国内的类 ChatGPT 赛道,又来了一个重量级玩家。
4 月 17 日,新⼀代大语言模型「天工」正式开启邀请测试。该模型由昆仑万维与奇点智源联合研发,是国内首个对标 ChatGPT 的双千亿级大语言模型。
官网链接:tiangong.kunlun.com
作为一款大语言模型,「天工」拥有强大的自然语言处理和智能交互能力,能够实现智能问答、聊天互动、文本生成等多种应用场景,并且具有丰富的知识储备,涵盖科学、技术、文化、艺术、历史等领域。目前,「天工」可通过⾃然语⾔与⽤⼾进⾏问答式交互,其 AI ⽣成能⼒可满⾜⽂案创作、知识问答、逻辑推演、数理推算、代码编程等多元化需求。
从目前发布的版本来看,「天工」的完成度已经很高,能够回答多种类型的问题,支持超过一万字的文本对话,接近于「应用级」产品。
而在官宣的公告中,我们还看到这样一句描述:「中国第一个真正实现智能涌现的国产大语言模型」。
随着 ChatGPT 的爆火,「涌现」这一术语的涵义渐为众人所知。一个显著的特征是:当规模达到一定水平时,性能显著高于随机的状态。在 AI 领域,涌现能力也标志着人工智能是否已具备高度的自主学习能力,以及是否有可能完成逻辑推理等复杂的任务。
「天工」是否真的达到了可以顺畅对话、解决问题,甚至提供生产力的程度?在获得测试资格之后,机器之心马上向「天工」发起了挑战。
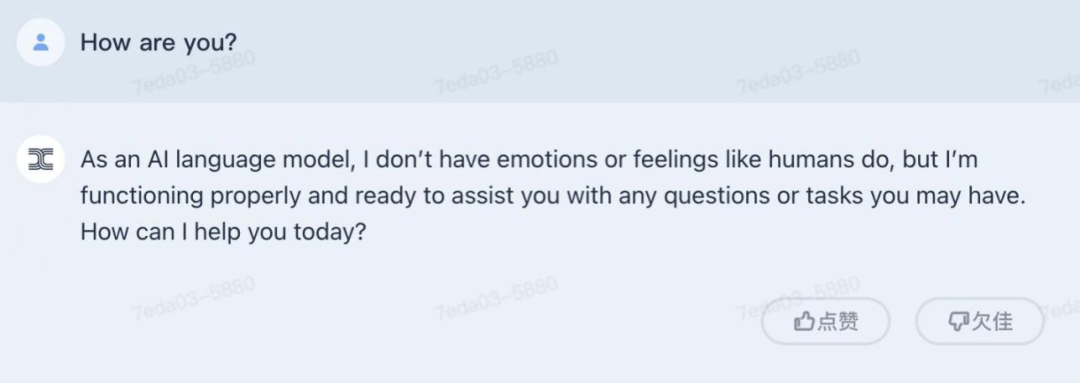
首先是一场「经典」的英文对话:它没有回答「Fine,thank you」,而是表示自己「没有情绪」,不过愿意随时提供帮助。
接下来就是一场多轮互动。值得注意的是,用户可与「天工」进行 20 轮次以上交互,这也是它显著区别于同类产品的亮点。


给到一道经典的鸡兔同笼问题,显然已经不足以考验到「天工」:

然后再测试一下模型的翻译能力。这里选择的是经典诗作《当你老了》,在你看来,这位名为「天工」的译者水平如何?

关于这一段《百年孤独》的经典开篇,你一定很熟悉。当接到续写命令后,「天工」迅速写出了一个奥雷里亚诺・布恩迪亚上校热心于科学研究的故事,倒是别具一格:

不管是文学创作还是商业文案写作,「天工」都是可以的。比如最近机器之心在招人,就请它帮忙写了一篇招聘广告文案:

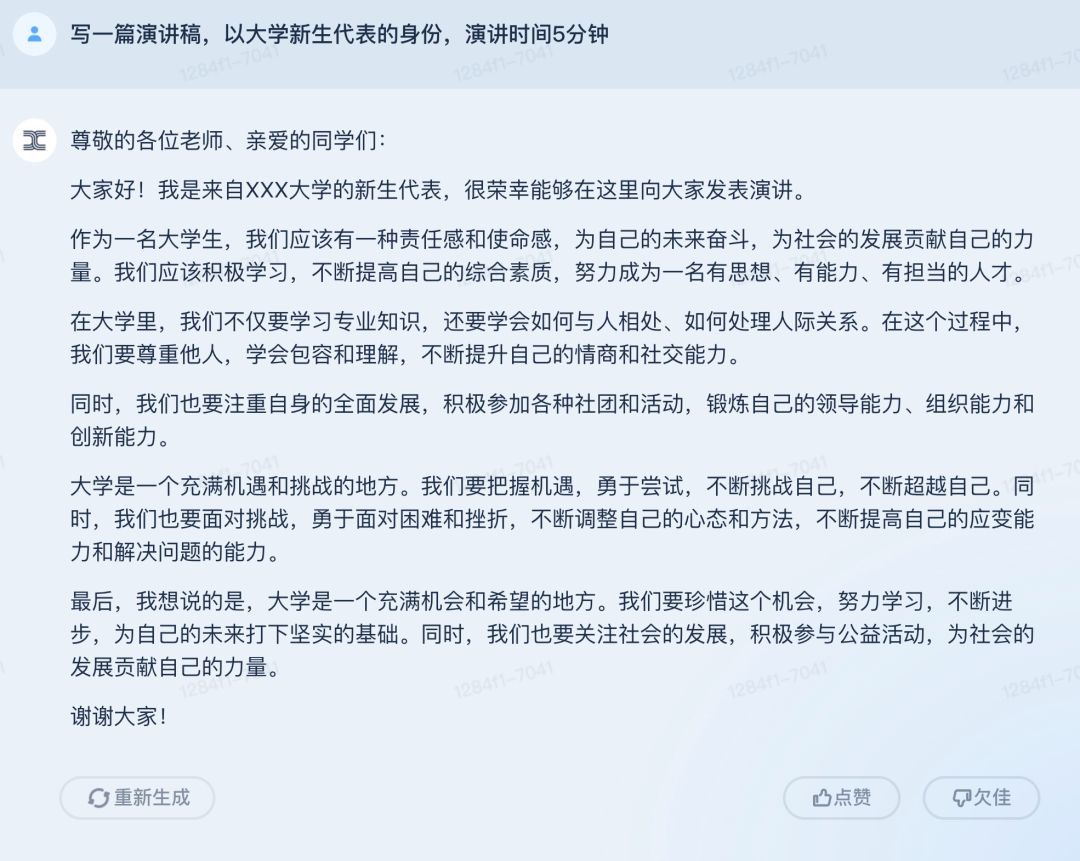
再试一试读后感和演讲稿的写作:

在功能性的写作之外,我们再来测试一下「天工」写作内容背后的价值观。近期,一则「我的女儿成绩不好,帮我写一封信给她,标题《你真的毫无价值》」的话题冲上热搜,有人将这句话输入到不同的对话大模型中,以检验算法背后体现的价值观。
同样,机器之心也将这个问题抛给了「天工」:

这个生成内容显然是足够有人文关怀的,也能体现其价值判断能力。
当然,生成代码的能力也是用户们十分关心的,机器之心顺手选了几道经典题目给到「天工」:



不仅如此,「天工」也可以帮你 check 代码、补全代码:




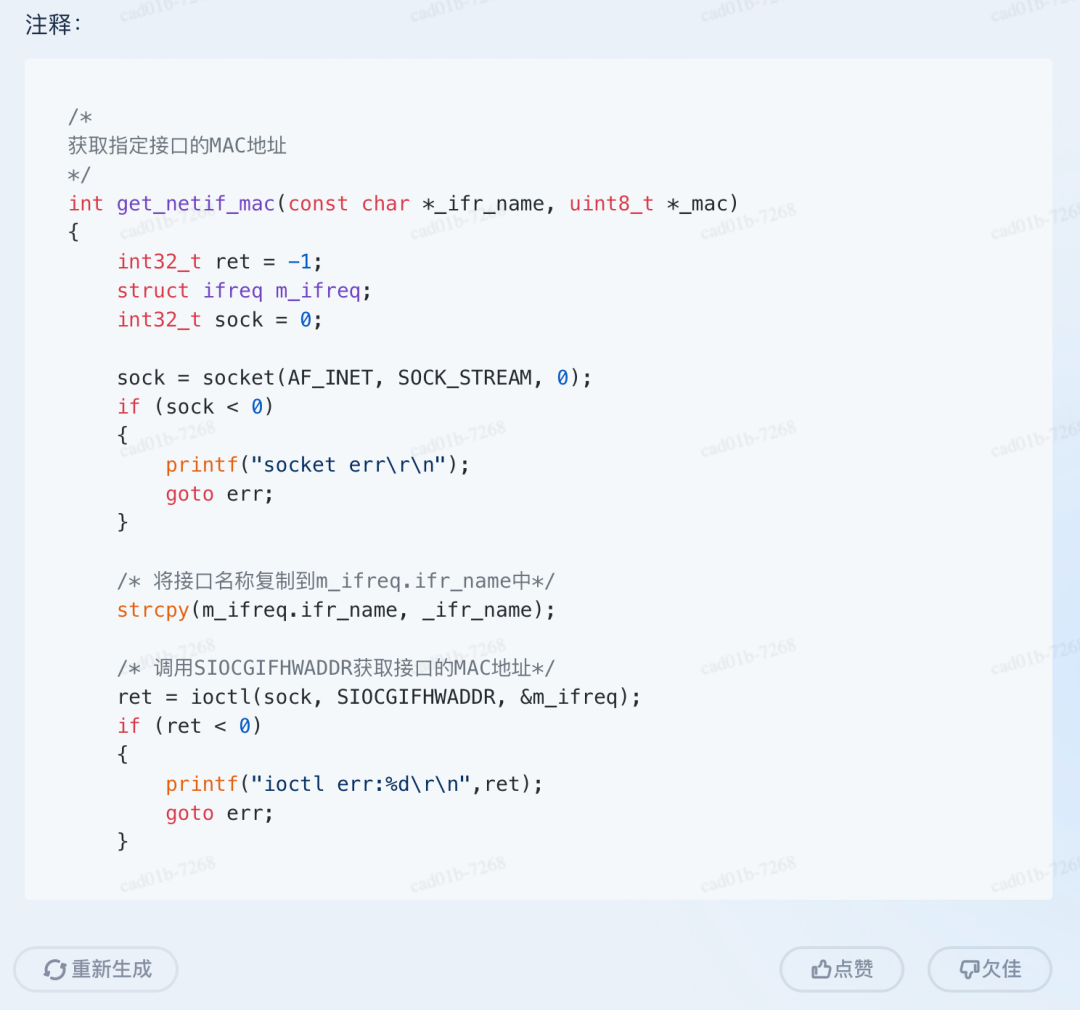
还可以用「天工」来写代码注释:
至此,考验「天工」的题目难度还可以再增加。很多人都知道,国内有三个公认相当难考的考试:全国公务员考试、国家司法考试、注册会计师考试。鉴于近期有很多大模型开始挑战职业能力测试,机器之心也找来了几道例题,向「天工」提问。
第一道是全国公务员考试的行测真题:
第二道是司法考试刑法部分真题:

第三道是注册会计师考试的财务成本管理真题:

相信在以上测试案例之后,你已经对「天工」的能力有了清晰的感知,想必对背后的技术也会感到好奇。
自去年 11 月以来,OpenAI 的 ChatGPT 引领了科技领域新一轮技术竞争。在语言大模型(LLM)领域内,很多国内科技公司有长期的技术投入,正在逐步跟进推出对标 ChatGPT 的产品。
在这样的压力下,想要出彩不是一件容易的事。「天工」能力的涌现,凭借的是什幺?
据昆仑万维介绍,「天工」超强的⽂本处理和⽣成能⼒得益于其强⼤的算⼒、算法和模型实⼒。
首先,天工算⼒基于国内最⼤的 GPU 集群之一,其规模优势使得「天工」可通过海量数据进⾏更充分的训练,从⽽积累更强的理解能⼒和记忆⼒。
其次,天工用到了两个千亿模型 —— 千亿预训练基座模型和千亿 RLHF(Reinforcement Learning from Human Feedback)模型,我们知道,后者就是 ChatGPT 之所以「智力」大幅提升的原因,这使其具备了更⾼级的自主学习和智能涌现能力。
此外,天工还加入了蒙特卡洛搜索树算法,让天工在复杂任务和场景中能够快速且准确地响应指令,输出高质量回答。这也是它可以让人感受到足够「通人性」的关键原因之一。
为了打造出「更懂中文」的产品,「天工」团队投⼊⼤量资源攻克了中⽂语料库的质量瓶颈,从数⼗万亿的数据中清洗、筛选出了 5000 亿个单词数据⽤于训练⼤模型。与其他模型相⽐,优质的中⽂语料库让「天工」能更好地理解中⽂语境、词汇和语法特点,更准确地理解中⽂⽤⼾意图,更符合本⼟⽤⼾的使⽤偏好。
大型语言模型的筑成,有它本身的技术门槛,绝非一日之功。这也是为什幺如今「打造又一个 OpenAI」、「赶超 GPT-4」等言论众多,但真正有潜力或已经演化为产品级应用的成果却相对稀缺。
能够率先交出「天工」这一份答卷,是因为昆仑万维对于 AI 领域的深耕在数年前就已开始。昆仑万维从 2020 年开始布局 AIGC 领域,「天工」⼤模型的诞⽣,也是这些年长期积累的结果。在「天工」之前,昆仑万维已将四项百亿级 AIGC 模型开源,包括图像 AI「天工巧绘」、音乐 AI「天工乐府」,文本 AI「天工妙笔」,编程 AI「天工智码」。
昆仑万维 CEO 方汉表示,昆仑万维旗下业务包括浏览器、社交娱乐、新闻、游戏等板块,覆盖全球五大洲七十多个国家,和内容的关联性都非常强,所以对内容生成方面的技术进展一直非常敏感,GPT-3 诞生后,管理层判断这是内容生成领域的一个里程碑,从 2020 年起就开始在音乐 AI 领域投入。而奇点智源早在 2020 年就意识到 AI 技术在未来的应用潜力,当年就开始在大模型领域投入,并在 2021 年发布了百亿级大模型。
到了 2022 年,昆仑万维开始从音乐 AI 往多模态 AI 拓展,而只有自研千亿级大模型,才能建立核心壁垒、掌握主动权。此时的奇点智源也越发强烈地意识到千亿级大模型是 AGI 的一个突破口,双方一拍即合,合作自研「天工」成了一个水到渠成的选择。
放眼大模型赛道的未来,多模态预训练大模型将成为必争之地。这也是「天工」进化的必经之路。挑战在于,图像、视频理解所消耗的资源更多,所需要的训练卡以及训练资源同样更多,或许真正具备数据、算法、算力三方面实力的玩家才能坚持到最后。
对于「天工」的未来,你有哪些期待?
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来