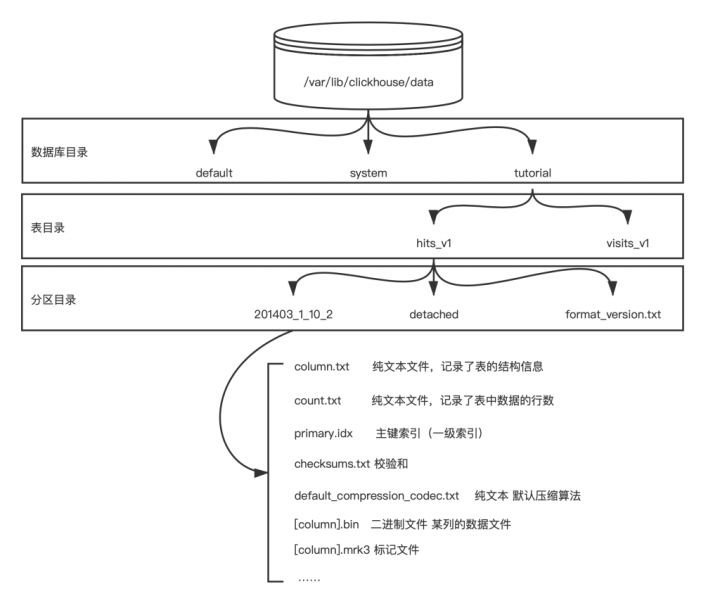
| 目录名 | 类型 | 说明 |
| 202103_1_10_2 | 目录 | 分区目录一个或多个,由于分区+LSM生成的 |
| detached | 目录 | 通过DETACH语句卸载后的表分区存放位置 |
| format_version.txt | 文本文件 | 纯文本,记录存储的格式 |
columns.txt:该文件是一个文本文件,存储了表结构信息,可以用文本编辑打开。
count.txt:该文件也是一个文本文件,存储了该分区下的行数。可以用文本文件打开。在用户执行select count(*) from xxx时本质上就是直接返回了该文件的内容,而不需要遍历数据。因此clickhouse的count(*)的速度非常快。
[column].bin:真正存储数据的数据文件。每一列都会生成一个单独的bin文件。
skp_idx_[column].idx:跳数索引,在使用了二级索引时会生成,否则这不生成。
比如20221115_2_2_0,其中 20221115是分区ID ,2_2对应的是最小的数据块编号和最大的数据块编号,最后的 _0 表示目前分区合并的层级。这么命名是为了数据目录合并算法。
分区ID:该值由 insert 数据时分区键的值来决定。分区键支持使用任何一个或者多个字段组合表达式,针对取值数据类型的不同,分区ID的生成逻辑目前有四种规则:
MinBlockNum 和 MaxBlockNum: BlockNum 是一个整型的自增长型编号,该编号在单张MergeTree表中从1开始全局累加,当有新的分区目录创建后,该值就加1,对新的分区目录来讲,MinBlockNum 和 MaxBlockNum 取值相同。
Level: 表示合并的层级。相当于某个分区被合并的次数,它不是以表全局累加,而是以分区为单位,初始创建的分区,初始值为0,相同分区ID发生合并动作时,在相应分区内累计加1。
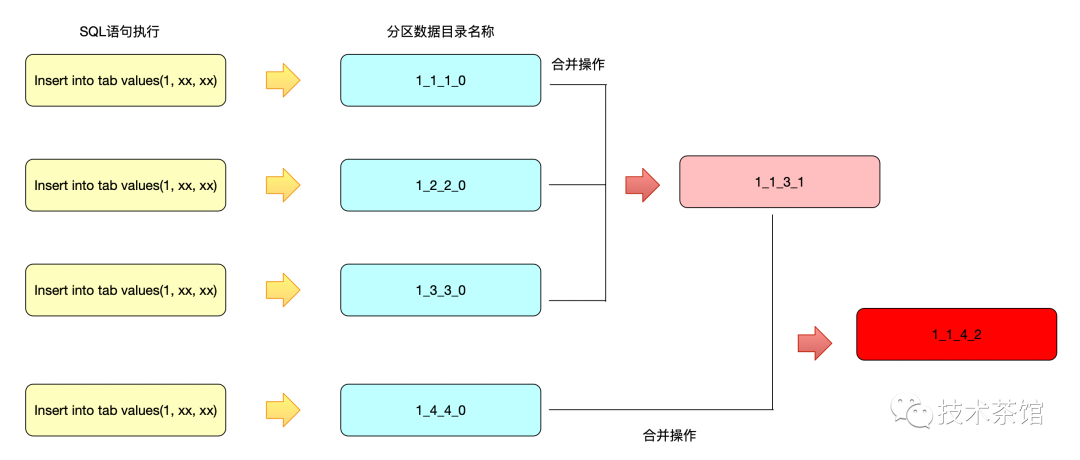
MergeTree的分区目录和传统意义上其他数据库有所不同。MergeTree的分区目录并不是在数据表被创建之后就存在的,而是在数据写入过程中被创建的。也就是说如果一张数据表没有任何数据,那么也不会有任何分区目录存在。MergeTree的分区目录伴随着每一批数据的写入(一次INSERT语句),MergeTree都会生成一批新的分区目录。即便不同批次写入的数据属于相同分区,也会生成不同的分区目录。也就是说,对于同一个分区而言,也会存在多个分区目录的情况。在之后的某个时刻(写入后的10~15分钟,也可以手动执行optimize查询语句),ClickHouse会通过后台任务再将属于相同分区的多个目录合并成一个新的目录。已经存在的旧分区目录并不会立即被删除,而是在之后的某个时刻通过后台任务被删除(默认8分钟)。
但是有些特殊场景下,用户希望立刻删除老的数据目录,这种需求可以在创建MergeTree表的时候通过Settings属性来设置。如下所示
CREATE TABLE partition_directory_merge
(
partition_key Int32,
orderBy_key String,
data String
)
ENGINE = MergeTree()
PARTITION BY partition_key
ORDER BY orderBy_key
SETTINGS old_parts_lifetime = 1我正在使用active_admin,我在Rails3应用程序的应用程序中有一个目录管理,其中包含模型和页面的声明。时不时地我也有一个类,当那个类有一个常量时,就像这样:classFooBAR="bar"end然后,我在每个必须在我的Rails应用程序中重新加载一些代码的请求中收到此警告:/Users/pupeno/helloworld/app/admin/billing.rb:12:warning:alreadyinitializedconstantBAR知道发生了什么以及如何避免这些警告吗? 最佳答案 在纯Ruby中:classA
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
rpartition和partition有什么区别?我已经阅读了文档,但我认为它们是一样的。只是那些出现在后来的ruby版本中吗? 最佳答案 以下示例将有助于识别差异:"abccba".partition("b")#=>["a","b","ccba"]"abccba".rpartition("b")#=>["abcc","b","a"]所以区别在于rpartition搜索最右边的匹配项,而不是最左边的匹配项。 关于Rubyrpartition与分区?,我们在StackOverflow
是否可以在应用程序中包含的gem代码中知道应用程序的Rails文件系统根目录?这是gem来源的示例:moduleMyGemdefself.included(base)putsRails.root#returnnilendendActionController::Base.send:include,MyGem谢谢,抱歉我的英语不好 最佳答案 我发现解决类似问题的解决方案是使用railtie初始化程序包含我的模块。所以,在你的/lib/mygem/railtie.rbmoduleMyGemclassRailtie使用此代码,您的模块将在
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g
在我让另一个人重做我的前端UI之前,我的Rails应用程序运行平稳。我已经尝试解决此错误3天了。这是错误:Nosuchfileordirectory-identifyExtractedsource(aroundline#59):575859606162@post=Post.find(params[:id])authorize@postif@post.update_attributes(post_params)flash[:notice]="Postwasupdated."redirect_to[@topic,@post]else{"utf8"=>"✓","_method"=>"patc
有什么区别:@attr[:field]=new_value和@attr.merge(:field=>new_value) 最佳答案 如果您使用的是merge!而不是merge,则没有区别。唯一的区别是您可以在合并参数中使用多个字段(意思是:另一个散列)。例子:h1={"a"=>100,"b"=>200}h2={"b"=>254,"c"=>300}h3=h1.merge(h2)putsh1#=>{"a"=>100,"b"=>200}putsh3#=>{"a"=>100,"b"=>254,"c"=>300}h1.merge!(h2)pu
我正在尝试以一种更类似于普通RubyGem结构的方式构建我的Sinatra应用程序。我有以下文件树:.├──app.rb├──config.ru├──Gemfile├──Gemfile.lock├──helpers│ ├──dbconfig.rb│ ├──functions.rb│ └──init.rb├──hidden│ └──Rakefile├──lib│ ├──admin.rb│ ├──api.rb│ ├──indexer.rb│ ├──init.rb│ └──magnet.rb├──models│ ├──init.rb│ ├──invite.rb│ ├─
我想编写一个ruby脚本来递归复制目录结构,但排除某些文件类型。因此,给定以下目录结构:folder1folder2file1.txtfile2.txtfile3.csfile4.htmlfolder2folder3file4.dll我想复制这个结构,但不包含.txt和.cs文件。因此,生成的目录结构应如下所示:folder1folder2file4.htmlfolder2folder3file4.dll 最佳答案 您可以使用查找模块。这是一个代码片段:require"find"ignored_extensions=[".cs"
之前有人问过这个问题,我发现了以下clip关于如何一次设置一个类对象的所有属性,但由于批量分配保护,这在Rails中是不可能的。(例如,您不能Object.attributes={})有没有一种很好的方法可以将一个类的属性合并到另一个类中?object1.attributes=object2.attributes.inject({}){|h,(k,v)|h[k]=vifObjectModel.column_names.include?(k);h}谢谢。 最佳答案 利用assign_attributes使用:without_prote