文章目录
大家好,我是阿光。
本专栏整理了《图神经网络代码实战》,内包含了不同图神经网络的相关代码实现(PyG以及自实现),理论与实践相结合,如GCN、GAT、GraphSAGE等经典图网络,每一个代码实例都附带有完整的代码。
正在更新中~ ✨

🚨 我的项目环境:
💥 项目专栏:【图神经网络代码实战目录】
本文我们将使用Pytorch + Pytorch Geometric来简易实现一个DeepWalk,让新手可以理解如何PyG来搭建一个简易的图网络实例demo。
本项目我们需要结合两个库,一个是Pytorch,因为还需要按照torch的网络搭建模型进行书写,第二个是PyG,因为在torch中并没有关于图网络层的定义,所以需要torch_geometric这个库来定义一些图层。
import matplotlib.pyplot as plt
import torch
from sklearn.manifold import TSNE
from torch_geometric.datasets import Planetoid
from torch_geometric.nn import Node2Vec
本文使用的数据集是比较经典的Cora数据集,它是一个根据科学论文之间相互引用关系而构建的Graph数据集合,论文分为7类,共2708篇。
这个数据集是一个用于图节点分类的任务,数据集中只有一张图,这张图中含有2708个节点,10556条边,每个节点的特征维度为1433。
# 1.加载Cora数据集
dataset = Planetoid(root='./data/Cora', name='Cora')
本项目是使用 Node2Vec 来生成每个节点的特征,所以对于原始节点特征是无用的,本项目只是单纯利用 Cora 数据集的节点空间关系,也就是 edge_index ,基于节点的空间关系来生成对应的节点特征,最终验证生成的节点特征效果如何。
这里我们就不重点介绍DeepWalk了,相信大家能够掌握基本原理,本文我们使用的是PyG定义这个网络,在PyG中已经定义好了 Node2Vec 这个层,我们可以利用这个层来实现 DeepWalk 。
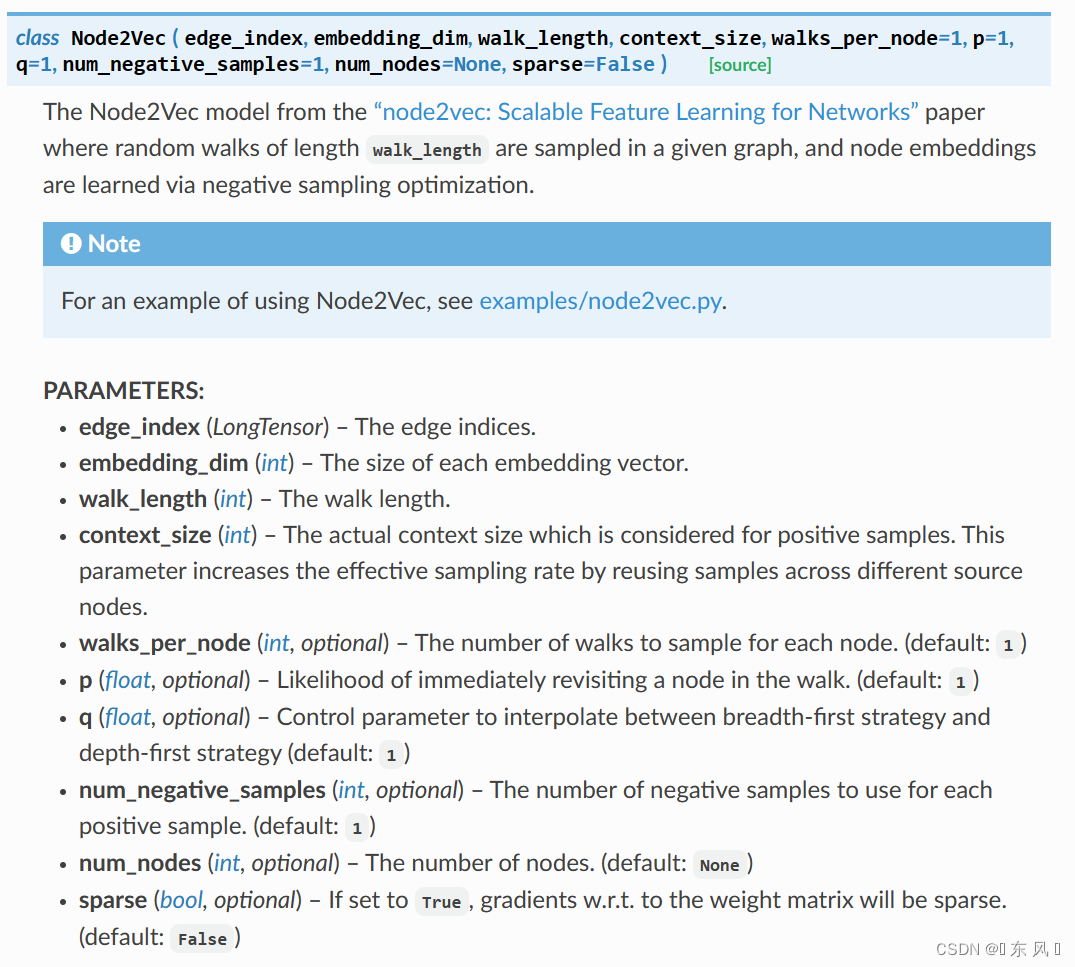
对于Node2Vec的常用参数:
data 的 edge_index,形状为【2,num_edges】如果熟悉 DeepWalk 和 Node2Vec 两个算法的小伙伴可以发现,如果把 Node2Vec 在游走时设置的概率 p 和 q 同时设为1,此时 Node2Vec 就会退化成为 DeepWalk 。
# deepwalk模型
model = Node2Vec(edge_index=data.edge_index,
embedding_dim=128, # 节点维度嵌入长度
walk_length=5, # 序列游走长度
context_size=4, # 上下文大小
walks_per_node=1, # 每个节点游走10个序列
p=1,
q=1,
sparse=True # 权重设置为稀疏矩阵
).to(device)
对于模型训练等部分,与 Node2Vec 实现方式一致,所以这里不再赘述,如果不清楚的小伙伴可以先去查看本传内的这篇文章 PyG基于Node2Vec实现节点分类及其可视化,这篇文章详细介绍了代码实战部分。
上面我们以经训练好了 DeepWalk 这个模型,通过调用 model() 即可获得内部的权重矩阵,也就是我们要的Embedding向量表(lookup table)。
生成好每个节点的 Embedding,我们可以通过可视化的方式更加直观的看到效果如何,对于可视化操作我们利用的是 TSNE 这个模块来进行降维,因为绘制二维图形需要x轴和y轴坐标(即二维),降到两个维度后,就获得了每个节点的坐标信息,然后利用 matplotlib 这个库来绘制不同类别的节点信息。

# 可视化节点的embedding
with torch.no_grad():
# 不同类别节点对应的颜色信息
colors = [
'#ffc0cb', '#bada55', '#008080', '#420420', '#7fe5f0', '#065535',
'#ffd700'
]
model.eval() # 开启测试模式
# 获取节点的embedding向量,形状为[num_nodes, embedding_dim]
z = model(torch.arange(data.num_nodes, device=device))
# 使用TSNE先进行数据降维,形状为[num_nodes, 2]
z = TSNE(n_components=2).fit_transform(z.detach().numpy())
y = data.y.detach().numpy()
plt.figure(figsize=(8, 8))
# 绘制不同类别的节点
for i in range(dataset.num_classes):
# z[y==0, 0] 和 z[y==0, 1] 分别代表第一个类的节点的x轴和y轴的坐标
plt.scatter(z[y == i, 0], z[y == i, 1], s=20, color=colors[i])
plt.axis('off')
plt.show()
import matplotlib.pyplot as plt
import torch
from sklearn.manifold import TSNE
from torch_geometric.datasets import Planetoid
from torch_geometric.nn import Node2Vec
# 1.加载Cora数据集
dataset = Planetoid(root='../data/Cora', name='Cora')
data = dataset[0]
# 2.定义模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
# deepwalk模型
model = Node2Vec(edge_index=data.edge_index,
embedding_dim=128, # 节点维度嵌入长度
walk_length=5, # 序列游走长度
context_size=4, # 上下文大小
walks_per_node=1, # 每个节点游走1个序列
p=1,
q=1,
sparse=True # 权重设置为稀疏矩阵
).to(device)
# 迭代器
loader = model.loader(batch_size=128, shuffle=True)
# 优化器
optimizer = torch.optim.SparseAdam(model.parameters(), lr=0.01)
# 3.开始训练
model.train()
for epoch in range(1, 101):
total_loss = 0 # 每个epoch的总损失
for pos_rw, neg_rw in loader:
optimizer.zero_grad()
loss = model.loss(pos_rw.to(device), neg_rw.to(device)) # 计算损失
loss.backward()
optimizer.step()
total_loss += loss.item()
# 使用逻辑回归任务进行测试生成的embedding效果
with torch.no_grad():
model.eval() # 开启测试模式
z = model() # 获取权重系数,也就是embedding向量表
# z[data.train_mask] 获取训练集节点的embedding向量
acc = model.test(z[data.train_mask], data.y[data.train_mask],
z[data.test_mask], data.y[data.test_mask],
max_iter=150) # 内部使用LogisticRegression进行分类测试
# 打印指标
print(f'Epoch: {epoch:02d}, Loss: {total_loss:.4f}, Acc: {acc:.4f}')
# 可视化节点的embedding
with torch.no_grad():
# 不同类别节点对应的颜色信息
colors = [
'#ffc0cb', '#bada55', '#008080', '#420420', '#7fe5f0', '#065535',
'#ffd700'
]
model.eval() # 开启测试模式
# 获取节点的embedding向量,形状为[num_nodes, embedding_dim]
z = model(torch.arange(data.num_nodes, device=device))
# 使用TSNE先进行数据降维,形状为[num_nodes, 2]
z = TSNE(n_components=2).fit_transform(z.detach().numpy())
y = data.y.detach().numpy()
plt.figure(figsize=(8, 8))
# 绘制不同类别的节点
for i in range(dataset.num_classes):
# z[y==0, 0] 和 z[y==0, 1] 分别代表第一个类的节点的x轴和y轴的坐标
plt.scatter(z[y == i, 0], z[y == i, 1], s=20, color=colors[i])
plt.axis('off')
plt.show()
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我即将开始一个将录制和编辑音频文件的项目,我正在寻找一个好的库(最好是Ruby,但会考虑Java或.NET以外的任何库)以进行实时可视化波形。有人知道我应该从哪里开始搜索吗? 最佳答案 要流入浏览器的数据量很大。Flash或Flex图表可能是唯一能提高内存效率的解决方案。Javascript图表往往会因大型数据集而崩溃。 关于ruby-Ruby中的波形可视化,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定