文章目录
集群上的master部署情况,一台机器上同时部署了纯master角色和纯data角色的两个ES节点
elasticsearch.yml中的配置项discovery.zen.ping.unicast.hosts修改为ABCDEF。elasticsearch.yml中的配置项discovery.zen.ping.unicast.hosts修改为DEF。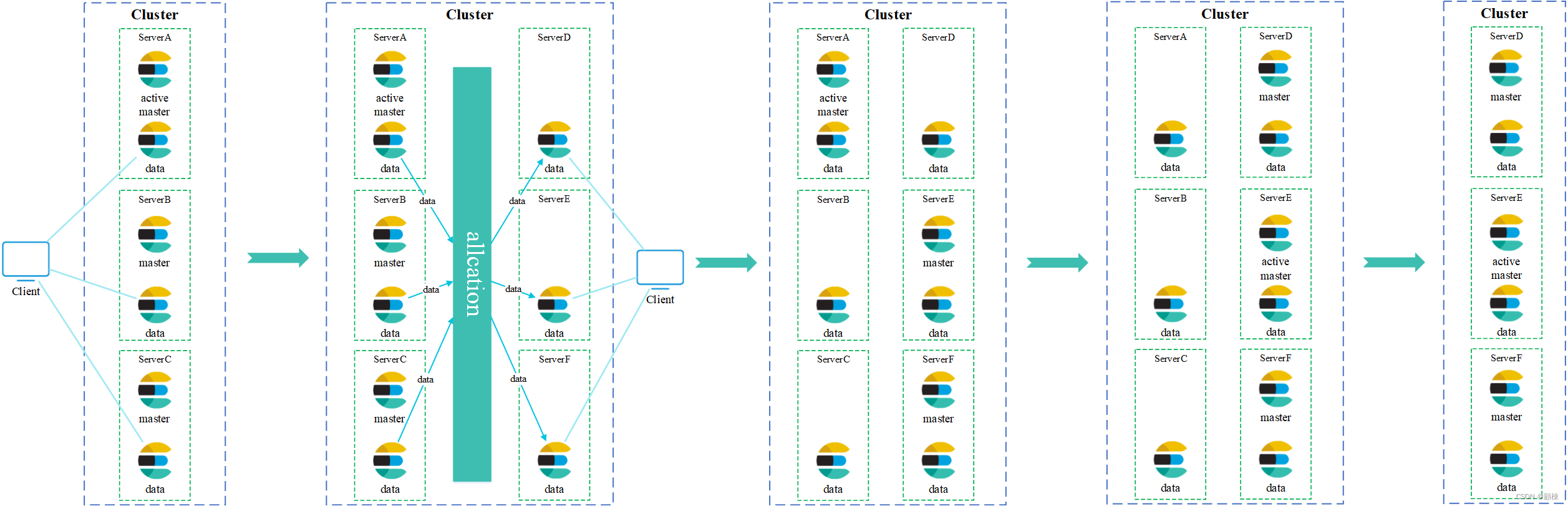
集群上的master部署情况,机器上的master角色是与data角色混在一个ES节点中
elasticsearch.yml中的配置项discovery.zen.ping.unicast.hosts修改为ABCDEF。elasticsearch.yml中的配置项discovery.zen.ping.unicast.hosts修改为DEF。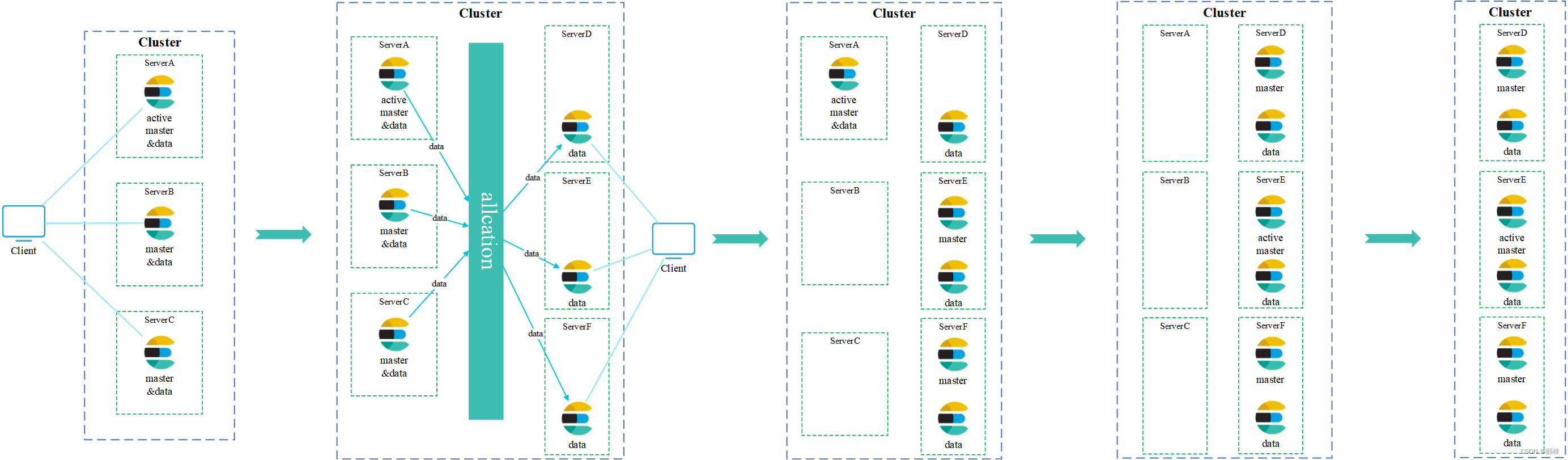
集群上的master部署情况,纯master角色ES节点和纯Data角色ES节点部署在不同的服务器上
elasticsearch.yml中的配置项discovery.zen.ping.unicast.hosts修改为DEFGHI。elasticsearch.yml中的配置项discovery.zen.ping.unicast.hosts修改为GHI。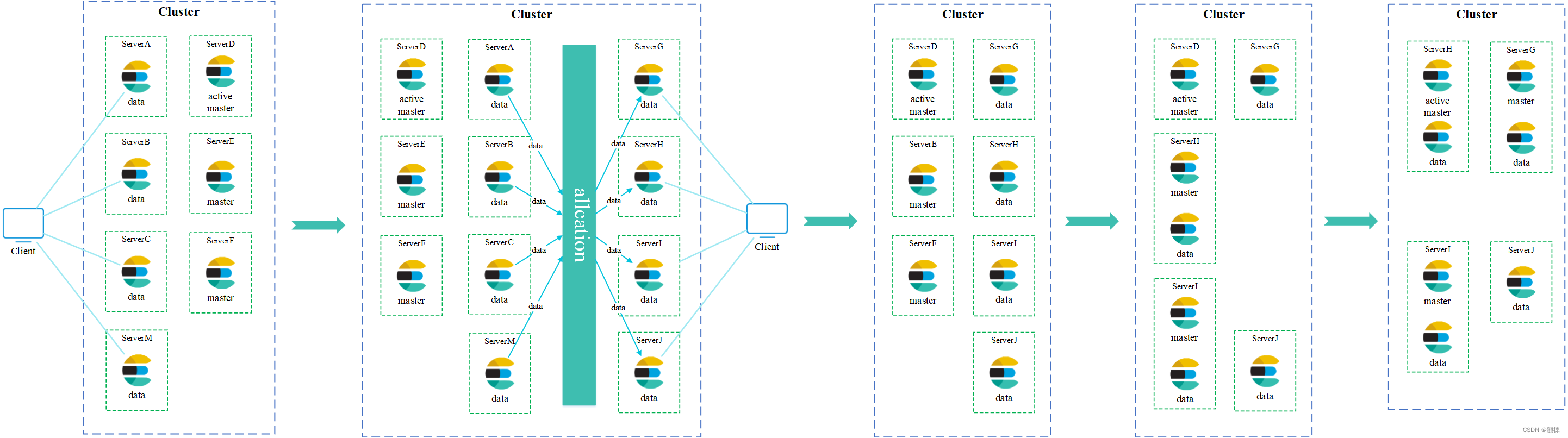
主要使用配置项cluster.routing.allocation.exclude._ip来实现数据迁移。
检查cluster.routing.allocation.exclude._ip配置项的值,如果没有,说明原来没有排除节点。
curl -X GET "http://{ip}:{port}/_cluster/settings?pretty"
清空数据节点的数据,{ip}:集群任意节点IP,{port}:http服务端口号,{ip1},{ip2}:需要排除数据的IP,将原来配置需要排除数据的节点IP加上本次排除数据的节点IP,以逗号分隔。
curl -X PUT "http://{ip}:{port}/_cluster/settings?pretty" -H 'Content-Type: application/json' -d'
{
"persistent" :{
"cluster.routing.allocation.exclude._ip" : "{ip1},{ip2}"
}
}'
检查数据节点上是否存在数据,结果中的IP列没有需要下线的IP,说明数据已经排尽,满足机器下线条件了。有的集群分片可能很多,可以将结果输出到文件查询。
curl -X GET "http://{ip}:{port}/_cat/shards?v&pretty&s=ip:desc"
index shard prirep state docs store ip node
config_s-20211108 1 r STARTED 0 130b 192.168.1.1 es03-prd
config_s-20211108 2 r STARTED 0 130b 192.168.1.1 es03-prd
config_s-20211108 0 p STARTED 0 130b 192.168.1.1 es03-prd
.monitoring-data-2 0 r STARTED 5 15.7kb 192.168.1.1 es03-prd
config_s-20211107 1 r STARTED 0 130b 192.168.1.1 es03-prd
config_s-20211107 2 r STARTED 0 130b 192.168.1.1 es03-prd
config_s-20211107 0 p STARTED 0 130b 192.168.1.1 es03-prd
index的副本分片数量的合理性
副本数 + 1 ≤ +1\leq +1≤data角色的节点数
单个ES数据节点的分片数量的合理性
官方的默认值是每个数据节点的分片数 ≤ \leq ≤ 1000,
https://www.elastic.co/guide/en/elasticsearch/reference/6.7/misc-cluster.html#cluster-shard-limit
大分片的数量

数据生命周期的调整
单机器多数据节点的 cluster.routing.allocation.same_shard.host 配置的调整,最佳为true。
允许执行检查,以防止基于主机名和主机地址在单个主机上分配同一分片的多个实例。 默认为false,表示默认情况下不执行任何检查。 仅当在同一台计算机上启动多个节点时,此设置才适用。
如何正确创建Rails迁移,以便将表更改为MySQL中的MyISAM?目前是InnoDB。运行原始执行语句会更改表,但它不会更新db/schema.rb,因此当在测试环境中重新创建表时,它会返回到InnoDB并且我的全文搜索失败。我如何着手更改/添加迁移,以便将现有表修改为MyISAM并更新schema.rb,以便我的数据库和相应的测试数据库得到相应更新? 最佳答案 我没有找到执行此操作的好方法。您可以像有人建议的那样更改您的schema.rb,然后运行:rakedb:schema:load,但是,这将覆盖您的数据。我的做法是(假设
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我正在创建一个新的Rails3.1应用程序。我希望这个新应用程序重用现有数据库(由以前的Rails2应用程序创建)。我创建了新的应用程序定义模型,它重用了数据库中的一些现有数据。在开发和测试阶段,一切正常,因为它在干净的表数据库上运行,但是当尝试部署到生产环境时,我收到如下消息:PGError:ERROR:column"email"ofrelation"users"alreadyexists***[err::localhost]:ALTERTABLE"users"ADDCOLUMN"email"charactervarying(255)DEFAULT''NOTNULL但是我在迁移中有这
我想使用PostgreSQL中的point类型。我已经完成了:railsgmodelTestpoint:point最终的迁移是:classCreateTests当我运行时:rakedb:migrate结果是:==CreateTests:migrating====================================================--create_table(:tests)rakeaborted!Anerrorhasoccurred,thisandalllatermigrationscanceled:undefinedmethod`point'for#/hom
我是Rails的新手,我是从Django背景开始接触它的。我已经接受了这样一个事实,即模型和数据库模式在Rails和在线Django中是分开的。但是,我仍在努力处理迁移。我的问题很简单-如何使用迁移向模型添加关系?例如,我现在有Artist和Song作为ActiveRecord::Base子类的空模型,没有任何关系。我需要开始做这件事:classArtist但是我如何使用railsgmigrate更改架构以反射(reflect)这一点?我正在使用Rails3.1.3。 最佳答案 现在,在Rails4中,您可以:classAddPro
文章目录1.任务背景2.任务目标3.相关知识点4.任务实操4.1安装配置JDK4.2启动FISCOBCOS4.3下载解压WeBASE-Front4.4拷贝sdk证书文件4.5启动节点4.6访问节点4.7检查运行状态5.任务总结1.任务背景FISCOBCOS其实是有控制台管理工具,用来对区块链系统进行各种管理操作。但是对于初学者来说,还是可视化界面更友好,本节就来介绍WeBASE管理平台,这是一款微众银行开源的自研区块链中间件平台,可以降低区块链使用的门槛,大幅提高区块链应用的开发效率。微众银行是腾讯牵头设立的民营银行,在国内民营银行里还是比较出名的。微众银行参与FISCOBCOS生态建设,一定
如何在rakedb:migrate:status中删除带有“**NOFILE**”的迁移ID列表?例如:StatusMigrationIDMigrationName--------------------------------------------------up20131017204224Createusersup20131218005823**********NOFILE**********up20131218011334**********NOFILE**********我不明白为什么当我自己手动删除它时它仍然保留旧的迁移文件,因为我正在研究迁移的工作原理。这是为了记录吗?但