文章目录
标量:由单一数值构成的对待研究对象的量化评价,标量的定义与其代表的数据类型强相关
cm的实数值表示身高0或1的布尔型值表示信用状况向量:如果在标定或描述一个事物的特征时需要用到多个标量,那么它就称之为向量
给定任一向量 x = [ x 1 , x 2 , . . . , x d ] x=[x_{1},x_{2},...,x_{d}] x=[x1,x2,...,xd],它包含大小与方向两类信息,只有各分量位置处取相同值时两个向量才相等
若有集合 s = { 1 , 3 , 5 } s=\{1,3,5\} s={1,3,5},则
注意以下特殊向量
坐标系中的向量表示:在线性代数中,向量是一个以坐标原点为起点的箭头
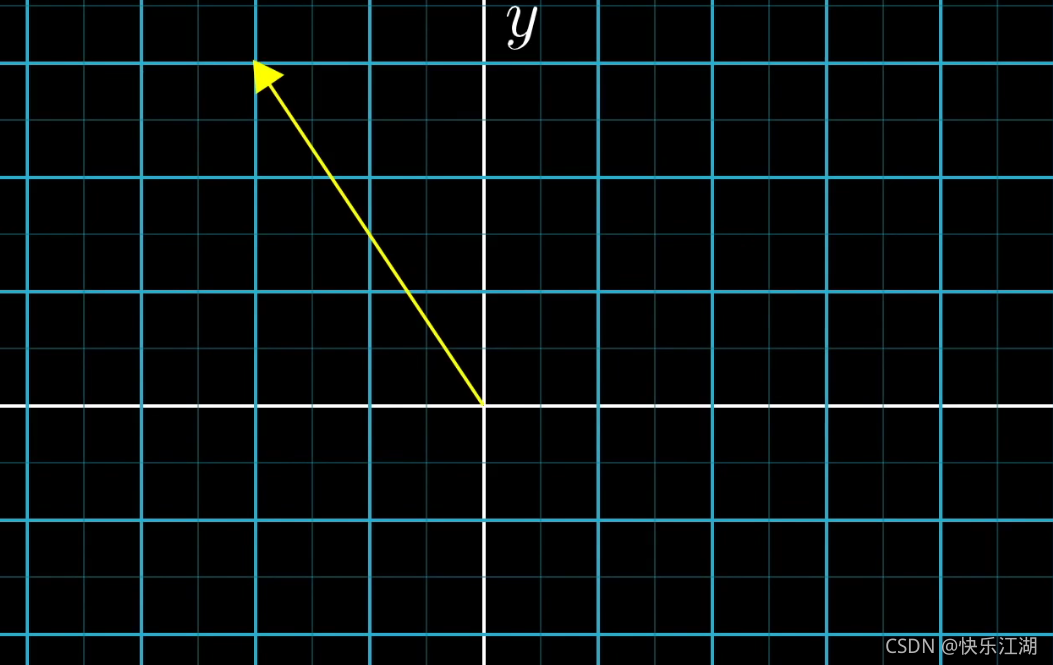
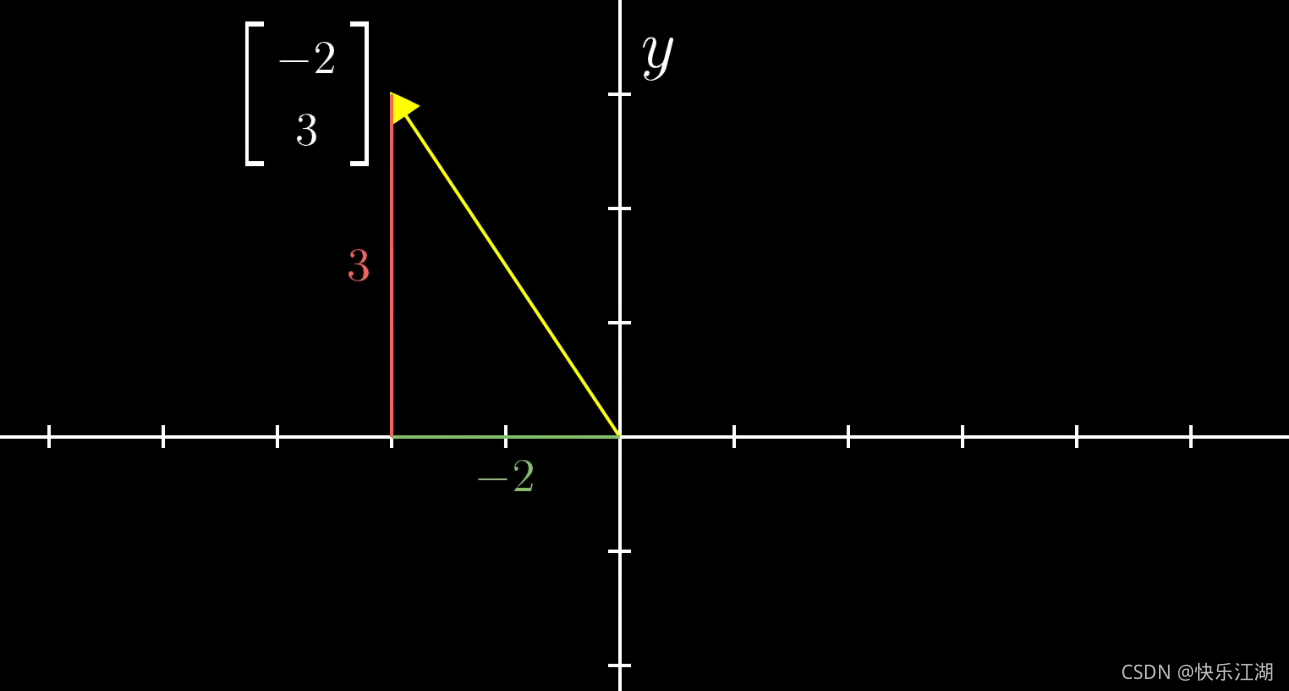
以 ( − 2 3 ) \begin{pmatrix} -2\\ 3\end{pmatrix} (−23)为例,这一对数表示了如何从原点(向量起点)到达末端(向量终点)。每一对数给出了唯一的一个向量,而每一个向量又恰好对应唯一的一对数
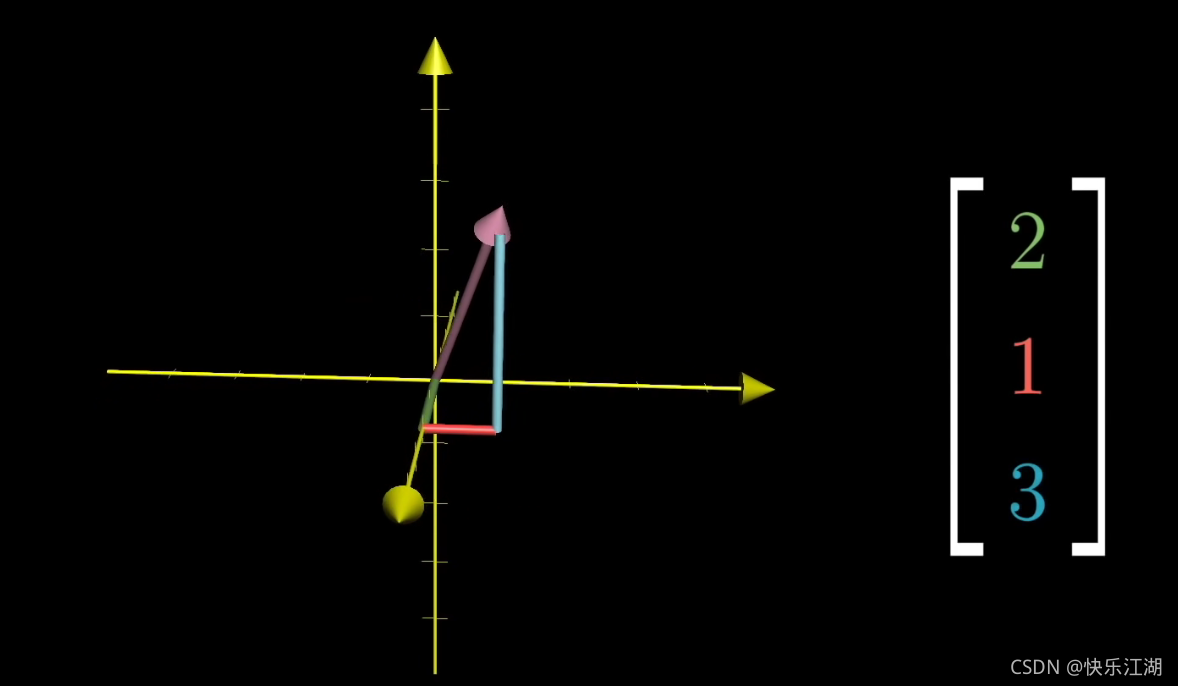
再以 ( 2 1 3 ) \begin{pmatrix} 2\\ 1\\ 3\end{pmatrix} ⎝⎛213⎠⎞为例
向量运算:即向量之间的运算,在实际问题中会经常涉及向量运算。例如:“在共同申请贷款时,银行会把双方的特征向量作为一个整体来考虑他们是否满足标准”
加减与数乘:对于给定向量 x 1 = [ g 1 , h 1 , r 1 ] x_{1}=[g_{1}, h_{1}, r_{1}] x1=[g1,h1,r1]和 x 2 = [ g 2 , h 2 , r 2 ] x_{2}=[g_{2}, h_{2}, r_{2}] x2=[g2,h2,r2],则
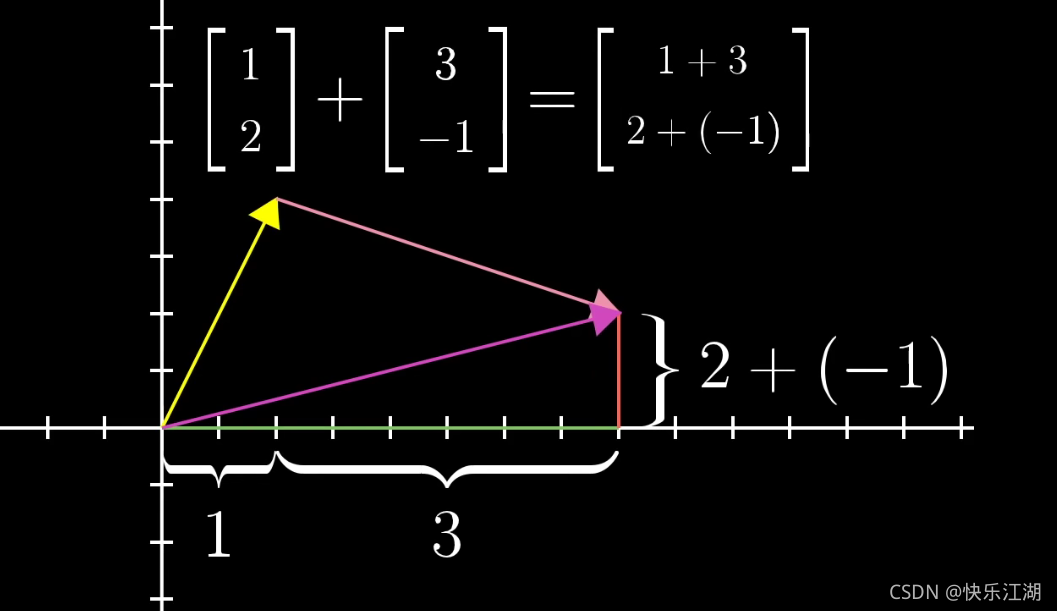
向量加法举例: ( 1 2 ) \begin{pmatrix} 1\\ 2\end{pmatrix} (12)+ ( 3 − 1 ) \begin{pmatrix} 3\\ -1\end{pmatrix} (3−1)= ( 4 1 ) \begin{pmatrix} 4\\ 1\end{pmatrix} (41)
首先 ( 1 2 ) \begin{pmatrix} 1\\ 2\end{pmatrix} (12)和 ( 3 − 1 ) \begin{pmatrix} 3\\ -1\end{pmatrix} (3−1)这两个向量在坐标系中表示如下
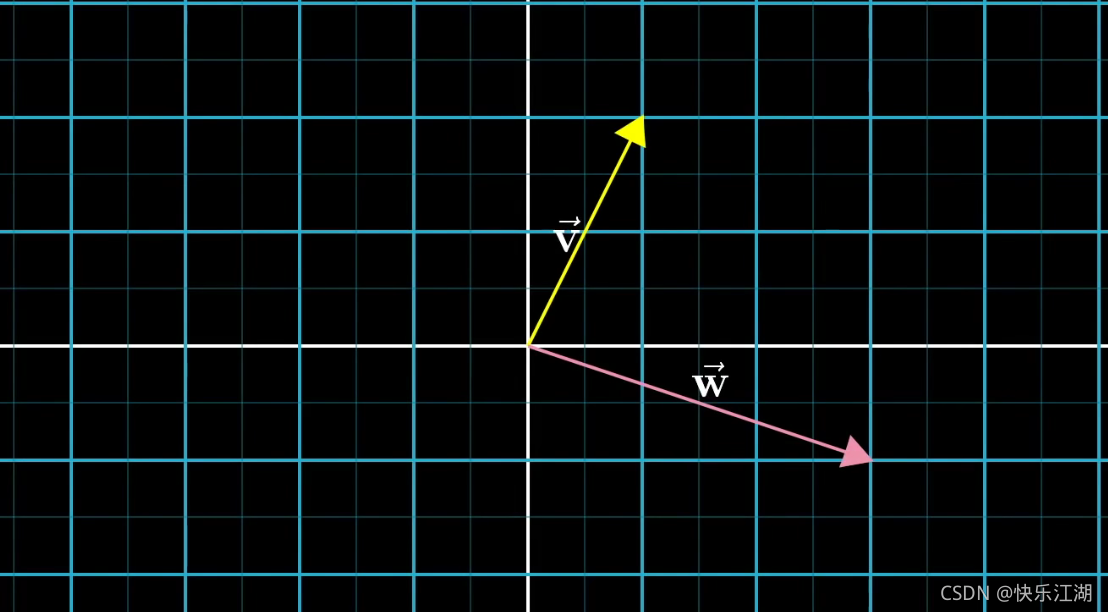
移动第二个向量,使其起点对齐至第一个向量的末尾,然后连线
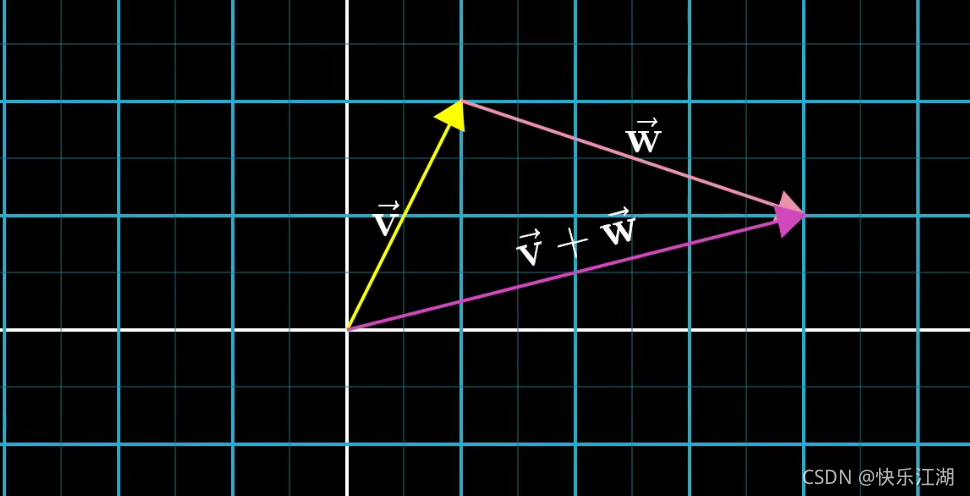
为什么向量加法要这样操作呢?其实向量从某种方面来讲,揭示的是一种运动趋势,自然就有方向和距离,所以大家可以看到向量的和其实就是最终的运动趋势。体现在运算上,就是各个分量对应相加
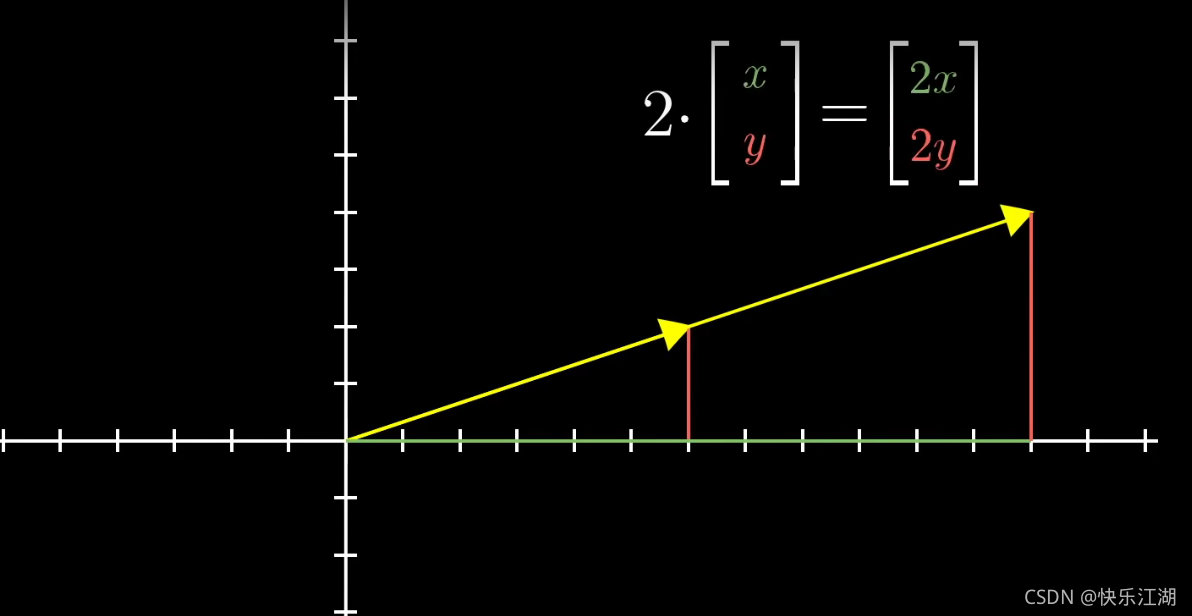
向量数乘举例:2· ( 1 2 ) \begin{pmatrix} 1\\ 2\end{pmatrix} (12)= ( 2 4 ) \begin{pmatrix} 2\\ 4\end{pmatrix} (24)
对于一个向量,对其延长2倍等于把它的每个分量都乘以2,也即
2·
(
1
3
)
\begin{pmatrix} 1\\ 3\end{pmatrix}
(13)=
(
1
×
2
3
×
2
)
\begin{pmatrix} 1×2\\ 3×2\end{pmatrix}
(1×23×2) =
(
2
6
)
\begin{pmatrix} 2\\ 6\end{pmatrix}
(26)
在人工智能领域处理数据时,常常会构造一个特征空间 [ g , h , r ] [g, h, r] [g,h,r]然后把所有数据都变换到空间中去,然后通过操控特征空间对数据做出评判和处理
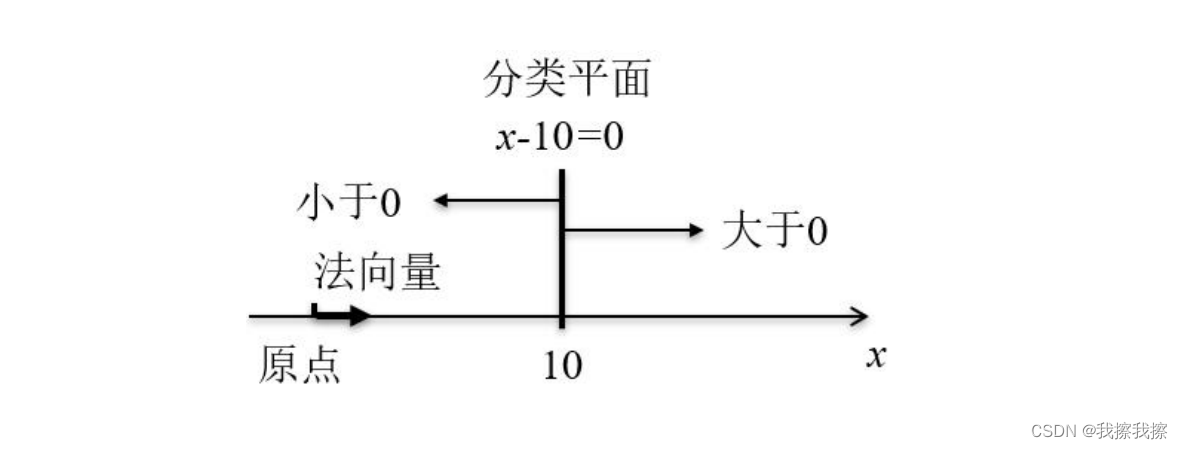
如果这个空间只有一个维度,那么在坐标轴上就是一条直线,例如 x = 10 x=10 x=10,其右侧大于 0 0 0,左侧小于 0 0 0
如果这个空间有两个维度,那么就是一个平面,以直线方程 x − y + 1 = 0 x-y+1=0 x−y+1=0,在法向量那一侧的大于0,与法向量相反的那一侧小于0。同时 x − y + 1 = 0 x-y+1=0 x−y+1=0实际上就是向量 a = [ x , y , 1 ] a=[x, y, 1] a=[x,y,1]和向量 w = [ 1 , − 1 , 1 ] w=[1,-1,1] w=[1,−1,1]的内积,也即 w a T = 0 wa^{T}=0 waT=0
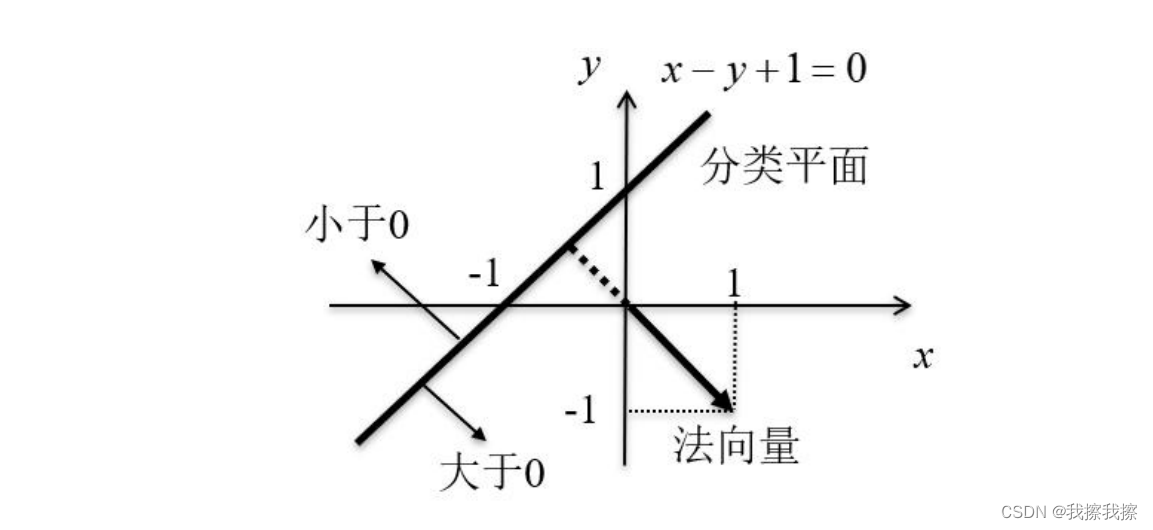
向量内积:给定向量 x 1 = [ x 1 , 1 , x 1 , 2 , . . . , x 1 , d ] x_{1}=[x_{1,1},x_{1,2},...,x_{1,d}] x1=[x1,1,x1,2,...,x1,d]和向量 x 2 = [ x 2 , 1 , x 2 , 2 , . . . , x 2 , d ] x_{2}=[x_{2,1},x_{2,2},...,x_{2,d}] x2=[x2,1,x2,2,...,x2,d],则 x 1 x_{1} x1和 x 2 x_{2} x2的内积为 x 1 x 2 T = < x 1 , x 2 > = ∑ i = 1 d x 1 , i x 2 , i x_{1}x_{2}^{T}=<x_{1},x_{2}>=\sum\limits_{i=1}^{d}x_{1,i}x_{2,i} x1x2T=<x1,x2>=i=1∑dx1,ix2,i,向量内积满足交换律,即 < x 1 , x 2 > = < x 2 , x 1 > <x_{1},x_{2}>=<x_{2},x_{1}> <x1,x2>=<x2,x1>。向量进行内积运算的结果为标量,这意味着内积的转置等于自身,即 x 1 x 2 T = x 2 x 1 T = ( x 1 x 2 T ) T x_{1}x_{2}^{T}=x_{2}x_{1}^{T}=(x_{1}x_{2}^{T})^{T} x1x2T=x2x1T=(x1x2T)T
向量内积的几何意义有两点, < x 1 , x 2 > = ∣ ∣ x 1 ∣ ∣ ∣ ∣ x 2 ∣ ∣ c o s θ <x_{1},x_{2}>=||x_{1}|| ||x_{2}||cos\theta <x1,x2>=∣∣x1∣∣∣∣x2∣∣cosθ
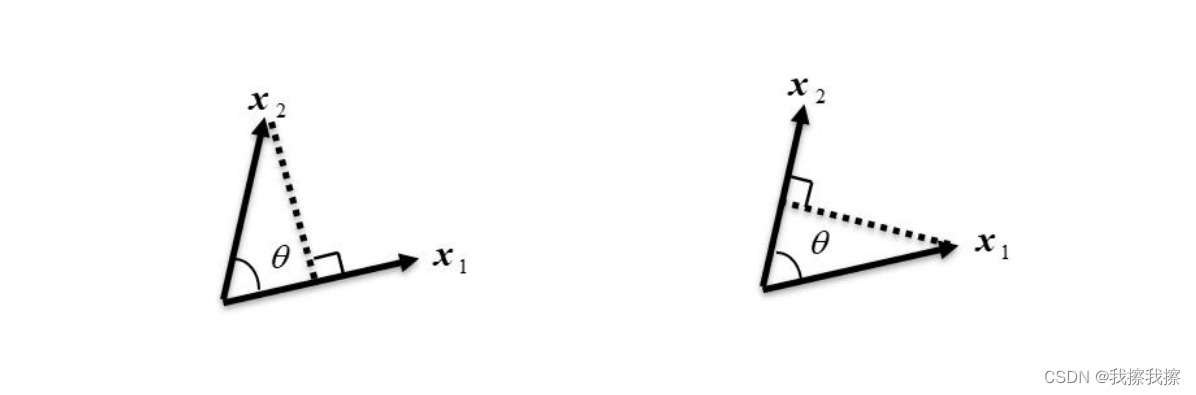
如果向量内积结果为0,这表明两个向量正交;如果相互正交的两个向量均为单位向量,则称这种正交为标准正交
柯西-施瓦茨不等式:由于 c o s θ ∈ [ − 1 , 1 ] cos\theta \in[-1,1] cosθ∈[−1,1],所以可得柯西-施瓦茨不等式
− ∣ ∣ x 1 ∣ ∣ ∣ ∣ x 2 ∣ ∣ ≤ < x 1 , x 2 > ≤ ∣ ∣ x 1 ∣ ∣ ∣ ∣ x 2 ∣ ∣ -||x_{1}||||x_{2}||\leq <x_{1},x_{2}>\leq ||x_{1}||||x_{2}|| −∣∣x1∣∣∣∣x2∣∣≤<x1,x2>≤∣∣x1∣∣∣∣x2∣∣
所以 θ \theta θ取值不同时,两个向量会呈现出不同的形式
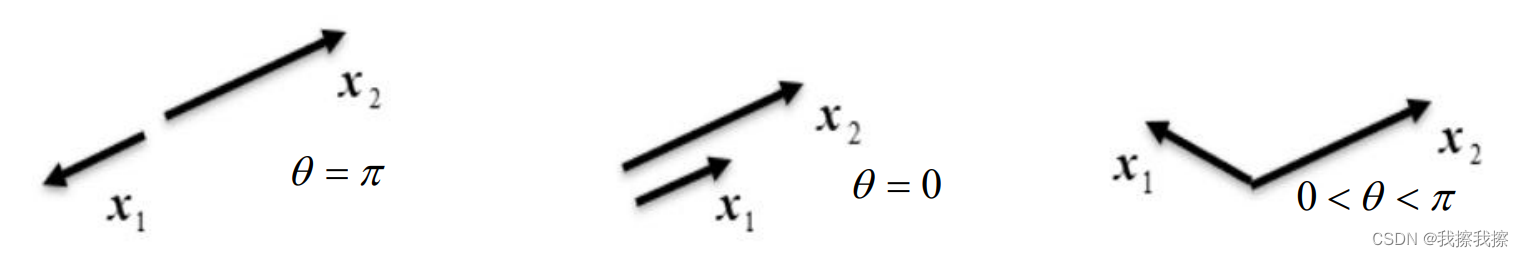
如果两个内积向量均已被单位化(也即长度均为1),则向量内积可以作为两个向量相似程度的判断依据。在长度确定的情况下,内积结果越接近长度的乘积,则向量在方向上越相似

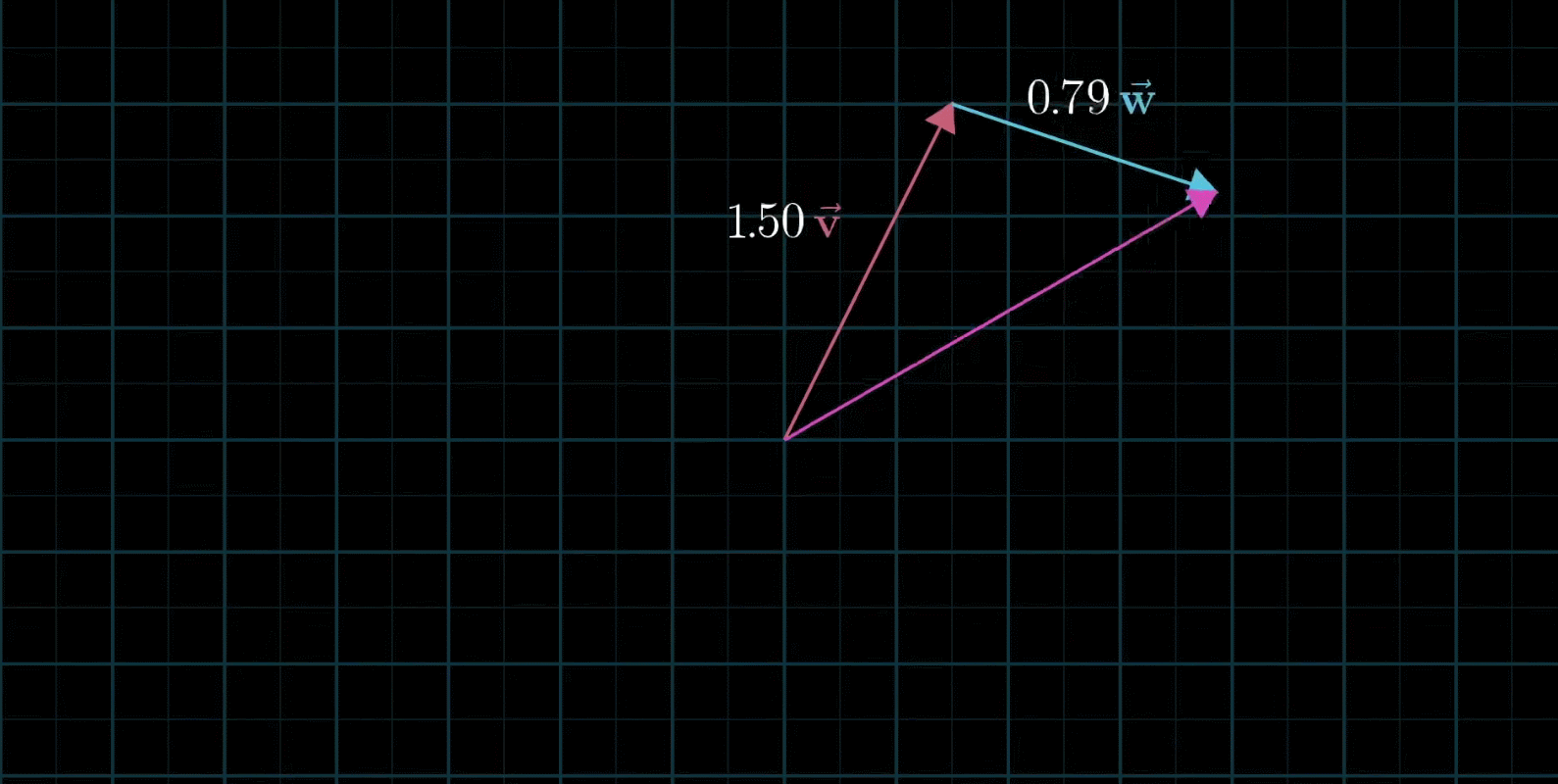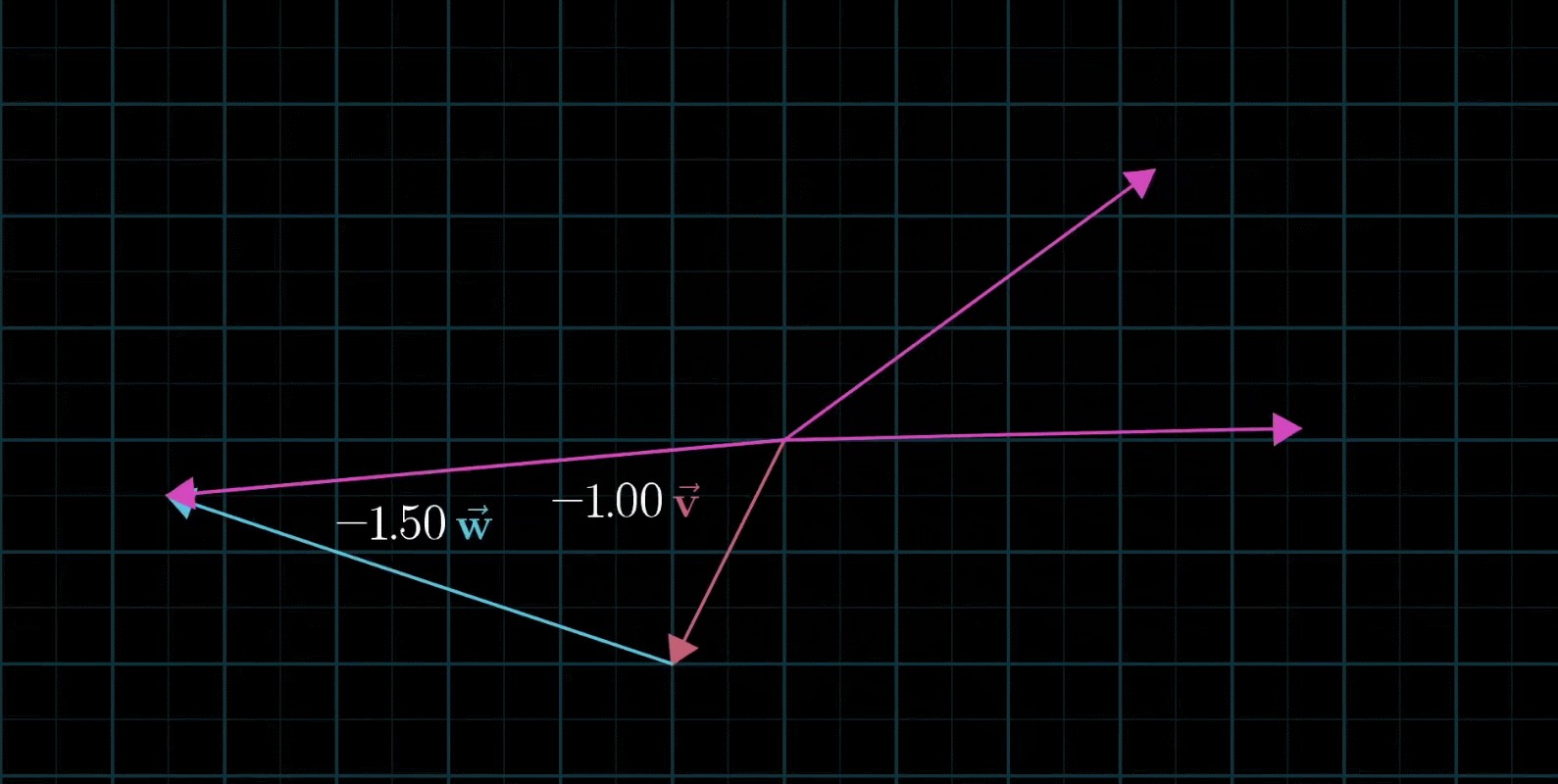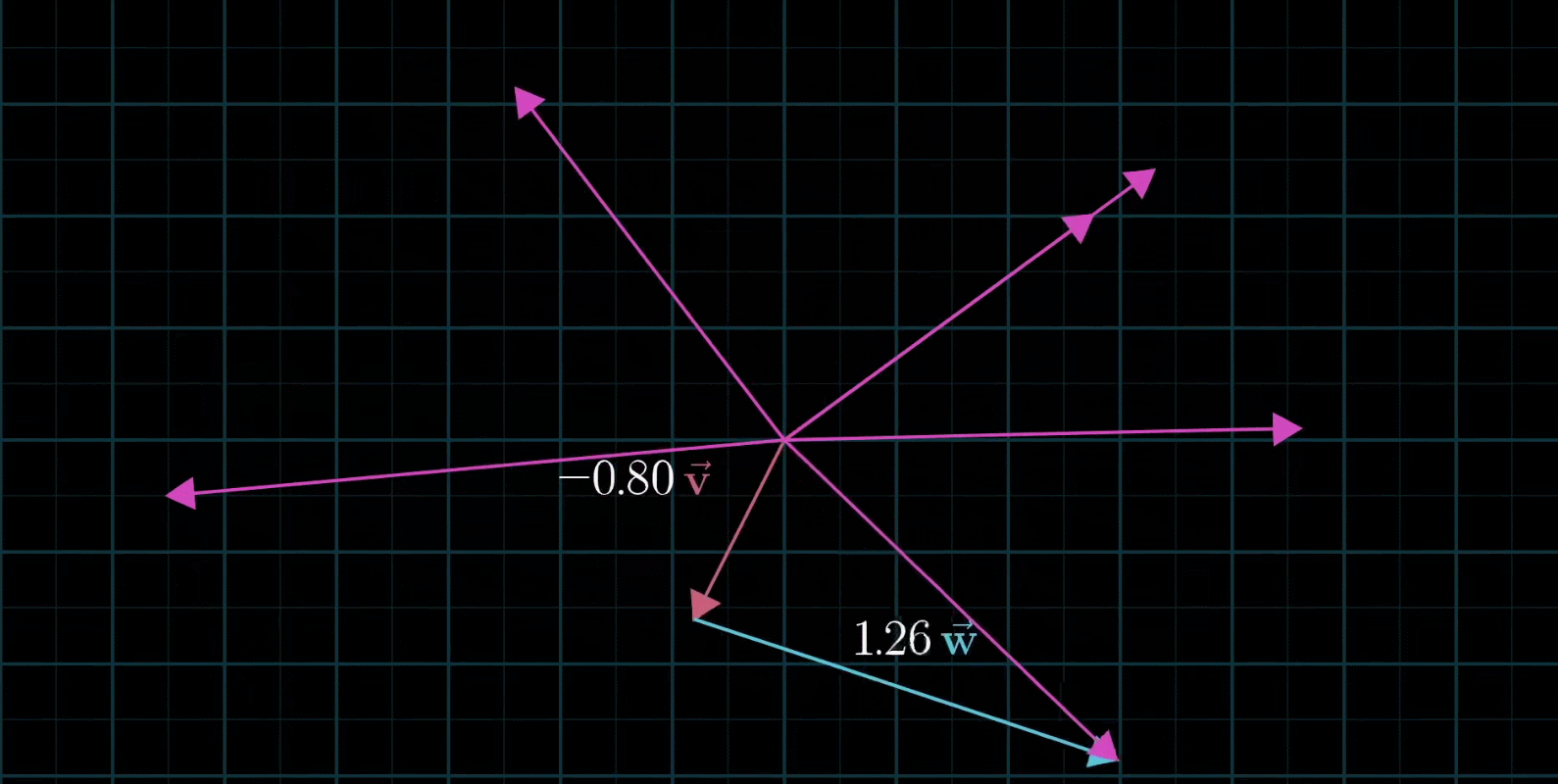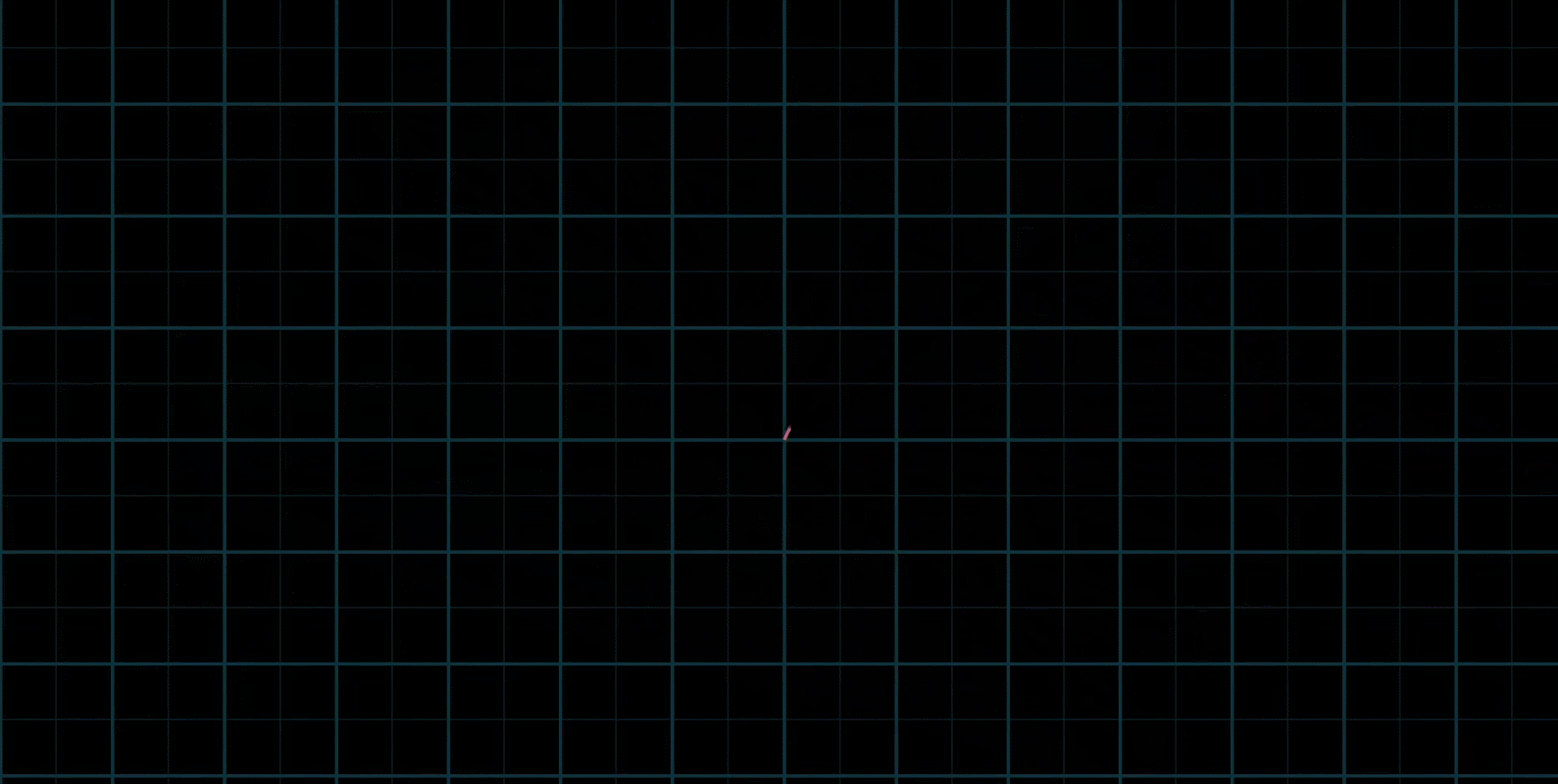
线性组合:两个数乘向量的和称为这两个向量的线性组合
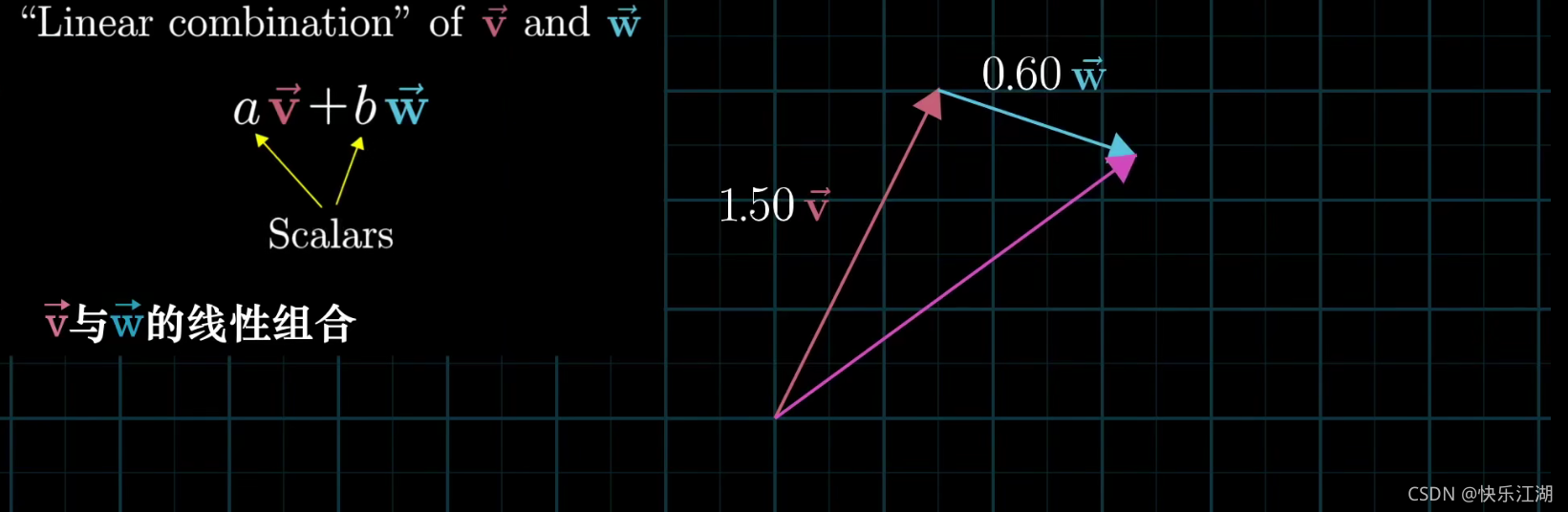

如果固定其中一个标量,让另外一个标量自由变换,那么所能表示的向量的终点会绘成一条直线
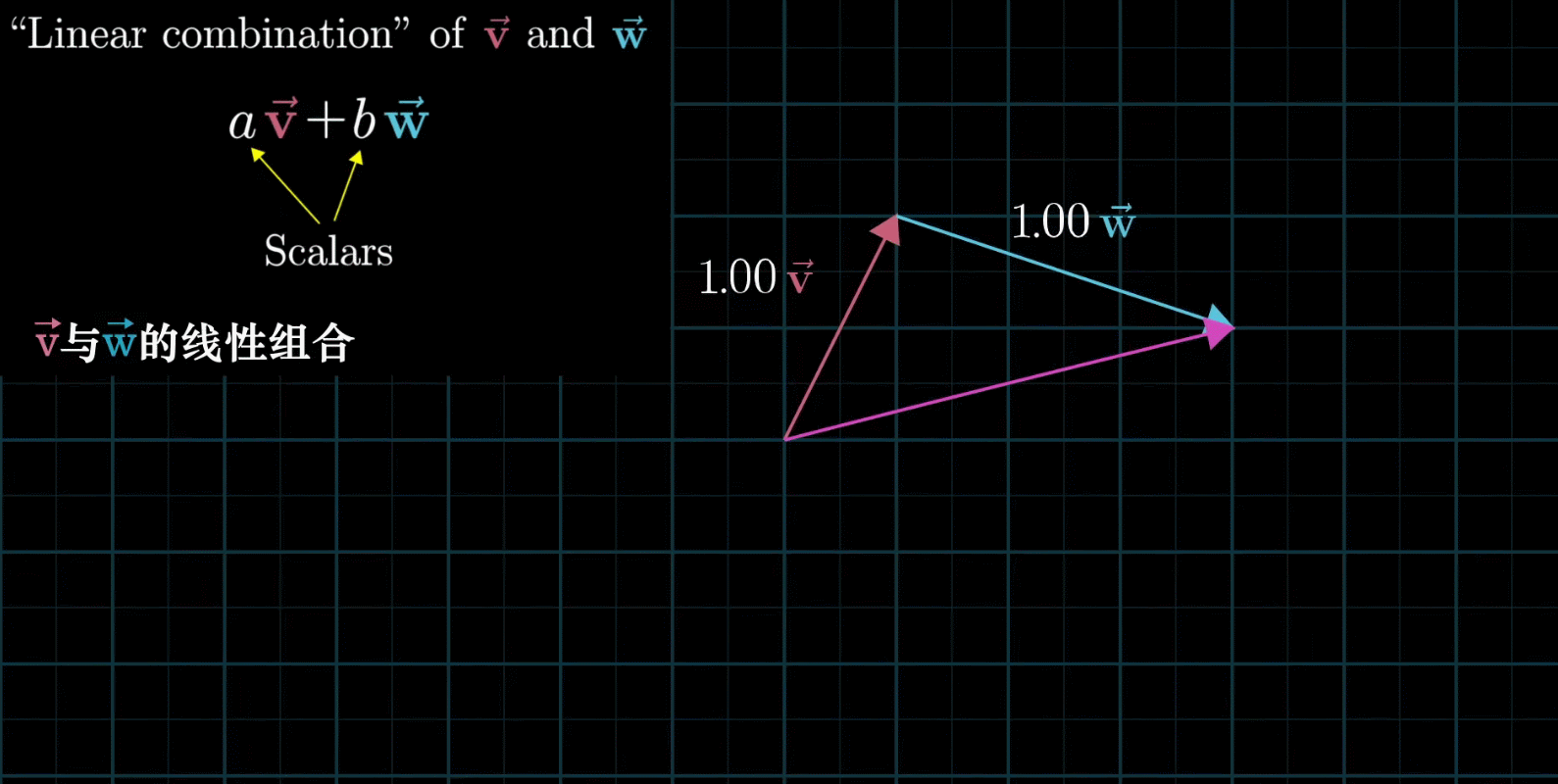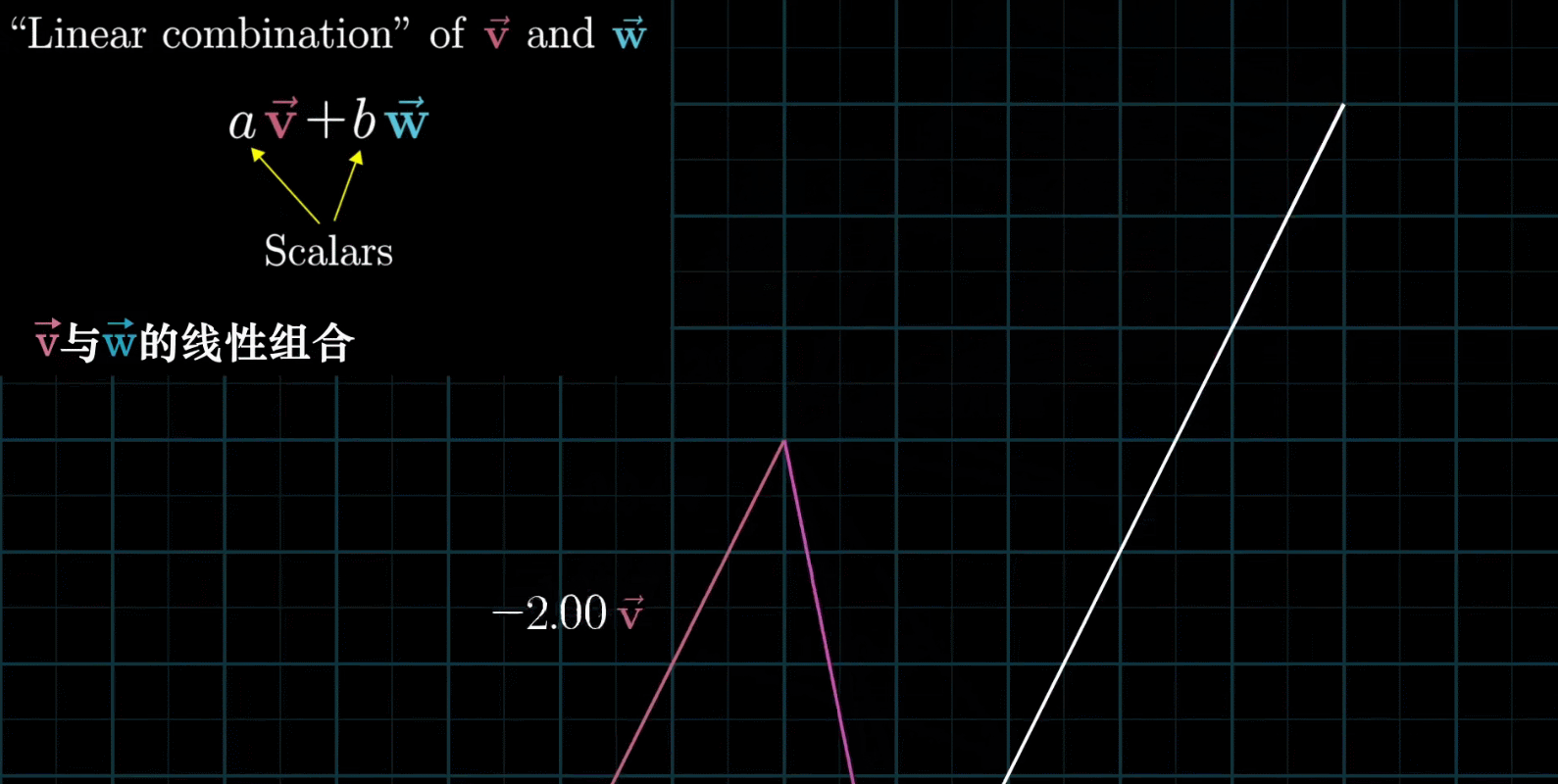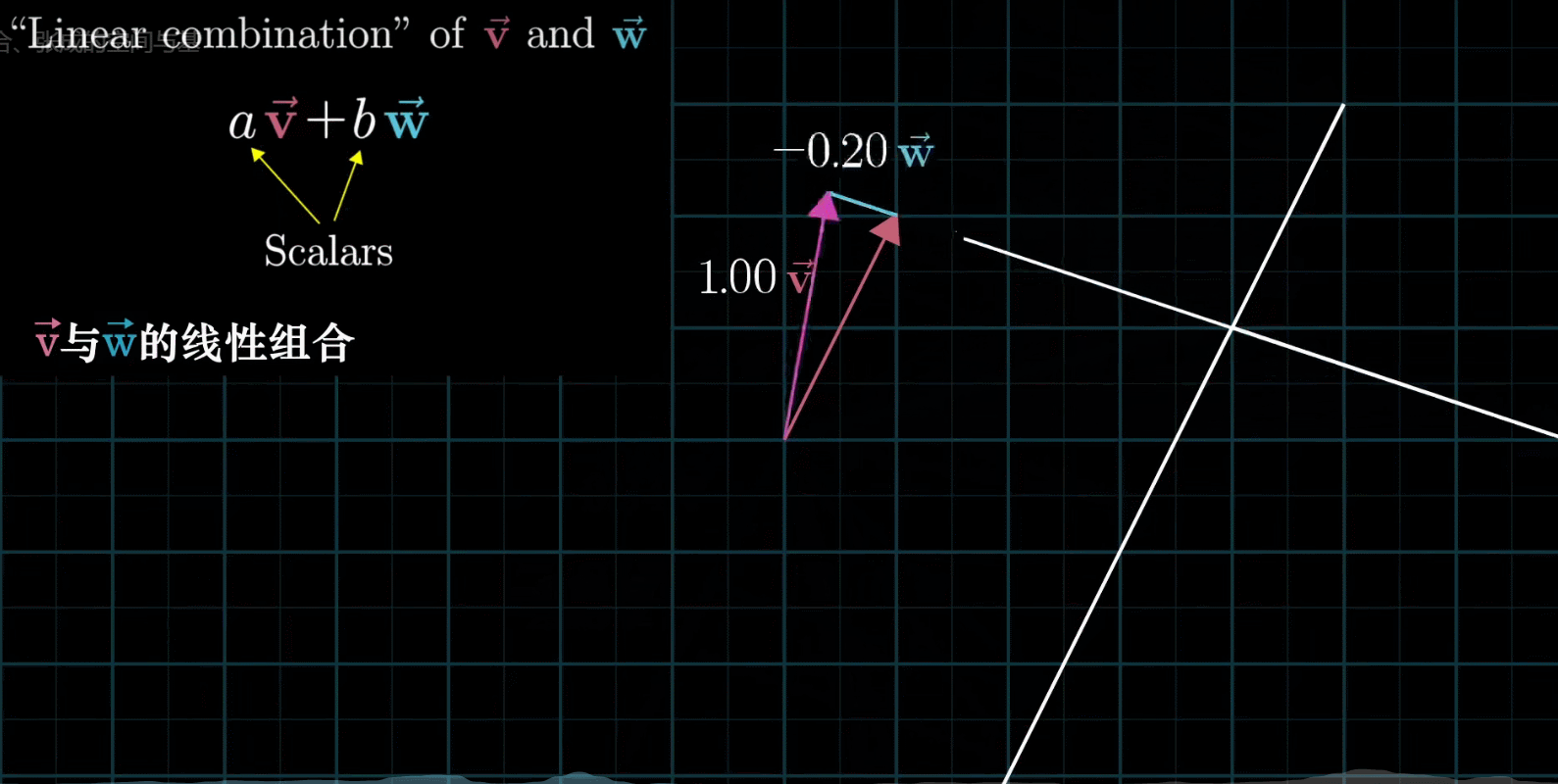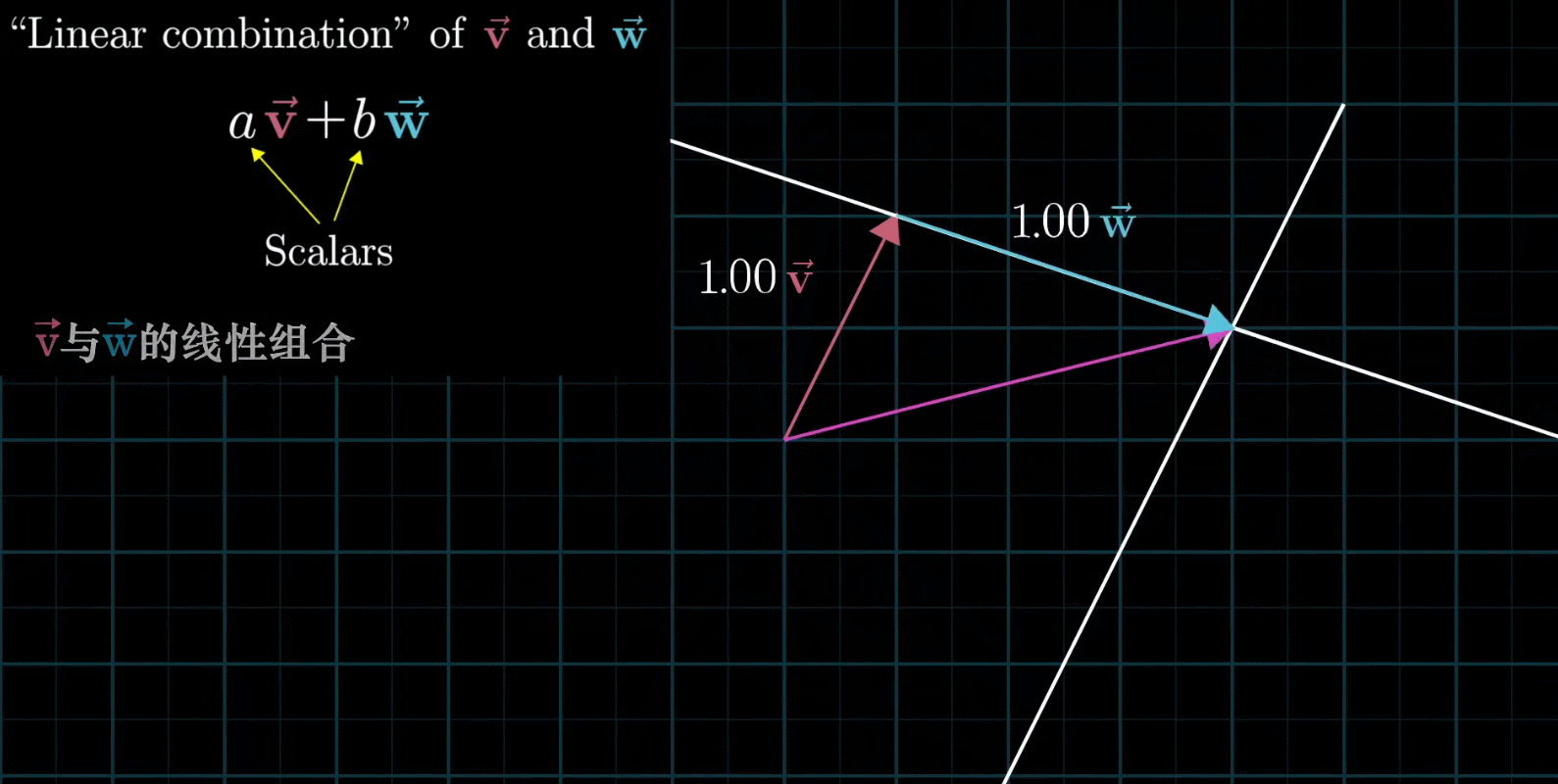
如果让两个标量都自由变换,那么会有以下几种情况:
在大多数情况下,对于一切初始向量,你能到达平面中任何一个点,所有二维向量尽在你的掌握之中
有时也会出现两个初始向量共线,那么所产生的新的向量的重点会被限制在一条过原点的直线上
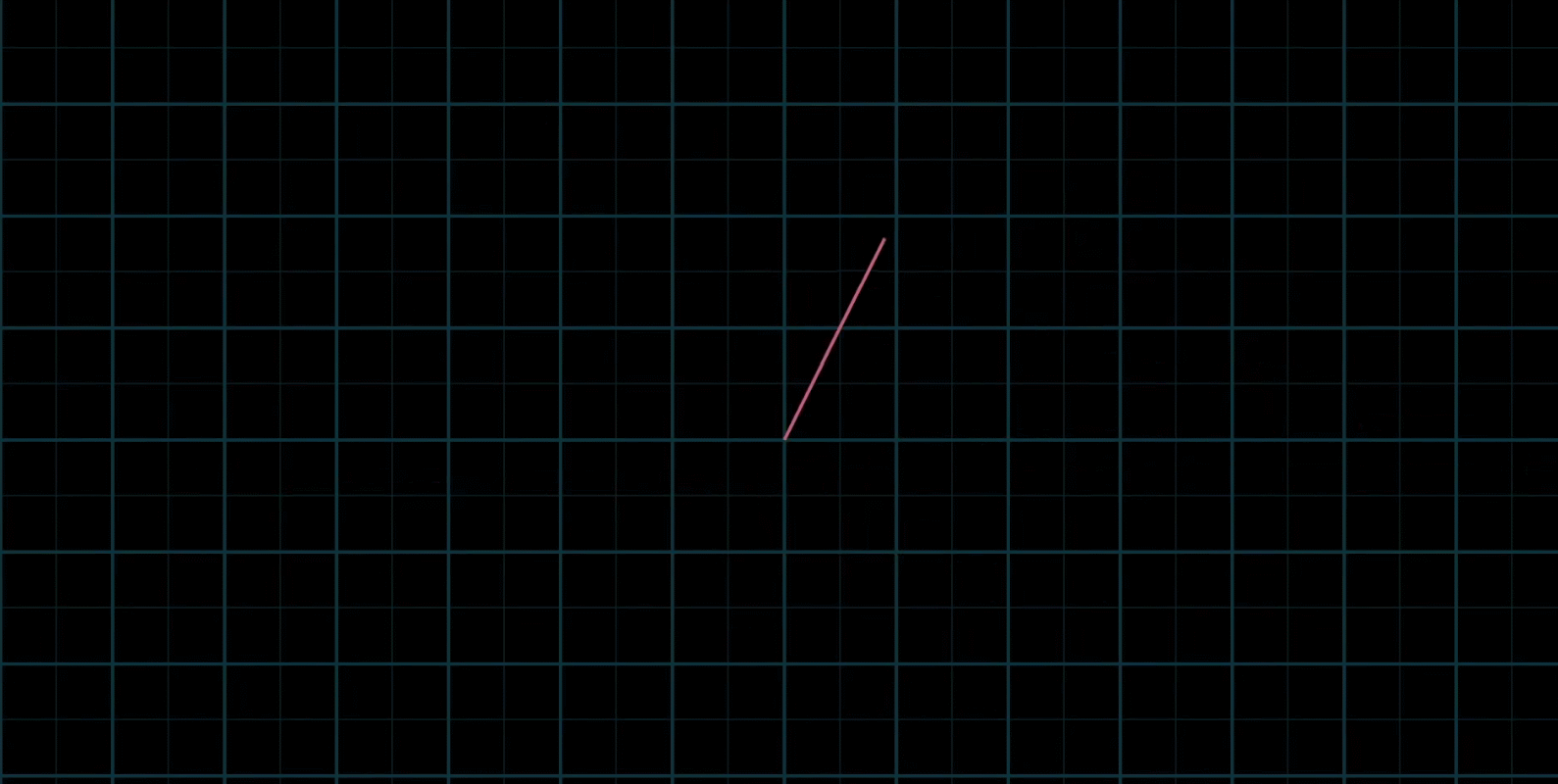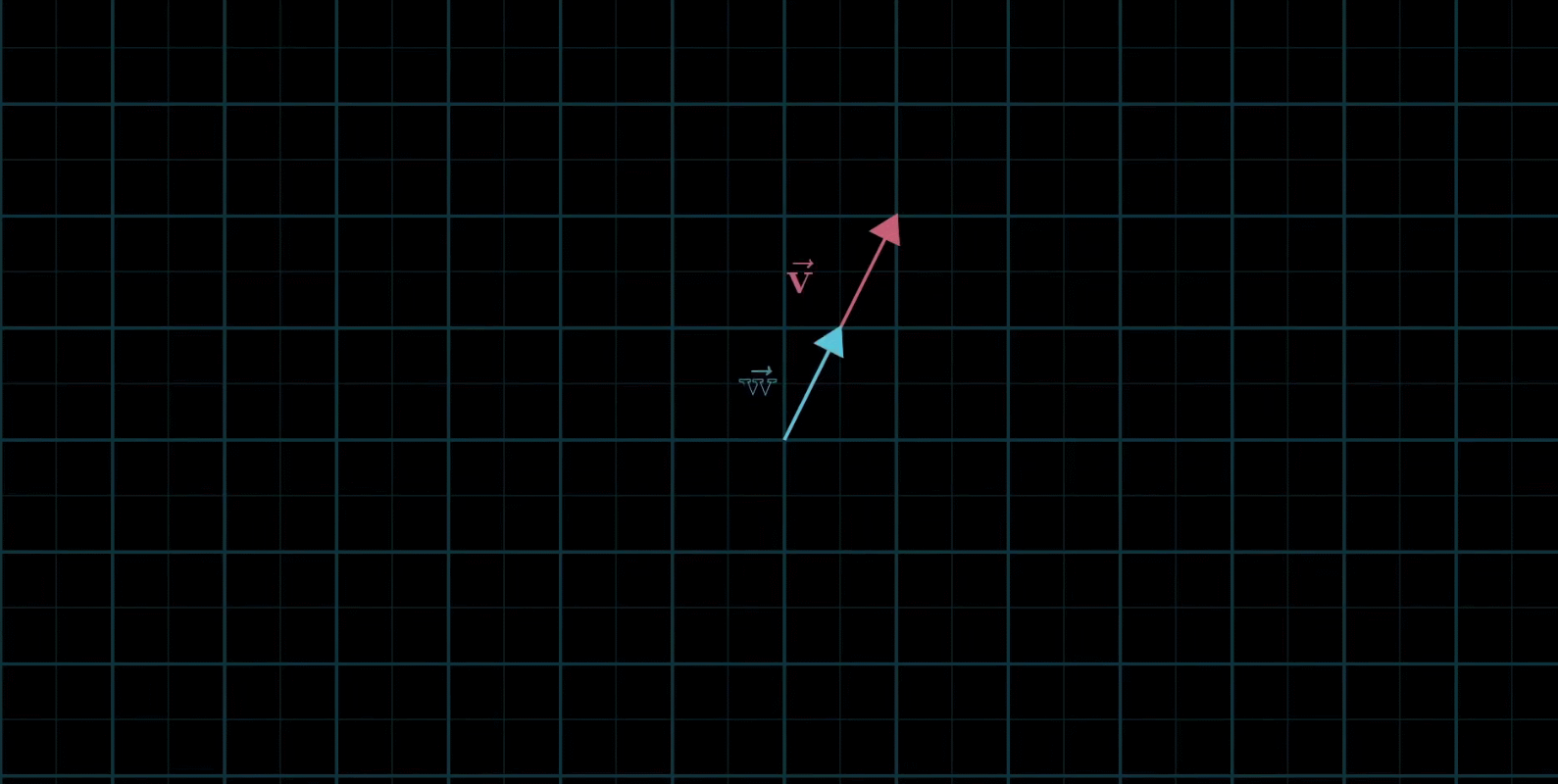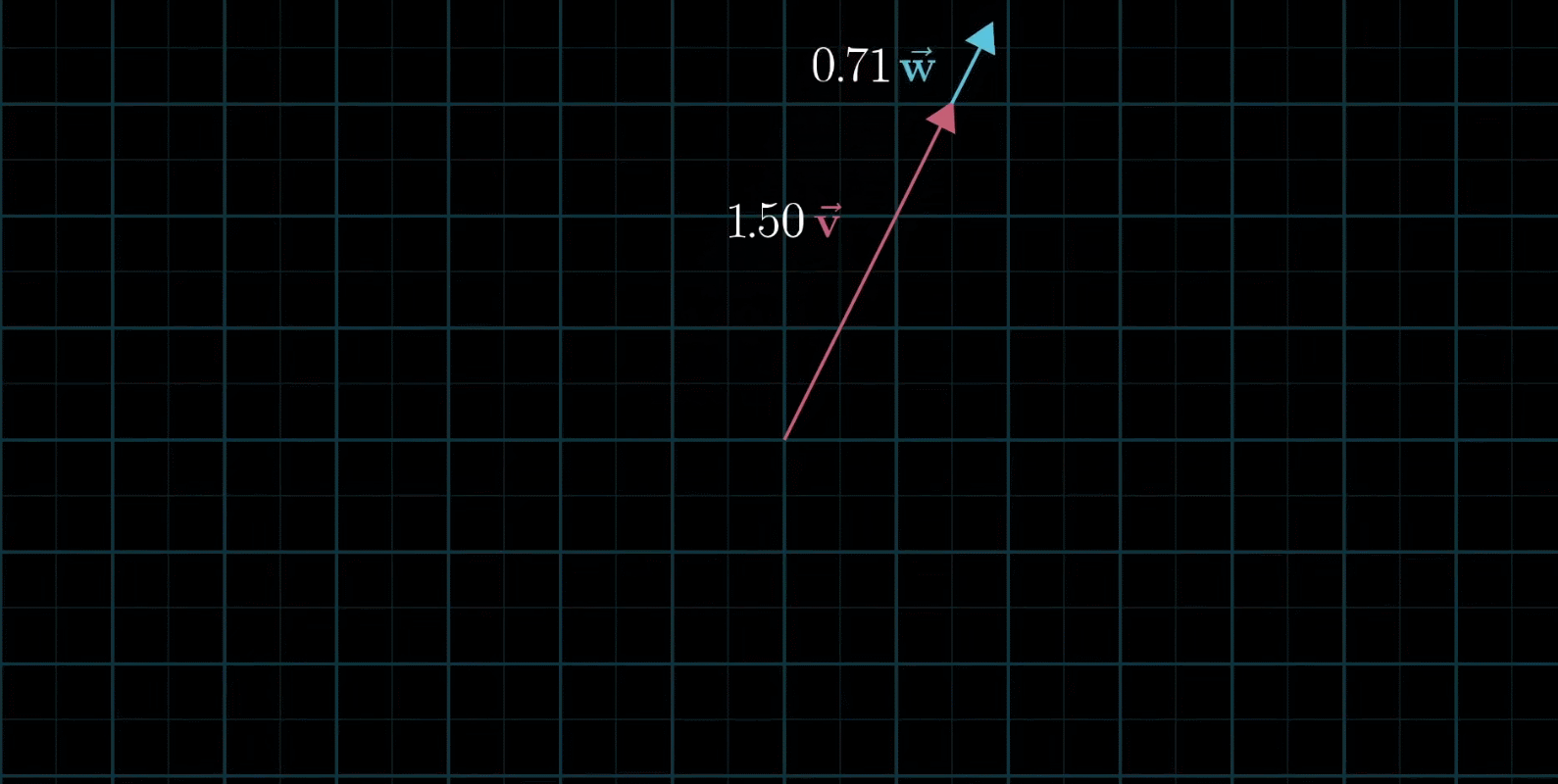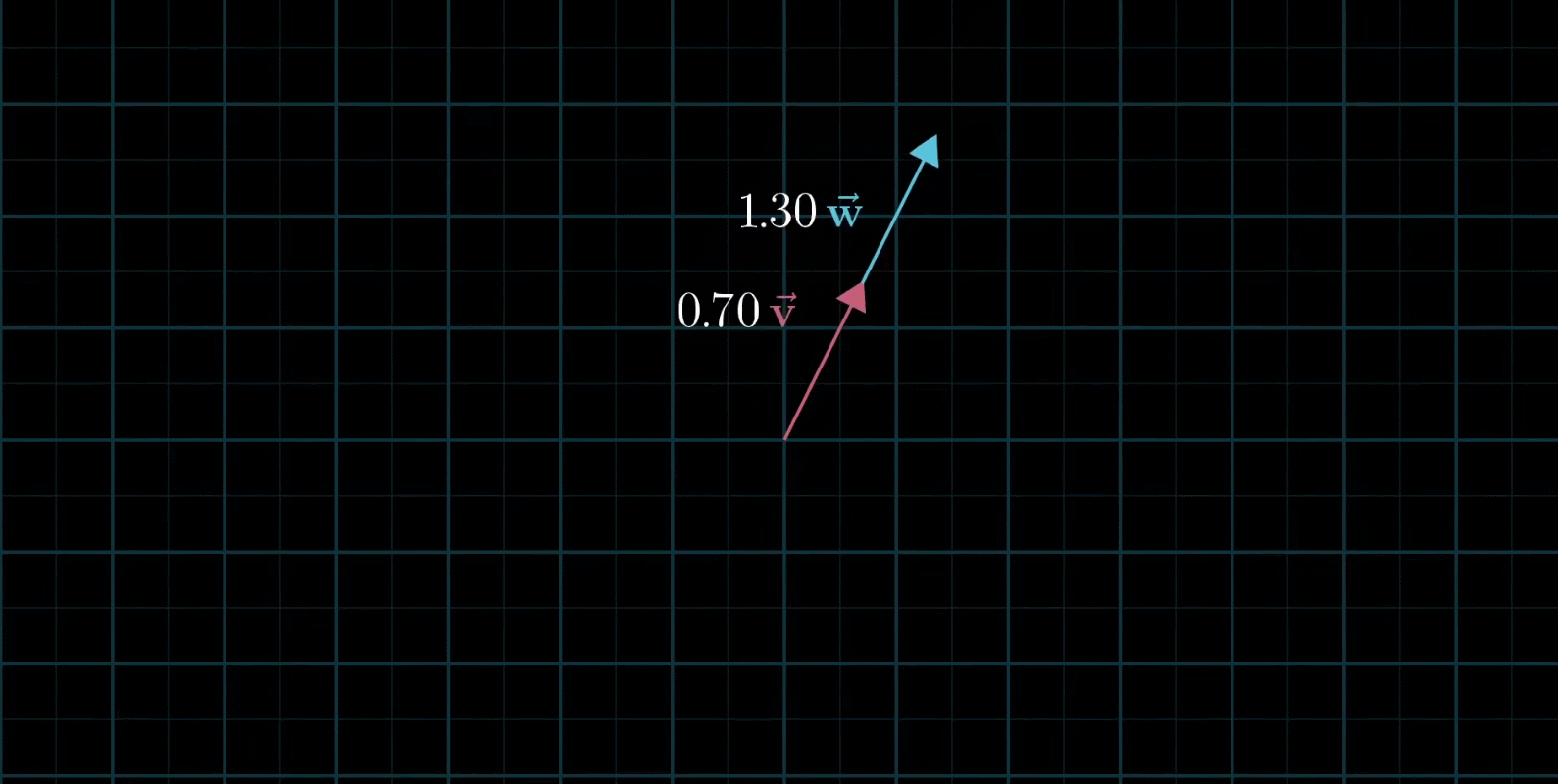
还有,两个向量可能都是零向量,那么就只能呆在原地了
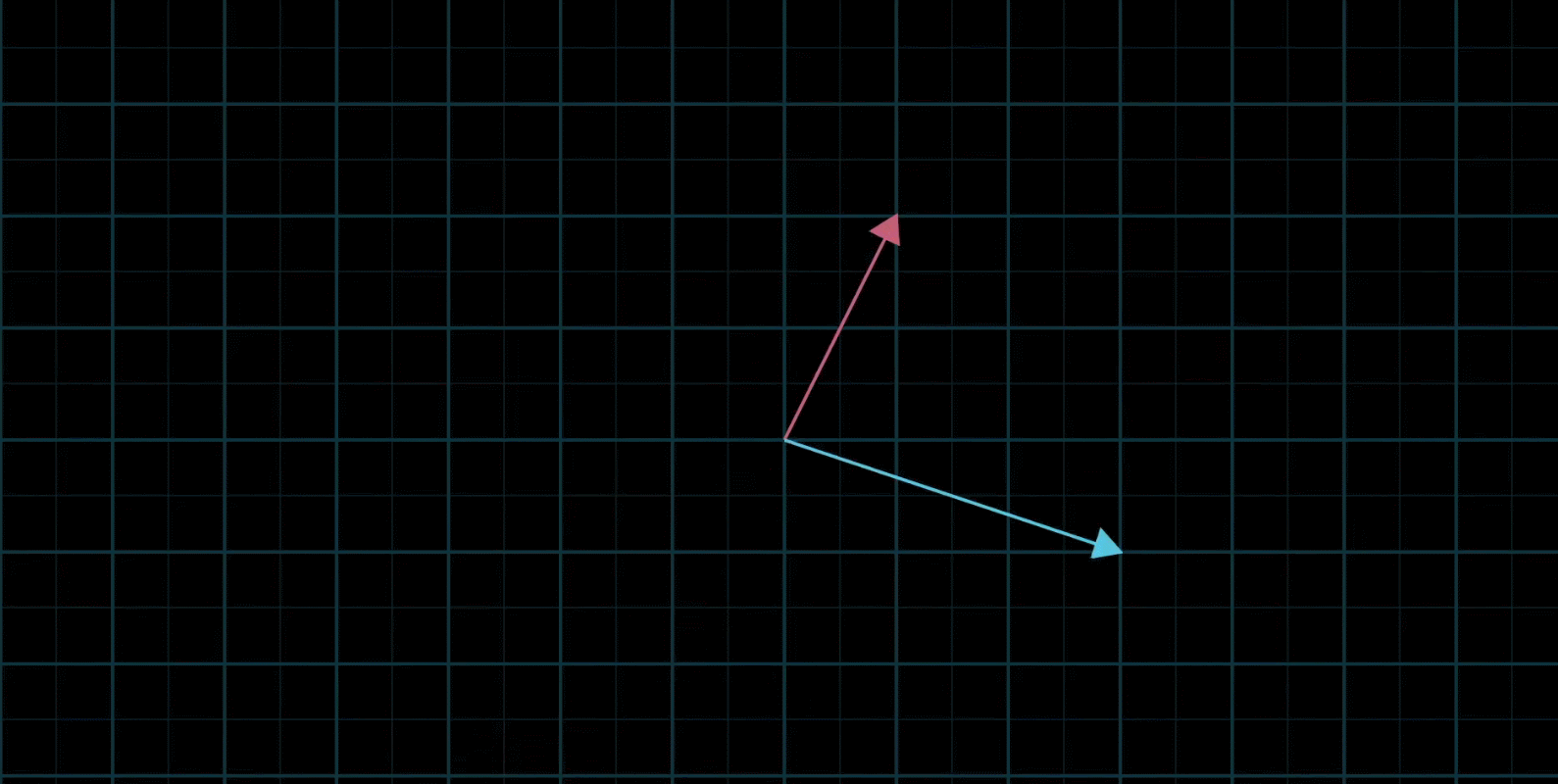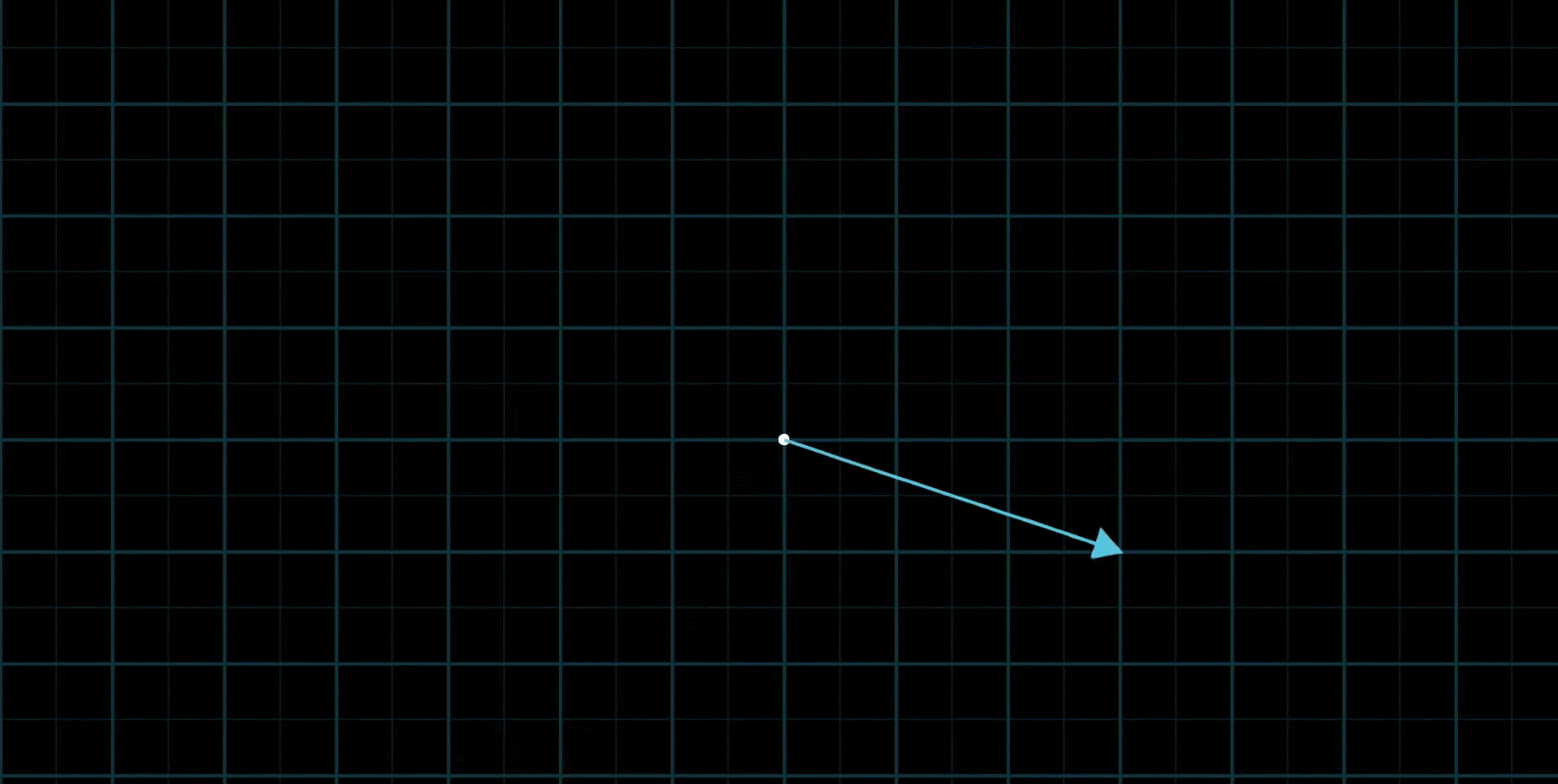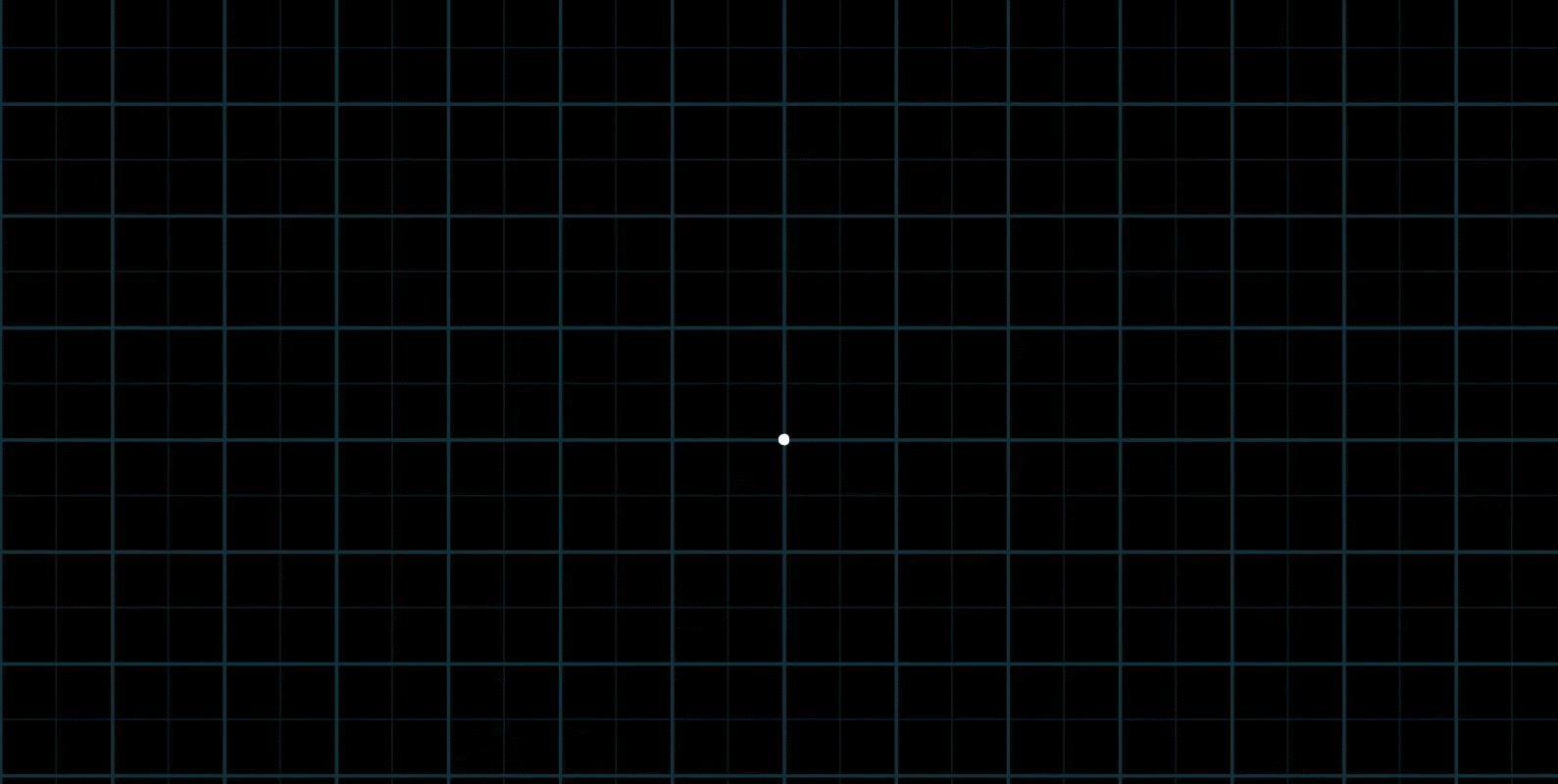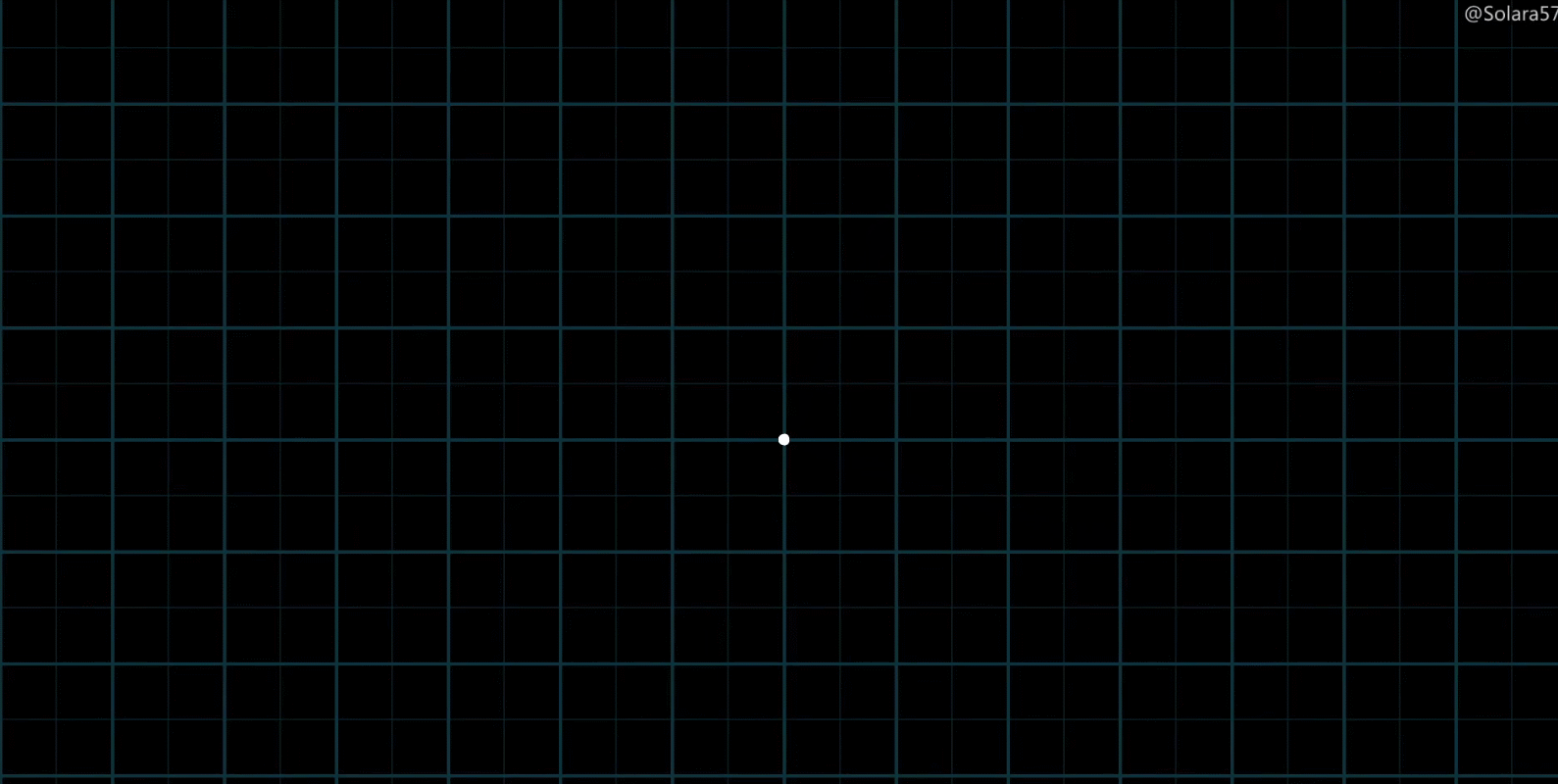
基向量:在二维平面直角坐标系中有一对非常特殊的向量
以 ( 3 − 2 ) \begin{pmatrix} 3\\ -2\end{pmatrix} (3−2)为例,可以看做是由单向向量 i i i正向拉长为原来的3倍,同时把单位向量 j j j反向拉长为原来的2倍得到
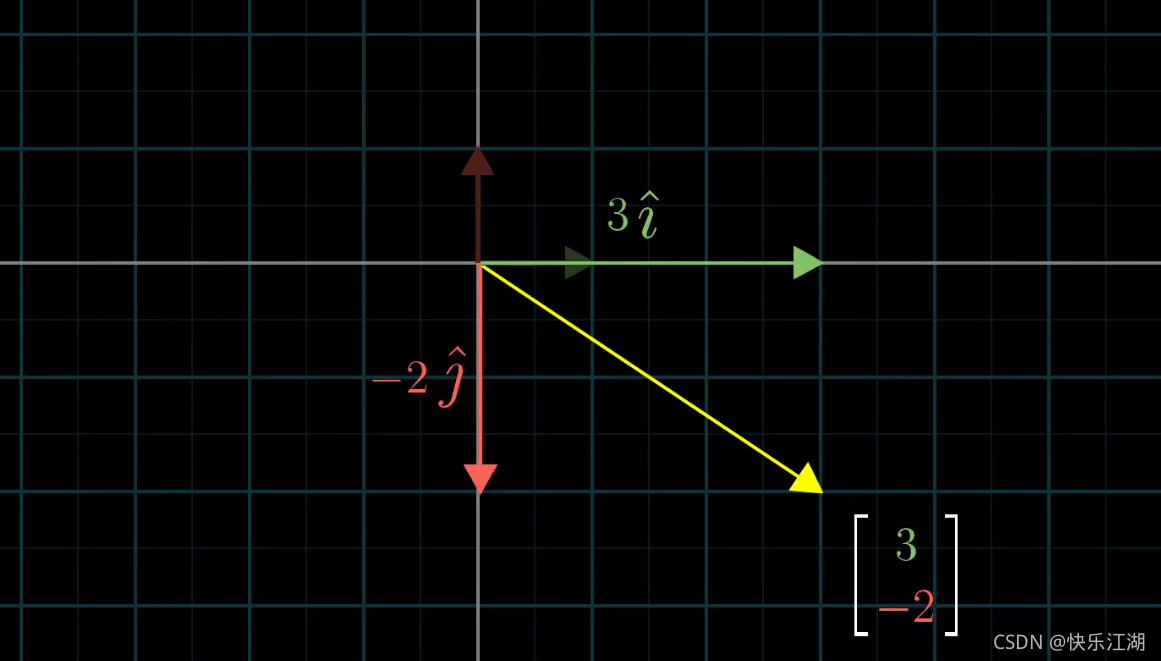
从这个角度上理解这个向量实际上是两个经过缩放的向量的和(注意这个概念非常重要)
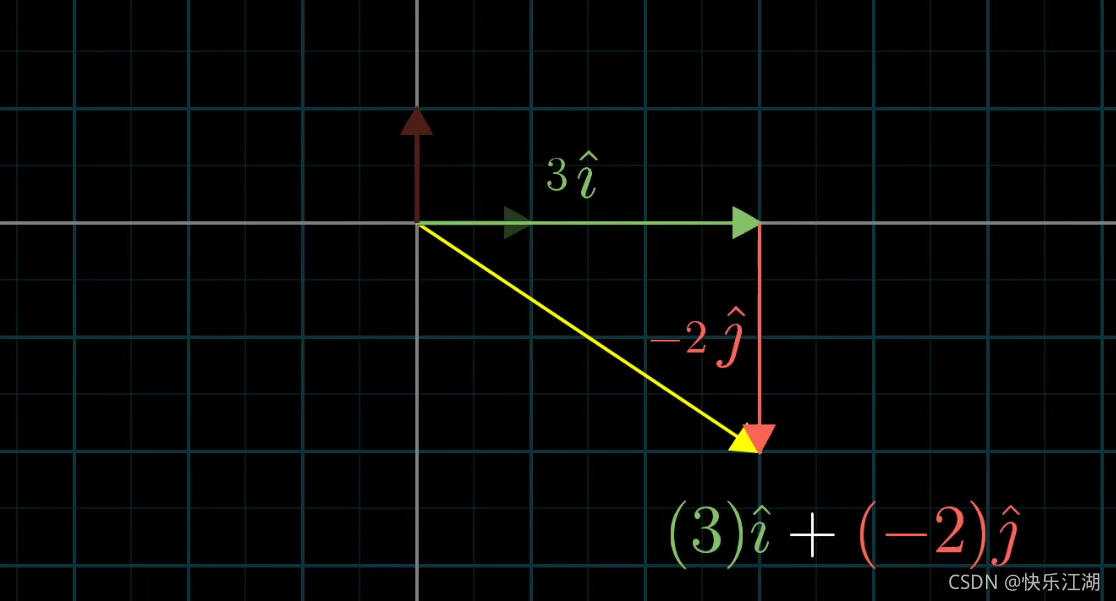
因此,这里我们把 i i i和 j j j称为 x y xy xy坐标系的“基向量”

向量张成的空间:它是一个集合,这个集合表示了所有可以由给定向量通过线性组合表示的向量
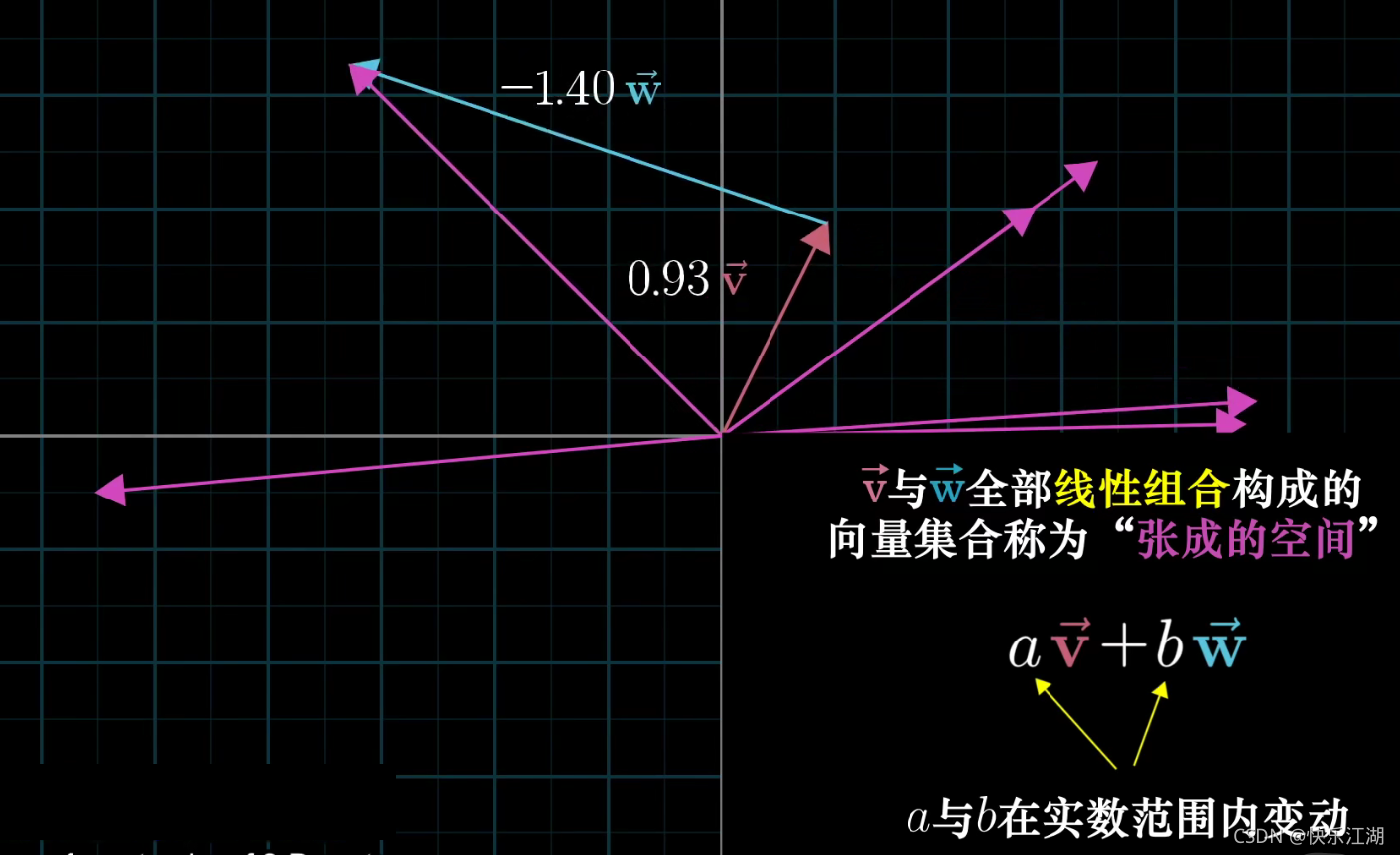
两个向量张成的空间提出了一个问题:仅通过向量加法和向量数乘这两种基础的运算,能获得的所有向量的集合是什么?
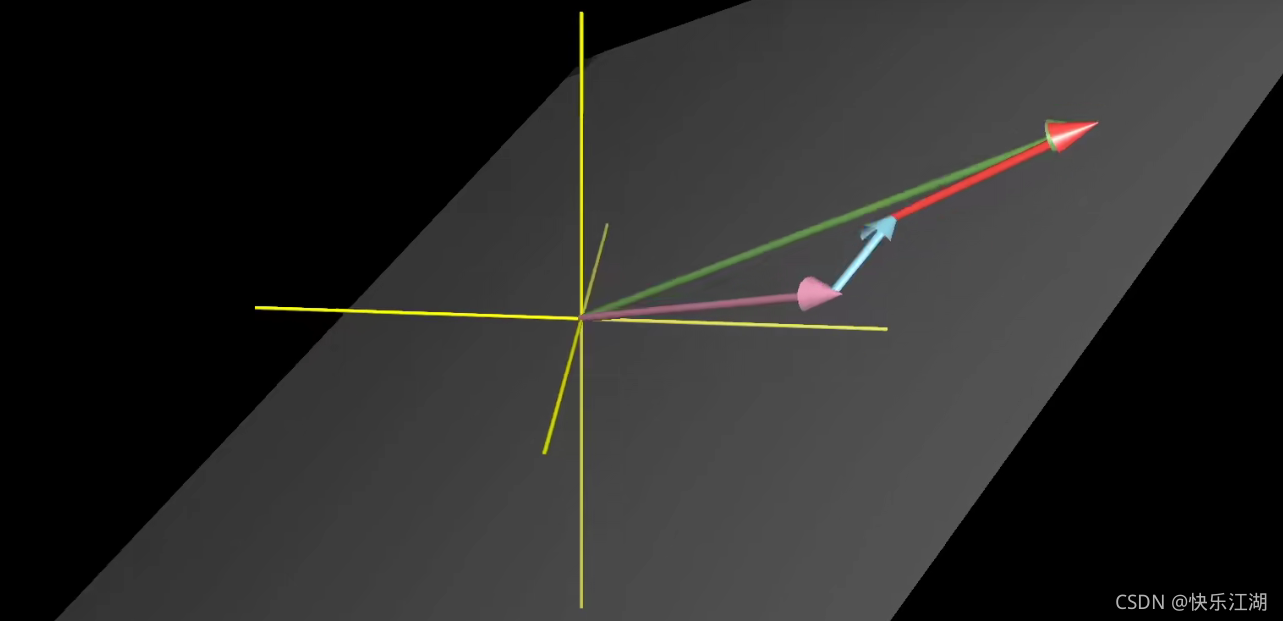
所以在三维空间中,取两个不同指向的向量,其张成的空间就是过某个原点的平面

如果让第三个向量落在前面两个向量张成的空间中,那么它们张成的空间将不会发生变化,或者通俗点说,这个向量就会被困在这个空间内
特征向量:本质就是一个向量,在实际场景中,用于描述一个事务、数据或问题,它有很多维度或者属性。例如:
特征空间:在特征向量中,由各个维度可能的取值所张成的空间,称之为特征空间。显然,特征空间限定了特征向量的取值范围。所以在特征中,任意一个向量代表的都是 n 维空间中的一个点;反过来, 空间中的任意点也都可以唯一地用一个
向量表示

线性无关:任取特征空间中的 n n n个特征向量 x 1 , x 2 , . . , x n x_{1},x_{2},..,x_{n} x1,x2,..,xn,如果当且仅当标量值 a 1 = a 2 = . . . = a n = 0 a_{1}=a_{2}=...=a_{n}=0 a1=a2=...=an=0时,才有 a 1 x 1 + a 2 x 2 + , . . . , + a n x n = 0 a_{1}x_{1}+a_{2}x_{2}+,...,+a_{n}x_{n}=0 a1x1+a2x2+,...,+anxn=0成立,就说这 n n n个特征向量是线性无关的,也就是说,其中任意一个向量不能写成由其他向量的数乘与加法运算构成的线性组合
根据前面所述,在一组向量中,有个别向量是“多余的”,去掉它们,向量张成的空间不会减少,那么我们就称它们是线性相关的

反之,如果所有向量都给张成的空间增添了新的维度,那么我们就称它们是线性无关的

因此,向量空间的一组基是张成该空间的一个线性无关向量集合
我正在尝试从Postgresql表(table1)中获取数据,该表由另一个相关表(property)的字段(table2)过滤。在纯SQL中,我会这样编写查询:SELECT*FROMtable1JOINtable2USING(table2_id)WHEREtable2.propertyLIKE'query%'这工作正常:scope:my_scope,->(query){includes(:table2).where("table2.property":query)}但我真正需要的是使用LIKE运算符进行过滤,而不是严格相等。然而,这是行不通的:scope:my_scope,->(que
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
我的Rails应用程序中安装了carrierwave。但是,当用户上传多页pdf时,我只希望应用程序获取文档中的第一页并将其转换为jpeg。这可能吗?用什么命令?这是我的uploader。#encoding:utf-8classImageUploader[200,300]##defscale(width,height)##dosomething#end#Createdifferentversionsofyouruploadedfiles:version:thumbdoprocess:resize_to_fill=>[150,210]process:convert=>:jpgdefful
我正在尝试按Rails相关模型中的字段进行排序。我研究的所有解决方案都没有解决如果相关模型被另一个参数过滤?元素模型classItem相关模型:classPriority我正在使用where子句检索项目:@items=Item.where('company_id=?andapproved=?',@company.id,true).all我需要按相关表格中的“位置”列进行排序。问题在于,在优先级模型中,一个项目可能会被多家公司列出。因此,这些职位取决于他们拥有的company_id。当我显示项目时,它是针对一个公司的,按公司内的职位排序。完成此任务的正确方法是什么?感谢您的帮助。PS-我
有没有办法跳过CSV文件的第一行,让第二行作为标题?我有一个CSV文件,第一行是日期,第二行是标题,所以我需要能够在遍历它时跳过第一行。我尝试使用slice但它会将CSV转换为数组,我真的很想将其读取为CSV,以便我可以利用header。 最佳答案 根据您的数据,您可以使用另一种方法和skip_lines-option此示例跳过所有以#开头的行require'csv'CSV.parse(DATA.read,:col_sep=>';',:headers=>true,:skip_lines=>/^#/#Markcomments!)do|
我的任务是从数组中选择最高和最低的数字。我想我很清楚我想做什么,但只是努力以正确的格式访问信息以满足通过标准。defhigh_and_low(numbers)array=numbers.split("").map!{|x|x.to_i}array.sort!{|a,b|ba}putsarray[0,-1]end数字可能看起来像"80917234100",要通过,我需要输出"9234"。我正在尝试putsarray.first.last,但一直无法弄明白。 最佳答案 有Array#minmax完全满足您需要的方法:array=[80,
假设您有一个可执行文件foo.rb,其库bar.rb的布局如下:/bin/foo.rb/lib/bar.rb在foo.rb的header中放置以下要求以在bar.rb中引入功能:requireFile.dirname(__FILE__)+"../lib/bar.rb"只要对foo.rb的所有调用都是直接的,这就可以正常工作。如果你把$HOME/project和符号链接(symboliclink)foo.rb放入$HOME/usr/bin,然后__FILE__解析为$HOME/usr/bin/foo.rb,因此无法找到bar.rb关于foo.rb的目录名.我意识到像rubygems这
或者好像我必须自己写方法?(保持DHA不变):ruby-1.9.2-p180:001>s='omega-3(DHA)'=>"omega-3(DHA)"ruby-1.9.2-p180:002>s.capitalize=>"Omega-3(dha)"ruby-1.9.2-p180:003>s.titleize=>"Omega3(Dha)"ruby-1.9.2-p180:005>s[0].upcase+s[1..-1]=>"Omega-3(DHA)" 最佳答案 如果我的回答只是垃圾,我深表歉意(我不做ruby)。但我相信我已经为您找到了答
我有这个字符串:auteur="comtedeFlandreetHainaut,Baudouin,Jacques,Thierry"我想删除第一个逗号之前的所有内容,即在这种情况下保留“Baudouin,Jacques,Thierry”试过这个:nom=auteur.gsub(/.*,/,'')但这会删除最后一个逗号之前的每个逗号,只保留“Thierry”。 最佳答案 auteur.partition(",").last#=>"Baudouin,Jacques,Thierry" 关于rub
我有一个以时间戳为键的哈希。hash={"2016-05-31T22:30:58+02:00"=>{"path"=>"/","method"=>"GET"},"2016-05-31T22:31:23+02:00"=>{"path"=>"/tour","method"=>"GET"},"2016-05-31T22:31:05+02:00"=>{"path"=>"/contact_us","method"=>"GET"}}我订购了这个系列并得到了第一双这样的:hash.sort_by{|k,_|k}.first.first但是我该如何删除它呢?删除方法requiresyou知道key的准确