大家好,我是Maynor。相信大家和我一样,都有一个大厂梦,作为一名资深大数据选手,深知SQL重要性,接下来我准备用100天时间,基于大数据岗面试中的经典SQL题,以每日1题的形式,带你过一遍热门SQL题并给出恰如其分的解答。
一路走来,随着问题加深,发现不会的也愈来愈多。但底气着实足了不少,相信不少朋友和我一样,日积月累才是最有效的学习方式!
基于附录2《借据表》统计下述指标,请提供Vintage统计SQL(mobX指的是发放后第X月末的不良余额/发放月金额)
| 发放月份 | 发放金额 | MOB1 | MOB2 | MOB3 | MOB4 | MOB5 | MOB6 | MOB7 | MOB8 | MOB9 | MOB10 | MOB11 | MOB12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2019-10 | |||||||||||||
| 2019-11 | |||||||||||||
| 2019-12 | |||||||||||||
| 2020-01 | |||||||||||||
| 2020-02 | |||||||||||||
| 2020-03 | |||||||||||||
| 2020-04 | |||||||||||||
| 2020-05 | |||||||||||||
| 2020-06 | |||||||||||||
| 2020-07 | |||||||||||||
| 2020-08 | |||||||||||||
| 2020-09 | |||||||||||||
| 2020-10 |
链接:https://pan.baidu.com/s/1Wiv-LVYziVxm8f0Lbt38Gw?pwd=s4qc
提取码:s4qc
debt.txt文件
set spark.sql.shuffle.partitions=4;
create database webank_db;
use webank_db;
create or replace temporary view check_view (ds comment '日期分区',
sno comment '流水号', uid comment '用户id',
is_risk_apply comment '是否核额申请',
is_pass_rule comment '是否通过规则',
is_obtain_qutoa comment '是否授信成功', quota comment '授信金额',
update_time comment '更新时间')
as
values ('20201101', 's000', 'u000', 1, 1, 1, 700, '2020-11-01 08:12:12'),
('20201102', 's088', 'u088', 1, 1, 1, 888, '2020-11-02 08:12:12'),
('20201230', 's091', 'u091', 1, 1, 1, 789, '2020-12-30 08:12:12'),
('20201230', 's092', 'u092', 1, 0, 0, 0, '2020-12-30 08:12:12'),
('20201230', 's093', 'u093', 1, 1, 1, 700, '2020-12-30 08:12:12'),
('20201231', 's094', 'u094', 1, 1, 1, 789, '2020-12-31 08:12:12'),
('20201231', 's095', 'u095', 1, 1, 1, 600, '2020-12-31 08:12:12'),
('20201231', 's096', 'u096', 1, 1, 0, 0, '2020-12-31 08:12:12')
;
--创建核额流水表
drop table if exists check_t;
create table check_t (
sno string comment '流水号',
uid string,
is_risk_apply bigint,
is_pass_rule bigint,
is_obtain_qutoa bigint,
quota decimal(30,6), update_time string
) partitioned by (ds string comment '日期分区');
--动态分区需要设置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table check_t partition (ds) select sno,
uid, is_risk_apply, is_pass_rule, is_obtain_qutoa, quota,
update_time,
ds
from check_view;
-- 创 建 借 据 表
create table debt(
duebill_id string comment '借据号',
uid string, prod_type string,
putout_date string,
putout_amt decimal(30, 6),
balance decimal(30, 6),
is_buliang int,
overduedays int
)partitioned by (ds string comment '日期分区');
--资料提供了一个34899条借据数据的文件
--下面补充如何将文件的数据导入到分区表中。需要一个中间普通表过度。
drop table if exists webank_db.debt_temp;
create table webank_db.debt_temp(
duebill_id string comment '借据号', uid string,
prod_type string,
putout_date string, putout_amt decimal(30, 6),
balance decimal(30,6),
is_buliang int, overduedays int,
ds string comment '日期分区'
) row format delimited fields terminated by 't';
load data local inpath '/root/debt.txt' overwrite into table webank_db.debt_temp;
--动态分区需要设置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table webank_db.debt partition (ds)
select * from webank_db.debt_temp;
--技巧:如果查询debt表,由于分区数太多,导致查询很慢。
-- 开发阶段,我们可以事先将表缓存起来,并且降低分区数比如为6,那么查缓存表大大提升了开发效率。
-- 上线阶段,再用实际表替换缓存表。
--首次缓存会耗时慢
cache table cache_debt as select /+ coalesce(6) / from
debt;
--第二次使用缓存会很快
select count(*) from cache_debt;
select ds,count(1) from cache_debt group by ds;


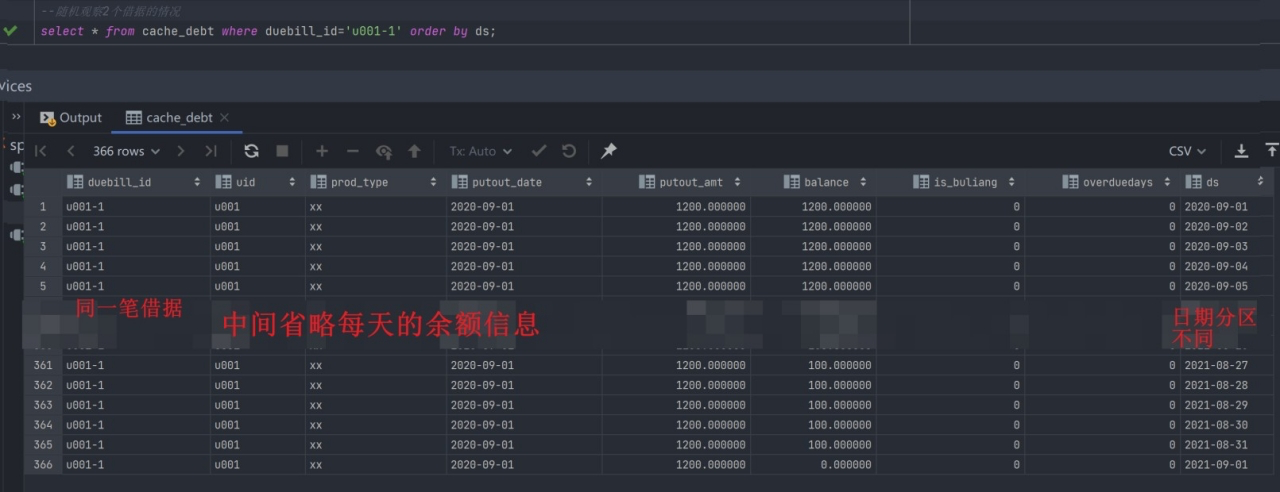
随机观察2个借据的情况
*select* * *from* cache_debt *where* duebill_id='u001-1' *order by* ds;
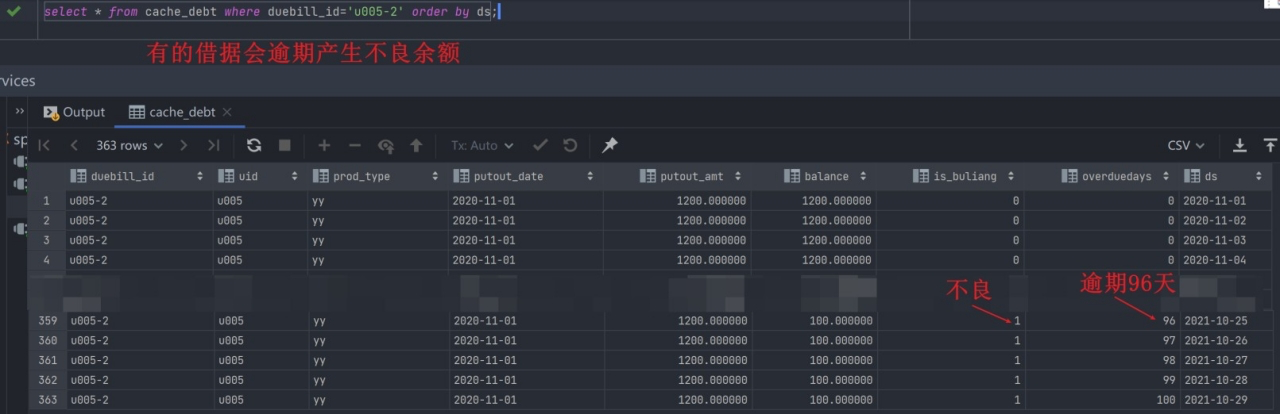
*select* * *from* cache_debt *where* duebill_id='u005-2' *order by* ds;
分3个大步骤:
步骤1:形成临时表1_每月的总发放金额
| 发放月份 | 发放金额 |
|---|---|
| 2019-10 | aa |
| 2019-11 | bb |
| 2019-12 | cc |
| 2020-01 | dd |
| 2020-02 | ee |
| 2020-03 | ff |
| 2020-04 | gg |
| 2020-05 | hh |
步骤2:形成临时表2_发放后第几个月末时的不良余额
| 发放后第几个月末时的不良余额(元) | ||||||||
|---|---|---|---|---|---|---|---|---|
| 发放月份 | 1月后 | 2月后 | 3月后 | 4月后 | 5月后 | 6月后 | 7月后 | 8月后 |
| 2019-10 | a1 | a2 | a3 | a4 | a5 | a6 | a7 | a8 |
| 2019-11 | b1 | b2 | b3 | b4 | b5 | b6 | b7 | b8 |
| 2019-12 | c1 | c2 | c3 | c4 | c5 | c6 | c7 | c8 |
| 2020-01 | d1 | d2 | d3 | d4 | d5 | d6 | d7 | d8 |
| 2020-02 | e1 | e2 | e3 | e4 | e5 | e6 | e7 | e8 |
| 2020-03 | f1 | f2 | f3 | f4 | f5 | f6 | f7 | f8 |
| 2020-04 | g1 | g2 | g3 | g4 | g5 | g6 | g7 | g8 |
| 2020-05 | h1 | h2 | h3 | h4 | h5 | h6 | h7 | h8 |
步骤3:用上面的临时表1关联临时表2,用临时表2的每个值除以临时表的总金额。
| 发放后第几个月末时的不良余额占发放金额的比例 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 发放月份 | 发放金额 | 1月后 | 2月后 | 3月后 | 4月后 | 5月后 | 6月后 | 7月后 | 8月后 |
| 2019-10 | aa | a1/aa | a2/aa | a3/aa | a4/aa | a5/aa | a6/aa | a7/aa | a8/aa |
| 2019-11 | bb | b1/bb | b2/bb | b3/bb | b4/bb | b5/bb | b6/bb | b7/bb | b8/bb |
| 2019-12 | cc | c1/cc | c2/cc | c3/cc | c4/cc | c5/cc | c6/cc | c7/cc | c8/cc |
| 2020-01 | dd | d1/dd | d2/dd | d3/dd | d4/dd | d5/dd | d6/dd | d7/dd | d8/dd |
| 2020-02 | ee | e1/ee | e2/ee | e3/ee | e4/ee | e5/ee | e6/ee | e7/ee | e8/ee |
| 2020-03 | ff | f1/ff | f2/ff | f3/ff | f4/ff | f5/ff | f6/ff | f7/ff | f8/ff |
| 2020-04 | gg | g1/gg | g2/gg | g3/gg | g4/gg | g5/gg | g6/gg | g7/gg | g8/gg |
| 2020-05 | hh | h1/hh | h2/hh | h3/hh | h4/hh | h5/hh | h6/hh | h7/hh | h8/hh |
建议你先动脑思考,动手写一写再对照看下答案,如果实在不懂可以点击下方卡片,回复:大厂sql 即可。
参考答案适用HQL,SparkSQL,FlinkSQL,即大数据组件,其他SQL需自行修改。
点击下方卡片关注 联系我进群
或者直接私信我进群
| 字段名 | 字段意义 | 字段类型 |
|---|---|---|
| ds | 日期分区,样例格式为20200101,每个分区有全量流水 | string |
| sno | 每个ds内主键,流水号 | string |
| uid | 户id | string |
| is_risk_apply | 是否核额申请(核额漏斗第一步)取值0和1 | bigint |
| is_pass_rule | 是否通过规则(核额漏斗第二步)取值0和1 | bigint |
| is_obtain_qutoa | 是否授信成功(核额漏斗第三步)取值0和1 | bigint |
| quota | 授信金额 | decimal(30,6) |
| update_time | 更新时间样例格式为2020-11-14 08:12:12 | string |
| 字段名 | 字段意义 | 字段类型 |
|---|---|---|
| ds | 日期分区,样例格式为20200101每个分区有全量借据 | string |
| duebilid | 借据号(每个日期分区内的主键) | string |
| uid | 用户id | string |
| prod_type | 产品名称仅3个枚举值XX贷YY贷ZZ贷 | string |
| putout_date | 发放日期样例格式为2020-10-10 00:10:30 | bigint |
| putout_amt | 发放金额 | decimal(30,6) |
| balance | 借据余额 | decimal(30,6) |
| is_buliang | 状态-是否不良取值0和1 | bigint |
| overduedays | 逾期天数 | bigint |
| 字段名 | 字段意义 | 字段类型 |
|---|---|---|
| ds | 日期分区,样例格式为20200101增量表部分流水记录可能有更新 | string |
| sno | 流水号,主键 | string |
| create time | 创建日期样例格式为2020-10-10 00:10:30与sno唯一绑定,不会变更 | string |
| uid | 用户id | string |
| content | son格式key值名称为V01~V06,value值取值为0和1 | string |
| create_time | 更新日期样例格式为2020-10-1000:10:30 | string |
提高SQL功底的思路。
1、造数据。因为有数据支撑,会方便我们根据数据结果去不断调整SQL的写法。
造数据语法既可以create table再insert into,也可以用下面的create temporary view xx as values语句,更简单。
其中create temporary view xx as values语句,SparkSQL语法支持,hive不支持。
2、先将结果表画出来,包括结果字段名有哪些,数据量也画几条。这是分析他要什么。
从源表到结果表,一路可能要走多个步骤,其实就是可能需要多个子查询,过程多就用with as来重构提高可读性。
3、要由简单过度到复杂,不要一下子就写一个很复杂的。
先写简单的select from table…,每个中间步骤都执行打印结果,看是否符合预期, 根据中间结果,进一步调整修饰SQL语句,再执行,直到接近结果表。
4、数据量要小,工具要快,如果用hive,就设置set hive.exec.mode.local.auto=true;如果是SparkSQL,就设置合适的shuffle并行度,set spark.sql.shuffle.partitions=4;
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 Maynor 原创,首发于 CSDN博客🙉
📢不能老盯着手机屏幕,要不时地抬起头,看看老板的位置⭐
📢专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12182595.html
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
我找到了这样的东西:Rails:Howtolistdatabasetables/objectsusingtheRailsconsole?这一行没问题:ActiveRecord::Base.connection.tables并返回所有表但是ActiveRecord::Base.connection.table_structure("users")产生错误:ActiveRecord::Base.connection.table_structure("projects")我认为table_structure不是Postgres方法。如何列出Postgres数据库的Rails控制台中表中的所有
Ruby中防止SQL注入(inject)的好方法是什么? 最佳答案 直接使用ruby?使用准备好的语句:require'mysql'db=Mysql.new('localhost','user','password','database')statement=db.prepare"SELECT*FROMtableWHEREfield=?"statement.execute'value'statement.fetchstatement.close 关于ruby-防止SQL注入(inject
我有一个任务列表(名称、starts_at),我试图在每日View中显示它们(就像iCal)。deftodays_tasks(day)Task.find(:all,:conditions=>["starts_atbetween?and?",day.beginning,day.ending]end我不知道如何将Time.now(例如“2009-04-1210:00:00”)动态转换为一天的开始(和结束),以便进行比较。 最佳答案 deftodays_tasks(now=Time.now)Task.find(:all,:conditio
我正在编写一个Rails应用程序,它将监视某些特定数据库的数据质量。为了做到这一点,我需要能够对这些数据库执行直接SQL查询——这当然与用于驱动Rails应用程序模型的数据库不同。简而言之,这意味着我无法使用通过ActiveRecord基础连接的技巧。我需要连接的数据库在设计时是未知的(即:我不能将它们的详细信息放在database.yaml中)。相反,我有一个模型“database_details”,用户将使用它来输入应用程序将在运行时执行查询的数据库的详细信息。因此与这些数据库的连接实际上是动态的,细节仅在运行时解析。 最佳答案
所有题目均有五种语言实现。C实现目录、C++实现目录、Python实现目录、Java实现目录、JavaScript实现目录题目n行m列的矩阵,每个位置上有一个元素你可以上下左右行走,代价是前后两个位置元素值差的绝对值.另外,你最多可以使用一次传送阵(只能从一个数跳到另外一个相同的数)求从走上角走到右下角最少需要多少时间。输入描述:第一行两个整数n,m,分别代表矩阵的行和列。后面n行,每行m个整数,分别代表矩阵中的元素。输出描述:一个整数,表示最少需要多少时间。
什么是0day漏洞?0day漏洞,是指已经被发现,但是还未被公开,同时官方还没有相关补丁的漏洞;通俗的讲,就是除了黑客,没人知道他的存在,其往往具有很大的突发性、破坏性、致命性。0day漏洞之所以称为0day,正是因为其补丁永远晚于攻击。所以攻击者利用0day漏洞攻击的成功率极高,往往可以达到目的并全身而退,而防守方却一无所知,只有在漏洞公布之后,才后知后觉,却为时已晚。“后知后觉、反应迟钝”就是当前安全防护面对0day攻击的真实写照!为了方便大家理解,中科三方为大家梳理当前安全防护模式下,一个漏洞从发现到解决的三个时间节点:T0:此时漏洞即0day漏洞,是已经被发现,还未被公开,官方还没有相