文章目录
在上文的案例中我们添加了@LoadBalanced注解,即可实现负载均衡功能,这是什么原理呢?
我们这里的@LoadBalanced相当于是一个标记,标记这个RestTemplate发出的请求要被我们的Ribbon拦截和处理。
SpringCloud底层其实是利用了一个名为Ribbon的组件,来实现负载均衡功能的。
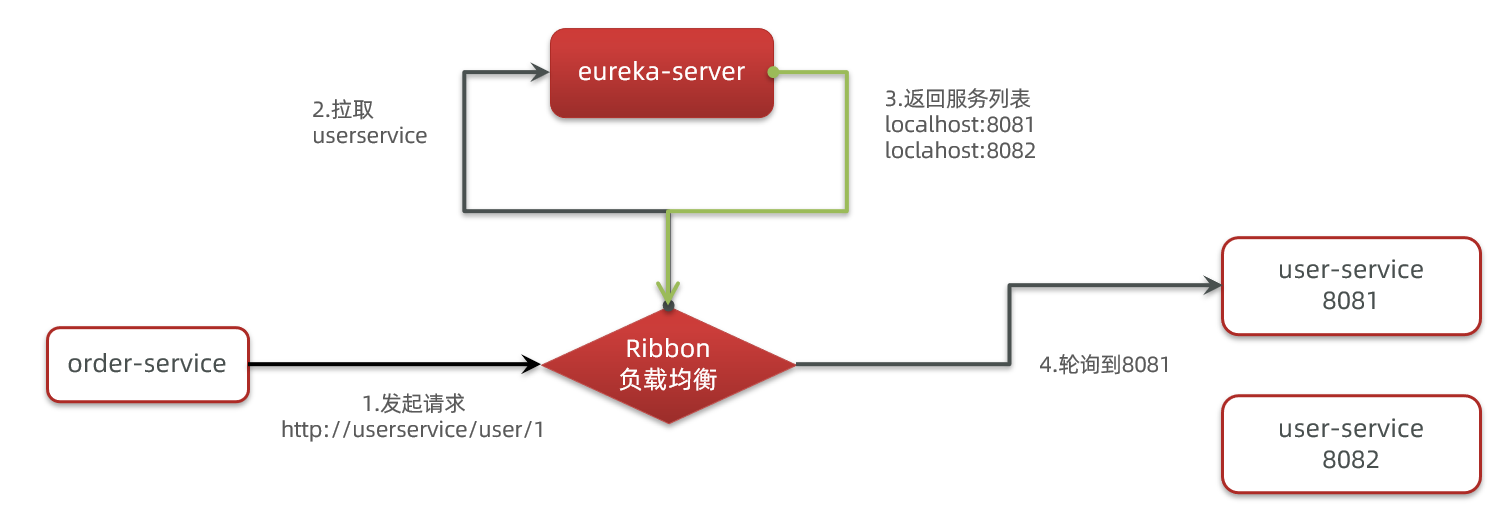
那么我们发出的请求明明是http://userservice/user/1,怎么变成了http://localhost:8081的呢?
为什么我们只输入了service名称就可以访问了呢?之前还要获取ip和端口。
显然有人帮我们根据service名称,获取到了服务实例的ip和端口。它就是LoadBalancerInterceptor,这个类会在对RestTemplate的请求进行拦截,然后从Eureka根据服务id获取服务列表,随后利用负载均衡算法得到真实的服务地址信息,替换服务id。
我们进行源码跟踪:
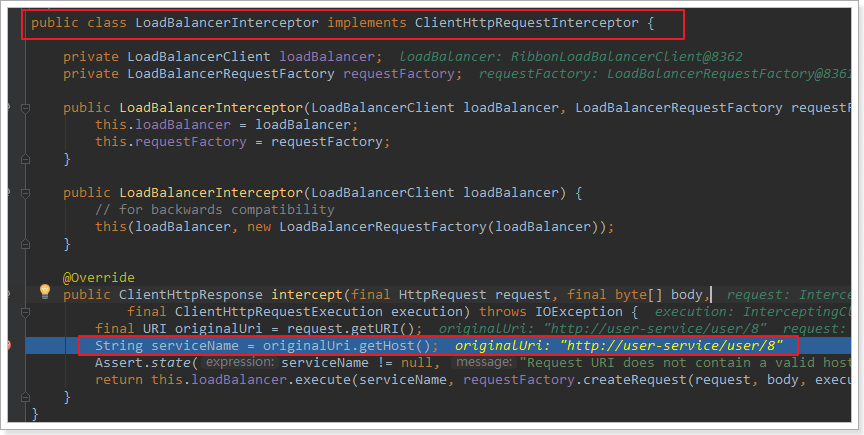
可以看到这里的intercept方法,拦截了用户的HttpRequest请求,然后做了几件事:
request.getURI():获取请求uri,本例中就是 http://user-service/user/8originalUri.getHost():获取uri路径的主机名,其实就是服务id,user-servicethis.loadBalancer.execute():处理服务id,和用户请求。这里的this.loadBalancer是LoadBalancerClient类型,我们继续跟入。
继续跟入execute方法:
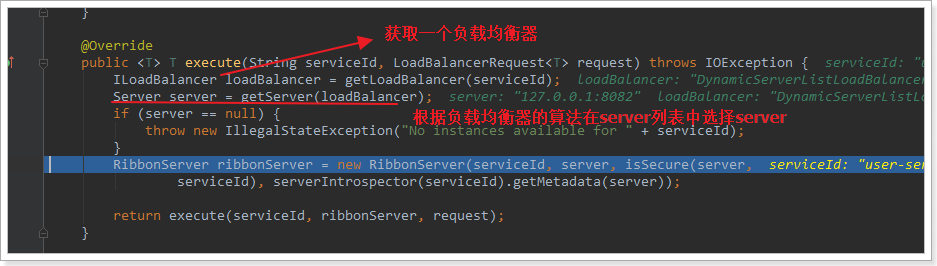
代码是这样的:
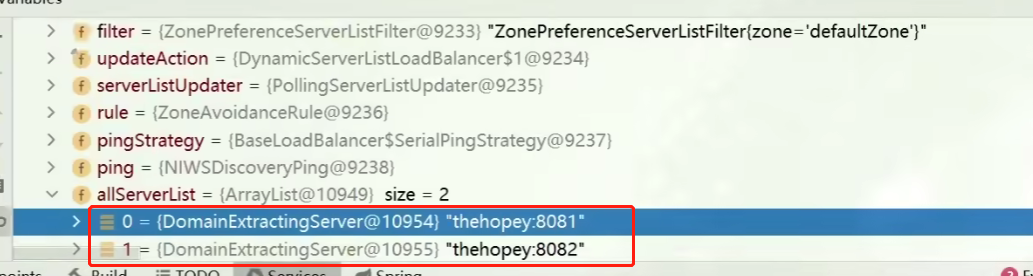
放行后,再次访问并跟踪,发现获取的是8081:
果然实现了负载均衡。
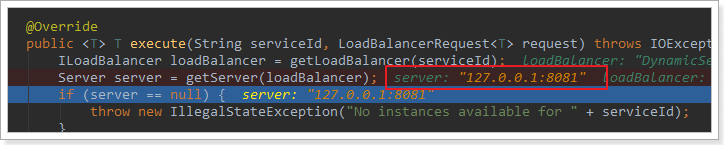
在刚才的代码中,可以看到获取服务使通过一个getServer方法来做负载均衡:
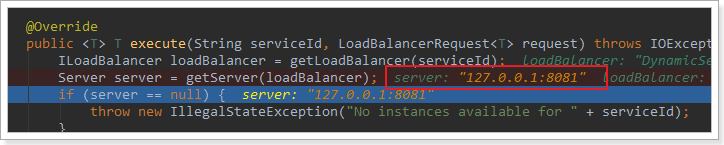
我们继续跟入:
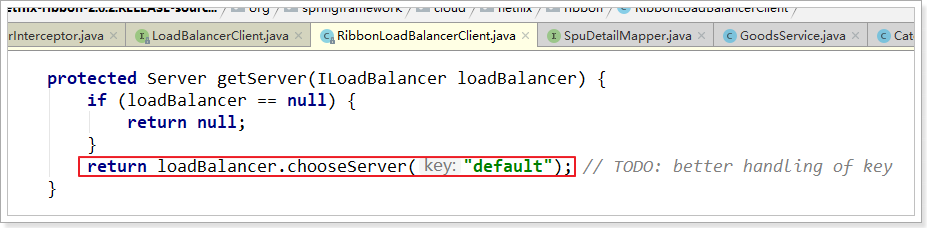
继续跟踪源码chooseServer方法,发现这么一段代码:
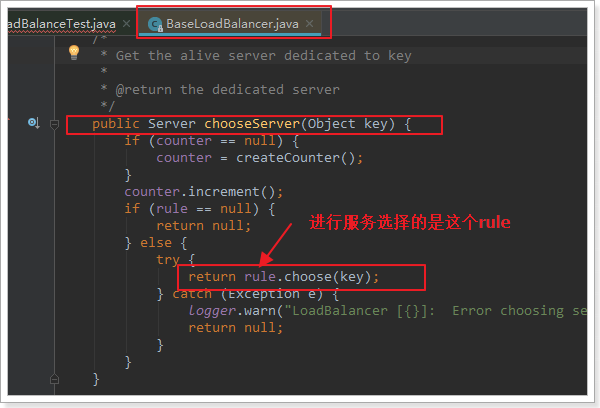
我们看看这个rule是谁:
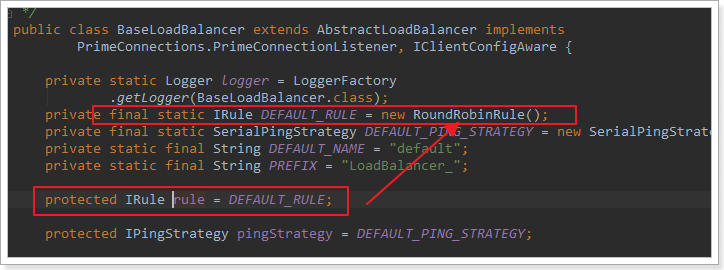
这里的rule默认值是一个RoundRobinRule,看类的介绍:
这不就是轮询的意思嘛。
到这里,整个负载均衡的流程我们就清楚了。
SpringCloudRibbon的底层采用了一个拦截器,拦截了RestTemplate发出的请求,对地址做了修改。用一幅图来总结一下:
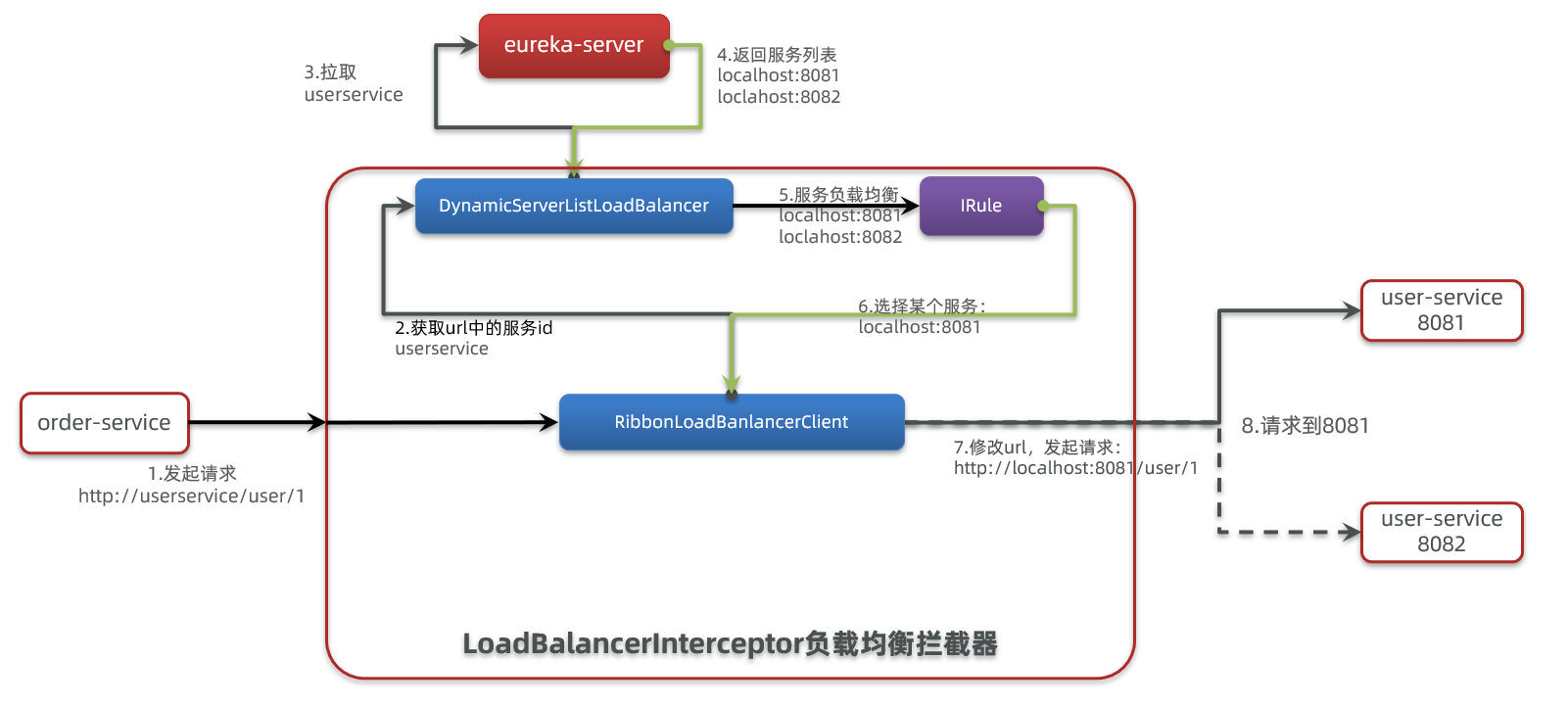
基本流程如下:
负载均衡的规则都定义在IRule接口中,而IRule有很多不同的实现类:
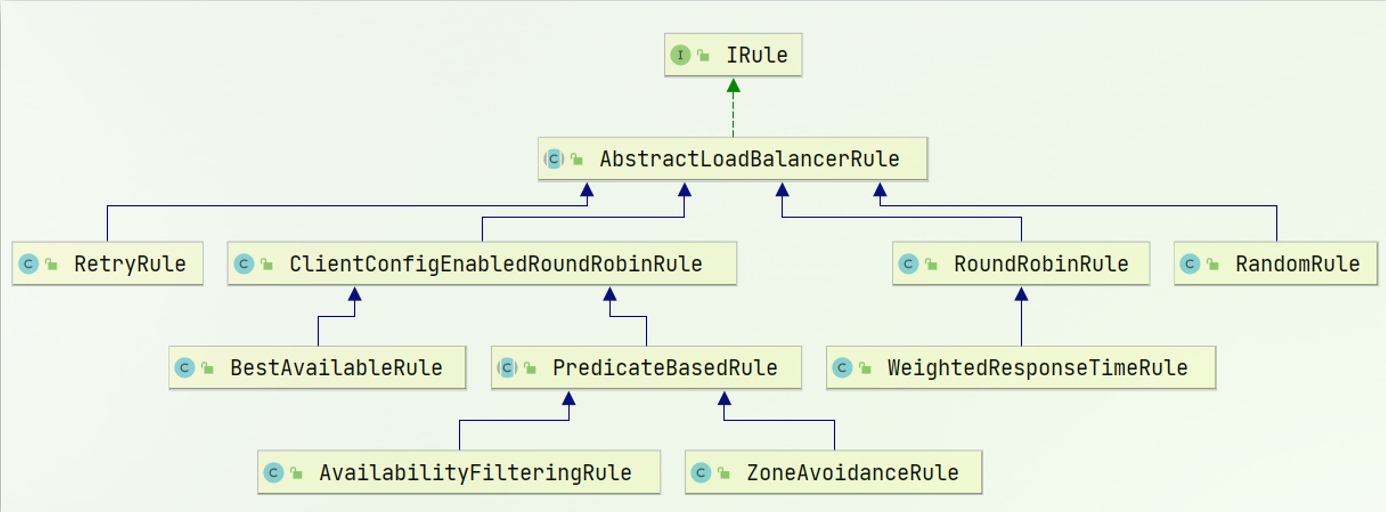
不同规则的含义如下:
| 内置负载均衡规则类 | 规则描述 |
|---|---|
| RoundRobinRule | 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。 |
| AvailabilityFilteringRule | 对以下两种服务器进行忽略: (1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加。 (2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上限,可以由客户端的..ActiveConnectionsLimit属性进行配置。 |
| WeightedResponseTimeRule | 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询。 |
| BestAvailableRule | 忽略那些短路的服务器,并选择并发数较低的服务器。 |
| RandomRule | 随机选择一个可用的服务器。 |
| RetryRule | 重试机制的选择逻辑 |
默认的实现就是ZoneAvoidanceRule,是一种轮询方案
通过定义IRule实现可以修改负载均衡规则,有两种方式:
@Bean
public IRule randomRule(){
return new RandomRule();
}
userservice: # 给某个微服务配置负载均衡规则,这里是userservice服务
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则
注意,一般用默认的负载均衡规则,不做修改。
Ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载:
ribbon:
eager-load:
enabled: true
clients: userservice
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
我有一个EC2实例正在运行。我有一个负载均衡器,它与EC2实例相关联。PingTarget:HTTP:3001/healthCheckTimeout:5secondsInterval:24secondsUnhealthythreshold:2Healthythreshold:10现在该实例显示为OutofService。我什至尝试更改监听端口等等。一切正常,直到重新启动我的EC2实例。任何帮助将不胜感激。仅供引用:我有一个在端口3001上运行的Rails应用程序,我有一个用于HTTP:80(loadbalancer)到HTTP:3001的监听器。我还在终端中通过ssh检查了正在运行的应
我对为我的RubyonRails3.1.3应用优化我的Unicorn设置的方法很感兴趣。我目前正在高CPU超大实例上生成14个工作进程,因为我的应用程序在负载测试期间似乎受CPU限制。在模拟负载测试中,每秒大约20个请求重放请求,我的实例上的所有8个内核都达到峰值,盒子负载飙升至7-8个。每个unicorn实例使用大约56-60%的CPU。我很好奇可以通过哪些方式对其进行优化?我希望能够每秒将更多请求汇集到这种大小的实例上。内存和所有其他I/O一样完全正常。在我的测试过程中,CPU越来越低。 最佳答案 如果您受CPU限制,您希望使用
我每12小时在我的亚马逊EC2微型实例上运行一次cron作业。它下载118MB的文件并使用json库解析它。这当然会使实例内存不足。我的实例有416MB的可用内存,但随后我运行脚本,它下降到6MB,然后被操作系统杀死。我想知道我在这里有什么选择?是否可以通过Ruby有效地解析它,或者我是否必须下降到像C这样的低级东西?我可以获得一个功能更强大的亚马逊实例,但我真的很想知道是否可以通过Ruby做到这一点。更新:我看过yajl。它可以在解析时为您提供json对象,但问题是,如果您的JSON文件仅包含1个根对象,那么它将被迫解析所有文件。我的JSON看起来像这样:--Root-Obj1-Ob
这篇文章,主要介绍如何使用SpringCloud微服务组件从0到1搭建一个微服务工程。目录一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件(2)微服务依赖1.2、搭建注册中心(1)引入依赖(2)配置文件(3)启动类1.3、搭建配置中心(1)引入依赖(2)配置文件(3)启动类1.4、搭建API网关(1)引入依赖(2)配置文件(3)启动类1.5、搭建服务提供者(1)引入依赖(2)配置文件(3)启动类1.6、搭建服务消费者(1)引入依赖(2)配置文件(3)启动类1.7、运行测试一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件这里主要是使用的SpringCloudNetflix
文章目录Kubernetes(k8s)工作负载一、Workloads二、Pod三、Deployment四、RC、RS、DaemonSet、StatefulSet五、Job、CronJob1、Job2、CronJob六、GCKubernetes(k8s)工作负载一、Workloads什么是工作负载(Workloads)工作负载是运行在Kubernetes上的一个应用程序。一个应用很复杂,可能由单个组件或者多个组件共同完成。无论怎样我们可以用一组Pod来表示一个应用,也就是一个工作负载Pod又是一组容器(Containers)所以关系又像是这样工作负载(Workloads)控制一组PodPod控制
模块之间的关系我们可以了解到一共有这么多服务,我们先启动这三个服务其中rouyi–api模块是远程调用也就是提取出来的openfeign的接口ruoyi–commom是通用工具模块其他几个都是独立的服务ruoyi-api模块api模块当中有几个提取出来的OpenFeign的接口分别为文件,日志,用户服务我们以RemoteUserService接口为例子:其中contextId="remoteUserService"为bean的名称,value=ServiceNameConstants.SYSTEM_SERVICE为接口的描述,fallbackFactory=RemoteUserFallback
Nginx的6种负载均衡策略【轮询/加权轮询weight/ip_hash/least_conn/urlhash/fair】总结:nginx负载均衡策略1、轮询策略轮询策略其实是一个特殊的加权策略,不同的是,服务器组中的各个服务器的权重都是1upstreambackend{server192.168.136.136weight=1;server192.168.136.136:81weight=1;server192.168.136.136:82weight=1;server192.168.136.136:83weight=1;}server{listen80;server_namelocalho
我正在尝试为模块实现懒惰加载。该模块有一堆儿童路线独特的出口名称。当我尝试访问路线时,这似乎不起作用。从我保存的这个示例中,这似乎可以:https://plnkr.co/edit/nnxaozitm00riixzemts?p=preview您可以看到我有孩子的路线{path:'list',component:HeroListComponent,outlet:'abc'},在hero-routing.module.ts和路由器出口:在hero.com.ponent.ts当我在本地运行时,我应该能够访问Localhost:3000/Heroes/(ABC:List),但似乎不起作用。注意:您可以通
🚗Es学习·第五站~🚩Es学习起始站:【微服务】Elasticsearch概述&环境搭建(一)🚩本文已收录至专栏:微服务探索之旅👍希望您能有所收获一.引入综合前几站所学,我们已经对Elasticsearch的使用有了一定的了解,接下来让我们一起通过一个综合实战案例来复习前几站所学内容,体会在实际生产中的作用。我们一起实现如下功能:酒店搜索和分页酒店结果过滤我周边的酒店酒店竞价排名数据聚合筛选选项搜索框自动补全酒店数据的同步二.环境搭建按照第一站的学习部署Elasticsearch并启动运行。按照第二站的学习中的如下步骤,初始化测试项目并在Es导入数据。使用Elasticsearch,肯定离不开