本文基于Dubbo2.6.x版本,中文注释版源码已上传github:xiaoguyu/dubbo
上一篇文章,讲了Dubbo的服务导出:
本文,咱们来聊聊Dubbo的服务引用。
本文案例来自Dubbo官方Demo,路径为:
dubbo/dubbo-demo/dubbo-demo-consumer/
Dubbo服务引用对象的生成,是在ReferenceBean#getObject()方法中
其生成时机有两个:
饿汉式
ReferenceBean对象继承了InitializingBean接口
public void afterPropertiesSet() throws Exception {
......
Boolean b = isInit();
if (b == null && getConsumer() != null) {
b = getConsumer().isInit();
}
if (b != null && b.booleanValue()) {
getObject();
}
}
从代码可以看出,需要开启init属性
懒汉式
因为ReferenceBean继承了FactoryBean接口,当服务被注入到其他类中时,Spring会调用getObject方法
而服务的调用方式分三种:
不管是哪种引用方式,最后都会得到一个 Invoker 实例。
我们再次看看Invoker的官方解释:
Invoker 是实体域,它是 Dubbo 的核心模型,其它模型都向它靠扰,或转换成它,它代表一个可执行体,可向它发起 invoke 调用,它有可能是一个本地的实现,也可能是一个远程的实现,也可能一个集群实现。
在Dubbo中,Invoker是多重套娃的(可以理解为装饰器模式或者包装增强类),通过一层层的包装,使普通的Invoker具备了负载均衡、集群的功能。
最后,为服务接口(本文为DemoService)生成代理对象,Invoker#invoke(Invocation invocation)实现服务的调用。
本文不讨论直连方式引用,也不讨论负载均衡、集群等功能(后续再开坑说)。
梦的开始,ReferenceBean#getObject()
public Object getObject() throws Exception {
return get();
}
public synchronized T get() {
if (destroyed) {
throw new IllegalStateException("Already destroyed!");
}
if (ref == null) {
// init 方法主要用于处理配置,以及调用 createProxy 生成代理类
init();
}
return ref;
}
很明显,在 init 方法中生成了ref
private void init() {
// 省略大堆的检查以及参数处理
......
//attributes are stored by system context.
// 存储 attributes 到系统上下文中
StaticContext.getSystemContext().putAll(attributes);
// 创建代理类
ref = createProxy(map);
// 根据服务名,ReferenceConfig,代理类构建 ConsumerModel,
// 并将 ConsumerModel 存入到 ApplicationModel 中
ConsumerModel consumerModel = new ConsumerModel(getUniqueServiceName(), this, ref, interfaceClass.getMethods());
ApplicationModel.initConsumerModel(getUniqueServiceName(), consumerModel);
}
直接看 createProxy(map)
private T createProxy(Map<String, String> map) {
URL tmpUrl = new URL("temp", "localhost", 0, map);
final boolean isJvmRefer;
// isJvmRefer 的赋值处理
......
// 本地引用
if (isJvmRefer) {
// 生成invoker
......
// 远程引用
} else {
// 生成invoker、合并invoker
......
}
// invoker 可用性检查
......
// 生成代理类
return (T) proxyFactory.getProxy(invoker);
}
这个方法主要做了两件事
这里先略过invoker的处理,先看看代理对象的生成。
proxyFactory 是自适应拓展类,默认实现是JavassistProxyFactory,getProxy 方法在其父类AbstractProxyFactory中
// 这是AbstractProxyFactory类的方法
public <T> T getProxy(Invoker<T> invoker) throws RpcException {
return getProxy(invoker, false);
}
public <T> T getProxy(Invoker<T> invoker, boolean generic) throws RpcException {
Class<?>[] interfaces = null;
// 获取接口列表
String config = invoker.getUrl().getParameter("interfaces");
if (config != null && config.length() > 0) {
// 切分接口列表
String[] types = Constants.COMMA_SPLIT_PATTERN.split(config);
if (types != null && types.length > 0) {
interfaces = new Class<?>[types.length + 2];
// 设置服务接口类和 EchoService.class 到 interfaces 中
interfaces[0] = invoker.getInterface();
interfaces[1] = EchoService.class;
for (int i = 0; i < types.length; i++) {
// 加载接口类
interfaces[i + 2] = ReflectUtils.forName(types[i]);
}
}
}
if (interfaces == null) {
interfaces = new Class<?>[]{invoker.getInterface(), EchoService.class};
}
// 为 http 和 hessian 协议提供泛化调用支持,参考 pull request #1827
if (!invoker.getInterface().equals(GenericService.class) && generic) {
int len = interfaces.length;
Class<?>[] temp = interfaces;
// 创建新的 interfaces 数组
interfaces = new Class<?>[len + 1];
System.arraycopy(temp, 0, interfaces, 0, len);
// 设置 GenericService.class 到数组中
interfaces[len] = GenericService.class;
}
// 调用重载方法
return getProxy(invoker, interfaces);
}
这里的大段逻辑都是在处理interfaces参数,此时interfaces的值为{ DemoService.class, EchoService.class }
继续看子类JavassistProxyFactory实现的 getProxy(invoker, interfaces) 方法
public <T> T getProxy(Invoker<T> invoker, Class<?>[] interfaces) {
// return (T) Proxy.getProxy(interfaces).newInstance(new InvokerInvocationHandler(invoker));
// 源码是上面那行,我们将上面的代码改下面的格式
Proxy proxy = Proxy.getProxy(interfaces);
return (T) proxy.newInstance(new InvokerInvocationHandler(invoker));
}
注意:我下面开始讲的 proxy 不是平时理解的代理对象,你可以理解为一个生成代理对象的 builder
此方法做了两件事:
proxy对象newInstance方法生成实际的代理对象这里,我就不讲 Proxy.getProxy 的源码了,感兴趣的朋友自行了解。简单讲下里面做了什么:
构建服务接口(本文为DemoService)的代理类的字节码对象,其生成的字节码对象如下:
这里简化了下代码,实际上还实现了EchoService接口
package org.apache.dubbo.common.bytecode;
public class proxy0 implements org.apache.dubbo.demo.DemoService {
public static java.lang.reflect.Method[] methods;
private java.lang.reflect.InvocationHandler handler;
public proxy0() {
}
public proxy0(java.lang.reflect.InvocationHandler arg0) {
handler = $1;
}
public java.lang.String sayHello(java.lang.String arg0) {
Object[] args = new Object[1];
args[0] = ($w) $1;
Object ret = handler.invoke(this, methods[0], args);
return (java.lang.String) ret;
}
}
构建生成服务接口代理对象的builder
package com.alibaba.dubbo.common.bytecode;
public class Proxy0 extends com.alibaba.dubbo.common.bytecode.Proxy {
public Proxy0() {
}
public Object newInstance(java.lang.reflect.InvocationHandler h){
return new com.alibaba.dubbo.common.bytecode.proxy0($1);
}
}
注意一下:一个是proxy0,另一个是Proxy0,包名不同,类名的p子也有大小写的区别,别搞混了
再对照之前的 getProxy 方法
Proxy.getProxy(interfaces) 生成的是 Proxy0(大写的P)
proxy.newInstance(new InvokerInvocationHandler(invoker)) 生成的是 proxy0(小写的p)
至此,Dubbo服务引用对象已生成,可以看到,生成的引用对象结构也很简单,主要是依赖 invoker 对象完成接口调用的,下面就去看看 invoker 的生成。
让我们的视线重新回到createProxy方法中
private T createProxy(Map<String, String> map) {
URL tmpUrl = new URL("temp", "localhost", 0, map);
final boolean isJvmRefer;
// isJvmRefer 的赋值处理
......
// 本地引用
if (isJvmRefer) {
// 生成本地引用 URL,协议为 injvm
URL url = new URL(Constants.LOCAL_PROTOCOL, NetUtils.LOCALHOST, 0, interfaceClass.getName()).addParameters(map);
// 调用 refer 方法构建 InjvmInvoker 实例
invoker = refprotocol.refer(interfaceClass, url);
if (logger.isInfoEnabled()) {
logger.info("Using injvm service " + interfaceClass.getName());
}
// 远程引用
} else {
// url 不为空,表明用户可能想进行点对点调用
if (url != null && url.length() > 0) { // user specified URL, could be peer-to-peer address, or register center's address.
......
} else { // assemble URL from register center's configuration
// 加载注册中心 url
......
}
// 单个注册中心或服务提供者(服务直连,下同)
if (urls.size() == 1) {
// 调用 RegistryProtocol 的 refer 构建 Invoker 实例
invoker = refprotocol.refer(interfaceClass, urls.get(0));
// 多个注册中心或多个服务提供者,或者两者混合
} else {
List<Invoker<?>> invokers = new ArrayList<Invoker<?>>();
URL registryURL = null;
// 获取所有的 Invoker
for (URL url : urls) {
// 通过 refprotocol 调用 refer 构建 Invoker,refprotocol 会在运行时
// 根据 url 协议头加载指定的 Protocol 实例,并调用实例的 refer 方法
invokers.add(refprotocol.refer(interfaceClass, url));
if (Constants.REGISTRY_PROTOCOL.equals(url.getProtocol())) {
registryURL = url; // use last registry url
}
}
if (registryURL != null) { // registry url is available
// 如果注册中心链接不为空,则将使用 AvailableCluster
URL u = registryURL.addParameterIfAbsent(Constants.CLUSTER_KEY, AvailableCluster.NAME);
// 创建 StaticDirectory 实例,并由 Cluster 对多个 Invoker 进行合并
invoker = cluster.join(new StaticDirectory(u, invokers));
} else { // not a registry url
invoker = cluster.join(new StaticDirectory(invokers));
}
}
}
// invoker 可用性检查
......
// 生成代理类
return (T) proxyFactory.getProxy(invoker);
}
if (isJvmRefer) {
// 生成本地引用 URL,协议为 injvm
URL url = new URL(Constants.LOCAL_PROTOCOL, NetUtils.LOCALHOST, 0, interfaceClass.getName()).addParameters(map);
// 调用 refer 方法构建 InjvmInvoker 实例
invoker = refprotocol.refer(interfaceClass, url);
if (logger.isInfoEnabled()) {
logger.info("Using injvm service " + interfaceClass.getName());
}
}
refprotocol 是自适应拓展,根据URL中的协议,确定实现类是InjvmProtocol
public <T> Invoker<T> refer(Class<T> serviceType, URL url) throws RpcException {
return new InjvmInvoker<T>(serviceType, url, url.getServiceKey(), exporterMap);
}
其 refer 方法也很简单,就生成了 InjvmInvoker 对象并返回。其实这里搭配服务调用过程才容易理解(也就是InjvmInvoker#doInvoke(Invocation invocation方法),但本文是将服务引用过程,所以不展开。
远程引用区分单注册中心或单服务提供者和多注册中心或多服务提供者,此处我们以单注册中心或单服务提供者举例,主要逻辑是下面这段
// 单个注册中心或服务提供者(服务直连,下同)
if (urls.size() == 1) {
// 调用 RegistryProtocol 的 refer 构建 Invoker 实例
invoker = refprotocol.refer(interfaceClass, urls.get(0));
}
refprotocol 是自适应拓展类,根据 url 中的协议参数,其实现类为RegistryProtocol
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
url = url.setProtocol(url.getParameter(Constants.REGISTRY_KEY, Constants.DEFAULT_REGISTRY)).removeParameter(Constants.REGISTRY_KEY);
// 获取注册中心实例
Registry registry = registryFactory.getRegistry(url);
if (RegistryService.class.equals(type)) {
return proxyFactory.getInvoker((T) registry, type, url);
}
// group="a,b" or group="*"
// 将 url 查询字符串转为 Map
Map<String, String> qs = StringUtils.parseQueryString(url.getParameterAndDecoded(Constants.REFER_KEY));
// 获取 group 配置
String group = qs.get(Constants.GROUP_KEY);
if (group != null && group.length() > 0) {
if ((Constants.COMMA_SPLIT_PATTERN.split(group)).length > 1
|| "*".equals(group)) {
// 通过 SPI 加载 MergeableCluster 实例,并调用 doRefer 继续执行服务引用逻辑
return doRefer(getMergeableCluster(), registry, type, url);
}
}
// 调用 doRefer 继续执行服务引用逻辑
return doRefer(cluster, registry, type, url);
}
获取注册中心实例的过程,就是创建 zookeeper 连接,我在上一篇Dubbo服务导出博文中讲过了,请自行查找。
我们继续关注主要方法doRefer(cluster, registry, type, url)
private <T> Invoker<T> doRefer(Cluster cluster, Registry registry, Class<T> type, URL url) {
// 创建 RegistryDirectory 实例
RegistryDirectory<T> directory = new RegistryDirectory<T>(type, url);
// 设置注册中心和协议
directory.setRegistry(registry);
directory.setProtocol(protocol);
// all attributes of REFER_KEY
Map<String, String> parameters = new HashMap<String, String>(directory.getUrl().getParameters());
// 生成服务消费者链接
URL subscribeUrl = new URL(Constants.CONSUMER_PROTOCOL, parameters.remove(Constants.REGISTER_IP_KEY), 0, type.getName(), parameters);
// 注册服务消费者,在 consumers 目录下新节点
if (!Constants.ANY_VALUE.equals(url.getServiceInterface())
&& url.getParameter(Constants.REGISTER_KEY, true)) {
URL registeredConsumerUrl = getRegisteredConsumerUrl(subscribeUrl, url);
registry.register(registeredConsumerUrl);
directory.setRegisteredConsumerUrl(registeredConsumerUrl);
}
// 订阅 providers、configurators、routers 等节点数据
directory.subscribe(subscribeUrl.addParameter(Constants.CATEGORY_KEY,
Constants.PROVIDERS_CATEGORY
+ "," + Constants.CONFIGURATORS_CATEGORY
+ "," + Constants.ROUTERS_CATEGORY));
// 一个注册中心可能有多个服务提供者,因此这里需要将多个服务提供者合并为一个
Invoker invoker = cluster.join(directory);
ProviderConsumerRegTable.registerConsumer(invoker, url, subscribeUrl, directory);
return invoker;
}
此方法主要做了4个操作:
创建一个 RegistryDirectory 实例,这是一个服务目录对象。
服务目录中存储了一些和服务提供者有关的信息,通过服务目录,服务消费者可获取到服务提供者的信息,比如 ip、端口、服务协议等。通过这些信息,服务消费者就可通过 Netty 等客户端进行远程调用。
向注册中心进行注册
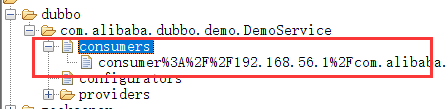
订阅 providers、configurators、routers 等节点下的数据
生成invoker
cluster.join(directory) 默认实现类是FailoverCluster,这个是集群处理,后续文章再讨论。
讨论了这么久,还没看到如何连接暴露出来的远程服务。
其实,连接远程服务的操作,就是在订阅 providers 节点数据时完成的
这里,就不细说订阅 providers 之后的各种处理,直接快进到远程服务的连接。下面放上订阅节点数据到启动远程连接的调用路径
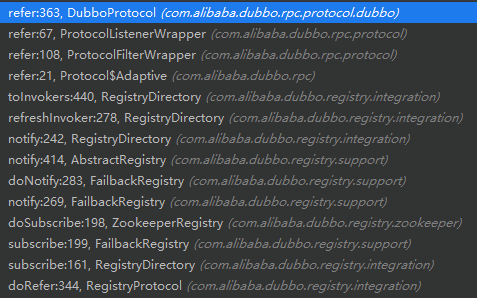
别问为什么是DubboProtocol,因为服务导出时,也就会zookeeper的providers节点中注册的url,就是Dubbo协议
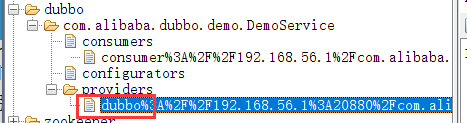
下面来看看DubboProtocol的 refer 方法
public <T> Invoker<T> refer(Class<T> serviceType, URL url) throws RpcException {
// 序列化优化处理
optimizeSerialization(url);
// create rpc invoker.
DubboInvoker<T> invoker = new DubboInvoker<T>(serviceType, url, getClients(url), invokers);
invokers.add(invoker);
return invoker;
}
此方法创建了 DubboInvoker 并返回,但是 DubboInvoker 的构造方法没啥好说的,就是一些类变量的赋值。我们主要关注 getClients ,其返回的是客户端实例
private ExchangeClient[] getClients(URL url) {
// whether to share connection
// 是否共享连接
boolean service_share_connect = false;
// 获取连接数,默认为0,表示未配置
int connections = url.getParameter(Constants.CONNECTIONS_KEY, 0);
// 如果未配置 connections,则共享连接
if (connections == 0) {
service_share_connect = true;
connections = 1;
}
ExchangeClient[] clients = new ExchangeClient[connections];
for (int i = 0; i < clients.length; i++) {
if (service_share_connect) {
// 获取共享客户端
clients[i] = getSharedClient(url);
} else {
// 初始化新的客户端
clients[i] = initClient(url);
}
}
return clients;
}
connections 的默认值为0,也就是 service_share_connect 为 true ,进入 getSharedClient(url) 方法
private ExchangeClient getSharedClient(URL url) {
String key = url.getAddress();
// 获取带有“引用计数”功能的 ExchangeClient
ReferenceCountExchangeClient client = referenceClientMap.get(key);
if (client != null) {
if (!client.isClosed()) {
// 增加引用计数
client.incrementAndGetCount();
return client;
} else {
referenceClientMap.remove(key);
}
}
locks.putIfAbsent(key, new Object());
synchronized (locks.get(key)) {
if (referenceClientMap.containsKey(key)) {
return referenceClientMap.get(key);
}
// 创建 ExchangeClient 客户端
ExchangeClient exchangeClient = initClient(url);
// 将 ExchangeClient 实例传给 ReferenceCountExchangeClient,这里使用了装饰模式
client = new ReferenceCountExchangeClient(exchangeClient, ghostClientMap);
referenceClientMap.put(key, client);
ghostClientMap.remove(key);
locks.remove(key);
return client;
}
}
此处就是一些引用计数和缓存操作,主要关注 ExchangeClient 的创建
private ExchangeClient initClient(URL url) {
// 获取客户端类型,默认为 netty
String str = url.getParameter(Constants.CLIENT_KEY, url.getParameter(Constants.SERVER_KEY, Constants.DEFAULT_REMOTING_CLIENT));
......
ExchangeClient client;
try {
// 获取 lazy 配置,并根据配置值决定创建的客户端类型
if (url.getParameter(Constants.LAZY_CONNECT_KEY, false)) {
// 创建懒加载 ExchangeClient 实例
client = new LazyConnectExchangeClient(url, requestHandler);
} else {
// 创建普通 ExchangeClient 实例
client = Exchangers.connect(url, requestHandler);
}
} catch (RemotingException e) {
throw new RpcException("Fail to create remoting client for service(" + url + "): " + e.getMessage(), e);
}
return client;
}
我们这里不讨论懒加载的情况。有见到了熟悉的 Exchangers, 在服务导出的时候,调用的是Exchangers.bind 方法,服务引用这里用的是 Exchangers.connect
public static ExchangeClient connect(URL url, ExchangeHandler handler) throws RemotingException {
if (url == null) {
throw new IllegalArgumentException("url == null");
}
if (handler == null) {
throw new IllegalArgumentException("handler == null");
}
url = url.addParameterIfAbsent(Constants.CODEC_KEY, "exchange");
// 获取 Exchanger 实例,默认为 HeaderExchangeClient
return getExchanger(url).connect(url, handler);
}
这里 getExchanger(url) 返回的是 HeaderExchangeClient,直接进去看 connect 方法
public ExchangeClient connect(URL url, ExchangeHandler handler) throws RemotingException {
// 这里包含了多个调用,分别如下:
// 1. 创建 HeaderExchangeHandler 对象
// 2. 创建 DecodeHandler 对象
// 3. 通过 Transporters 构建 Client 实例
// 4. 创建 HeaderExchangeClient 对象
return new HeaderExchangeClient(Transporters.connect(url, new DecodeHandler(new HeaderExchangeHandler(handler))), true);
}
HeaderExchangeClient内部持有 client ,并封装了心跳的功能。我们重点在 Transporters.connect ,也就是Dubbo的网络传输层是如何连接的
public static Client connect(URL url, ChannelHandler... handlers) throws RemotingException {
if (url == null) {
throw new IllegalArgumentException("url == null");
}
ChannelHandler handler;
if (handlers == null || handlers.length == 0) {
handler = new ChannelHandlerAdapter();
} else if (handlers.length == 1) {
handler = handlers[0];
} else {
// 如果 handler 数量大于1,则创建一个 ChannelHandler 分发器
handler = new ChannelHandlerDispatcher(handlers);
}
// 获取 Transporter 自适应拓展类,并调用 connect 方法生成 Client 实例
return getTransporter().connect(url, handler);
}
getTransporter() 获取的是Transporter的自适应拓展类,默认是NettyTransporter
public Client connect(URL url, ChannelHandler listener) throws RemotingException {
return new NettyClient(url, listener);
}
NettyTransporter的 connect 方法就创建了一个 NettyClient 对象,所以启动连接的相关逻辑在其构造函数中
public NettyClient(final URL url, final ChannelHandler handler) throws RemotingException {
super(url, wrapChannelHandler(url, handler));
}
// NettyClient的父类AbstractClient
public AbstractClient(URL url, ChannelHandler handler) throws RemotingException {
......
try {
doOpen();
} catch (Throwable t) {
......
}
try {
connect();
if (logger.isInfoEnabled()) {
logger.info("Start " + getClass().getSimpleName() + " " + NetUtils.getLocalAddress() + " connect to the server " + getRemoteAddress());
}
} catch (RemotingException t) {
......
}
......
}
这里又是使用模板方法,doOpen() 和 connect() 的具体实现在子类NettyClient中,其作用就是创建对远程服务的连接。这部分属于Netty的API调用,就不做具体描述了。
本文讲述了Dubbo服务导出的过程,也就是创建服务接口代理对象的过程。其中服务调用、集群、负载均衡等部分并未描述,可以期待后续文章。
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame
我有一个使用PDFKit呈现网页的pdf版本的Rails应用程序。我使用Thin作为开发服务器。问题是当我处于开发模式时。当我使用“bundleexecrailss”启动我的服务器并尝试呈现任何PDF时,整个过程会陷入僵局,因为当您呈现PDF时,会向服务器请求一些额外的资源,如图像和css,看起来只有一个线程.如何配置Rails开发服务器以运行多个工作线程?非常感谢。 最佳答案 我找到的最简单的解决方案是unicorn.geminstallunicorn创建一个unicorn.conf:worker_processes3然后使用它: