自动补全和集群部署ElasticSearch
要实现根据字母做补全,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件。地址:github上的拼音分词器下载
测试用法
POST /_analyze
{
"text": "如家酒店还不错",
"analyzer": "pinyin"
}
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音(rujia),需要对拼音分词器做个性化定制,形成自定义分词器。
elasticsearch中分词器(analyzer)的组成包含三部分:
声明自定义分词器的语法如下:
PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": { // 自定义tokenizer filter
"py": { // 过滤器名称
"type": "pinyin", // 过滤器类型,这里是pinyin
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart" //搜索时使用中午分词器
}
}
}
}
注意:拼音分词器适合在创建倒排索引时使用,不要在搜索的时候使用
总结:
如何使用拼音分词器?
①下载pinyin分词器
②解压并放到elasticsearch的plugin目录
③重启es容器即可
如何自定义分词器?
①创建索引库时,在settings中配置,可以包含三部分:
character filter
tokenizer
filter
拼音分词器注意事项有哪些?
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
参与补全查询的字段必须是completion类型。
字段的内容一般是用来补全的多个词条形成的数组。
比如,一个这样的索引库:
// 创建索引库
PUT test1
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
然后插入下面的数据:
// 示例数据
POST test1/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test1/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test1/_doc
{
"title": ["Nintendo", "switch"]
}
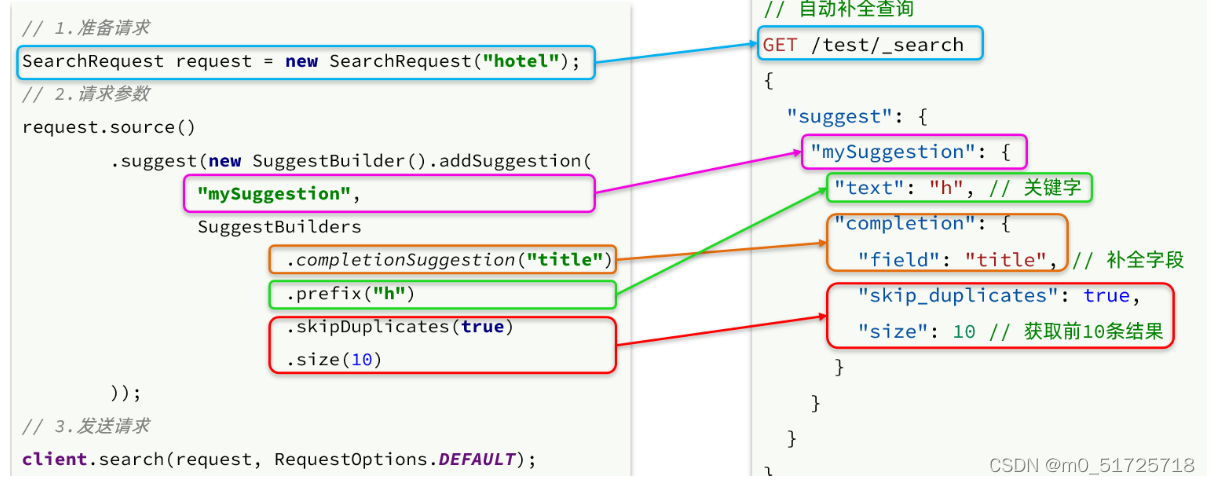
查询的DSL语句如下:
// 自动补全查询
GET /test1/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 关键字
"completion": {
"field": "title", // 补全查询的字段
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}
准备工作,索引库创建
// 酒店数据索引库
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}
测试数据:
后续上传
java代码实现
public List<String> getSuggestions(String prefix) {
try {
//1.准备请求
SearchRequest request = new SearchRequest("hotel");
//2.准备参数
request.source()
.suggest(new SuggestBuilder().addSuggestion("suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix(prefix)
.skipDuplicates(true)
.size(10)));
//3.发起请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
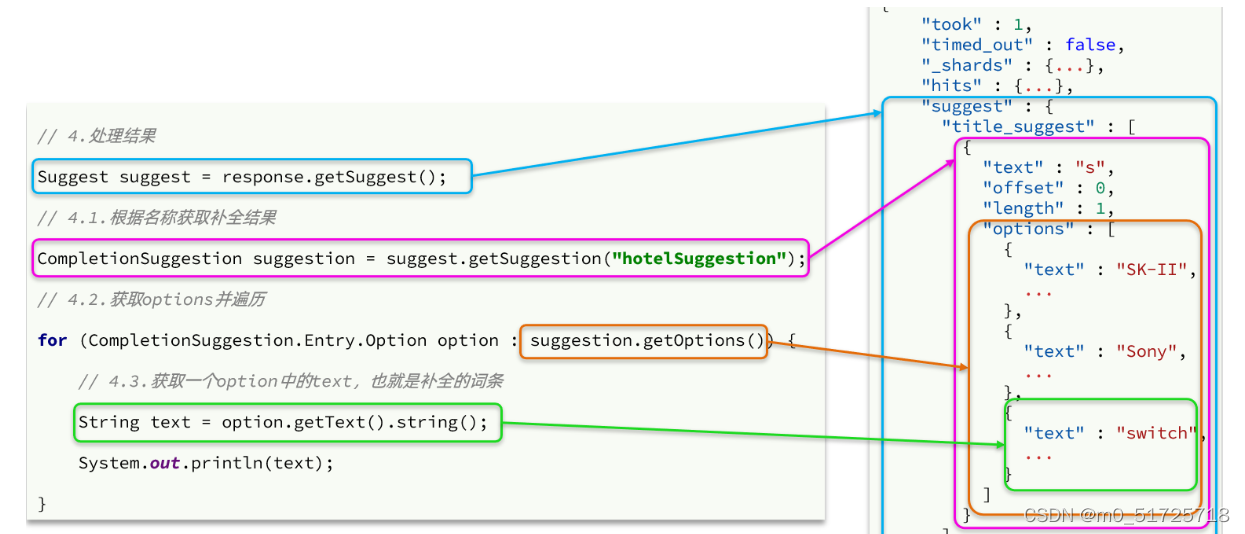
//4.解析结果
Suggest suggest = response.getSuggest();
// 4.1.根据补全查询名称,获取补全结果
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
// 4.2.获取options
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
// 4.3.遍历
List<String> list = new ArrayList<>(options.size());
for (CompletionSuggestion.Entry.Option option : options) {
String text = option.getText().toString();
list.add(text);
}
return list;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
示例截图
解析过程截图
暂未写
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
a=[3,4,7,8,3]b=[5,3,6,8,3]假设数组长度相同,是否有办法使用each或其他一些惯用方法从两个数组的每个元素中获取结果?不使用计数器?例如获取每个元素的乘积:[15,12,42,64,9](0..a.count-1).eachdo|i|太丑了...ruby1.9.3 最佳答案 使用Array.zip怎么样?:>>a=[3,4,7,8,3]=>[3,4,7,8,3]>>b=[5,3,6,8,3]=>[5,3,6,8,3]>>c=[]=>[]>>a.zip(b)do|i,j|c[[3,5],[4,3],[7,6],
我有一个非常简单的Controller来管理我的Rails应用程序中的静态页面:classPagesController我怎样才能让View模板返回它自己的名字,这样我就可以做这样的事情:#pricing.html.erb#-->"Pricing"感谢您的帮助。 最佳答案 4.3RoutingParametersTheparamshashwillalwayscontainthe:controllerand:actionkeys,butyoushouldusethemethodscontroller_nameandaction_nam
我正在尝试复制此GETcurl请求:curl-D--XGET-H"Authorization:BasicdGVzdEB0YXByZXNlYXJjaC5jb206NGMzMTg2Mjg4YWUyM2ZkOTY2MWNiNWRmY2NlMTkzMGU="-H"Content-Type:application/json"http://staging.example.com/api/v1/campaigns在Ruby中,通过电子邮件+apikey生成身份验证:auth="Basic"+Base64::encode64("test@example.com:4c3186288ae23fd9661c
我有两个文本文件,master.txt和926.txt。如果926.txt中有一行不在master.txt中,我想写入一个新文件notinbook.txt。我写了我能想到的最好的东西,但考虑到我是一个糟糕的/新手程序员,它失败了。这是我的东西g=File.new("notinbook.txt","w")File.open("926.txt","r")do|f|while(line=f.gets)x=line.chompifFile.open("master.txt","w")do|h|endwhile(line=h.gets)ifline.chomp!=xputslineendende