RuntimeError: [enforce fail at ..\c10\core\CPUAllocator.cpp:76] data. DefaultCPUAllocator: not enough memory: you tried to allocate 1105920 bytes.
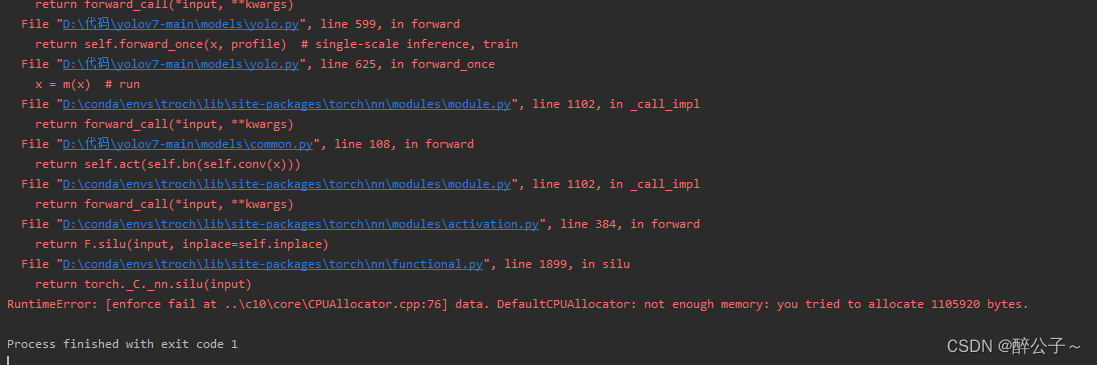
今天在使用自己电脑跑YOLOV7的时候,因为自己没有GPU所以使用CPU来跑测试模型,使用CPU来进行一张独立的图像进行预测,跑一张图像完全没有问题,非常的nice!!!但是,但是我接下来进行一段视频(多张图像)的预测,他给我说内存分配不足,
DefaultCPUAllocator: not enough memory: you tried to allocate 1105920 bytes.,
而且它这个不是在跑第二张图像的是后出现的,是在计算第17张图像时出现,后面多次内存释放都不行~~~~~~~~
在pytorch中,tensor有一个requires_grad参数,如果设置为True,则反向传播时,该tensor就会自动求导。tensor的requires_grad的属性默认为False,若一个节点(叶子变量:自己创建的tensor)requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True(即使其他相依赖的tensor的requires_grad = False)
注:requires_grad是Pytorch中通用数据结构Tensor的一个属性,用于说明当前量是否需要在计算中保留对应的梯度信息,以线性回归为例,容易知道权重w和偏差b为需要训练的对象,为了得到最合适的参数值,我们需要设置一个相关的损失函数,根据梯度回传的思路进行训练。
当requires_grad设置为False时,反向传播时就不会自动求导了,因此大大节约了显存或者说内存。
那么本问题的解决方法也就随之而来, 在测试的时候让模型不要记录梯度就好, 因为其实也用不到。
使用 with torch.no_grad(),在测试的时候让模型不要保存梯度:
with torch.no_grad():
output, _ = model(image) # 在图像计算前加入
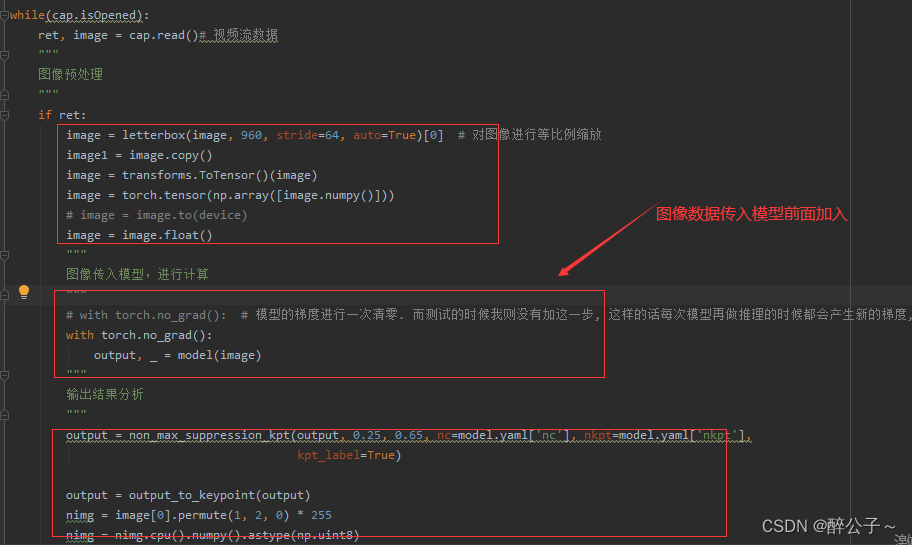
这样在模型对每张图像进行计算的时候,不会再去求导,梯度不会保存!
完美解决!
希望这篇文章对你有用!
谢谢点赞评论!
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我刚刚开始从Ruby1.8.7升级到Ruby1.9.2(使用RVM)。我的所有应用程序都使用“脚本/服务器”(或“rails服务器”)和1.9.2运行,但是,只有Rails3.0.0RC应用程序可以与Passenger一起使用。Rails2.3.8应用给出的错误信息是:invalidbytesequenceinUS-ASCII我猜这是一个Passenger问题。我使用找到的RVM指南安装了Passenger2.2.15here.任何想法如何修复这个错误?谢谢。我已更新以包含堆栈跟踪:/Users/kevin/.rvm/gems/ruby-1.9.2-p0/gems/actionpack
尝试在我的Rails应用程序中导入CSV文件时,出现错误UTF-8中的无效字节序列。一切正常,直到我添加了一个gsub方法来将其中一个CSV列与我的数据库中的一个字段进行比较。当我导入CSV文件时,我想检查每一行的地址是否包含在特定客户端的不同地址数组中。我有一个带有alt_addresses属性的客户端模型,其中包含客户端地址的几种不同可能格式。然后我有一个引用模型(如果您熟悉本地SEO,您就会知道这个术语)。引用模型没有地址字段,但它有一个nap_correct?字段(NAP代表“姓名”、“地址”、“电话号码”)。如果CSV行的名称、地址和电话号码与我在该客户的数据库中拥有的相同,
RuntimeError:CUDAerror:device-sideasserttriggered问题描述解决思路发现问题:总结问题描述当我在调试模型的时候,出现了如下的问题/opt/conda/conda-bld/pytorch_1656352465323/work/aten/src/ATen/native/cuda/IndexKernel.cu:91:operator():block:[5,0,0],thread:[63,0,0]Assertion`index>=-sizes[i]&&index通过提示信息可以知道是个数组越界的问题。但是如图一中第二行话所说这个问题可能并不出在提示的代码段
我在我的RubyonRails应用程序中使用ActiveRecord::Store模块时遇到了一个奇怪的问题。据我了解,该模块在后台使用“序列化”方法,因此它只是使用ruby内置的psychgem将您的数据序列化为yaml格式。大多数时候它工作正常,但有时我会收到500错误并显示以下消息:LoadError(cannotloadsuchfile--enc/trans/single_byte):~/.rbenv/versions/1.9.3-p286/lib/ruby/1.9.1/psych/visitors/emitter.rb:27:in`write'~/.rbenv/versi
我对UTF-8编码有一些问题。我在这里阅读了一些帖子,但它仍然无法正常工作。这是我的代码:#!/bin/envruby#encoding:utf-8defdeterminefile=File.open("/home/lala.txt")file.eachdo|line|puts(line)type=line.match(/DOG/)puts('aaaaa')iftype!=nilputs(type[0])breakendendend这是我文件的前3行:;?lalalalal60000065535-1362490443-0000006334-0000018467-0000000041en
我尝试通过以下命令在我的计算机上安装gem(Mechanize):>>geminstallmechanize--platform=ruby>>geminstallmechanize错误ERROR:Errorinstallingmechanize:ERROR:Failedtobuildgemnativeextension."C:/ProgramFiles/Ruby200-x64/bin/ruby.exe"extconf.rbC:/ProgramFiles/Ruby200-x64/bin/ruby.exe:invalidswitchinRUBYOPT:-F(RuntimeError)在我尝
在IRB中,我正在尝试以下操作:1.9.3p194:001>foo="\xBF".encode("utf-8",:invalid=>:replace,:undef=>:replace)=>"\xBF"1.9.3p194:002>foo.match/foo/ArgumentError:invalidbytesequenceinUTF-8from(irb):2:in`match'知道出了什么问题吗? 最佳答案 我猜"\xBF"已经认为它是用UTF-8编码的,所以当你调用encode时,它认为你正在尝试编码一个UTF-8中的UTF-8字符
在我们的rails3.1.4应用程序中,rspec用于测试应用程序Controller中的公共(public)方法require_signin。这是require_signin方法:defrequire_signinif!signed_in?flash.now.alert="Loginfirst!"redirect_tosignin_pathendend这是rspec代码:it"shouldinvokerequire_signinforthosewithoutlogin"docontroller.send(:require_signin)controller{shouldredirec
我正在尝试上传一个csv文件,但收到UTF-8中的无效字节序列错误。我正在使用“roo”gem。我的代码是这样的:defupload_results_csvfilespreadsheet=MyFileUtil.open_file(file)header=spreadsheet.row(1)#THISLINERAISESTHEERROR(2..spreadsheet.last_row).eachdo|i|row=Hash[[header,spreadsheet.row(i)].transpose]......endclassMyFileUtildefself.open_file(file