Frida 使用教程和错误汇总
开始安卓学习之后,Frida和Xposed就经常使用,网上自学之路艰辛,在这过程中碰到了很多问题,故想做一个学习笔记,方便以后回顾。慢慢更新吧
以下是学习中碰到比较重要的网站:
Frida官方文档
Frida入门总结
Frida官方github
详细图片的流程可以看Frida入门总结
结合我个人安装经验的总结流程如下:
电脑上的frida安装:
- 安装
frida所需环境,python3- 安装
frida模块,pip install frida- 安装
frida-tools,pip install frida-tools
手机上的frida安装:
- 查看手机架构,
adb shell cat /proc/cpuinfo,可以看到我是64位的
或者可以用
adb shell getprop ro.product.cpu.abi获取cpu处理器位数:. armeabi-v7a(32位ARM设备). arm64-v8a(64位ARM设备)- 下载
frida-sever,官方下载地址:https://github.com/frida/frida/releases,可能需要代理才能下的比较快。
先看自己电脑上pip install 安装的什么版本的frida:使用frida --version,其次看手机架构,选择合适的下载版本。- 将下载的
frida-server压缩包解压,并将解压后的文件使用adb push 文件 /data/local/tmp(手机位置)放进手机中。- 赋予存入手机的
frida-server执行权限,注意需要su权限否则不能继续。使用adb shell进入手机命令行,使用su获取权限,进入存放frida-server的位置,cd /data/local/tmp,赋予执行权限chmod 777 文件名
运行
./文件名运行 (没有管理员权限即没有使用su会报Permission Denied)- 另起一个电脑端命令行,使用
frida-ps -U | grep frida可以看到手机端有无frida程序运行 (windows系统下使用frida-ps -U | findstr frida)- 之后就是编写脚本并执行(需要进行端口转发)
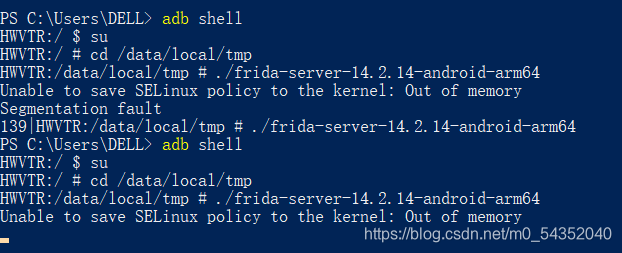
使用部分华为手机(不知道是不是只有华为手机会这样)运行Frida时,可能会报Unable to save SELinux policy to the kernel: Out of memory Segmentation fault错误,解决它的方法网上有两种。
- setenforce 0 详细见链接 https://github.com/frida/frida/issues/473
但现在是否可以成功未知- 重新编译内核 详细见链接
https://github.com/frida/frida/issues/1039
华为荣耀6x内核编译修改PTRACE安装xposed/frida并打开ro.debuggable记录
我使用的测试机是华为P10,运行Frida时有一定概率发生 Segmentation fault,会断开手机和电脑的连接,重新连接后再次或再多次尝试运行Frida,仅会报Unable to save SELinux policy to the kernel: Out of memory,不会段错误,并不影响后续使用。
在我使用magisk重新root之后不会发生错误。
注:这里具体情况我也不是很清楚,只是记录一下我的经历,或可给需要的人提供些信息
运行流程:以python为例(已完成安装)
- 电脑端编写好脚本hookApi.py
- 电脑端转发端口,使用
adb forward tcp:27043 tcp:27043和adb forward tcp:27042 tcp:27042命令- 手机端执行frida
PC端连接手机用root身份进入存放frida文件的文件夹下,./文件名启动(若不可以执行,记得chmod 777 文件名)加&后台启动- 电脑端使用python hookApi.py
端口转发命令
adb forward tcp:27042 tcp:27042
adb forward tcp:27043 tcp:27043
Frida Hook所使用的JS脚本该如何编写(官方教程:JavaScript API)
var my_class = Java.use('%s');
console.log("%s test")
my_class.%s.overload(%s).implementation = function(){
var ret = this.%s.overload(%s).apply(this, arguments);
var para_string = 'param: '
for(var i=0; i<arguments.length;i++){
para_string += arguments[i] + ' ' //函数参数获取
}
}
hook 类中类时要使用$符号链接类,例如Hook android.provider.Settings$Secure类
我对Native层接触较少,这部分具体细看 Frida入门总结中的 Hook Native层。
我对Frida的使用还比较基础,之后碰到了有需要学习再慢慢补充
可以在js代码内直接进行文件读写,但是需要注意:
没有读写权限时,只能读取安卓分配给应用的文件存储位置。
var file = new File("/sdcard/text.txt","a+");//a+表示追加内容,此处的模式和c语言的fopen函数模式相同
file.write(content + "\n");
file.flush()
file.close();
Frida JS脚本写好之后,上端接口可以用python、JS进行注入,我最常用的为python脚本
获取当前打开的app包名
adb shell dumpsys window | findstr mCurrentFocus
import frida
PACKAGE = "com.didiglobal.passenger"
frida_session = None
global script
script = None
if __name__ == '__main__':
device = frida.get_device_manager().enumerate_devices()[-1]
resume = False
try:
frida_session = device.attach(PACKAGE)
print("[INFO] Attach Success" )
except Exception as e:
pid = device.spawn(PACKAGE)
frida_session = device.attach(pid)
resume = True
print("[INFO] Spawn and attach success")
load_script()
# 注入js脚本,其中
# script = frida_session.create_script(hook_script)
# script.load()
if resume:
device.resume(pid)
sys.stdin.read(1)
script.unload()
exit(0)
在js代码内使用send函数,并在外部python进程中使用on_message函数接收,使用send发送的数据会以json格式输出
def on_message(message, data):
if 'send' == message['type']:
save_message(message['payload'])
def create_hookjs():
jscode = """
console.log("Script loaded successfully");
Java.perform(function(){
var jni_env = Java.vm.getEnv();
send(jni_env);
return ret;
}
"""
return jscode
def load_script():
global script
if script is not None:
script.unload()
hook_script = create_hookjs()
script = frida_session.create_script(hook_script)
script.on('message', on_message)
script.load()
console用于命令行打印,其函数有三个级别:log、warn、error
缓慢更新
报错信息:
frida.ServerNotRunningError: unable to connect to remote frida-server
设置端口转发
adb forward tcp:27042 tcp:27042
adb forward tcp:27043 tcp:27043
报错信息:
{“type”:“error”,“description”:“Error: invalid address”,“stack”:“Error: invalid address\n at Object.value [as patchCode] (frida/runtime/core.js:170:1)\n at Jt (frida/node_modules/frida-java-bridge/lib/android.js:945:1)\n at zt.activate (frida/node_modules/frida-java-bridge/lib/android.js:998:1)\n at Ut.replace (frida/node_modules/frida-java-bridge/lib/android.js:1045:1)\n at Function.set [as implementation] (frida/node_modules/frida-java-bridge/lib/class-factory.js:1010:1)\n at Function.set [as implementation] (frida/node_modules/frida-java-bridge/lib/class-factory.js:925:1)\n at installLaunchTimeoutRemovalInstrumentation (/internal-agent.js:249:24)\n at init (/internal-agent.js:33:3)\n at c.perform (frida/node_modules/frida-java-bridge/lib/vm.js:11:1)\n at g._performPendingVmOps (frida/node_modules/frida-java-bridge/index.js:238:1)”,“fileName”:“frida/runtime/core.js”,“lineNumber”:170,“columnNumber”:1}

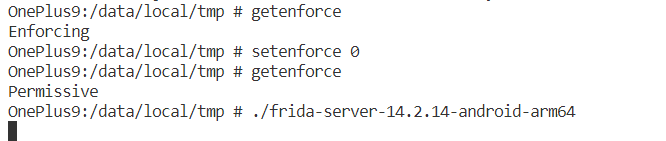
解决方法:关闭SELinux
$ su
$ setenforce 0
报错信息
Unable to start: Error binding to address 127.0.0.1:27042: Address already in use
我这里会有这个问题是因为我将frida后台运行了所以我重新运行frida的时候会正在使用
frida-ps -U | findstr frida 命令可以看到我这里仍然在运行

报错信息
Failed to attach: process with pid xxx either refused to load frida-agent, or terminated during injection
我设置frida后台运行,中间停止不使用再用就会有这类问题,我是使用root身份 kill xxx(frida-pid)之后重新启动可以修复
Frida入门总结
Frida从入门到入门—安卓逆向菜鸟的frida食用说明
FRIDA-API使用篇:rpc、Process、Module、Memory使用方法及示例
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
