ubuntu18.04
开启hadoop

当前工作目录

input=$1 #获得第一个参数,也就是需要上传的文件
filename=$(basename $input) #获得该文件的文件名
dst="/root/update" #上传的文件目录
if `/root/rDesk/hadoop-3.3.2/bin/hadoop fs -test -e $dst"/"$filename` ;then
echo "该文件已存在,是否追加到该文件尾部“
echo "追加到尾部:y 覆盖源文件:n”
read opt
case $opt in
[yY]*)
`/root/rDesk/hadoop-3.3.2/bin/hadoop fs -appendToFile $input $dst"/"$filename`
;;
[nN]*)
`/root/rDesk/hadoop-3.3.2/bin/hadoop fs -rm $dst"/"$filename`
`/root/rDesk/hadoop-3.3.2/bin/hadoop fs -put $input $dst`
;;
*)
echo "input err, shell out"
;;
esac
else
`/root/rDesk/hadoop-3.3.2/bin/hadoop fs -put $intput $dst`
fi
echo "the shell is completed"

downloadPath=$1 #HDFS中下载的文件的路径
savePath=$2 #保存在本地的路径
downloadFilename=$(basename $downloadPath) #下载的文件的文件名
nowtime=$(date "+%Y%m%d%H%M%S") #获取当前时间
if [ -e $savePath"/"$downloadFilename ]; then
#如果存在相同文件名文件,则以当前时间当作文件名
`/root/rDesk/hadoop-3.3.2/bin/hadoop fs -get $downloadPath $savePath"/"$nowtime`
echo "the original filename is existed, now the filename is $savePath"/"$nowtime"
else
`/root/rDesk/hadoop-3.3.2/bin/hadoop fs -get $downloadPath $savePath`
fi
echo "copyOver"
将hdfs系统下/root/update/tag.txt文件复制到当前目录(./)

filePath=$1 #获得需要指定的HDFS中的文件路径
#echo $filePath
echo `/root/rDesk/hadoop-3.3.2/bin/hadoop fs -cat $filePath`

bin/hadoop fs -ls /root
or
#codecodecoderr
echo `/root/rDesk/hadoop-3.3.2/bin/hadoop fs -ls $1`


/root/rDesk/hadoop-3.3.2/bin/hadoop fs -ls -R /root

#codecodecoderr
path=$1 #获取指定的文件路径
if `/root/rDesk/hadoop-3.3.2/bin/hadoop fs -test -e $path`;then
echo "the file is exist"
else
echo "the file is not exist"
`/root/rDesk/hadoop-3.3.2/bin/hadoop fs -mkdir $path`
echo "the dir is created"
fi

bin/hadoop fs -mkdir -p /root/update/a/b/c
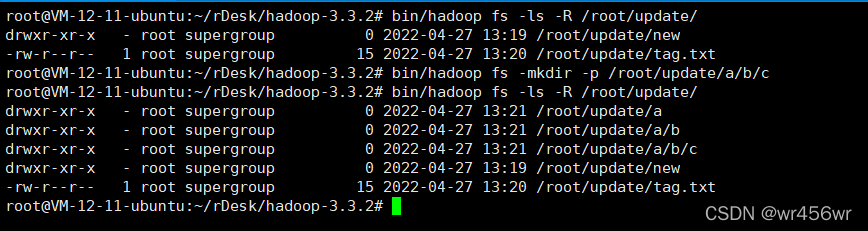
删除一个文件夹,当不为空的时候指定是否进行删除
bin/hadoop fs -rmdir /root/update/a
当该文件夹不为空任然删除
bin/hadoop fs -rm -r /root/update/a

hdfsPath=$2 #HDFS中指定文件的路径
localPath=./tmp__ #临时本地文件存储路径
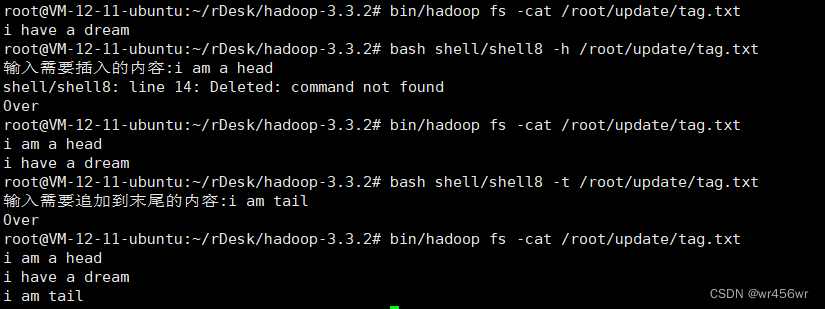
type=$1 #操作类型 -h表示追加到开头,-t表示追加到末尾
#判断是否该目录下是否存在tmp__文件,存在删除
if [ -e $localPath ];then
`rm -rf $localPath`
fi
case $type in
-h)
#追加到开头,操作流程:先将HDFS指定文件复制到本地,使用sed命令在开头写入内容,然后删除HDFS的文件,再将编辑好的文件上传到HDFS
`/root/rDesk/hadoop-3.3.2/bin/hadoop fs -copyToLocal $hdfsPath $localPath`
read -p "输入需要插入的内容:" text
`sed -i "1 i $text" $localPath`
`/root/rDesk/hadoop-3.3.2/bin/hadoop fs -rm $hdfsPath`
`/root/rDesk/hadoop-3.3.2/bin/hadoop fs -put $localPath $hdfsPath`
`rm -rf $localPath`
;;
-t)
#策略:以输入的文件内容在本地临时创建一个文件,然后使用appendToFile命令将该文件内容追加到HDFS指定文件末尾
read -p "输入需要追加到末尾的内容:" text
`echo $text > $localPath`
`/root/rDesk/hadoop-3.3.2/bin/hadoop fs -appendToFile $localPath $hdfsPath`
`rm -rf $localPath`
;;
*)
echo "llxxx操作数错误xxxll"
;;
esac
echo "Over"
删除指定文件
bin/hadoop fs -rm /root/update/tag.txt
删除指定空目录
bin/hadoop fs -rmdir /root/update/new

bin/hadoop fs -cp /root/update/tag.txt /root

https://www.jianshu.com/p/52e16e9ce24e
https://blog.csdn.net/weixin_43215948/article/details/107290768
http://c.biancheng.net/view/2767.html
https://blog.csdn.net/Olivia_Vang/article/details/104081096
https://blog.csdn.net/weixin_39962758/article/details/116929907
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
a=[3,4,7,8,3]b=[5,3,6,8,3]假设数组长度相同,是否有办法使用each或其他一些惯用方法从两个数组的每个元素中获取结果?不使用计数器?例如获取每个元素的乘积:[15,12,42,64,9](0..a.count-1).eachdo|i|太丑了...ruby1.9.3 最佳答案 使用Array.zip怎么样?:>>a=[3,4,7,8,3]=>[3,4,7,8,3]>>b=[5,3,6,8,3]=>[5,3,6,8,3]>>c=[]=>[]>>a.zip(b)do|i,j|c[[3,5],[4,3],[7,6],
我有一个非常简单的Controller来管理我的Rails应用程序中的静态页面:classPagesController我怎样才能让View模板返回它自己的名字,这样我就可以做这样的事情:#pricing.html.erb#-->"Pricing"感谢您的帮助。 最佳答案 4.3RoutingParametersTheparamshashwillalwayscontainthe:controllerand:actionkeys,butyoushouldusethemethodscontroller_nameandaction_nam
我需要在rail3中使用标准注册/登录/忘记密码功能进行身份验证。是否有大多数人为此使用的插件或其他东西? 最佳答案 我不确定最常用的方法是什么-但可以肯定的是,Plataformatec的“Devise”是一个非常流行的方法:http://github.com/plataformatec/devise我已经尝试了一些authgem,对我来说,它是最简单的设置和修改以满足我的需要。它内置了密码恢复、帐户确认(如果需要)和其他一些非常方便的功能。 关于ruby-on-rails-在Rail
我在ruby表单中有一个提交按钮f.submitbtn_text,class:"btnbtn-onemgt12mgb12",id:"btn_id"我想在不使用任何javascript的情况下通过ruby禁用此按钮 最佳答案 添加disabled:true选项。f.submitbtn_text,class:"btnbtn-onemgt12mgb12",id:"btn_id",disabled:true 关于ruby-on-rails-如何在Rails中添加禁用的提交按钮,我们在St
关闭。这个问题是off-topic.它目前不接受答案。想改进这个问题吗?Updatethequestion所以它是on-topic用于堆栈溢出。关闭11年前。Improvethisquestion我不经常使用ruby-通常它加起来相当于每两个月或更长时间编写一次脚本。我的大部分编程都是使用C++进行的,这与ruby有很大不同。由于我与ruby之间的差距如此之大,我总是忘记语言的基本方面(比如解析文本文件和其他简单的东西)。我想每天练习一些基本的东西,我想知道是否有一些我可以订阅的网站,并且会向我发送当天的Ruby问题或类似的东西。有人知道这样的站点/Internet服务吗?
电脑上可以截取图片吗?如果可以,该如何操作呢?相信很多小伙伴都只知道一两种截图的方式,知道的并不全面。其实,电脑上有多种方式截图的,而且非常方便。电脑怎么截图?今天我们就来教大家如何使用电脑截取图片的8种常用方式!操作环境:演示机型:Delloptiplex7050系统版本:Windows10方法一:系统自带截图具体操作:同时按下电脑的自带截图键【Windows+shift+S】,可以选择其中一种方式来截取图片:截屏有矩形截屏、任意形状截屏、窗口截屏和全屏截图。 方法二:QQ截图具体操作:在电脑登录QQ,然后同时按下【Ctrl+Alt+A】,可以任意截图你需要的界面,可以把截图的页面直接下载,