目录
4.3、刷入 refresh 页缓存的同时,写入 translog
一个分布式的实时文档存储,每个字段可以被索引与搜索
一个分布式实时分析搜索引擎
能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
基于Lucene,隐藏复杂性,提供简单易用的Restful API接口、Java API接口(还有其他语言的API接口)。ES是一个可高度扩展的全文搜索和分析引擎。它能够快速地、近乎实时地存储、查询和分析大量数据。


如上图所示,假如在1个主shared,1个副本的配置下,主和replica会分布在不同的Node节点上,起到一个容灾的作用。
replica只负责复制Primary给下来的数据,只有当primary挂了,他才上位。
集群(cluster)
ES集群由若干节点组成,这些节点在同一个网络内,cluster-name相同
节点(node)
一个ES的实例,本质上是一个java进程,生产环境一般建议一台机器上运行一个ES实例。节点可以分布在不同的机房。
节点有如下分类:
1、master节点:集群中的一个节点会被选为master节点,它将负责管理集群范畴的变更,例如创建或删除索引,添加节点到集群或从集群删除节点。master节点无需参与文档层面的变更和搜索,这意味着仅有一个master节点并不会因流量增长而成为瓶颈。任意一个节点都可以成为 master 节点。
2、data节点:持有数据和倒排索引。默认情况下,每个节点都可以通过设定配置文件中的node.data属性为true(默认)成为数据节点。如果需要一个专门的主节点,应将其node.data属性设置为false。
node.master: true/false
node.data: true/false
一个节点可以既为Master节点,又为Data节点,但是为什么不推荐?
因为Data节点请求过多,负载过高的时候,可能会导致es假死,也就是可能导致其他节点认为该 Master挂了,另外 Data节点会进行gc 回收,这个过程也可能影响 Master节点的正常响应。所以强烈建议 Master 只做集群管理工作,不参与data的index与query
3、client节点:如果将node.master属性和node.data属性都设置为false,那么该节点就是一个客户端节点,扮演一个负载均衡的角色,将到来的请求路由到集群中的各个节点。也叫协调节点,这个节点不需要配置的,只要任何一个节点接收到请求,并且请求不需要这个节点处理,只需要他进行转发的场景下,这个节点就被叫做协调节点。
索引(index)
文档的容器,一类文档的集合
分片(shard)
单个节点由于物理机硬件限制,存储的文档是有限的,如果一个索引包含海量文档,则不能在单个节点存储。ES提供分片机制,同一个索引可以存储在不同分片(数据容器)中,这些分片又可以存储在集群中不同节点上。
分片分为主分片(primary shard) 以及从分片(replica shard)
1、主分片与从分片关系:从分片只是主分片的一个副本,它用于提供数据的冗余副本
2、从分片应用:在硬件故障时提供数据保护,同时服务于搜索和检索这种只读请求
3、是否可变:索引中的主分片的数量在索引创建后就固定下来了,但是从分片的数量可以随时改变
文档(document)
可搜索的最小单元 ,json格式保存
| RDBMS | ES |
|---|---|
| Table | Index |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | DSL |
分片(Shard)在数据库概念映射里面类似于分表(水平拆分)
index、type的初衷
之前es将index、type类比于关系型数据库(例如mysql)中database、table,这么考虑的目的是“方便管理数据之间的关系”。
【本来为了方便管理数据之间的关系,类比database-table 设计了index-type模型】
a. 在关系型数据库中table是独立的(独立存储),但es中同一个index中不同type是存储在同一个索引中的(lucene的索引文件),因此不同type中相同名字的字段的定义(mapping)必须一致。如果是mysql,两个table中的age字段,2个table可以分别定义成int和string,但是es不行,必须一样
b. 不同类型的“记录”存储在同一个index中,会影响lucene的压缩性能。

1、所有数据的处理都由 Primary Shared去处理
shard = hash(routing) % number_of_primary_shards2、假如客户端请求 Node2 写入数据,比如是往spu-record这个index写入数据,此时根据路由字段(一般是主键id)路由到数据应该写入到分片3 Shared3 上,那么此时会找到分片3所在的节点Node3,Node2转发请求给Node3去处理,Node3写入Primary主分片,写入后同步给分片3的副本Replica,同步数据成功后,会告知Node3接收数据成功,Node3发送写入成功Reponse告知Node2,Node2把response发给客户端。
3、读取数据如下图,假如请求Node2,但是数据在Node3,那么会转发请求到Node3去拿到数据转发给客户端。
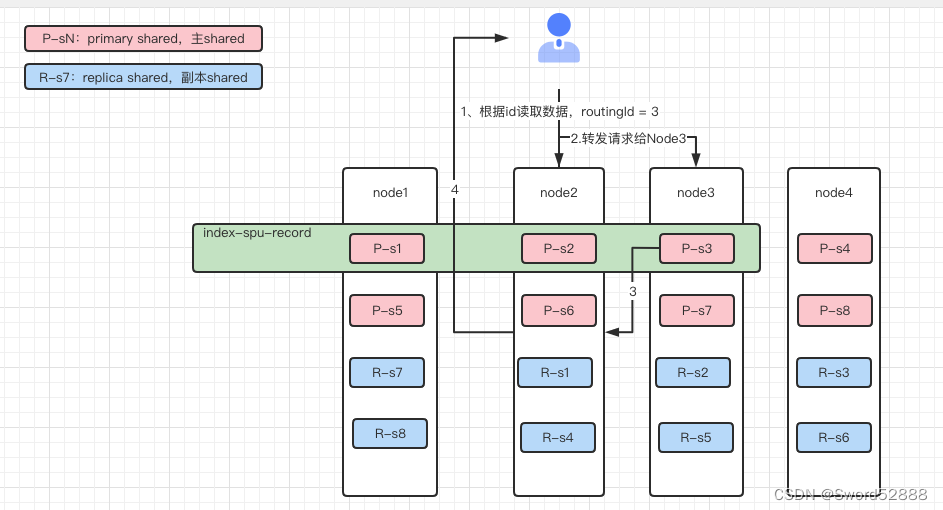
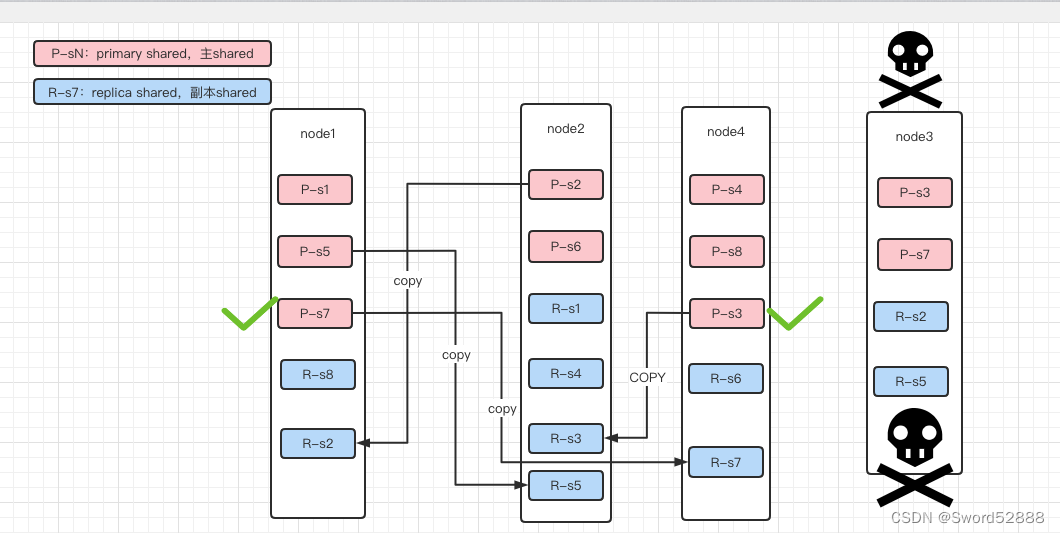
1、假如服务器 Node3 挂了
2、Node3上有2个primary节点,shared3 和 shared7,此时 Node1 上的shared7的副本会晋升成 Primary Shard,Node4 上的 shared3 的副本也会晋升成 Primary Shard 。晋升后,即可马上对外提供服务。
3、由于配置了副本数是1,所以会把已经丢失的 s3 s7 s2 s5这四个 shard 在其他Node上复制一份。(如果有200G数据,千兆网络,拷贝完需要1600秒。如果没有replica,则这1600秒内这些Shard就不能服务。)
1、如何去服务器找到es的配置文件
ps -ef | grep java2、找到文件夹所在位置 es.path.home
-Des.path.home=/opt/company/apps/elasticsearch/current找到 config文件夹
/opt/company/apps/elasticsearch/current/config找到es服务的配置文件 elasticsearch.yml
less elasticsearch.yml找到 path.data
path.data: /opt/company/es_datatree 命令,或者 find . -type d -maxdepth 3

上面的 foo 是索引名称,有些可能用索引的 uuid 代替。
data/elasticsearch/nodes/0(这个0是固定的)/indices/foo/0 (这个0是foo位于这个Node上的shard分片)
Elasticsearch事务日志确保可以安全地将数据索引到Elasticsearch,而无需为每个文档执行低级Lucene提交。提交Lucene索引会在Lucene级别创建一个新的segment,即执行fsync(),会导致大量磁盘I / O影响性能。
为了接受索引文档并使其可搜索而不需要完整的Lucene提交,Elasticsearch将其添加到Lucene IndexWriter并将其附加到事务日志中。在每个refresh_interval之后,它将在Lucene索引上调用reopen(),这将使数据可以在不需要提交的情况下进行搜索。这是Lucene Near Real Time API的一部分。当IndexWriter最终由于自动刷新事务日志或由于显式刷新操作而提交时,先前的事务日志将被丢弃并且新的事务日志将取代它。
如果需要恢复,将首先恢复在Lucene中写入磁盘的segments,然后重放事务日志,以防止丢失尚未完全提交到磁盘的操作。
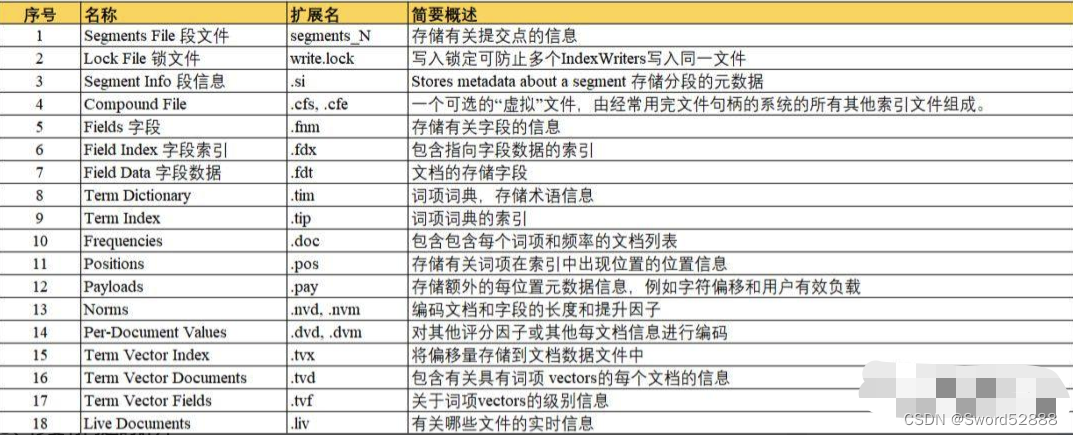
| Name | Extension | Brief Description |
|---|---|---|
| Segment Info | .si | segment的元数据文件 |
| Compound File | .cfs, .cfe | 一个segment包含了如下表的各个文件,为减少打开文件的数量,在segment小的时候,segment的所有文件内容都保存在cfs文件中,cfe文件保存了lucene各文件在cfs文件的位置信息 |
| Fields | .fnm | 保存了fields的相关信息 |
| Field Index | .fdx | 正排存储文件的元数据信息 |
| Field Data | .fdt | 存储了正排存储数据,写入的原文存储在这 |
| Term Dictionary | .tim | 倒排索引的元数据信息 |
| Term Index | .tip | 倒排索引文件,存储了所有的倒排索引数据 |
| Frequencies | .doc | 保存了每个term的doc id列表和term在doc中的词频 |
| Positions | .pos | Stores position information about where a term occurs in the index 全文索引的字段,会有该文件,保存了term在doc中的位置 |
| Payloads | .pay | Stores additional per-position metadata information such as character offsets and user payloads 全文索引的字段,使用了一些像payloads的高级特性会有该文件,保存了term在doc中的一些高级特性 |
| Norms | .nvd, .nvm | 文件保存索引字段加权数据 |
| Per-Document Values | .dvd, .dvm | lucene的docvalues文件,即数据的列式存储,用作聚合和排序 |
| Term Vector Data | .tvx, .tvd, .tvf | Stores offset into the document data file 保存索引字段的矢量信息,用在对term进行高亮,计算文本相关性中使用 |
| Live Documents | .liv | 记录了segment中删除的doc |
为了提升对文件的读写效率,Linux 内核会以页大小(4KB)为单位,将文件划分为多数据块。当用户对文件中的某个数据块进行读写操作时,内核首先会申请一个内存页(称为 页缓存)与文件中的数据块进行绑定。如下图所示:


Doc会先被搜集到内存中的Buffer内,这个时候还无法被搜索到,如下图所示:

Lucene支持对新段写入和打开,可以使文档在没有完全刷入硬盘的状态下就能对搜索可见,而且是一个开销较小的操作,可以频繁进行。
下面是一个已经将Docs刷入段,但还没有完全提交的示意图:
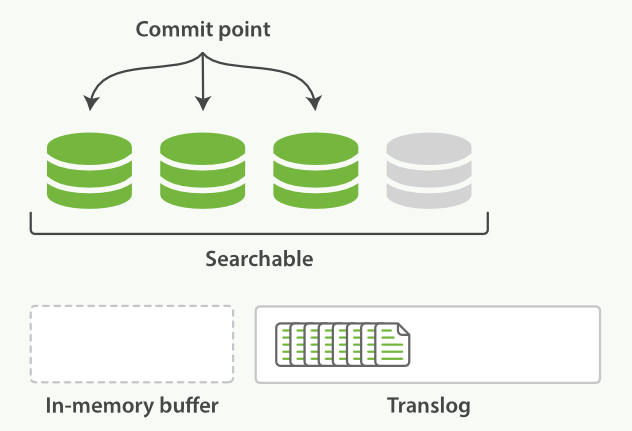
我们可以看到,新段虽然还没有被完全提交,但是已经对搜索可见了。
引入refresh操作的目的是提高ES的实时性,使添加文档尽可能快的被搜索到,同时又避免频繁fsync带来性能开销,依靠的就是文件系统缓存OS cache里缓存的文件可以被打开(open/reopen)和读取,而这个os cache实际是一块内存区域,而非磁盘,所以操作是很快的,这就是ES被称为近实时搜索的原因。
refresh默认执行的间隔是1秒,可以使用refreshAPI进行手动操作,但一般不建议这么做。还可以通过合理设置refresh_interval在近实时搜索和索引速度间做权衡。
translog记录的是已经在内存生成(segments)并存储到os cache但是还没写到磁盘的那些索引操作。
index segment刷入 refresh 到os cache后就可以打开供查询,这个操作是有潜在风险的,因为os cache中的数据有可能在意外的故障中丢失,而此时数据必备并未刷入到os disk,此时数据丢失将是不可逆的,这个时候就需要一种机制,可以将对es的操作记录下来,来确保当出现故障的时候,已经落地到磁盘的数据不会丢失,并在重启的时候可以从操作记录中将数据恢复过来。elasticsearch提供了translog来记录这些操作,结合os cached segments数据定时落盘来实现数据可靠性保证(flush)。
文档被添加到buffer同时追加到translog:
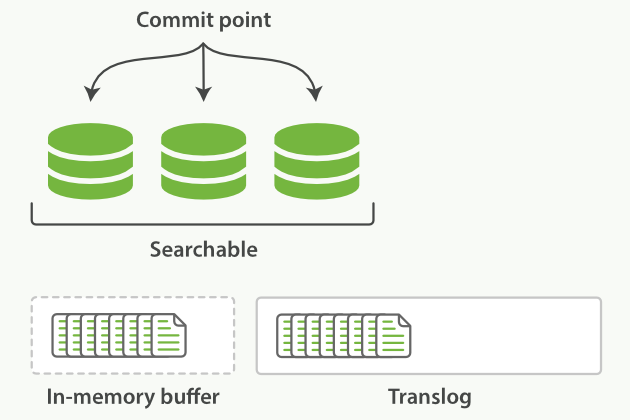
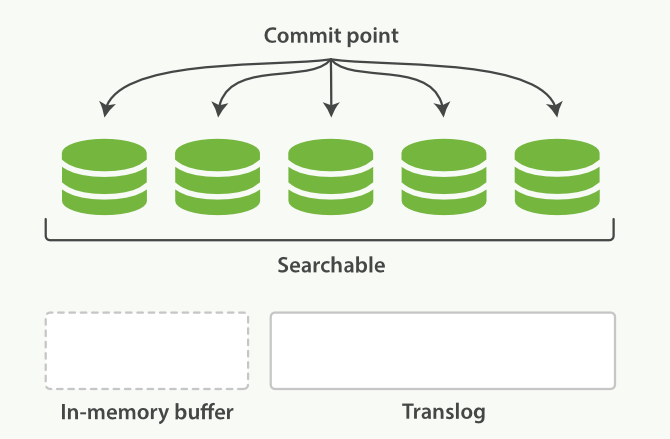
每隔一段时间(例如translog变得太大),index会被flush到磁盘,新的translog文件被创建,commit执行结束后,会发生以下事件:
fsync flushtranslog本身也是磁盘文件,频繁的写入磁盘会带来巨大的IO开销,因此对translog的追加写入操作的同样操作的是os cache,因此也需要定时落盘(fsync)。translog落盘的时间间隔直接决定了ES的可靠性,因为宕机可能导致这个时间间隔内所有的ES操作既没有生成segment磁盘文件,又没有记录到Translog磁盘文件中,导致这期间的所有操作都丢失且无法恢复。
translog的fsync是ES在后台自动执行的,默认是每5秒钟主动进行一次translog fsync,或者当translog文件大小大于512MB主动进行一次fsync,对应的配置是
index.translog.flush_threshold_period
index.translog.flush_threshold_size当 Elasticsearch 启动的时候, 它会从磁盘中使用最后一个提交点去恢复已知的段,并且会重放 translog 中所有在最后一次提交后发生的变更操作。
translog 也被用来提供实时 CRUD 。当你试着通过ID来RUD一个Doc,它会在从相关的段检索之前先检查 translog 中最新的变更。
默认translog是每5秒或是每次请求完成后被fsync到磁盘(在主分片和副本分片都会)。也就是说,如果你发起一个index, delete, update, bulk请求写入translog并被fsync到主分片和副本分片的磁盘前不会反回200状态。
这样会带来一些性能损失,可以通过设为异步fsync,但是必须接受由此带来的丢失少量数据的风险。
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}flush就是执行commit清空、干掉老translog的过程。默认每个分片30分钟或者是translog过于大的时候自动flush一次。可以通过flush API手动触发,但是只会在重启节点或关闭某个索引的时候这样做,因为这可以让未来ES恢复的速度更快(translog文件更小)。
满足下列条件之一就会触发冲刷操作:
内存缓冲区已满,相关参数: indices.memory.index_buffer
自上次冲刷后超过了一定的时间,相关参数:index.translog.flush_threshold_period
事物日志达到了一定的阔值,相关参数:index.translog.flush_threshold_size
删除一个ES文档不会立即从磁盘上移除,它只是被标记成已删除。因为段是不可变的,所以文档既不能从旧的段中移除,旧的段也不能更新以反映文档最新的版本。
ES的做法是,每一个提交点包括一个.del文件(还包括新段),包含了段上已经被标记为删除状态的文档。所以,当一个文档被做删除操作,实际上只是在.del文件中将该文档标记为删除,依然会在查询时被匹配到,只不过在最终返回结果之前会被从结果中删除。ES将会在用户之后添加更多索引的时候,在后台进行要删除内容的清理。
文档的更新操作和删除是类似的:当一个文档被更新,旧版本的文档被标记为删除,新版本的文档在新的段中索引。
该文档的不同版本都会匹配一个查询,但是较旧的版本会从结果中删除。
通过每秒自动刷新创建新的段,用不了多久段的数量就爆炸了,每个段消费大量文件句柄,内存,cpu资源。更重要的是,每次搜索请求都需要依次检查每个段。段越多,查询越慢。
ES通过后台合并段解决这个问题。ES利用段合并的时机来真正从文件系统删除那些version较老或者是被标记为删除的文档。被删除的文档(或者是version较老的)不会再被合并到新的更大的段中。
可见,段合并主要有两个目的:
ES对一个不断有数据写入的索引处理流程如下:
合并过程如图:
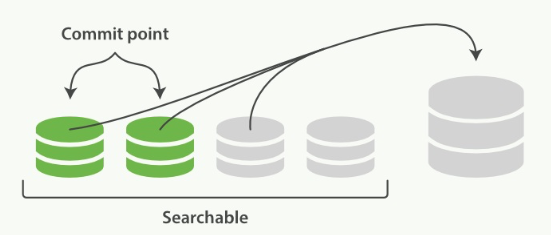
从上图可以看到,段合并之前,旧有的Commit和没Commit的小段皆可被搜索。
段合并后的操作:
合并完成后新的段可被搜索,旧的段被删除,如下图所示:

注意:段合并过程虽然看起来很爽,但是大段的合并可能会占用大量的IO和CPU,如果不加以控制,可能会大大降低搜索性能。段合并的optimize API 不是非常特殊的情况下千万不要使用,默认策略已经足够好了。不恰当的使用可能会将你机器的资源全部耗尽在段合并上,导致无法搜索、无法响应。
1、 Day 7 - Elasticsearch中数据是如何存储的
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个简单的静态Rack应用程序。查看下面的config.ru代码:useRack::Static,:urls=>["/elements","/img","/pages","/users","/css","/js"],:root=>"archive"map'/'dorunProc.new{|env|[200,{'Content-Type'=>'text/html','Cache-Control'=>'public,max-age=6400'},File.open('archive/splash.html',File::RDONLY)]}endmap'/pages/search.
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我去了这个website查看Rails5.0.0和Rails5.1.1之间的区别为什么5.1.1不再包含:config/initializers/session_store.rb?谢谢 最佳答案 这是删除它的提交:Setupdefaultsessionstoreinternally,nolongerthroughanapplicationinitializer总而言之,新应用没有该初始化器,session存储默认设置为cookie存储。即与在该初始值设定项的生成版本中指定的值相同。 关于
我正在关注Hartl的railstutorial.org并已到达11.4.4:Imageuploadinproduction.我做了什么:注册亚马逊网络服务在AmazonIdentityandAccessManagement中,我创建了一个用户。用户创建成功。在AmazonS3中,我创建了一个新存储桶。设置新存储桶的权限:权限:本教程指示“授予上一步创建的用户读写权限”。但是,在存储桶的“权限”下,未提及新用户名。我只能在每个人、经过身份验证的用户、日志传送、我和亚马逊似乎根据我的名字+数字创建的用户名之间进行选择。我已经通过选择经过身份验证的用户并选中了上传/删除和查看权限的框(而不
我正在使用mechanize登录网站,然后检索页面。我遇到了一些问题,我怀疑这是由于cookie中的某些值造成的。当Mechanize登录网站时,我假设它存储了cookie。如何通过Mechanize打印出存储在cookie中的所有数据? 最佳答案 代理有一个cookie方法。agent=Mechanize.newpage=agent.get("http://www.google.com/")agent.cookiesagent.cookies.to_scookie返回一个Mechanize::Cookiesobject
我以为它们存储在cookie中-但不,检查cookie没有任何结果。session也不存储它们。那么,我在哪里可以找到它们?我需要这个来直接设置它们(而不是通过flashhash)。 最佳答案 它们存储在inyoursessionstore.自rails2.0以来的默认设置是cookie存储,但请检查config/initializers/session_store.rb以检查您是否使用默认设置以外的东西。 关于ruby-on-rails-闪存消息存储在哪里?,我们在StackOverf
对于我正在编写的Rails3应用程序,我正在考虑从本地文件系统上的XML、YAML或JSON文件中读取一些配置数据。重点是:我应该把这些文件放在哪里?Rails应用程序中是否有用于存储此类内容的默认位置?附带说明一下,我的应用程序部署在Heroku上。 最佳答案 我经常做的是:如果文件是通用配置文件:我在目录/config中创建一个YAML文件,每个环境有一个上层key如果我为每个环境(大项目)创建一个文件:我为每个环境创建一个YAML并将它们存储在/config/environments/然后我在加载YAML的地方创建了一个初始化
有没有办法将RubyVM::InstructionSequence存储到文件中并稍后读取?我尝试了Marshal.dump但没有成功。我收到以下错误:`dump':no_dump_dataisdefinedforclassRubyVM::InstructionSequence(TypeError) 最佳答案 是的,有办法。首先,您需要使InstructionSequence的load方法可访问,默认情况下该方法是禁用的:require'fiddle'classRubyVM::InstructionSequence#RetrieveR