本文主要介绍下mybatis的延迟加载,从原理上介绍下怎么使用、有什么好处能规避什么问题。延迟加载一般用于级联查询(级联查询可以将主表不能直接查询的数据使用自定义映射规则调用字表来查,主查询查完之后通过某个column列或多个列将查询结果传递给子查询,子查询再根据主查询传递的参数进行查询,最后将子查询结果进行映射)。mybatis的懒加载是通过创建代理对象来实现的,只有当调用getter等方法的时候才会去查询子查询,查询后完成设值再获取值。
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
this.useConstructorMappings = false; // reset previous mapping result
final List<Class<?>> constructorArgTypes = new ArrayList<>();
final List<Object> constructorArgs = new ArrayList<>();
// 创建result接收对象
Object resultObject = createResultObject(rsw, resultMap, constructorArgTypes, constructorArgs, columnPrefix);
if (resultObject != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
// 处理其他属性properties
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
for (ResultMapping propertyMapping : propertyMappings) {
// issue gcode #109 && issue #149 创建代理
if (propertyMapping.getNestedQueryId() != null && propertyMapping.isLazy()) {
resultObject = configuration.getProxyFactory().createProxy(resultObject, lazyLoader, configuration, objectFactory, constructorArgTypes, constructorArgs);
break;
}
}
}
// 使用有参构造函数创建了对象
this.useConstructorMappings = resultObject != null && !constructorArgTypes.isEmpty(); // set current mapping result
return resultObject;
}通过mybatis代码propertyMapping.getNestedQueryId() != null && propertyMapping.isLazy()发现只有当存在嵌套查询select子句和isLazy=true的时候才会创建代理,那么isLazy=true是什么条件,从创建ResultMapping的代码中可以看到boolean lazy = "lazy".equals(context.getStringAttribute("fetchType", configuration.isLazyLoadingEnabled() ? "lazy" : "eager")); 只有手动设置fetchType=lazy或者全局设置configuration的lazyLoadingEnabled=true,两者缺一不可。
关于代理是通过Javassist创建的,下面有一个简单的例子
public class HelloMethodHandler implements MethodHandler {
private Object target;
public HelloMethodHandler(Object o) {
this.target = o;
}
@Override
public Object invoke(Object self, Method thisMethod, Method proceed, Object[] args) throws Throwable {
String methodName = thisMethod.getName();
if (methodName.startsWith("get")) {
System.out.println("select database....");
// 进行sql查询到结果并set设置值
((Student)self).setName("monian");
}
return proceed.invoke(self, args);
}
public static void main(String[] args) throws Exception {
Student student = new Student();
ProxyFactory proxyFactory = new ProxyFactory();
proxyFactory.setSuperclass(Student.class);
Constructor<Student> declaredConstructor = Student.class.getDeclaredConstructor();
Object o = proxyFactory.create(declaredConstructor.getParameterTypes(), new Object[]{});
((Proxy)o).setHandler(new HelloMethodHandler(student));
Student proxy = (Student)o;
System.out.println(proxy.getName());
}
}mybatis的原理就是通过创建一个代理对象,当通过这个代理对象调用getter、is、equals、clone、toString、hashCode等方法时会调用select子查询,然后完成设置,最后取值就像早就获取到一样。
public class UserDO {
private Integer userId;
private String username;
private String password;
private String nickname;
private List<PermitDO> permitDOList;
public UserDO() {}
}
<resultMap id="BaseMap" type="org.apache.ibatis.study.entity.UserDO">
<id column="user_id" jdbcType="INTEGER" property="userId" />
<result column="username" jdbcType="VARCHAR" property="username" />
<result column="password" jdbcType="VARCHAR" property="password" />
<result column="nickname" jdbcType="VARCHAR" property="nickname"/>
<collection property="permitDOList" column="user_id" select="getPermitsByUserId"
fetchType="lazy">
</collection>
</resultMap>
<resultMap id="PermitBaseMap" type="org.apache.ibatis.study.entity.PermitDO">
<id column="id" jdbcType="INTEGER" property="id"/>
<result column="code" jdbcType="VARCHAR" property="code"/>
<result column="name" jdbcType="VARCHAR" property="name"/>
<result column="type" jdbcType="TINYINT" property="type"/>
<result column="pid" jdbcType="INTEGER" property="pid"/>
</resultMap>
<select id="getByUserId2" resultMap="BaseMap">
select * from user
where user_id = #{userId}
</select>
<select id="getPermitsByUserId" resultMap="PermitBaseMap">
select p.*
from user_permit up
inner join permit p on up.permit_id = p.id
where up.user_id = #{userId}
</select>通过fetchType=lazy指定子查询getPermitsByUserId使用懒加载,这样的话就不用管全局配置lazyLoadingEnabled是true还是false了。当然这里可以直接用多表关联查询不使用子查询,使用方法在上一篇文章
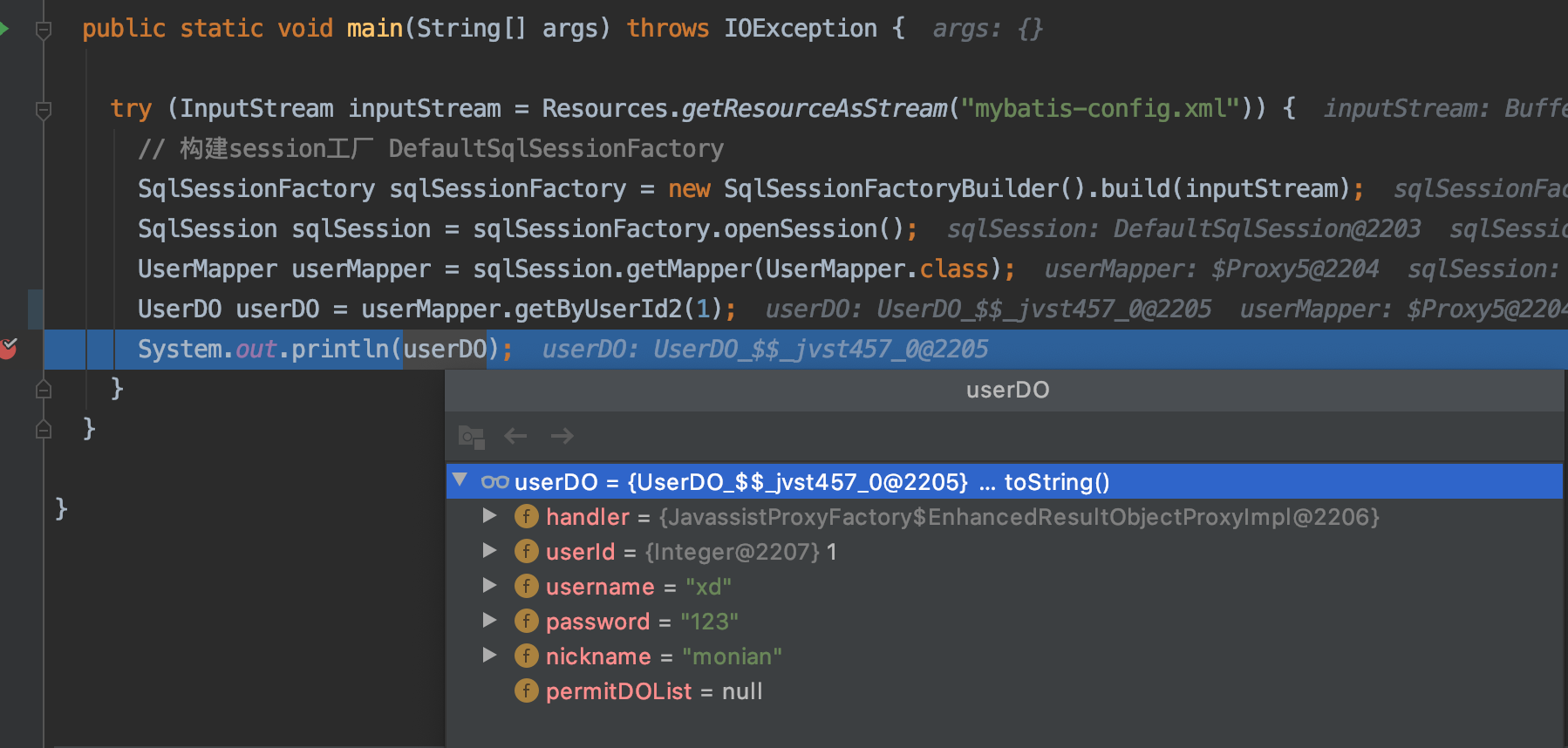
测试代码
public class Test {
public static void main(String[] args) throws IOException {
try (InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml")) {
// 构建session工厂 DefaultSqlSessionFactory
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
UserDO userDO = userMapper.getByUserId2(1);
System.out.println(userDO);
}
}
}结果如下,打了断点可以看到原userDO对象已被代理并且permitDOList是null需要调用get方法才会去查询拿到值,咳咳这边之前直接运行显示是已经把permitDOList查询出来了,想了半天啥原因后来才发现println会调用userDO对象的toString方法,而toString方法也会走代理方法直接去调用子查询的

延迟加载主要能解决mybatis的N+1问题,什么是N+1问题其实叫1+N更为合理,以上面的业务例子来说就是假设一次查询出来10000个用户,那么还需要针对这10000个用户使用子查询getPermitsByUserId获取每个用户的权限列表,需要10000次查询,总共10001次,真实情况下你可能并不需要每个子查询的结果,这样就浪费数据库连接资源了。如果使用延迟加载的话就相当于不用进行这10000次查询,因为它是等到你真正使用的时候才会调用子查询获取结果。
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
是否可以在所有delayed_job任务之前运行一个方法?基本上,我们试图确保每个运行delayed_job的服务器都有我们代码的最新实例,所以我们想运行一个方法来在每个作业运行之前检查它。(我们已经有了“check”方法并在别处使用它。问题只是关于如何从delayed_job中调用它。) 最佳答案 现在有一种官方方法可以通过插件来做到这一点。这篇博文通过示例清楚地描述了如何执行此操作http://www.salsify.com/blog/delayed-jobs-callbacks-and-hooks-in-rails(本文中描述
如何只加载map边界内的标记gmaps4rails?当然,在平移和/或缩放后加载新的。与此直接相关的是,如何获取map的当前边界和缩放级别? 最佳答案 我是这样做的,我只在用户完成平移或缩放后替换标记,如果您需要不同的行为,请使用不同的事件监听器:在你看来(index.html.erb):{"zoom"=>15,"auto_adjust"=>false,"detect_location"=>true,"center_on_user"=>true}},false,true)%>在View的底部添加:functiongmaps4rail
我需要做这样的事情classUser'User',:foreign_key=>'abuser_id'belongs_to:gameendclassGame['JOINabuse_reportsONusers.id=abuse_reports.abuser_id','JOINgamesONgames.id=abuse_reports.game_id'],:group=>'users.id',:select=>'users.*,count(distinctgames.id)ASgame_count,count(abuse_reports.id)asabuse_report_count',:
我指的是pubrailscasttutorial并已正确执行所有步骤,但在运行最后一个命令时,即rackupprivate_pub.ru-sthin-Eproduction为了架设faye服务器,我收到以下错误:/usr/lib/ruby/1.9.1/rubygems/custom_require.rb:36:in`require':cannotloadsuchfile--thin(LoadError)from/usr/lib/ruby/1.9.1/rubygems/custom_require.rb:36:in`require'from/var/lib/gems/1.9.1/gems
我们在服务器端遇到libxml-rubygem的问题可能是因为它使用x86_64架构:$uname-aLinuxip-10-228-171-642.6.21.7-2.fc8xen-ec2-v1.0#1SMPTueSep110:25:30EDT2009x86_64GNU/Linuxrequire'libxml'LoadError:/usr/local/ruby-enterprise/lib/ruby/gems/1.8/gems/libxml-ruby-1.1.4/lib/libxml_ruby.so:invalidELFheader-/usr/local/ruby-enterprise/
我不太确定为什么这不起作用,我一直在寻找解决方案。很简单,我正在运行一个执行require'CSV'的小脚本。,它在我的Mac1.9.3-p327上运行良好,但在p374上的服务器上无法运行。我得到的错误是/home/deployer/.rbenv/versions/1.9.3-p374/lib/ruby/1.9.1/rubygems/custom_require.rb:36:inrequire':cannotloadsuchfile--CSV(LoadError)from/home/deployer/.rbenv/versions/1.9.3-p374/lib/ruby/1.9.1/