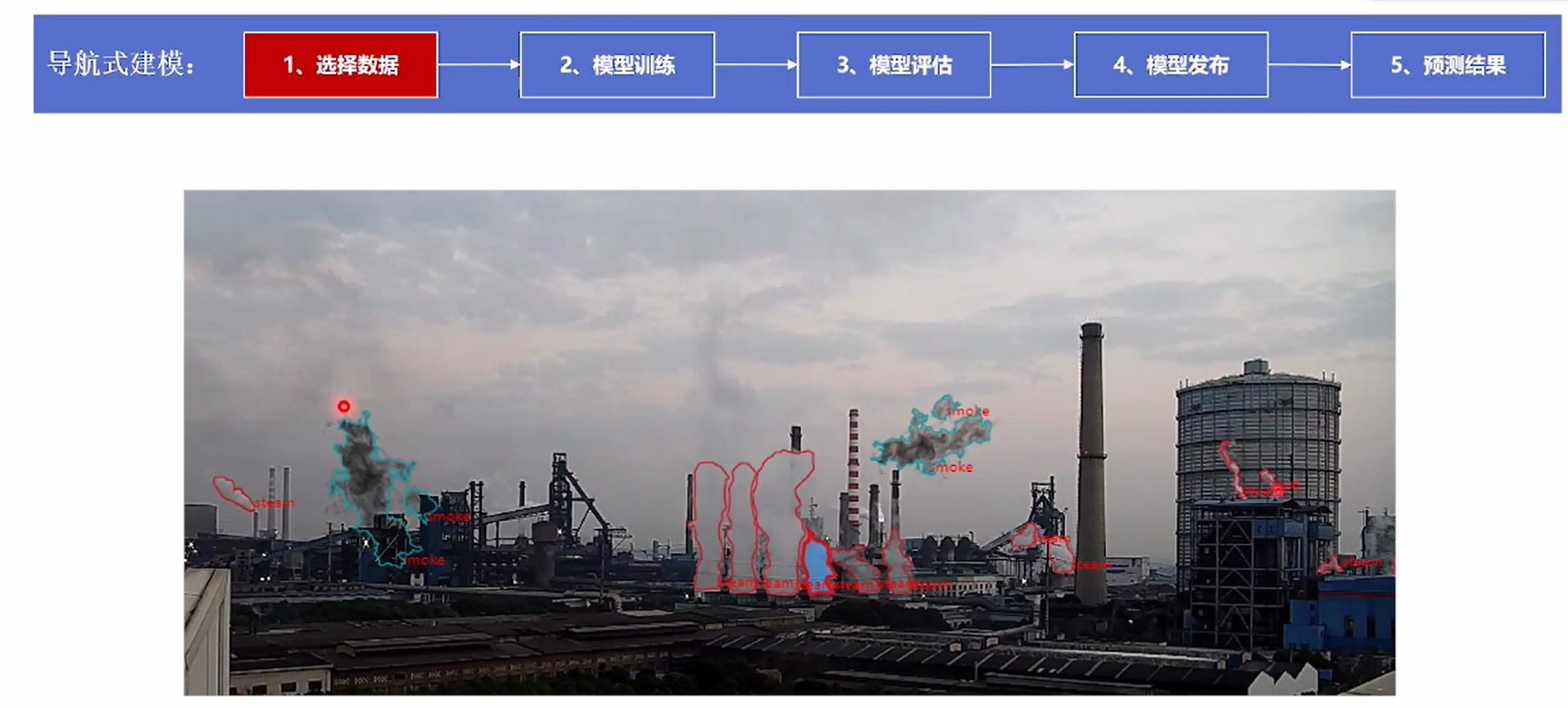
①数据集采集、数据选择:业务人员基于在工厂中采集的数据图片,使用样本库提供的在线标注功能,标注目标(黑烟),作为训练数据集。
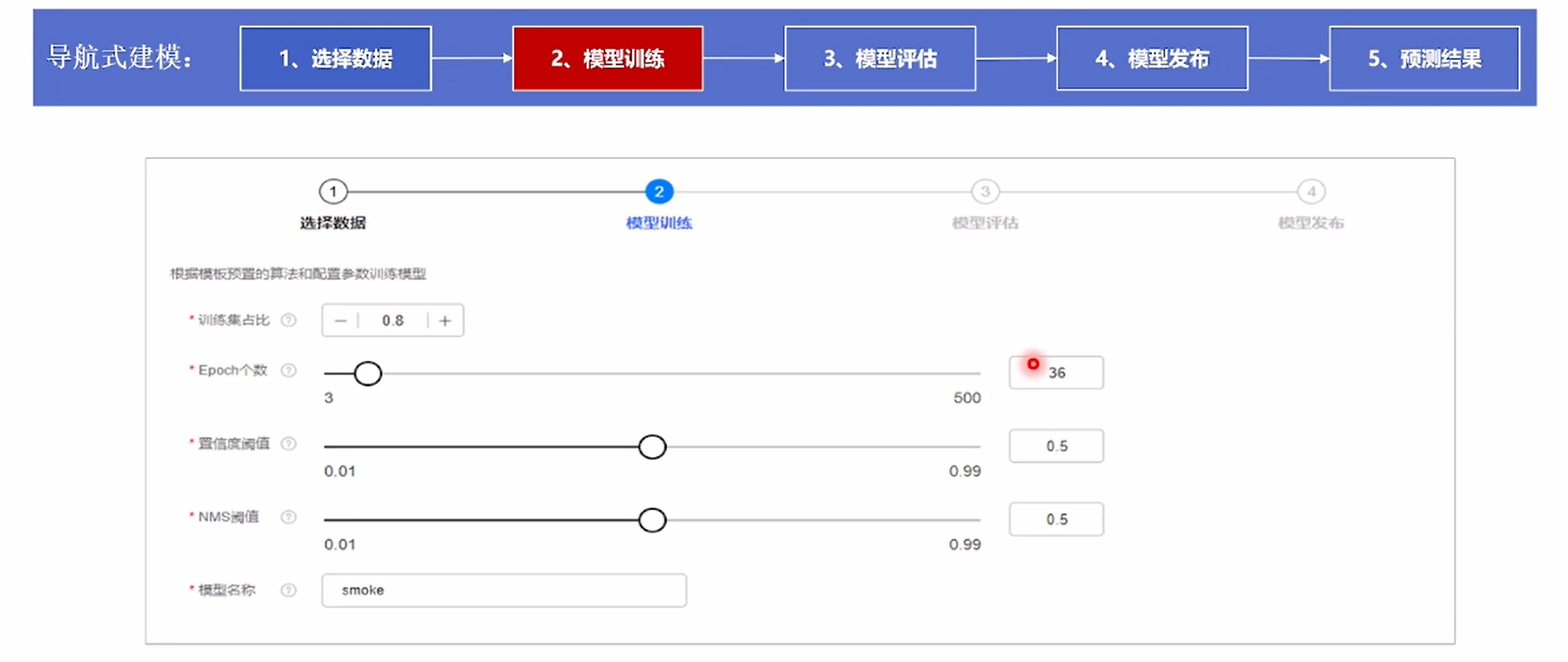
②模型训练:使用采集的数据集合,设置训练参数对模型进行训练。
③模型评估:根据平台提供的可视化界面对模型进行相应的评估。

④模型发布:配置相关资源参数即可完成发布。
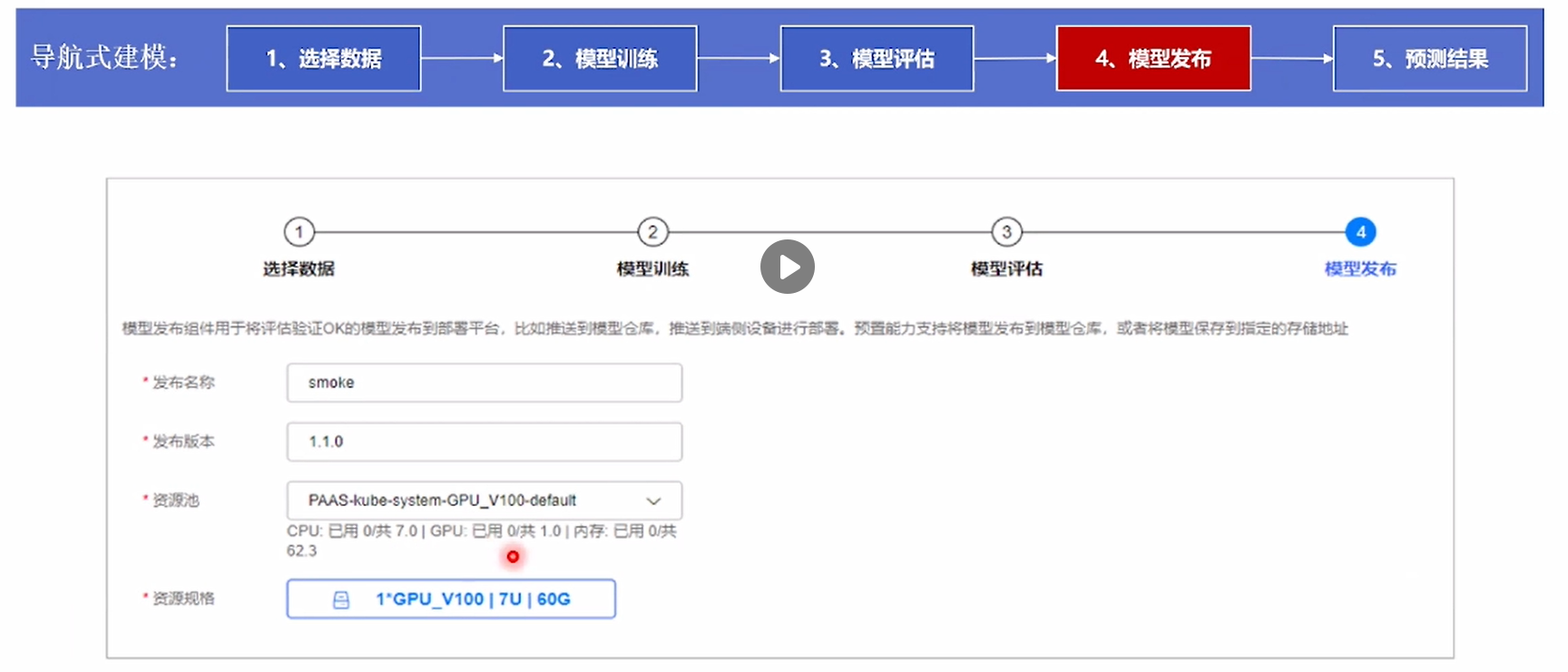
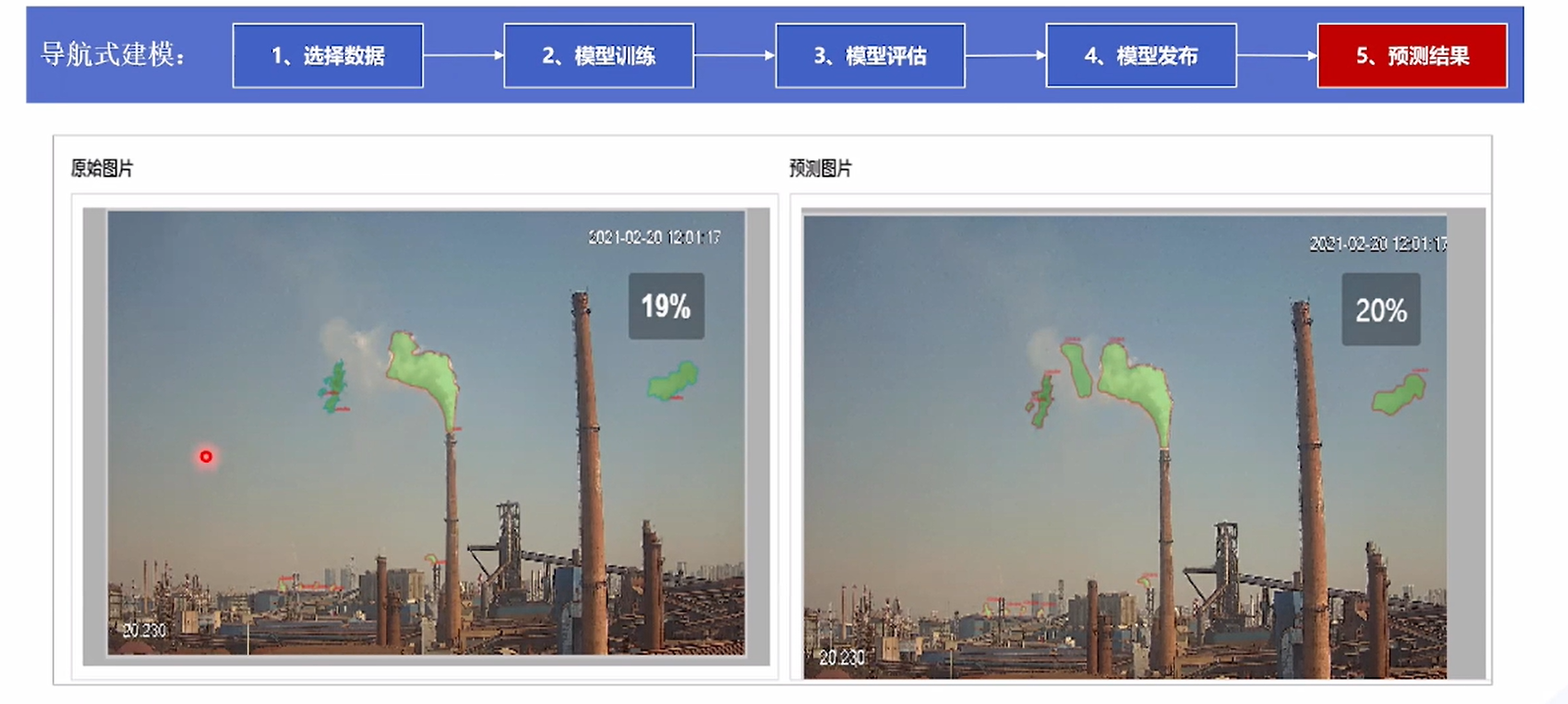
⑤预测结果:原始图片结果是19%,训练后的模型判断为20%
开发平台前端页面:

流程:创建实例——选择数据集——设置模型训练参数——设置模型评估参数——配置资源配置——训练模型——结果验证
以创建花卉结构分类模型为例:

①创建实例

②设置实例自定义参数,点击确定

③选择数据集,这里我们选择已有的iris数据集
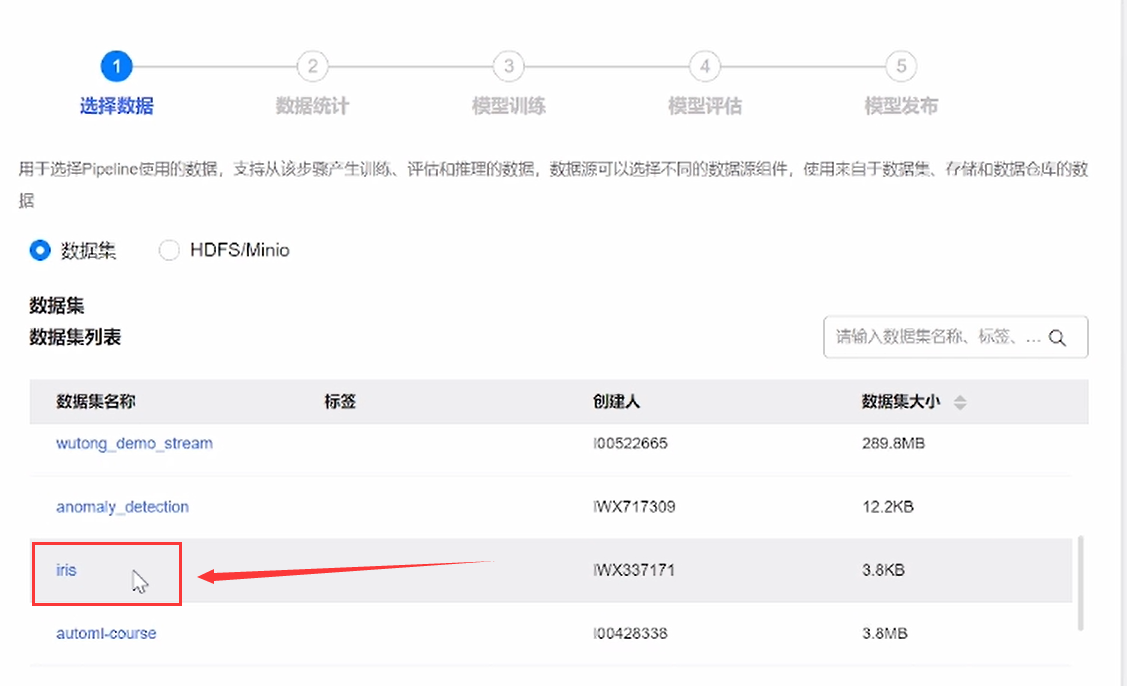
④此时显示已选数据iris,点击下一步

⑤设置模型训练参数

⑥设置模型评估参数,并选择验证用的数据集
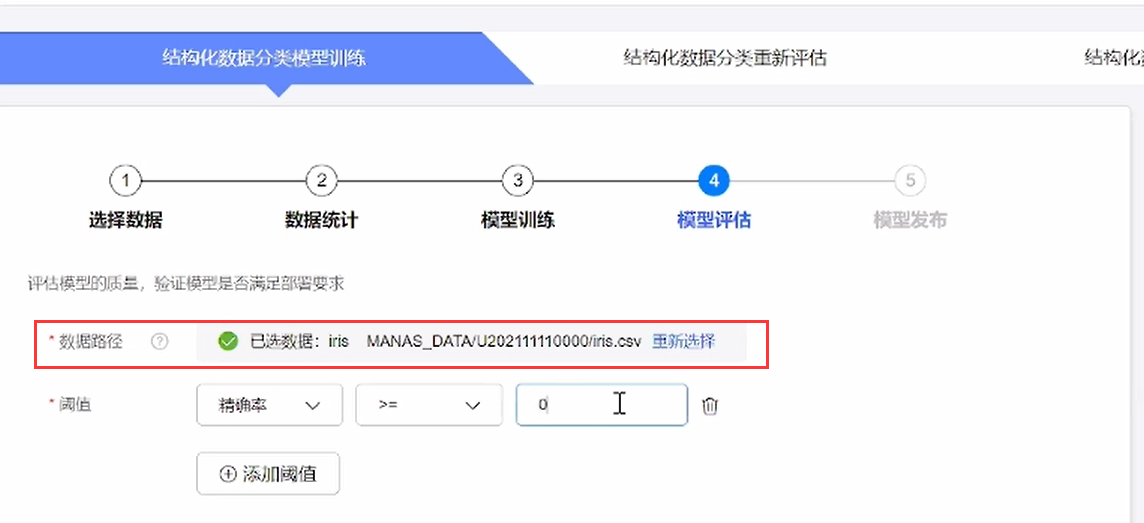
⑦配置发布信息,选择资源规格,即可开始训练
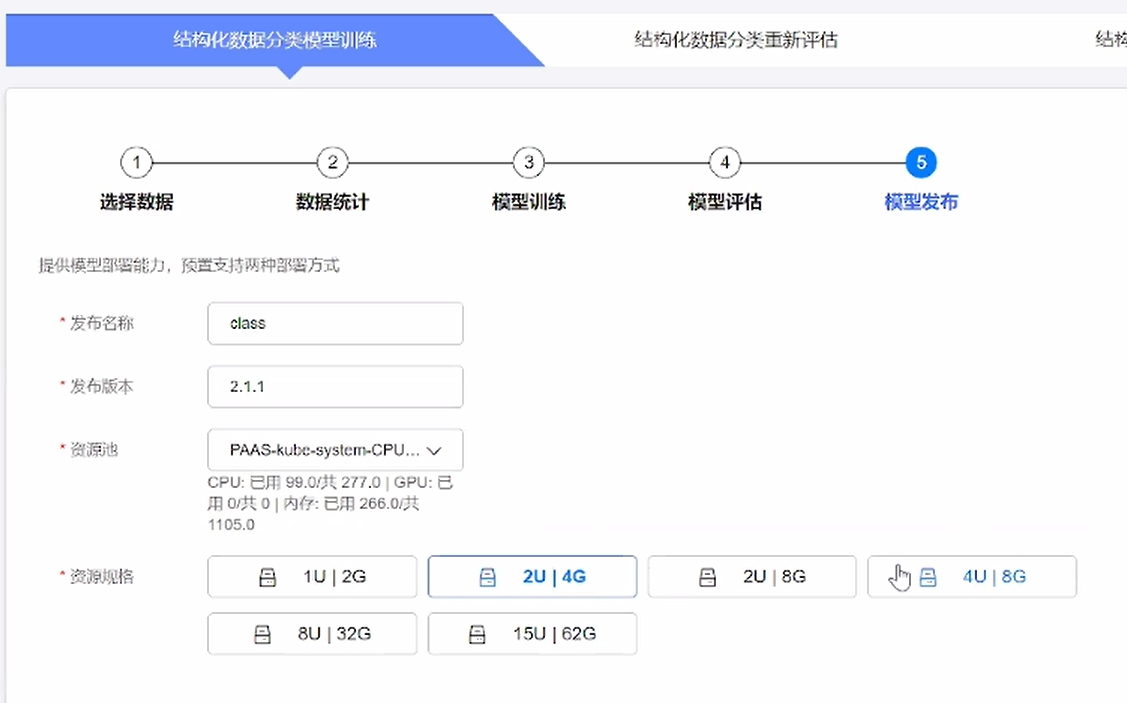
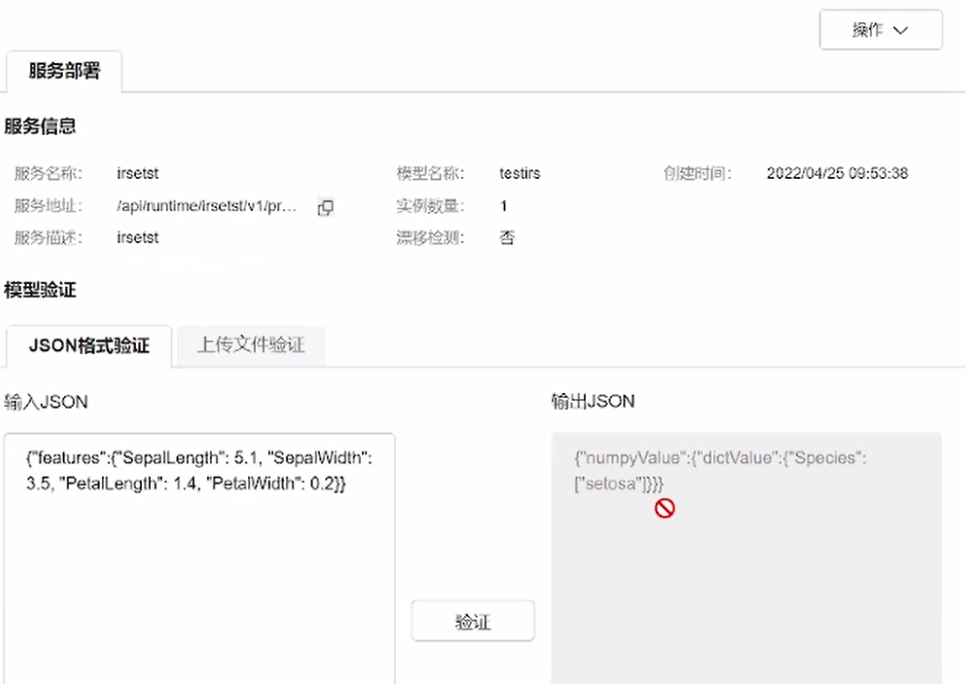
⑧结果验证——输入测试参数,即可得到通过AI训练模型得到的判断结果


面向AI开发者的一站式开发平台,提供样本自动化标注、大规模分布式训练、自动化模型生成等能力;提供图像、文字、知识图谱、自然语言处理、预测性维护等多种AI领域通用服务,使企业能快速开发和构建AI业务,支持电信网络、制造等行业自动化、智能化解决方案实现。
向导式、可视化进行AI建模,低建模门槛。
其他相关链接:
💗 “战胜恐惧的最好办法——做好准备、深呼吸、不卑不亢地直面它!”
💗 “少年心怀凌云志,骄阳亦须敬三分。”
——Created By 是羽十八ya
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl